







全连接神经网络学习笔记
全连接神经网络的整体结构
全连接神经网络整体架构分为输入层、隐藏层和输出层三层
-
输入层:用于接受原始数据。每个神经元代表一个特征,例如图像的像素值、语音信号的特征等。
-
隐藏层:处理和提取数据特征。每个神经元通过加权和激活函数来处理输入数据,然后将结果传递到下一层。
-
输出层:给出最终的预测结果。输出层的神经元数目等于任务的类别数。例如,在数字分类任务中,输出层有10个神经元(分别代表0到9这10个数字)。
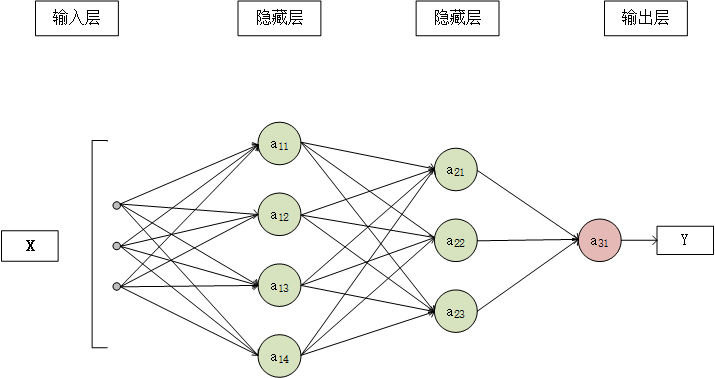
全连接神经网络的结构单元
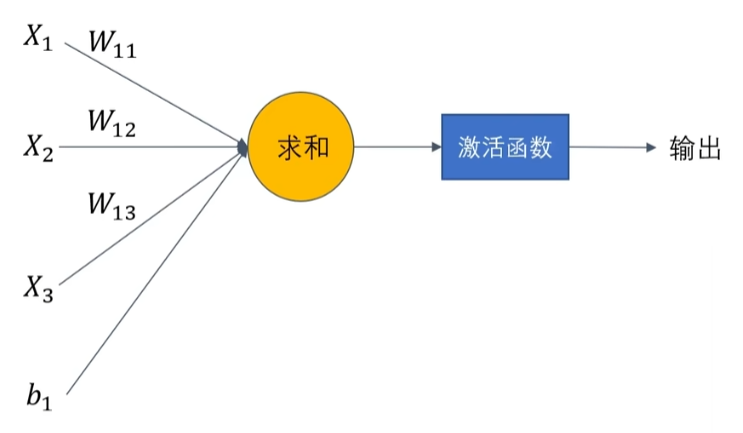
神经元的数学表达式如下所示:
a
=
h
(
w
∗
x
+
b
)
a=h(w*x+b)
a=h(w∗x+b)
其中 h() 就是激活函数,若隐去h() ,
w
∗
x
+
b
w*x+b
w∗x+b 就是线性回归模型的函数表达式,若 h() 是 sigmod 函数,则变成逻辑回归模型的函数表达式。
激活函数
激活函数是神经元最重要的组成部分,往往存在于神经网络的输入层和输出层之间,作用是给神经网络中增加一些非线性因素,使得神经网络能够解决更加复杂的问题,同时也增加神经网络的表达能力和学习能力。如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,最终的输出都是输入的线性组合。 激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数。
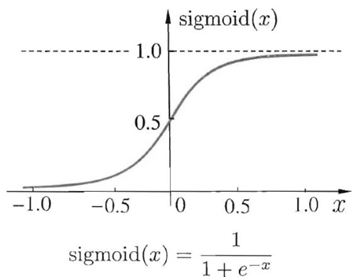
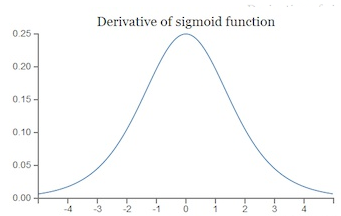
Sigmoid 函数
公式与导数如下所示:
y
=
1
1
+
e
−
z
⇒
y
′
=
y
(
1
−
y
)
y=\frac{1}{1+e^{-z}}\Rightarrow y'=y(1-y)
y=1+e−z1⇒y′=y(1−y)
其函数图像与导数图像如下所示:
优点:
- 简单、非常适用分类任务;
- 输出区间为 (0,1),方便观察输出是否符合预期,适合作为概率模型的输出
缺点:
- 反向传播训练时有梯度消失的问题;
- 输出区间为 (0,1),关于 0 不对称,导致参数 w 更新较慢;
- 梯度更新在不同方向走得太远,使得优化难度增大,训练耗时
Tanh 函数(双曲正切函数)
公式与导数如下所示:
y
=
e
z
−
e
−
z
e
z
+
e
−
z
⇒
y
′
=
1
−
y
2
y=\frac{e^z-e^{-z}}{e^z+e^{-z}}\Rightarrow y'=1-y^2
y=ez+e−zez−e−z⇒y′=1−y2
其函数图像如图所示:
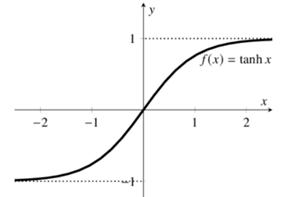
可以看出 Tanh 函数的取值范围为 [-1,1]。
优点:
- 解决了 Sigmoid 函数输出值非 0 对称的问题;
- 训练比 Sigmoid 函数快,更容易收敛
缺点:
- 反向传播训练时有梯度消失的问题;
- Tanh 函数和 Sigmoid 函数非常相似,虽然解决了 Sigmoid 函数输出值非 0 对称的问题,但仍然存在饱和问题
ReLU 函数
公式和导数如下所示:
y
=
{
z
z
>
0
0
z
≤
0
⇒
