









Zhuosheng Zhang, Junjie Yang, Hai Zhao, Department of Computer Science and Engineering, Shanghai Jiao Tong University, Retrospective Reader for Machine Reading Comprehension
论文原文:https://arxiv.org/pdf/2001.09694v4.pdf
源码:https://github.com/cooelf/AwesomeMRC (**official)
当前是 SQuAD 上第四名的成绩(2020/3/16)看了看作者主页应该是被 AAAI2021 接收了
1 introduction
当前大多机器阅读理解模型大多建立在(所给定的问题都是可以回答的 = 在原文的某一个范围内一定存在答案)的假设上,但是真实的业务场景并不如此。举个例子(来自 SQuAD2.0 MRC task):

此时要求机器能够判别当前的问题是否真的是可以回答的,而不是对于任何问题都勉强给出一个似是而非的答案。基于此我们的主要任务包括:1)检查问题的可回答性 answerability 2)对可以回答的问题再作进一步的阅读理解
也就是说此时除了传统的 MRC 所重点关注的 encoder 模块,我同时需要一个 verification 的部分来区分这些不可回答的问题,而当前的大多数模型要么直接假设所有的问题都是可以回答的,要么就是单纯地将所有的 verification 的模块简单地集成入了 encoder 或者 decoder 的部分,而这样的操作往往效果不是很好
传统的 MRC 模型主要包括以下几个结构设计:
- 直接的 encoder + decoder 的模型,也就是说此时认为所有的问题都是可以回答的,直接不对本身的问题作 verification
- 将 verification 的部分包括在 encoder 内或者 decoder 内,但相对地效果不佳

本文考虑一种新的架构:
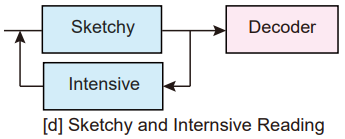
来考虑一下真的人类是怎么做的:先通读一遍文章 + 再重新回到文章中进行精度进一步确认答案。基于人类的行为,这里提出一个新的模型 retrospective reader (Retro-Reader),主要执行以下两个步骤:
- 粗略地阅读文章,并掌握文章和问题之间的关系,给出一个初始的判断
- 进一步精度文章,再验证答案并给出最后的预测
简单表示如下:

2 Our Proposed Model 模型介绍
2.1 overview
这里主要关注的还是抽取式的阅读理解问题( span-based MRC task),也就是目标为在文档中划出一个 span 来作为答案。
也就是说此时给定的信息为一个 <文章 P ,问题 Q,答案 A > 的三元组,则此时我们的任务是 1)从给定的文章 P 中进行 A 开始和结束位置的预测 = 在文中划出一个 span 作为候选答案 2)或对于不可回答的问题,回复一个 null 表示此问题本身是得不到答案的
本文将阅读理解任务分为两个阶段(two-stage reading process):
- sketchy reading:通过略读大概掌握关系并给出一个粗糙的判断,这一步的主要目标是初步判断这个问题是不是可以回答的
- intensive reading:通过精读进一步得到候选答案(也就是得到 answer span)+ 最后判断问题是否是可以回答的 + 给出最后的预测
整体模型结构如下:

