







Pandas是python里分析结构数据化的工具集
基础是numpy:高性能矩阵运算
图形库matplotlib:提供数据可视化
创建关键数据结构
s = pd.Series([1,2,3,np.NaN,8,4])
data = pd.DataFrame(np.random.randn(6,4),index = dates,cloums = list(“ABCD”))
d = {“A”:1,“B”:2,“C”:rang(4),“D”:arange(4)}
data.head() #默认查看前5行,括号中参数就是行数
data.tail() #默认查看后五行,括号中参数就是行数
data.tail(3)
data.index #查看行标签
data.sort_index(axis=1,ascending=Fales) #按顺序排序,axis = 1是列标签,默认=0行标签,ascending=Fales是降序,True是升序
data.columes #查看列标签
data.T #转置
data.sort_values(by = “a”) #列标签a进行排序
读取文件:
1.csv,tsv,txt用逗号。tan分割的纯文本文件:pd.read_csv
2.excle微软xls或者xlsx文件:pd.read_excel
3.musql关系型数据库表:pd.read_sql
读取csv
读取txt文件
读取excel文件
读取mysql表:

Pandas数据结构:
1.DataFrame:二维数组,整个表格,多行多列

2。Series:是一种类似一位数组的对象,由一组数据(不同数据类型)以及一组与之相关的数据标签(索引)组成。:一维数据,一行或者一列,
Series和DataFrame搭配使用:DataFrame查询出一个区块,仍然是一个二维表格,那么仍然是DataFrame,但是如果结果是一列或者一行,那么他的结构就是Series。
创建Series的方法:
1.s = pd.Series([1,“a”,5.2,7]) #类似于列表
s.index #获取索引
s.values #获取元素值的列表
2.s = pd.Series([1,“a”,5.2,7],index = [“d”,“b”,“a”,“c”])
s
d 1
b a
a 5.2
c 7
dtype:object
3.s1 = {“a”:30,“b”:24,“c”:52}
s = pd.Series(s1)
s
a 30
b 24
c 52
dtype:object
根据标签索引查询数据
类似于python的dict
s = pd.Series([1,“a”,5.2,7],index = [“d”,“b”,“a”,“c”])
s[“a”]
5.2
s[[“b”,“a”]]
a,5.2
DataFrame:
和series不同,dataframe有行索引index也有列索引columns。
可以被看做是有series组成的字典,创建dataframe最常用的方法就是上面提到的读取纯文本文件,excel和mysql数据库。
根据多个字典序列创建dataframe。

df.dypes
state object
year int64
pop float64
dtype:object
df.columns
state,year,pop
df.index
start = 0,stop=5,step =1
dataframe中查询出series
查询列:
df[’'year"] #series,查询一类,返回的是行的索引
df[“year”,“pop”] #dataframe
查询行:
df.loc[1] #series,需要用到loc方法,返回的索引是列名
df.loc[1:3] #查询多行,这里需要注意,这里都是闭区间,也就是包含第三行。这也是一个dataframe
pandas如何对数据进行查询(df.loc的5种方法)
5种方法分别是按数值,列表,区间,条件,函数
Pandas的查询方法:
1.df.loc方法,根据行,列的标签值查询(.loc既能查询,又能覆盖写入,强烈推荐!!)
df.loc的5个查询数据的方法:
1.使用单个label值查询数据
2.使用值列表批量查询
3.使用数值区间进行范围查询
4.使用条件表达式查询
5.调用函数查询
以上的查询方法,适用于各个维度。既适用于行,也适用于列,注意观察降维dataframe>Series>值
数据:
df.set_index(“ymd”,inplace=“True”) #改变行名,由0-1-2-3-4.。。。改变成日期,inplace:True是直接改变这个df。
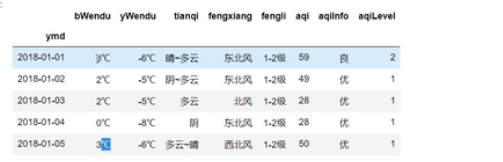
把bwendu列的数据进行处理:
df.loc[:,“bwendu”] = df[“bwendu”].str.replace(“℃”,"").sdtype(“int32”)
df.loc[:,“ywendu”] = df[“ywendu”].str.replace(“℃”,"").sdtype(“int32”)
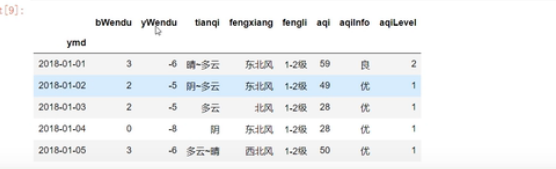
正题开始:
1.使用单个label值查询数据:行或者列,都可以值传入单个值,事先精准匹配
df.loc[“2018-01-03”,“bWendu”]
2
df.loc[“2018-01-03”,][“bWendu”,“yWendu”]
bWendu 2
yWendu -5
Name:2018-01-03,dtype:object
2.使用值列表进行批量查询
df.loc[[“2018-01-03”,“2018-01-04”,“2018-01-05”],[“bWendu”,“yWendu”]]
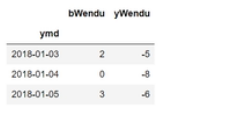
3.使用数值区间进行范围查询
df.loc[“2018-01-03”:“2018-01-05”,“bWendu”]

4.使用条件表达式查询,返回的是bool类型的数组,bool列表的长度等于行数或者列数。
例子1.查询全年最低温度低于-10度的列表:
df.loc[df[“bWendu”]<-10,:] #这个series传入df以后,只会返回结果为True的数据.后面的:表示从索引取所有行
观察返回的series,左侧返回的是ymd,右侧返回的是bool类型。


例子2.查询我心中的完美天气:
df.loc[(df[dWendu]>15)&(df[yWendu]<30)&(df[“tianqi”] == “晴”)&(df[“aqiLevel”] == 1),:]

5.调用函数查询
df.loc[lambda df :(df[“bWendu”]<=30)&df[“yWendu”]>=15,:]


2.df.iloc方法,根据行,列的数字位置查询
3.df.where方法(比较高级)
4.df.query方法(比较高级)
python新增数据列(直接赋值,apply,assign,分条件赋值)
pandas怎样新增数据列:
在进行数据分析时,经常按照一定条件创建新的数据列,然后进行进一步的分析。
直接赋值
apply:df.apply
assign:df,assign
分条件赋值:按条件选择分组分别赋值

1.直接赋值法(在上一小节,已经处理温度的时候,想把3℃变成int类型,这种方法就是直接赋值):
df.loc[:,“bWendu”] = df[“bWendu”],str,replace(“℃”,"").astype(“int32”) #df.loc[:,“bWendu”]选择所有行数的bWendu这列,等于最低温度这一列的str形式的replace函数(这个函数是把逗号后面的“”中数据替换成前面的“”中的数据)。最后astype(转换类型,类型为astype后面引号中的数据类型)
df,loc[:,“yWendu”] = df[“yWendu”],str,replace(“℃”,"").astype(“int32”)
df.head()

df.loc[:,“wencha”] = df[“bWendu”] - df[“yWendu”]
#注意。df[“bWendu”]其实是一个Series,后面的减法返回的是Series。
df.head()

2.df.apply()
沿着df的某个轴,应用了一个函数,传入给函数的对象,是一个Series,这个Series 要么是df的index(axis = 0),要么是cloumns(axis = 1)
df.loc[:,“wendu_type”] = df.apply(get_wendu_type,axis = 1)
实例:添加一列温度类型:
def get_wendu_type(x):
if x[“bWendu”]>33:
return “高温”
elif x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 641
641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