y
′
=
{
1
z
>
0
0
z
≤
0
y= \begin{cases} z & z>0 \\ 0 & z\leq0 \\ \end{cases} \Rightarrow y'= \begin{cases} 1 & z>0 \\ 0 & z\leq0 \\ \end{cases}
y={z0z>0z≤0⇒y′={10z>0z≤0
其函数图像与导数图像如下所示:
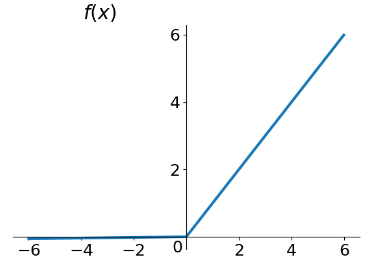
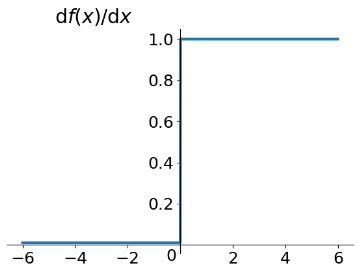
优点:
- 在X > 0 时,由于导数为 1,链式法则连乘也不会导致梯度消失,解决了梯度消失的问题;
- 计算方便,不存在 Sigmoid 函数和 Tanh 函数的指数计算,计算速度快 ,加速了网络的训练
缺点:
- 由于负数部分恒为0,大的学习率会导致一些神经元永久性死亡,无法激活(可通过设置小学习率部分解决);
- 输出不是以0为中心的
**PS:**关于大的学习率导致“神经元永久性死亡”如何理解,首先我们知道参数更新是通过 W = W − α W ′ W=W-αW' W=W−αW′,若学习率 α 太大,会导致 W 更新后为负数,当输入某个正值时,会导致其与 W 相乘后仍然为负值,此时激活函数输出为 0,而此时的导数也为 0,下次反向传播链式法则更新参数时,由于梯度为 0,W 将永远得不到更新。
LeakReLU 函数
公式和导数如下所示:
y
=
{
z
z
>
0
a
z
z
≤
0
⇒
y
′
=
{
1
z
>
0
a
z
≤
0
y= \begin{cases} z & z>0 \\ az & z\leq0 \\ \end{cases} \Rightarrow y'= \begin{cases} 1 & z>0 \\ a & z\leq0 \\ \end{cases}
y={zazz>0z≤0⇒y′={1az>0z≤0
其函数图像如下所示:
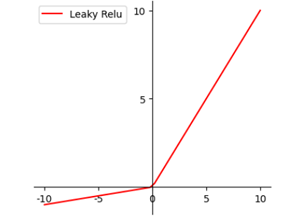
优点:
- 具有 ReLU 激活函数的优点;
- 解决了 ReLU 函数会杀死一部分神经元的情况
缺点:
- 无法为正负输入值提供一致的关系预测(不同区间函数不同)
SoftMax 函数
公式和导数如下所示:
y
i
=
e
z
i
∑
j
e
z
j
⇒
y
i
′
=
y
i
(
1
−
y
i
)
y_i=\frac{e^{z_i}}{\sum_j e^{z_j}}\Rightarrow y_i'=y_i(1-y_i)
yi=∑jezjezi⇒yi′=yi(1−yi)
SoftMax 函数的值域是在 [0,1] 之间的,并且存在多个输出,例如一个三分类任务,那么 SoftMax 函数最终的输出是对应每个类别的概率,同时这三个类别对应的概率相加最终的结果为 1 。因此在多分类任务的场景下,神经网络的最后一层一般都是使用 SoftMax 函数作为激活函数。
前向传播
神经网络的输出是通过前向传播最后输出的,前向传播是将数据特征作为输入,输入到隐藏层,将数据特征和对应的权重相乘同时再和偏置进行求和,将计算的结果通过激活函数进行激活,将激活函数输出值作为下一层神经网络层的输入再和对应的权重相乘同时和对应的偏置求和,再将计算的结果通过激活函数进行激活,不断重复上述的过程直到神经网络的输出层,最终得到神经网络的输出值。
