






在人工智能和机器学习领域,NVIDIA 公司凭借其 CUDA 计算生态系统和高性能 GPU 架构,已成为大型语言模型(LLM)训练与推理的主导力量。从基础实验到前沿研究,NVIDIA 的技术方案几乎成为了行业标准。作为其主要竞争对手,AMD(YES!)在 AI 计算领域的发展潜力值得关注。
AMD 在 CPU 和 GPU 市场已深耕多年。在处理器领域,AMD 不仅与英特尔形成有效竞争,近期在数据中心市场份额方面甚至实现了超越。而在 GPU 领域,尽管 AMD 主要聚焦于中端游戏市场,提供了一系列性价比优异的高性能显卡,但在 AI 计算特别是 LLM 推理方面,专业技术文档与实施指南相对匮乏,这制约了开发者充分利用 AMD 硬件进行 AI 开发。

本文以 AMD Radeon RX 7900XT 为例,RX 7900XT 配备 5376 个流处理器(与 CUDA 核心在概念上相似但架构不同)和 20GB GDDR6 显存(320 位总线宽度)。我们将在 Linux 环境下解决了 ROCm 部署的诸多技术挑战。
系统架构与环境配置
本文采用的 LLM 部署架构基于 ROCm + Ollama + Open WebUI 技术栈以下配置步骤会因目标平台特性(如操作系统版本)而略有差异。本文主要以Linux 环境为例,适用于大多数基于 Ubuntu/Debian 的发行版。对于其他 Linux 发行版,请参考相应的软件包管理与系统配置命令。
1、GPU 驱动与 ROCm 环境配置
安装 GPU 驱动是硬件升级后的首要任务。除了基本显卡驱动外,还需要安装 AMD 的 Radeon Open Compute Platform (ROCm),这是 Ollama 在 GPU 上执行推理任务的基础环境,类似于 NVIDIA 的 CUDA 平台。
首先,需确定 ROCm 版本与 GPU 型号及 Linux 内核的兼容性。可通过以下命令查看当前内核版本:
$ uname-r
6.6.0-30-generic
根据 ROCm 兼容性文档,对于上述内核版本,ROCm 6.2.x 系列最为适合。经过测试,ROCm 6.2.1 提供了最稳定的性能表现。可从官方仓库下载
amdgpu-install
工具:
wget https://repo.radeon.com/amdgpu-install/6.2.1/ubuntu/jammy/amdgpu-install_6.2.60201-1_all.deb
sudo apt-get install ./amdgpu-install_6.1.60103-1_all.deb
使用以下参数执行安装脚本,完成驱动及开发环境的配置:
sudo amdgpu-install --usecase=dkms,graphics,multimedia,rocm,rocmdev,opencl,openclsdk,hip,hiplibsdk
安装过程中可能出现各类兼容性警告或错误,需针对具体情况查找解决方案。例如,常见的 gcc 版本兼容性问题(“gcc version does not match version that built latest default kernel”)可能需要切换到特定版本的编译器:
$ gcc-v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/12/lto-wrapper
OFFLOAD_TARGET_NAMES=nvptx-none:amdgcn-amdhsa
OFFLOAD_TARGET_DEFAULT=1
Target: x86_64-linux-gnu
...
Thread model: posix
Supported LTO compression algorithms: zlib zstd
gcc version 12.3.0 (Ubuntu 12.3.0-1ubuntu1~22.04)
2、驱动验证与环境测试
成功安装驱动和 ROCm 后,重启系统并执行一系列基本验证,确认环境配置正确:
验证当前显示驱动状态(注意
driver=amdgpu
标识):
$ sudo lshw -C display
*-display
description: VGA compatible controller
product: Navi 31 [Radeon RX 7900 XT/7900 XTX/7900 GRE/7900M]
vendor: Advanced Micro Devices, Inc. [AMD/ATI]
physical id: 0
bus info: pci@0000:08:00.0
logical name: /dev/fb0
version: cc
width: 64 bits
clock: 33MHz
capabilities: pm pciexpress msi vga_controller bus_master cap_list rom fb
configuration: depth=32driver=amdgpu latency=0resolution=3440,1440
resources: irq:102 memory:d0000000-dfffffff memory:e0000000-e01fffff ioport:e000(size=256) memory:fc900000-fc9fffff memory:c0000-dffff
验证内核驱动模块状态:
$ dkms status
amdgpu/6.8.5-2038383.22.04, 6.8.0-40-generic, x86_64: installed (original_module exists)
amdgpu/6.8.5-2038383.22.04, 6.8.0-52-generic, x86_64: installed (original_module exists)
验证 GPU 设备识别状态(GPU 应作为代理 2 被正确识别):
$ rocminfo
ROCk module version 6.8.5 is loaded
=====================
HSA System Attributes
=====================
Runtime Version: 1.14
Runtime Ext Version: 1.6
System Timestamp Freq.: 1000.000000MHz
Sig. Max Wait Duration: 18446744073709551615 (0xFFFFFFFFFFFFFFFF) (timestamp count)
Machine Model: LARGE
System Endianness: LITTLE
Mwaitx: DISABLED
DMAbuf Support: YES
...
*******
Agent 2
*******
Name: gfx1100
Uuid: GPU-c6f8040818892811
Marketing Name: Radeon RX 7900 XT
Vendor Name: AMD
Feature: KERNEL_DISPATCH
Profile: BASE_PROFILE
Float Round Mode: NEAR
Max Queue Number: 128(0x80)
Queue Min Size: 64(0x40)
Queue Max Size: 131072(0x20000)
Queue Type: MULTI
Node: 1
Device Type: GPU
...
验证 OpenCL 平台识别状态:
$ clinfo
Number of platforms: 1
Platform Profile: FULL_PROFILE
Platform Version: OpenCL 2.1 AMD-APP (3625.0)
Platform Name: AMD Accelerated Parallel Processing
Platform Vendor: Advanced Micro Devices, Inc.
Platform Extensions: cl_khr_icd cl_amd_event_callback
Platform Name: AMD Accelerated Parallel Processing
Number of devices: 1
Device Type: CL_DEVICE_TYPE_GPU
Vendor ID: 1002h
Board name: Radeon RX 7900 XT
Device Topology: PCI[ B#8, D#0, F#0 ]
Max compute units: 42
Max work items dimensions: 3
Max work items[0]: 1024
Max work items[1]: 1024
Max work items[2]: 1024
Max work group size: 256
...
3、GPU 性能监控工具
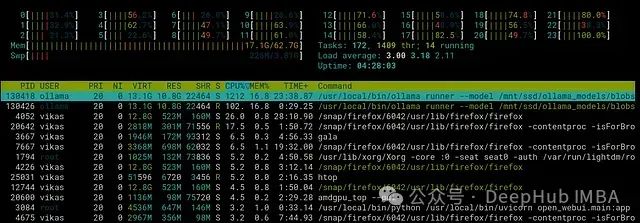
在运行 LLM 时,实时监控 GPU 资源使用情况对于性能优化和系统稳定性至关重要。这些数据可以帮助确定模型层的 GPU 卸载策略,优化内存使用和功耗控制。在 Linux 环境下,
amdgpu_top
是一款基于 Rust 开发的专业监控工具,可提供 AMD GPU 的全面运行指标。通过
cargo
包管理器可以便捷安装:
推荐以图形界面模式运行:
amdgpu_top --gui
amdgpu_top 运行界面。左侧显示设备信息,右侧实时更新性能指标。

