






11.7 函数
11.7.1 系统函数
- 标量函数
只有数值大小,没有方向的量,行变行
- 比较函数

-
逻辑函数

-
算数函数

- 字符串函数

- 时间函数

- 聚合函数
多行变一行
count(),sum(),rank(),row_number()
11.7.2 自定义函数(UDF)
- 分类
标量函数,聚合函数:多对一
表函数,表聚合函数:一对多,多对多
- 调用流程
- 注册函数
tableEnv.createTemporarySystemFunction("MyFunction",MyFunction.class);
createTemporarySystemFunction属于系统函数,全局的,如果不需要可以用它createTemporaryFunction
- 使用TableAPI调用函数
使用call()方法调用自定义函数,第一个MyFunction是注册好的函数名字,myField表示传入的参数
tableEnv.from("MyTable").select(call("MyFunction",$("myField")));
要是没注册
tableEnv.from("MyTable").select(call(SubstringFunction.class,${"myField"}));
- 直接在SQL中调用函数
tableEnv.sqlQuery("SELECT MyFunction(myField) FROM MyTable");
11.7.3 标量函数
- 概述
要想实现标量函数,需要自定义一个类来继承抽象类ScalarFunction,ScalarFunction里面没有求值方法
,但是需要实现叫做eval()的求值方法(固定public公有的)


- 代码
public class UdfTest_ScalarFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//1. 在创建表的DDL中直接定义时间属性
String createDDL = "CREATE TABLE clickTable (" +
" `user` STRING, " +
" url STRING, " +
" ts BIGINT," +
" et AS TO_TIMESTAMP(FROM_UNIXTIME(ts/1000))," +//TO_TIMESTAMP要String,使用FROM_UNIXTIME转成string传入,ts/1000是秒
" WATERMARK FOR et AS et - INTERVAL '1' SECOND " +//水位线
" ) WITH (" +
" 'connector' = 'filesystem'," +
" 'path' = 'input/clicks.csv',"+
" 'format' = 'csv'" +
") ";
tableEnv.executeSql(createDDL);
//2.注册自定义标量函数
tableEnv.createTemporarySystemFunction("MyHash",MyHashFunction.class);
//3.调用UDF进行查询转换
Table resultTable = tableEnv.sqlQuery("select user,MyHash(user) from clickTable");
//4.转换成流打印输出
tableEnv.toDataStream(resultTable).print();
env.execute();
}
//自定义实现Scalar
public static class MyHashFunction extends ScalarFunction{
//自己定义一个
public int eval(String str){
return str.hashCode();
}
}
}
结果
+I[Mary, 2390779]
+I[Alice, 63350368]
+I[Bob, 66965]
+I[Bob, 66965]
+I[Bob, 66965]
+I[Mary, 2390779]
+I[Bob, 66965]
+I[Bob, 66965]
+I[Bob, 66965]
+I[Bob, 66965]
+I[Bob, 66965]
+I[Bob, 66965]
Process finished with exit code 0
11.7.4 表函数
- 概述


要实现自定义的表函数,需要自定义来继承抽象类TableFunticon,内部也要实现一个eval的求值方法,跟标量函数一样
泛型就是返回的类型,可以基本类型,也可以二元组Tuple,或者Row类等其他类型
有Collector类,返回的时候调用collect()接口中的方法即可
再使用LATERAL TABLE语法实现表的拓展
"SELECT myField, word, length " +
"FROM MyTable, LATERAL TABLE(SplitFunction(myField))");
也可以重命名
"SELECT myField, newWord, newLength " +
"FROM MyTable " +
"LEFT JOIN LATERAL TABLE(SplitFunction(myField)) AS T(newWord, newLength) ON TRUE")
- 例子
public class UdfTest_TableFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//1. 在创建表的DDL中直接定义时间属性
String createDDL = "CREATE TABLE clickTable (" +
" `user` STRING, " +
" url STRING, " +
" ts BIGINT," +
" et AS TO_TIMESTAMP(FROM_UNIXTIME(ts/1000))," +//TO_TIMESTAMP要String,使用FROM_UNIXTIME转成string传入,ts/1000是秒