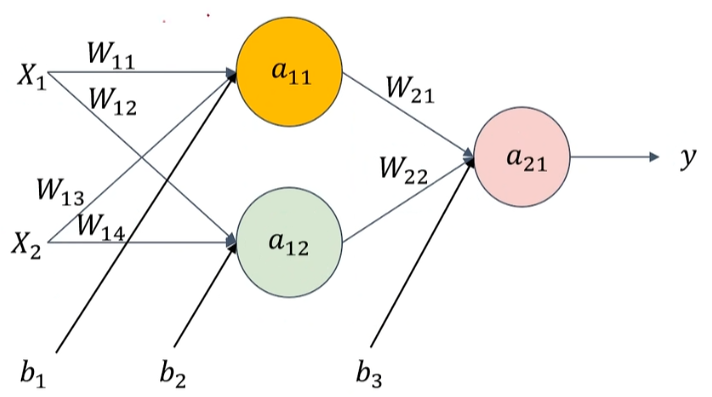
举例前向传播计算过程:
a
11
=
s
i
g
m
o
i
d
(
x
1
w
11
+
x
2
W
13
+
b
1
)
a
12
=
s
i
g
m
o
i
d
(
x
1
w
12
+
x
2
W
14
+
b
2
)
a
21
=
s
i
g
m
o
i
d
(
a
11
w
21
+
x
12
W
22
+
b
3
)
y
=
a
21
a_{11}=sigmoid(x_1w_{11}+x_2W_{13}+b_1)\\ a_{12}=sigmoid(x_1w_{12}+x_2W_{14}+b_2)\\ a_{21}=sigmoid(a_{11}w_{21}+x_{12}W_{22}+b_3)\\ y=a_{21}
a11=sigmoid(x1w11+x2W13+b1)a12=sigmoid(x1w12+x2W14+b2)a21=sigmoid(a11w21+x12W22+b3)y=a21
前向传播具体计算过程
这里利用一个简化的例子和具体的数值,推导计算辅助理解整个前向传播过程,同时可以借助该例对后续反向传播内容理解提供推导验算实例。
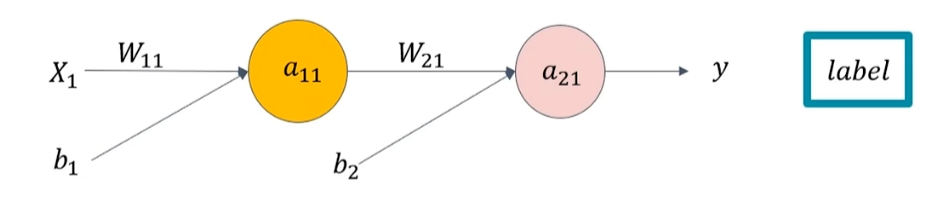
具体计算过程:
假设,初始化值为
w
11
=
0.5
w_{11}=0.5
w11=0.5,
w
21
=
1
w_{21}=1
w21=1,
b
1
=
0.5
b_1=0.5
b1=0.5,
b
2
=
1
b_2=1
b2=1,
x
1
=
1
x_1=1
x1=1,
l
a
b
e
l
=
2
label=2
label=2。
a
11
=
s
i
g
m
o
i
d
(
1
×
0.5
+
0
,
5
)
=
0.731
a
21
=
r
e
l
u
(
0.731
×
+
1
)
=
1.731
y
=
1.731
a_{11}=sigmoid(1\times0.5+0,5)=0.731\\ a_{21}=relu(0.731\times+1)=1.731\\ y=1.731
a11=sigmoid(1×0.5+0,5)=0.731a21=relu(0.731×+1)=1.731y=1.731
损失函数
均方差损失函数
J ( x ) = 1 2 m ∑ i = 1 m ( f ( x i ) − y i ) 2 J(x)=\frac{1}{2m}\sum_{i=1}^m(f(x_i)-y_i)^2 J(x)=2m1i=1∑m(f(xi)−yi)2
交叉熵损失函数
J ( x ) = − 1 m ∑ i = 1 m [ y i log σ ( w T x i + b ) + ( 1 − y i ) log ( 1 − σ ( w T x i + b ) ) ] J(x)=-\frac {1}{m}\sum_{i=1}^{m}[y_i\log \sigma(w^Tx_i+b)+(1-y_i)\log (1-\sigma(w^Tx_i+b))] J(x)=−m1i=1∑m[yilogσ(wTxi+b)+(1−yi)log(1−σ(wTxi+b))]
链式法则
单变量链式法则
假设,当 y 为 u 的函数。u 为 v 的函数,v 为 x 的函数,求 y 关于 x 的导数。具体的公式应当如下所示:
d
y
d
x
=
d
y
d
u
d
u
d
v
d
v
d
x
\frac{dy}{dx}=\frac{dy}{du}\frac{du}{dv}\frac{dv}{dx}