LLM 生成响应时 GPU 负载状态,峰值功耗约 281W。
4、Ollama 与 Open WebUI 部署
Ollama 安装流程很简单,关键在于确保系统正确识别 AMD ROCm 环境并下载相应版本:
$ curl -fsSL https://ollama.com/install.sh | sh
>>> Cleaning up old version at /usr/local/lib/ollama
[sudo] password for vikas:
>>> Installing ollama to /usr/local
>>> Downloading Linux amd64 bundle
######################################################################## 100.0%
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
>>> Downloading Linux ROCm amd64 bundle
######################################################################## 100.0%
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
>>> AMD GPU ready.
验证 Ollama 后台服务运行状态,确保 API 可正常访问:
$ sudo systemctl status ollama.service
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; vendor preset: enabled)
Drop-In: /etc/systemd/system/ollama.service.d
└─override.conf
Active: active (running) since Sat 2025-04-05 08:45:05 CEST; 1 day 7h ago
Main PID: 2857 (ollama)
Tasks: 29 (limit: 76822)
Memory: 12.3M
CPU: 2h 19min 29.139s
CGroup: /system.slice/ollama.service
└─2857 /usr/local/bin/ollama serve
Ollama 的默认 API 地址为 http://127.0.0.1:11434,作为下一步 Open WebUI 配置的输入参数。
Open WebUI 是一款功能完善的 LLM 前端界面,通过 Docker 容器可快速部署:
docker pull ghcr.io/open-webui/open-webui:main
docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
容器启动后,可通过 http://localhost:8080 访问 Open WebUI 界面。在局域网环境中,还可通过 http://<主机IP地址>:8080 从其他设备远程访问该界面。
性能评估
完成环境配置后,就可以通过基准测试评估 GPU 在 LLM 推理任务中的实际性能表现。我们使用
ollama-benchmark
Python 工具包进行系统化测试。该工具可通过创建模型配置文件测试多个模型的推理性能:
$ cat deepseek_r1_models.yaml
file_name: "deepseek_r1_models.yaml"
version: 1.0
models:
- model: "deepseek-r1:8b"
- model: "deepseek-r1:14b"
- model: "deepseek-r1:32b"
使用 Poetry 作为包管理器执行基准测试:
# 进入项目仓库目录
poetry install
poetry env activate
poetry run llm_benchmark run --custombenchmark=deepseek_r1_models.yaml
测试过程会先下载指定模型,然后依次执行预设的推理任务,最终返回平均推理速度(tokens/秒):
-------Linux----------
No GPU detected.
Total memory size : 31.24 GB
cpu_info: AMD Ryzen 9 5900X 12-Core Processor
gpu_info: Navi 31 [Radeon RX 7900 XT/7900 XTX/7900 GRE/7900M]
os_version: elementary OS 7.1 Horus
ollama_version: 0.5.12
----------
running custom benchmark from models_file_path: deepseek_r1_models.yaml
Disabling sendinfo for custom benchmark
LLM models file path:deepseek_r1_models.yaml
Checking and pulling the following LLM models
deepseek-r1:8b
deepseek-r1:14b
deepseek-r1:32b
----------
Running custom-model
model_name = deepseek-r1:8b
prompt = Summarize the key differences between classical and operant conditioning in psychology.
eval rate: 73.81 tokens/s
prompt = Translate the following English paragraph into Chinese and elaborate more -> Artificial intelligence is transforming various industries by enhancing efficiency and enabling new capabilities.
eval rate: 74.27 tokens/s
prompt = What are the main causes of the American Civil War?
eval rate: 73.83 tokens/s
prompt = How does photosynthesis contribute to the carbon cycle?
eval rate: 74.27 tokens/s
prompt = Develop a python function that solves the following problem, sudoku game.
eval rate: 72.41 tokens/s
--------------------
Average of eval rate: 73.718 tokens/s
----------------------------------------
model_name = deepseek-r1:14b
prompt = Summarize the key differences between classical and operant conditioning in psychology.
eval rate: 43.12 tokens/s
prompt = Translate the following English paragraph into Chinese and elaborate more -> Artificial intelligence is transforming various industries by enhancing efficiency and enabling new capabilities.
eval rate: 44.50 tokens/s
prompt = What are the main causes of the American Civil War?
eval rate: 43.86 tokens/s
prompt = How does photosynthesis contribute to the carbon cycle?
eval rate: 42.99 tokens/s
prompt = Develop a python function that solves the following problem, sudoku game.
eval rate: 40.75 tokens/s
--------------------
Average of eval rate: 43.044 tokens/s
----------------------------------------
model_name = deepseek-r1:32b
prompt = Summarize the key differences between classical and operant conditioning in psychology.
eval rate: 9.95 tokens/s
prompt = Translate the following English paragraph into Chinese and elaborate more -> Artificial intelligence is transforming various industries by enhancing efficiency and enabling new capabilities.
eval rate: 9.91 tokens/s
prompt = What are the main causes of the American Civil War?
eval rate: 9.91 tokens/s
prompt = How does photosynthesis contribute to the carbon cycle?
eval rate: 9.92 tokens/s
prompt = Develop a python function that solves the following problem, sudoku game.
eval rate: 9.39 tokens/s
--------------------
Average of eval rate: 9.816 tokens/s
----------------------------------------
测试结果表明,随着模型参数量增加,推理性能呈现明显下降趋势。对比 NVIDIA 硬件,RTX 5090 在 deepseek-r1:14b 模型上可达到约 122 tokens/秒的性能,远高于本文中测试的 AMD 显卡(43 tokens/秒)。然而,考虑到价格因素(RX 7900XT 约 700 欧元,而 RTX 5090 超过 2200 欧元),AMD 方案在性价比方面仍具有显著优势。从用户体验角度,任何超过 30 tokens/秒的推理速度已足以支持流畅的交互体验。
用户界面与实际应用
Open WebUI 提供了直观的操作界面。以下示例演示了使用 qwen2.5-coder:14b 模型作为数据科学辅助工具的实际场景,推理吞吐量约为 38 tokens/秒:

高级配置与优化
模型管理与下载
系统支持便捷的模型搜索与下载功能,可根据需求扩展本地模型库:

系统提示与参数调优
通过右上角的 Chat Controls(聊天控制)设置,可自定义系统提示,优化模型输出:
GPU 计算层配置
在同一设置面板底部的
num_gpu
参数可调整卸载到 GPU 的计算层数,影响性能与资源使用:

当
num_gpu
设置为 0 时,系统将完全依赖 CPU 执行推理计算。虽然这可能在功耗方面更为高效,但性能会有显著下降,如 deepseek-coder-v2 模型在 CPU 模式下仅能达到 12 tokens/秒,而 GPU 模式可达 60 tokens/秒:
总结
在 AMD 硬件上构建 LLM 推理环境目前仍面临一定技术挑战,尚未达到 NVIDIA CUDA 生态系统的即插即用水平。本文所述的工具链和配置方法,完全可以将现有的 AMD 游戏显卡转化为高效的 AI 推理设备。这种方案不仅在经济性上更具优势,还有助于推动 AI 硬件生态系统的多元化发展。
随着 AMD 持续完善 ROCm 平台,以及开源社区对非 NVIDIA 硬件的支持不断增强,基于 AMD GPU 的本地 LLM 部署方案将获得更广泛的应用。在 AI 技术日益普及的今天,能够在本地硬件上高效运行大型语言模型,为个人用户和小型组织提供了一种经济可行且不依赖云服务的 AI 实践路径。
https://avoid.overfit.cn/post/0f224faf731841ada57c3fcb134b2997
作者:Vikas Negi

















 1489
1489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