" WATERMARK FOR et AS et - INTERVAL '1' SECOND " +//水位线
" ) WITH (" +
" 'connector' = 'filesystem'," +
" 'path' = 'input/clicks.csv'," +
" 'format' = 'csv'" +
") ";
tableEnv.executeSql(createDDL);
//2.注册自定义表函数
tableEnv.createTemporarySystemFunction("MySplit", MySplit.class);
//3.调用UDF进行查询转换
Table resultTable = tableEnv.sqlQuery("select user,url,word,length"+
" from clickTable,LATERAL TABLE( MySplit(url)) AS T(word,length)");
//4.转换成流打印输出
tableEnv.toDataStream(resultTable).print();
env.execute();
}
//实现一个自定义的表函数
//以?作为拆分
public static class MySplit extends TableFunction<Tuple2<String,Integer>>{
public void eval(String str){
String[] fields = str.split("\\?");
for (String field : fields) {
collect(Tuple2.of(field,field.length()));
}
}
}
}
结果
+I[Mary, ./home, ./home, 6]
+I[Alice, ./cart, ./cart, 6]
+I[Bob, ./prod?id=100, ./prod, 6]
+I[Bob, ./prod?id=100, id=100, 6]
+I[Bob, ./cart, ./cart, 6]
+I[Bob, ./home, ./home, 6]
+I[Mary, ./home, ./home, 6]
+I[Bob, ./cart, ./cart, 6]
+I[Bob, ./home, ./home, 6]
+I[Bob, ./prod?id=10, ./prod, 6]
+I[Bob, ./prod?id=10, id=10, 5]
+I[Bob, ./prod?id=10, ./prod, 6]
+I[Bob, ./prod?id=10, id=10, 5]
+I[Bob, ./prod?id=10, ./prod, 6]
+I[Bob, ./prod?id=10, id=10, 5]
+I[Bob, ./prod?id=10, ./prod, 6]
+I[Bob, ./prod?id=10, id=10, 5]
Process finished with exit code 0
11.7.5 聚合函数
- 概述

自定义聚合函数需要继承抽象类AggregateFunction<T,ACC>,T表示聚合输出的结果类型,ACC则表示聚合的中间状态
重写createAccumulator()和getValue(),自己设置accumulate(中间聚合结果类型,传进来的参数1,传进来的参数2)的聚合方法
- 代码
public class UdfTest_AggregateFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//1. 在创建表的DDL中直接定义时间属性
String createDDL = "CREATE TABLE clickTable (" +
" `user` STRING, " +
" url STRING, " +
" ts BIGINT," +
" et AS TO_TIMESTAMP(FROM_UNIXTIME(ts/1000))," +//TO_TIMESTAMP要String,使用FROM_UNIXTIME转成string传入,ts/1000是秒
" WATERMARK FOR et AS et - INTERVAL '1' SECOND " +//水位线
" ) WITH (" +
" 'connector' = 'filesystem'," +
" 'path' = 'input/clicks.csv'," +
" 'format' = 'csv'" +
") ";
tableEnv.executeSql(createDDL);
//2.注册自定义聚合函数
tableEnv.createTemporarySystemFunction("WeightedAverage", WeightedAverage.class);
//3.调用UDF进行查询转换
Table resultTable = tableEnv.sqlQuery("select user,WeightedAverage(ts,1) as w_avg " +
"from clickTable group by user");
//4.转换成流打印输出
tableEnv.toChangelogStream(resultTable).print();
env.execute();
}
//单独定义一个累加器类型POJO
public static class WeightedAvgAccumulator{
public long sum = 0;
public int count =0;
}
//实现一个自定义的聚合函数,计算加权平均数
//以?作为拆分
public static class WeightedAverage extends AggregateFunction<Long,WeightedAvgAccumulator> {
//1.new 一个POJO类
@Override