dxdy=dudydvdudxdv
算例:
存在函数 z = u 2 z=u^2 z=u2,同时 u = 2 − y u=2-y u=2−y, y = 4 x y=4x y=4x,求 z 关于 x 的导数。按链式求导法则有:
d
z
d
x
=
d
y
d
u
d
u
d
v
d
v
d
x
=
2
u
×
(
−
1
)
×
4
=
−
8
u
\begin{aligned} \frac{dz}{dx}&=\frac{dy}{du}\frac{du}{dv}\frac{dv}{dx}\\ &=2u\times(-1)\times4\\ &=-8u \end{aligned}
dxdz=dudydvdudxdv=2u×(−1)×4=−8u
同时:
u
=
2
−
y
,
y
=
4
x
u
=
2
−
4
x
u=2-y,y=4x\\ u=2-4x
u=2−y,y=4xu=2−4x
因此:
d
z
d
x
=
−
8
u
=
−
8
×
(
2
−
4
x
)
=
32
x
−
16
\begin{aligned} \frac{dz}{dx}&=-8u\\ &=-8\times(2-4x)\\ &=32x-16 \end{aligned}
dxdz=−8u=−8×(2−4x)=32x−16
多变量链式法则
假设,变量 z 为 u,v 的函数,u 和 v 分别为 y 的函数,y 为 x 的函数,求 z 关于 x 的导数。具体的公式应当如下所示:
∂
z
∂
x
=
∂
z
∂
u
⋅
∂
u
∂
y
⋅
∂
y
∂
x
+
∂
z
∂
v
⋅
∂
v
∂
y
⋅
∂
y
∂
x
\frac{\partial z}{\partial x}=\frac{\partial z}{\partial u}\cdot\frac{\partial u}{\partial y}\cdot\frac{\partial y}{\partial x} + \frac{\partial z}{\partial v}\cdot\frac{\partial v}{\partial y}\cdot\frac{\partial y}{\partial x}
∂x∂z=∂u∂z⋅∂y∂u⋅∂x∂y+∂v∂z⋅∂y∂v⋅∂x∂y
算例:
存在函数
z
=
u
2
+
v
3
z=u^2+v^3
z=u2+v3,同时
u
=
2
−
y
u=2-y
u=2−y,
v
=
4
+
y
v=4+y
v=4+y,
y
=
4
x
y=4x
y=4x,求 z 关于 x 的导数。按链式求导法则有:
∂
z
∂
x
=
∂
z
∂
u
⋅
∂
u
∂
y
⋅
∂
y
∂
x
+
∂
z
∂
v
⋅
∂
v
∂
y
⋅
∂
y
∂
x
=
2
u
×
(
−
1
)
×
4
+
3
v
2
×
1
×
4
=
−
8
u
+
12
v
2
\begin{aligned} \frac{\partial z}{\partial x} &= \frac{\partial z}{\partial u}\cdot\frac{\partial u}{\partial y}\cdot\frac{\partial y}{\partial x} + \frac{\partial z}{\partial v}\cdot\frac{\partial v}{\partial y}\cdot\frac{\partial y}{\partial x}\\ &= 2u\times(-1)\times4+3v^2\times1\times4\\ &= -8u+12v^2 \end{aligned}
