







ResNeXt论文总结
摘要:
主要内容:
本文工作: 我们提出了一种用于图像分类的简单、高度模块化的网络架构。该网络通过反复堆叠Building Block实现,Building Block则通过聚集简洁的卷积模块来实现。
本文方法: 本文提出一个与网络宽度和深度类似作用的参数,用来衡量网络大小,称之为Cardinality基数(转换集的大小)。
本文优点: 该网络具有相同的、多分支的结构,并且对应的超参数非常少。
本文结论:
(1)ImageNet-1K数据集上,不增加模型复杂度,增加Cardinality可以提升网络性能。
(2)增加Cardinality比增加网络深度和宽度可以更好的提升网络模型的性能。
本文成果: ILSVRC 2016分类任务获得了第二名。
Introduction:
之前方法:
深度研究
VGG: 结构简洁, 堆叠使用3*3卷积。
不足:但是随着层数增多,出现梯度消失问题
ResNet: 堆叠的Building Block采用残差结构,用跨层连接缓解了这个问题,使得网络可以达到上千层。
不足:但是模型的参数量巨大
宽度研究
Inception系列:采用多分支结构Split- Transform-Merge(分割-变换-聚合)
1) Split:将向量x分成低维嵌入表示;(由1x1卷积降维)
2) Transform:每个低维特征经过一个线性变换;(再由3x3或者5x5的卷积进一步提取特征)
3) Merge:通过单位加合成最后的输出;(最后拼接各分支的特征)
不足:但是每个映射变换要量身定制卷积核数量、尺寸,模块在每一阶段都要改变。尤其将 Inception 模型用于新的数据或者任务时如何修改并不清晰。(Inception模型理论设计过于复杂,使用于新的数据集时,调参困难度大)
本文改进:
提出了一个简单的架构,采用与VGG/Resnet重复相同网络层的策略,以一种简单可扩展的方式延续Split- Transform-Merge策略,将Resnet中高维特征图分组为多个低维特征图,然后再卷积操作之后,将多组结构进行求和,最后得到ResneXt模型
模型设计的两个原则:
(1)如果输出的空间尺寸一样,那么模块的超参数(宽度和卷积核尺寸)也是一样的。
(2)每当空间分辨率/2(降采样),则卷积核的宽度*2。这样保持模块计算复杂度
作用:
这两条规则大大缩小设计空间,让我们专注于ResNeXt-50(32X4d)
32指进入网络的第一个ResNexT基本结构的分组C为32
4d表示depth即每一个分组的通道数为4(所以第一个基本结构输入通道数为128)
可以看出ResneXt和Resnet参数相同,但是精度却更高
单个神经元:
单个神经元是构建全连接和卷积层网络的基础元素
具体操作:
分割(Splitting): 把输入x分解为D个元素,可以理解为低维嵌入。
变换(Transforming): 每个元素进行变换,乘权重wi进行缩放。
聚合(Aggregating): 对D个变换后的结果进行求和。
Block中的聚合变换:
公式表示:
对于一个ResNeXt Block中的基数块输出可以表示为:
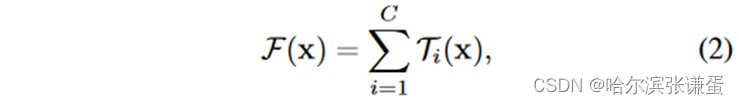
其中,参数C 代表基数块的数目,Ti 代表对应的基数块,将x投影到一个(可选的低维)集成中,然后对其进行变换。
这拓展了VGG设计原则:从重复相同大小的层,到重复相同拓扑的卷积核组。
在本文中,我们考虑一种设计变换函数的简单方法:所有的Ti都有相同的拓扑结构。
在这种情况下,每个Ti中的第一个1×1层产生低维嵌入。那么对应的残差网络输出就可以被表示为:
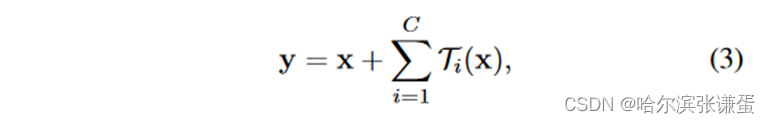
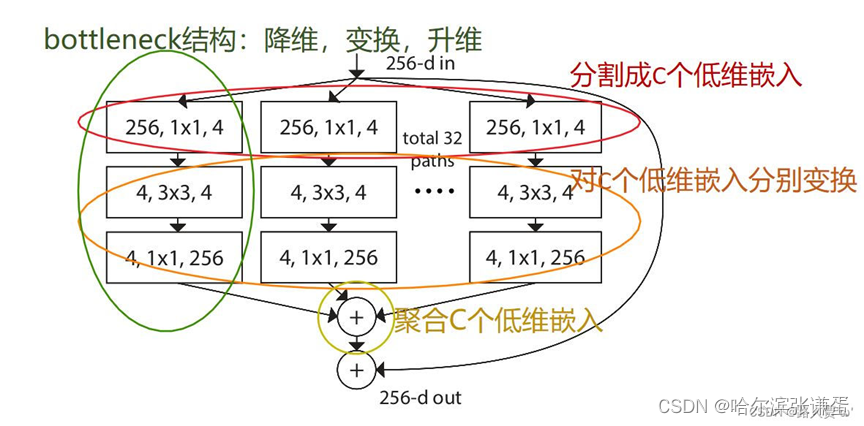
Splitting: 通过1×1卷积实现低维嵌入,256个通道变成4个通道,总共32个分支(cardinality = 32)
Transforming: 每个分支进行变换(对网络层对数据操作)
Aggregating: 对32个分支得到的变换结果—特征图,进行聚合
Block的三种等效形式
(a)表示先划分,单独卷积并计算输出,最后输出相加。split-transform-merge三阶段形式(图3(a)的形式,每个卷积层都进行分组)
(b)表示先划分,单独卷积,然后拼接再计算输出。将各分支的最后一个1×1卷积聚合成一个卷积。(图3(b)的形式,前两个卷积层进行分组,最后将两个卷积层分组卷积的结果融合到一起,经过最后一个层的卷积,最后输出为结果)
(c)就是分组卷积。将各分支的第一个1×1卷积融合成一个卷积,3×3卷积采用group(分组)卷积的形式,分组数=cardinality(基数)(第一层融合,第二层分组,cardinality(基数))
图3(C)结构分析:
- 首先经过一个1X1的卷积层进行降维处理,将它的Channel从256降到128
- 然后通过group卷积层进行处理,这里group卷积的卷积核为3X3,他的groups数为32,它所输出的Channel数为128
- 接着通过1x1的卷积核进行升维
- 最后将它的输出与我们的输入进行相加得到最后输出
三个结构为什么等价?