public WeightedAvgAccumulator createAccumulator() {
return new WeightedAvgAccumulator();
}
//3.判断后输出
@Override
public Long getValue(WeightedAvgAccumulator accumulator) {
if(accumulator.count==0)
return null;
else
return accumulator.sum /accumulator.count;
}
//2.累积计算的方法
public void accumulate(WeightedAvgAccumulator accumulator,Long iValue,Integer iWeight){
accumulator.sum+=iValue*iWeight;
accumulator.count+=iWeight;
}
}
}
结果
+I[Mary, 1000]
+I[Alice, 2000]
+I[Bob, 3000]
-U[Bob, 3000]
+U[Bob, 3500]
-U[Bob, 3500]
+U[Bob, 4000]
-U[Mary, 1000]
+U[Mary, 3500]
-U[Bob, 4000]
+U[Bob, 4750]
-U[Bob, 4750]
+U[Bob, 5400]
-U[Bob, 5400]
+U[Bob, 6000]
-U[Bob, 6000]
+U[Bob, 6714]
-U[Bob, 6714]
+U[Bob, 7500]
-U[Bob, 7500]
+U[Bob, 8333]
11.7.6 表聚合函数
- 概述
自定义表聚合函数需要继承抽象类TableAggregateFunction<T,ACC>,两个泛型,T表示输出,ACC表示累加器来聚合中间结果
需要实现三个方法createAccumulator()创建累加器,accumulate()聚合方法,emitValue()输出结果方法(只能手动写)或者emitUpdateWithRetract()方法
- 代码
实现Top2
public class UdfTest_TableAggregateFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//1. 在创建表的DDL中直接定义时间属性
String createDDL = "CREATE TABLE clickTable (" +
" `user` STRING, " +
" url STRING, " +
" ts BIGINT," +
" et AS TO_TIMESTAMP(FROM_UNIXTIME(ts/1000))," +//TO_TIMESTAMP要String,使用FROM_UNIXTIME转成string传入,ts/1000是秒
" WATERMARK FOR et AS et - INTERVAL '1' SECOND " +//水位线
" ) WITH (" +
" 'connector' = 'filesystem'," +
" 'path' = 'input/clicks.csv'," +
" 'format' = 'csv'" +
") ";
tableEnv.executeSql(createDDL);
//2.注册自定义聚合函数
tableEnv.createTemporarySystemFunction("Top2", Top2.class);
//3.调用UDF进行查询转换
String windowAggQuery = "SELECT user,COUNT(url) AS cnt,window_start,window_end " +
"FROM TABLE(TUMBLE(TABLE clickTable,DESCRIPTOR(et),INTERVAL '10' SECOND))" +
" GROUP BY user,window_start,window_end";
Table aggTable = tableEnv.sqlQuery(windowAggQuery);
Table resultTable = aggTable.groupBy($("window_end"))
//传入的参数
.flatAggregate(call("Top2", $("cnt")).as("value", "rank"))
.select($("window_end"), $("value"), $("rank"));
//4.转换成流打印输出
tableEnv.toChangelogStream(resultTable).print();
env.execute();
}
//单独定义一个累加器类型,包含了当前最大和第二大的数据
public static class Top2Accumulator {
public Long max;
public Long secondMax;
}
//实现一个自定义的表聚合函数
public static class Top2 extends TableAggregateFunction<Tuple2<Long, Integer>, Top2Accumulator> {
@Override
public Top2Accumulator createAccumulator() {
Top2Accumulator top2Accumulator = new Top2Accumulator();
//定义初值值,因为上面设置的时候没有定义,定义成长整型的最小值
top2Accumulator.max=Long.MIN_VALUE;
top2Accumulator.secondMax= Long.MAX_VALUE;
return top2Accumulator;
}
//自己定义一个更新累加器的方法
public void accumulate(Top2Accumulator accumulator,Long value){