∂x∂z=∂u∂z⋅∂y∂u⋅∂x∂y+∂v∂z⋅∂y∂v⋅∂x∂y=2u×(−1)×4+3v2×1×4=−8u+12v2
同时:
u
=
2
−
4
x
,
v
=
4
+
4
x
u=2-4x,v=4+4x
u=2−4x,v=4+4x
因此:
∂
z
∂
x
=
192
x
2
+
542
x
+
176
\frac{\partial z}{\partial x} = 192x^2+542x+176
∂x∂z=192x2+542x+176
反向传播
前向传播是神经网络通过层级结构和参数,将输入数据逐步转换为预测结果的过程,实现输入与输出之间的复杂映射。而反向传播算法利用链式法则,通过从输出层向输入层逐层计算误差梯度,高效求解神经网络参数的偏导数,以实现网络参数的优化和损失函数的最小化。
接下来利用之前学习前向传播过程时的简单例子推导演算反向传播的实现过程辅助理解。
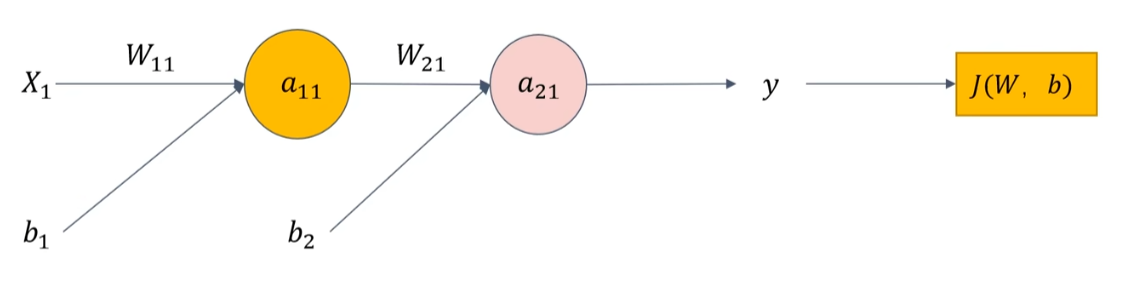
具体计算过程:
假设,初始化值为 w 11 = 0.5 w_{11}=0.5 w11=0.5, w 21 = 1 w_{21}=1 w21=1, b 1 = 0.5 b_1=0.5 b1=0.5, b 2 = 1 b_2=1 b2=1, x 1 = 1 x_1=1 x1=1, l a b e l = 2 label=2 label=2。通过前向传播计算得出 y = 1.731 y=1.731 y=1.731,而 l a b e l = 2 label=2 label=2,现在利用前向传播计算出来的输出值和真实值 label 之间的误差反向传播来进行梯度更新。
参数 w21 、b2 的求解:
∂
J
(
w
21
)
∂
w
21
=
∂
J
(
w
21
)
∂
y
⋅
∂
y
∂
a
21
⋅
∂
a
21
∂
w
21
=
∂
1
2
(
y
−
2
)
2
∂
y
⋅
∂
a
21
∂
a
21
⋅
∂
r
e
l
u
(
a
11
w
21
+
b
2
)
∂
(
a
11
w
21
+
b
2
)
⋅
∂
(
a
11
w
21
+
b
2
)
∂
w
21
=
(
y
−
2
)
×
1
⋅
∂
r
e
l
u
(
a
11
w
21
+
b
2
)
∂
(
a
11
w
21
+
b
2
)
⋅
∂
(
a
11
w
21
+
b
2
)
∂
w
21
=
(
y
−
2
)
×
a
11
×
∂
r
e
l
u
(
a
11
w
21
+
b
2
)
∂
(
a
11
w
21
+
b
2
)
\begin{aligned} \frac{\partial J(w_{21})}{\partial w_{21}} &= \frac{\partial J(w_{21})}{\partial y}\cdot\frac{\partial y}{\partial a_{21}}\cdot\frac{\partial a_{21}}{\partial w_{21}}\\ &= \frac{\partial \frac{1}{2}(y-2)^2}{\partial y}\cdot\frac{\partial a_{21}}{\partial a_{21}}\cdot\frac{\partial relu(a_{11}w_{21}+b_2)}{\partial (a_{11}w_{21}+b_2)}\cdot\frac{\partial(a_{11}w_{21}+b_2)}{\partial w_{21}}\\ &= (y-2)\times1\cdot\frac{\partial relu(a_{11}w_{21}+b_2)}{\partial (a_{11}w_{21}+b_2)}\cdot\frac{\partial(a_{11}w_{21}+b_2)}{\partial w_{21}}\\ &= (y-2)\times a_{11}\times \frac{\partial relu(a_{11}w_{21}+b_2)}{\partial (a_{11}w_{21}+b_2)} \end{aligned}
∂w21∂J(w21)=∂y∂J(w21)⋅∂a21∂y⋅∂w21∂a21=∂y∂21(y−2)2⋅∂a21∂a21⋅∂(a11w21+b2)∂relu(a11w21+b2)⋅∂w21∂(a11w21+b2)=(y−2)×1⋅∂(a11w21+b2)∂relu(a11w21+b2)⋅∂w21∂(a11w21+b2)=(y−2)×a11×∂(a11w21+b2)∂relu(a11w21+b2)
由于
a
11
w
21
+
b
=
1.731
>
0
a_{11}w{21}+b=1.731>0
a11w21+b=1.731>0,所以
∂
r
e
l
u
(
a
11
w
21
+
b
2
)
∂
(
a
11
w
21
+
b
2
)
=
1
\frac{\partial relu(a_{11}w_{21}+b_2)}{\partial (a_{11}w_{21}+b_2)}=1
∂(a11w21+b2)∂relu(a11w21+b2)=1
最终
∂
J
(
w
21
)
∂
w
21
=
(
y
−
2
)
×
a
11
=
(
1.731
−
2
)
×
0.731
=
−
0.196639
\begin{aligned} \frac{\partial J(w_{21})}{\partial w_{21}} &= (y-2)\times a_{11}\\ &=(1.731-2)\times 0.731\\ &=-0.196639 \end{aligned}
∂w21∂J(w21)=(y−2)×a11=(1.731−2)×0.731=−0.196639
同理可得出:
∂
J
(
b
2
)
∂
b
2
=
−
0.269
\frac{\partial J(b_2)}{\partial b_2}=-0.269
∂b2∂J(b2)=−0.269
参数 w11 、b1 的求解:
∂
J
(
w
11
)
∂
w
11
=
∂
J
(
w
11
)
∂
y
⋅
∂
y
∂
a
21
⋅
∂
a
21
∂
a
11
⋅
∂
a
11
∂
w
11
=
∂
1
2
(
y
−
2
)
2
∂
y
⋅
∂
a
21
∂
a
21
⋅
∂
r
e
l
u
(
a
11
w
21
+
b
2
)
∂
a
11
⋅
∂
s
i
g
m
o
i
d
(
x
1
w
11
+
b
1
)
∂
w
11
=
(
y
−
2
)
×
1
⋅
∂
r
e
l
u
(
a
11
w
21
+
b
2
)
∂
(
a
11
w
21
+
b
2
)
⋅
∂
(
a
11
w
21
+
b
2
)
∂
a
11
⋅
∂
s
i
g
m
o
i
d
(
x
1
w
11