- b和c等价
第一层:
过程:首先从(b)到(c)这个过程,对于(b)中第一层通过包括32个分支,每个分支(path)卷积核个数为4的1x1卷积,对于每个path而言它的卷积核大小都是1x1,channel为256,又由于我们path的个数为32,就可以简单将他们合并在一起,变为( c)图中第一层了。
参数:
(b)第一层256x1x1x4x32=32768
(c)第一层256X1x1x128=32768
第二层:
过程:和group卷积其实是一样的,对于每个path可以理解为一个group,每个组的输入输出channel为原来的1/group,对于每个组采用3x3的卷积核,卷积之后将特征矩阵进行concate拼接,所以图(b)第二层也是与图(c)第二层 group为32的组卷积也是等价的。
参数:
(b)第二层 4×3×3×4×32=4608
(c)第二层 128/32×3×3×128 = 4608
分组卷积
在AlexNet时就曾提出,由于首先当时的硬件条件,不得不将卷积操作拆分到两台GPU上运行,这两台GPU参数不是共享的。两组卷积核学习两种不同的特征,一组学习纹理,另一组学习色彩。
操作:
分组卷积的卷积层中,输入和输出的Channels被分为C个groups,分别对每个group进行操作
优点:
- 减少参数量,分成G组,则该层的参数量减为原来的1/G。
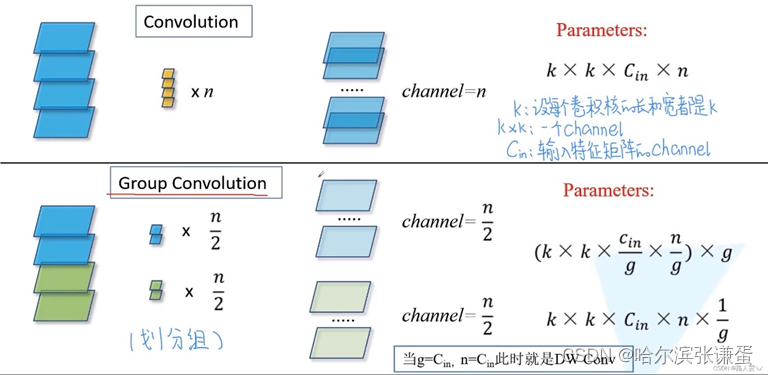
- 让网络学习到不同的特征,每组卷积学习到的特征不一样,获得更丰富的信息。
- 分组卷积可以看做是对原来特征图进行一个dropout,有正则的效果。
论文解决的问题:
Q1:论文试图解决什么问题?
本文用一种平行堆叠相同拓扑结构的blocks代替原来 ResNet 的三层卷积的block,在不明显增加参数量级的情况下提升了模型的准确率,同时由于拓扑结构相同,超参数也减少了,便于模型移植。
Q2:这是否是一个新的问题?
不是,是对ResNet的一个改进,结合了Inception和ResNet优点
Q3:这篇文章要验证一个什么科学假设?
1.在保持相同的计算复杂度和模型尺寸条件下,我们提出的这个网络模块要比原来的 ResNet 模块性能要好。
2.增加基数是一种比更深或更宽更有效的获得准确性的方法
Q4:有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
VGG/ResNet/Inception。图像分类
Q5:论文中提到的解决方案之关键是什么?
(1)提炼VGG、ResNet和Inception系列的优秀思想;
(2)处理相同尺寸的特征图时,采用同样大小、数量的卷积核;
(3)特征图分辨率长宽降低2倍时,特征图通道数(卷积核数量)翻倍;
(4)提出cardinality来衡量模型复杂度,实验表明cardinality比模型深度、宽度更高效
Q6:论文中的实验是如何设计的?
以ResNet50为基准,在ImageNet-1K、ImgaeNet-5K、CIFAR、COCO这些数据集上做对比实验。
Q7:论文中的实验及结果有没有很好地支持需要验证的科学假设?
验证了。实验结果和ResNet对比有提升,参数也减少了。
Q8:这篇论文到底有什么贡献?
采用分支同构使网络结构简明,模块化需要手动调节的超参数少;提炼split-transform-merge思想;引入cardinality指标,为CNN模型提供新的思路。
Q9:下一步呢?有什么工作可以继续深入?
最近ResNeXt已经应用到Mask R-CNN中,取得了SOTA的COCO实例分割和目标检测效果。
















 355
355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