if(value>accumulator.max){
accumulator.secondMax=accumulator.max;
accumulator.max = value;
}else if(value>accumulator.secondMax){
accumulator.secondMax=value;
}
}
//输出结果,当前的top2
public void emitValue(Top2Accumulator accumulator, Collector<Tuple2<Long, Integer>> out){
//不等于,表示改变过了,才输出
if(accumulator.max!=Long.MIN_VALUE){
out.collect(Tuple2.of(accumulator.max,1));
}if(accumulator.secondMax!=Long.MIN_VALUE){
out.collect(Tuple2.of(accumulator.secondMax,2));
}
}
}
}
结果
+I[1970-01-01T08:00:10, 2, 1]
-D[1970-01-01T08:00:10, 2, 1]
+I[1970-01-01T08:00:10, 2, 1]
+I[1970-01-01T08:00:10, 1, 2]
-D[1970-01-01T08:00:10, 2, 1]
-D[1970-01-01T08:00:10, 1, 2]
+I[1970-01-01T08:00:10, 6, 1]
+I[1970-01-01T08:00:10, 2, 2]
+I[1970-01-01T08:00:20, 3, 1]
Process finished with exit code 0
11.8 SQL客户端
- 启动

大松鼠好可爱呀 我想喂它吃松果,因为我也想吃松果了,我分一些给它
- 设置
- 表环境的运行时模式,有流处理和批处理两个选项
Flink SQL> SET 'execution.runtime-mode' = 'streaming';
- 表环境的运行时模式,有流处理和批处理两个选项
SQL 客户端的“执行结果模式”,主要有 table、changelog、tableau 三种
- 设置空闲状态生存时间(TTL)
Flink SQL> SET 'table.exec.state.ttl' = '1000';
- 案例
Flink SQL> CREATE TABLE EventTable(
> user STRING,
> url STRING,
> `timestamp` BIGINT
> ) WITH (
> 'connector' = 'filesystem',
> 'path' = 'events.csv',
> 'format' = 'csv'
> );
Flink SQL> CREATE TABLE ResultTable (
> user STRING,
> cnt BIGINT
> ) WITH (
> 'connector' = 'print'
> );
Flink SQL> INSERT INTO ResultTable SELECT user, COUNT(url) as cnt FROM EventTable
GROUP BY user;
11.9 连接到外部系统
11.9.1 输出到控制台
- sql脚本
CREATE TABLE ResultTable (
user STRING,
cnt BIGINT
WITH (
'connector' = 'print'
);
11.9.2 Kafka
- 引入依赖
- 连接器的依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
- 格式依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
- 创建连接器表
CREATE TABLE KafkaTable (
`user` STRING,
`url` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',-- 连接器
'topic' = 'events',-- 主题
'properties.bootstrap.servers' = 'localhost:9092',-- 服务器
'properties.group.id' = 'testGroup',-- 消费者组
'scan.startup.mode' = 'earliest-offset',-- 起始位置偏移量
'format' = 'csv'
)
- Upsert Kafka
可以支持更新的表操作的连接器
CREATE TABLE pageviews_per_region (
user_region STRING,
pv BIGINT,
uv BIGINT,
PRIMARY KEY (user_region) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka', -- 连接器改成upsert-kafka
'topic' = 'pageviews_per_region',
'properties.bootstrap.servers' = '...',
'key.format' = 'avro',-- 两个一个key
'value.format' = 'avro'-- 一个value
);
-- 计算 pv、uv 并插入到 upsert-kafka 表中
INSERT INTO pageviews_per_region
SELECT
user_region,
COUNT(*),
COUNT(DISTINCT user_id)
FROM pageviews
GROUP BY user_region;
11.9.3 文件系统
- sql脚本
CREATE TABLE MyTable (
column_name1 INT,
column_name2 STRING,
...