+
b
1
)
∂
w
11
=
(
y
−
2
)
×
w
21
⋅
∂
s
i
g
m
o
i
d
(
x
1
w
11
+
b
1
)
∂
w
11
=
(
y
−
2
)
×
w
21
×
s
i
g
m
o
i
d
(
x
1
w
11
+
b
1
)
(
1
−
s
i
g
m
o
i
d
(
x
1
w
11
+
b
1
)
x
1
)
=
(
1.731
−
2
)
×
1
×
0.731
×
(
1
−
0.731
)
×
1
=
−
0.269
×
0.731
×
0.269
×
1
=
−
0.052895
\begin{aligned} \frac{\partial J(w_{11})}{\partial w_{11}} &= \frac{\partial J(w_{11})}{\partial y}\cdot\frac{\partial y}{\partial a_{21}}\cdot\frac{\partial a_{21}}{\partial a_{11}} \cdot\frac{\partial a_{11}}{\partial w_{11}}\\ &= \frac{\partial \frac{1}{2}(y-2)^2}{\partial y}\cdot\frac{\partial a_{21}}{\partial a_{21}}\cdot\frac{\partial relu(a_{11}w_{21}+b_2)}{\partial a_{11}}\cdot\frac{\partial sigmoid(x_1w_{11}+b_1)}{\partial w_{11}}\\ &= (y-2)\times1\cdot\frac{\partial relu(a_{11}w_{21}+b_2)}{\partial (a_{11}w_{21}+b_2)}\cdot\frac{\partial(a_{11}w_{21}+b_2)}{\partial a_{11}}\cdot\frac{\partial sigmoid(x_1w_{11}+b_1)}{\partial w_{11}} \\ &= (y-2)\times w_{21}\cdot \frac{\partial sigmoid(x_1w_{11}+b_1)}{\partial w_{11}}\\ &= (y-2)\times w_{21}\times sigmoid(x_1w_{11}+b_1)(1-sigmoid(x_1w_{11}+b_1)x_1)\\ &= (1.731-2)\times 1\times 0.731 \times(1-0.731)\times1\\ &= -0.269\times 0.731\times 0.269\times1\\ &= -0.052895 \end{aligned}
∂w11∂J(w11)=∂y∂J(w11)⋅∂a21∂y⋅∂a11∂a21⋅∂w11∂a11=∂y∂21(y−2)2⋅∂a21∂a21⋅∂a11∂relu(a11w21+b2)⋅∂w11∂sigmoid(x1w11+b1)=(y−2)×1⋅∂(a11w21+b2)∂relu(a11w21+b2)⋅∂a11∂(a11w21+b2)⋅∂w11∂sigmoid(x1w11+b1)=(y−2)×w21⋅∂w11∂sigmoid(x1w11+b1)=(y−2)×w21×sigmoid(x1w11+b1)(1−sigmoid(x1w11+b1)x1)=(1.731−2)×1×0.731×(1−0.731)×1=−0.269×0.731×0.269×1=−0.052895