part_name1 INT,
part_name2 STRING
) PARTITIONED BY (part_name1, part_name2) WITH (
'connector' = 'filesystem', -- 连接器类型
'path' = '...', -- 文件路径
'format' = '...' -- 文件格式
)
11.9.4 JDBC
- 引入依赖
- JDBC连接器
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
- MYSQL驱动
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
- sql脚本
-- 创建一张连接到 MySQL 的 表
CREATE TABLE MyTable (
id BIGINT,
name STRING,
age INT,
status BOOLEAN,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/mydatabase',
'table-name' = 'users' -- 数据库中真实的表
);
-- 将另一张表 T 的数据写入到 MyTable 表中
INSERT INTO MyTable
SELECT id, name, age, status FROM T;
11.9.5 连接到Elasticsearch
- 引入依赖
- Es连接器
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
- sql脚本
-- 创建一张连接到 Elasticsearch 的 表
CREATE TABLE MyTable (
user_id STRING,
user_name STRING
uv BIGINT,
pv BIGINT,
PRIMARY KEY (user_id) NOT ENFORCED -- 主键才能用Upsert模式向es写入数据
) WITH (
'connector' = 'elasticsearch-7',-- 这边改成es的连接器
'hosts' = 'http://localhost:9200',
'index' = 'users'
);
11.9.6 Hbase
- 引入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hbase-2.2_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
- sql脚本
-- 创建一张连接到 HBase 的 表
CREATE TABLE MyTable (
rowkey INT,-- 原子类型也就是基本类型会被识别成rowkey
family1 ROW<q1 INT>,
family2 ROW<q2 STRING, q3 BIGINT>,
family3 ROW<q4 DOUBLE, q5 BOOLEAN, q6 STRING>,
PRIMARY KEY (rowkey) NOT ENFORCED
) WITH (
'connector' = 'hbase-1.4',-- 版本,仅支持1.4和2.2
'table-name' = 'mytable',-- 表名
'zookeeper.quorum' = 'localhost:2181'-- 集群
);
-- 假设表 T 的字段结构是 [rowkey, f1q1, f2q2, f2q3, f3q4, f3q5, f3q6]
INSERT INTO MyTable
SELECT rowkey, ROW(f1q1), ROW(f2q2, f2q3), ROW(f3q4, f3q5, f3q6) FROM T;
11.9.7 Hive
- 概述
使用HiveCatalog的hive目录使用元数据(Metastore)管理Flink元数据
特点
- Metastore可以持久化,因此是跨会话存储Flink的元数据,因此可以不建表,直接用
- 使用Flink作为计算引擎
- 阿里内部的Blink计划器提供了hive的支持,即Blink planner
- 引入依赖
- 版本支持
Hive 1.x:1.0.0~1.2.2;
Hive 2.x:2.0.0~2.2.0,2.3.0~2.3.6;
Hive 3.x:3.0.0~3.1.2;
- 依赖
<!-- Flink 的 Hive 连接器-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Hive 依赖 -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
</dependency>
- 连接hive
- 配置HiveCatalog
EnvironmentSettings settings =
EnvironmentSettings.newInstance().useBlinkPlanner().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
String name = "myhive";
String defaultDatabase = "mydatabase";
String hiveConfDir = "/opt/hive-conf";
// 创建一个 HiveCatalog,并在表环境中注册
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir);
tableEnv.registerCatalog("myhive", hive);
// 使用 HiveCatalog 作为当前会话的 catalog
tableEnv.useCatalog("myhive");
或者sql客户端配置
Flink SQL> create catalog myhive with ('type' = 'hive', 'hive-conf-dir' =
'/opt/hive-conf');
[INFO] Execute statement succeed.
Flink SQL> use catalog myhive;
[INFO] Execute statement succeed.
- 设置SQ方言
- 通过配置 table.sql-dialect 属性来设置 SQL 方言(客户端/代码)
set table.sql-dialect=hive;
- 配置文件同步才能使用sql客户端设置方言
在配置文件 sql-cli-defaults.yaml 中通过“configuration”模块
execution:
planner: blink
type: batch
result-mode: table
configuration:
table.sql-dialect: hive
- 还可以Table API 设置
// 配置 hive 方言
tableEnv.getConfig().setSqlDialect(SqlDialect.HIVE);
// 配置 default 方言
tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);
- 读写Hive表
- sql脚本
-- 设置 SQL 方言为 hive,创建 Hive 表
SET table.sql-dialect=hive;
-- 建表用hive语法
CREATE TABLE hive_table (
user_id STRING,
order_amount DOUBLE
) PARTITIONED BY (dt STRING, hr STRING) STORED AS parquet TBLPROPERTIES (
371
'partition.time-extractor.timestamp-pattern'='$dt $hr:00:00',
'sink.partition-commit.trigger'='partition-time',
'sink.partition-commit.delay'='1 h',
'sink.partition-commit.policy.kind'='metastore,success-file'
);
-- 设置 SQL 方言为 default(使用flinksql写),创建 Kafka 表
SET table.sql-dialect=default;
CREATE TABLE kafka_table (
user_id STRING,
order_amount DOUBLE,
log_ts TIMESTAMP(3),
WATERMARK FOR log_ts AS log_ts - INTERVAL '5' SECOND – 定义水位线
) WITH (...);
-- 将 Kafka 中读取的数据经转换后写入 Hive
INSERT INTO TABLE hive_table
SELECT user_id, order_amount, DATE_FORMAT(log_ts, 'yyyy-MM-dd'),
DATE_FORMAT(log_ts,s, 'HH')
FROM kafka_table;
12 Flink CEP
12.1 基本概念
- 概述
类似的多个事件的组合,我们把它叫做“复杂事件”,负责事件处理(Complex Event Processing)缩写就是CEP ,是一个Flink实现负责事件处理的库
复杂事件:例如“连续登录失败”,“订单支付超时”
核心思想:把事件流中的一个个简单事件,通过一定的规则匹配组合起来,就是“复杂事件”,然后基于这些满足规则的一组组复杂事件进行转换处理,得到需要输出的结果
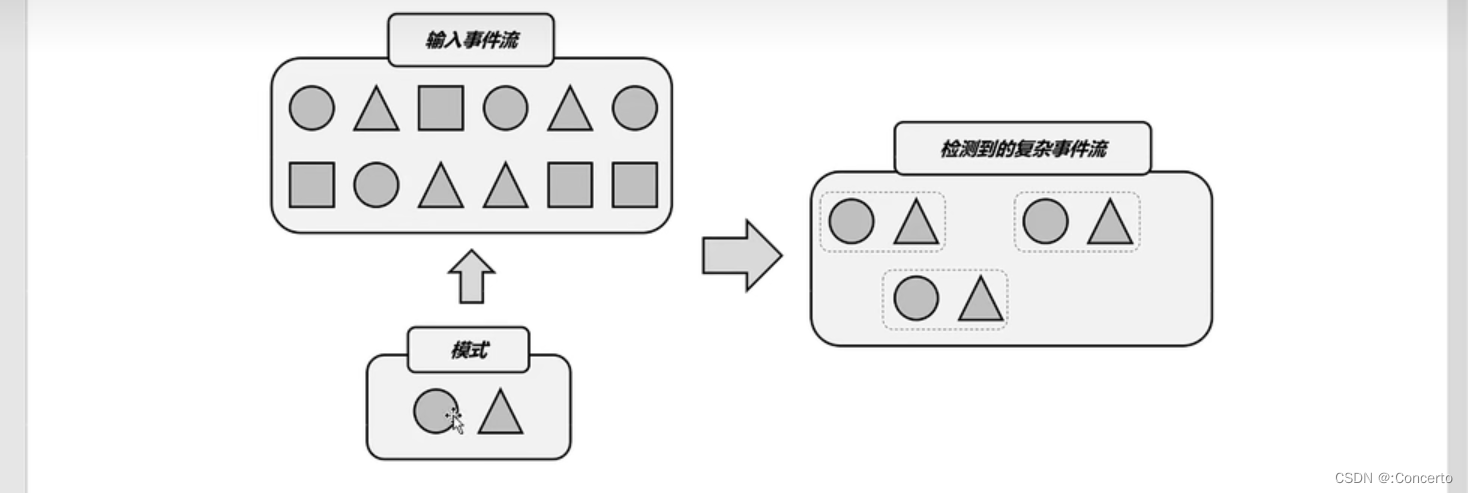
- 应用场景
- 风险控制
- 用户画像
- 运维监控
13 其他补充
13.1 自定义MysqlSink补充
- 核心代码
- App类
public class KafkaFlinkMySQL {
public static void main(String[] args) throws Exception {
//获取flink执行环境
StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
senv.getConfig().setAutoWatermarkInterval(200);
//source段和transform省略,着重体现sink
//数据入库MySQL
newsCounts.addSink(new MySQLSink());
}
- mysql配置
public class GlobalConfig {
public static final String DRIVER_CLASS="com.mysql.jdbc.Driver";
public static final String DB_URL="jdbc:mysql://hadoop1:3306/live?useUnicode=true&characterEncoding=UTF8&useSSL=false";
public static final String USER_MAME = "hive";
public static final String PASSWORD = "hive";
public static String AUDITINSERTSQL = "insert into auditcount (time,audit_type,province_code,count) VALUES (?,?,?,?) ON DUPLICATE KEY UPDATE time=VALUES(time),audit_type=VALUES(audit_type),province_code=VALUES(province_code),count=VALUES(count)";