同理可得出:
∂
J
(
b
1
)
∂
b
1
=
−
0.052895
\frac{\partial J(b_1)}{\partial b_1}=-0.052895
∂b1∂J(b1)=−0.052895
对应参数的梯度:
∂
J
(
w
21
)
∂
w
21
=
−
0.196639
,
∂
J
(
b
2
)
∂
b
2
=
−
0.269
,
∂
J
(
w
11
)
∂
w
11
=
−
0.052895
,
∂
J
(
b
1
)
∂
b
1
=
−
0.052895
\frac{\partial J(w_{21})}{\partial w_{21}}=-0.196639,\frac{\partial J(b_2)}{\partial b_2}=-0.269,\\ \frac{\partial J(w_{11})}{\partial w_{11}}=-0.052895,\frac{\partial J(b_1)}{\partial b_1}=-0.052895
∂w21∂J(w21)=−0.196639,∂b2∂J(b2)=−0.269,∂w11∂J(w11)=−0.052895,∂b1∂J(b1)=−0.052895
为了方便计算,以下全部保留三位小数,设置学习率大小为 0.1,则 更新参数 如下:
w
11
=
0.5
−
0.1
×
(
−
0.053
)
=
0.505
w
21
=
1
−
0.1
×
(
−
0.197
)
=
1.020
b
1
=
0.5
−
0.1
×
(
−
0.053
)
=
0.505
b
2
=
1
−
0.1
×
(
−
0.269
)
=
1.027
w_{11}=0.5-0.1\times(-0.053)=0.505\\ w_{21}=1-0.1\times(-0.197)=1.020\\ b_1=0.5-0.1\times(-0.053)=0.505\\ b_2=1-0.1\times(-0.269)=1.027
w11=0.5−0.1×(−0.053)=0.505w21=1−0.1×(−0.197)=1.020b1=0.5−0.1×(−0.053)=0.505b2=1−0.1×(−0.269)=1.027
由该组新参数前向传播得:
a
11
=
s
i
g
m
o
i
d
(
1
×
0.505
+
0.505
)
=
0.733
a
21
=
r
e
l
u
(
0.733
×
1.02
+
1.027
)
=
1.775
y
=
1.775
a_{11}=sigmoid(1\times 0.505+0.505)=0.733\\ a_{21}=relu(0.733\times1.02+1.027)=1.775\\ y=1.775
a11=sigmoid(1×0.505+0.505)=0.733a21=relu(0.733×1.02+1.027)=1.775y=1.775
结论:
此时最终的输出结果为 y = 0.1775 y=0.1775 y=0.1775 ,可以看出这个数值比初次前向传播得出的输出值 1.731 更接近真实值 2.

















 1223
1223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