}
- mysql自定义的MySQLSink
//继承RichSinkFunction接口
public class MySQLSink extends RichSinkFunction<Tuple2<String,Integer>> {
private Connection conn;
private PreparedStatement statement;
@Override
public void open(Configuration parameters) throws Exception {
Class.forName(GlobalConfig.DRIVER_CLASS);
conn = DriverManager.getConnection(GlobalConfig.DB_URL,GlobalConfig.USER_MAME,GlobalConfig.PASSWORD);
}
//关闭资源来着的
@Override
public void close() throws Exception {
if(statement !=null){
statement.close();
}
if(conn!=null){
conn.close();
}
}
//重写invoke()方法
@Override
public void invoke(Tuple2<String, Integer> value, Context context) throws Exception {
try {
//去掉[]
String name = value.f0.replaceAll("[\\[\\]]", "");
int count = value.f1;
System.out.println("name="+name+":count="+count);
//指定sql
String sql = "select 1 from newscount " + " where name = '" + name + "'";
String updateSql = "update newscount set count = " + count + " where name = '" + name + "'";
String insertSql = "insert into newscount(name,count) values('" + name + "'," + count + ")";
//jdbc固定写法喽
statement = conn.prepareStatement(sql);
ResultSet rs = statement.executeQuery();
if (rs.next()) {
//如果查询有数据,那就更新
statement.executeUpdate(updateSql);
} else {
//如果查询没有数据,那就插入
statement.execute(insertSql);
}
//捕捉异常
}catch (Exception e){
e.printStackTrace();
}
}
}
13.2 checkpoint容错和检查点补充
- 概念
- 状态和容错
State代表某个时刻operator(一般指的是算子)的状态,而checkpoint代表某个时刻整个job很多个operator的状态,可以理解为checkpoint是对state数据进行持久化存储
- checkpoint机制
- 全局性快照/异步性快照/周期性快照
- 序列化数据集合
- 全量checkpoint也可以是增量checkpoint
一种连续性绘制数据流状态的机制(周期性的),该机制确保即使出现故障,程序的状态最终也将为数据流中的每一条记录提供exactly once的语意保证(只能保证flink 系统内,对于sink 和 source 需要依赖的外部的组件一同保证)
注意:可以通过开关启用at least once语意保证;Checkpoint是通过分布式snapshot(异步快照)实现的,没有特殊说明时snapshot和checkpoint和back-up是一个意思。
- 配置checkpoint
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 每隔1000 ms进行启动一个检查点【设置checkpoint的周期】
env.enableCheckpointing(1000);
// 高级选项:
// 设置模式为exactly-once (这是默认值)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 确保检查点之间有至少500 ms的间隔【checkpoint最小间隔】
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// 检查点必须在一分钟内完成,否则被丢弃【checkpoint的超时时间】
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 同一时间只允许进行一个检查点
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
- 状态后端设置
















 888
888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