3.2 Sketchy Reading Module 泛读模块
Embedding
这部分的目标是通过一些预训练模型得到 P 文章和 Q 问题的向量表示(embedding),将两个向量表示作拼接,再将这些表示作为输入扔给后面的部分
具体来说,首先将输入的句子通过 tokenizer 切割为词语 / subword,比如此时切割为 n 个,记作 T = { t 1 , . . . , t n } T = \{t_1, ... , t_n\} T={t1,...,tn};每一个 subword 的 token 都是三个部分的加和:自身的 token + 位置 embedding + token 类型 embedding,设最后的输出为 X = { x 1 , x 2 , . . . , x n } X = \{x_1 ,x_2, ... , x_n\} X={x1,x2,...,xn}
Interaction
将上一步 embedding 得到的最后输出 X 作为输入,目标为得到输入的上下文表示
这里可以通过一个多层 Transformer(multi-layer Transformer)的 encoder 部分来实现(本身 Transformer 就是编码器 - 解码器的结构,Transformer 详解 戳这里),设最后一个隐藏层的输出为 H = { h 1 , h 2 , . . . , h n } H = \{h_1,h_2,...,h_n\} H={h1,h2,...,hn}
External Front Verification (E-FV)
得到上一步给出的上下文表示,可以认为此时机器已经完成了通读任务,但是此时需要机器给出一个粗糙的判断,此时通过 E-FV 来构造一个二分类器,让机器来初步判断此时的问题是不是可以回答的
这里的输入是上一层输出的隐藏层的值 H,将 H 的第一个 token,也就是 [CLS] 对应的部分,也就是 h1 作为整个序列的表示,直接扔进一个全连接层(注意不是扔全部的 H,只要 h1 部分就行)来判断此时的问题是否是可以回答的。给出的输出是预测概率 y i ^ \hat{y_i} yi^: y i ^ ∝ s o f t m a x ( F F N ( h 1 ) ) \hat{y_i}\varpropto softmax(FFN(h_1)) yi^∝softmax(FFN(h1))
用交叉熵函数来训练:
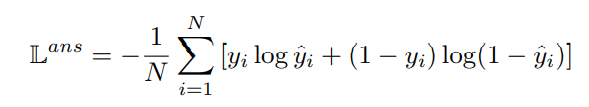
注意这里同时计算了一个 external verification score,在后面的部分会用到这个值:
s
c
o
r
e
e
x
t
=
l
o
g
i
t
n
a
−
l
o
g
i
t
a
n
s
score_{ext} = logit_{na} - logit_{ans}
scoreext=logitna−logitans,注意这里的 na 表示问题不能回答,ans 表示可以回答
3.3 Intensive Reading Module 精读模块
这一部分的模型需要完成:
- 最后拍板到底是不是可以回答的问题
- 给出候选答案,也就是预测 span
- 给出最后的预测结果
Embedding + interaction
和前面略读部分是一样的(原理一样但并不是共享参数,是两个独立训练的部分),最后获得文章 P 和问题 Q 的上下文表示 H H H,但是注意到和普通的 BERT 模型之流不一样的地方在于,此时并不是直接将上下文表示送进一个线性层来预测结果,而是后续备用继续处理
个人感觉这里不太对,问题在于等于要作两遍上下文表示训练,因为本身这个模型的略读和精读模块就是并行的,只是将它们的输出做了一个融合,而并不是让它俩耦合从而存在一种互相依赖的关系,则这里的两个上下文表示应该是并行训练的,这内存消耗(一言难尽(
Question-aware Matching
此时的输入是 embedding + interaction 得到的表示 H,首先注意到 H 本身是带有位置 embedding 的,将 H 分为两个部分,分别对应文章 H P H^P HP 和问题对应的 H Q H^Q HQ(或者说这里的输入表示本身就是 [ C L S ] , Q , [ S E P ] P , [ S E P ] [CLS],Q,[SEP]P,[SEP] [CLS],Q,[SEP]P,[SEP] 的形式,切分还是很方便的)
这里想要作 question aware,这里可以用如下两个注意力:(先了解相关背景知识再往下看,注意力机制详解 戳这里)
- 交叉注意力 multi-head cross attention (CA):
这里实际上是一个多头注意力,查询向量为 H P H^P HP,键K = 值V = H H H- 这里的 Q 共有 p 个 token,此时也就是 p*d 的维度(d 是 embedding 的维度),此时是多头注意力,也就相当于存在 p 个查询向量,每一个向量都能够对应得到一个注意力分布,得到一个综合后的 V = H 的表示,也就是一个向量
- 这里的多头注意力的最后的输出的维度应该是和 H P H^P HP 相同的,可以看作是一个文章 embedding 经过 question 的注意力后的一个表示
- 匹配注意力 Matching Attention:
实际上也就是一个普通的注意力模块,利用问题表示 H P H^P HP 来计算 H 的注意力分布- 这里的 H 的注意力后的表示计算如下,W b 可学习,e 是一个全是 1 的向量
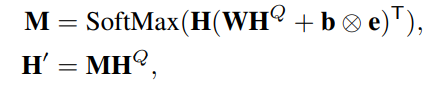
- 和前面不同的是这里直接用 H Q H^Q HQ 作为整个查询,也就是说最后得到的表示和 H 本身是同大小的,可以认为这里得到的 H‘ 是一个 passage + question 集合的上下文表示 H 对应的 question 注意力后的表示
- 这里有个问题:
- 这里的 H 的注意力后的表示计算如下,W b 可学习,e 是一个全是 1 的向量
对于matching attention 最后得到的 H’ 应该是和 H 相同大小的,也就是 问题的维度 +
文章的维度,但是后面的预测需要的大小应该是和 H P H^P HP 同大小的,原论文直接把这里的 H‘ 扔进后续部分了是咋搞的(。难道是直接取了 H‘ 对应的前面的 H P H^P HP 的部分(?
如果有思路欢迎交流指正 ~
Span Prediction
将上面得到的 H’ 扔进来预测候选答案,也就是确定 span
具体操作也就是扔进一个全连接层 + softmax 输出每一个 token 分别是 start 位点 和 end 位点的概率 s , e ∝ s o f t m a x ( F F N ( H ′ ) ) s,e \varpropto softmax(FFN(H')) s,e∝softmax(FFN(H′))
这里的损失函数还是用的交叉熵函数:
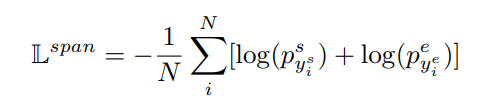
这里对应的
y
i
s
y_i^s
yis 也就是第 i 个位置到底是不是 gold answer 的开始位点的 0-1 标签,后面的
y
i
e
y_i^e
yie 同理
Internal Front Verification (I-FV)
再来进一步确认这个问题是不是可以回答的,输入为上面得到的表示 H ′ H' H′ 的第一个表示 h 1 h_1 h1,将 h1 扔进一个全连接层,再通过(基于分类方法)或(基于回归方法)得到最终的概率
这里还是给定几个可选的方法:
- 直接作 softmax:也就是将全连接层的输出通过一个 softmax,再利用交叉熵进行训练
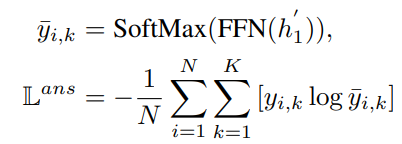
- 用二元交叉熵函数作损失函数:也就是说这里通过一个 sigmoid:

- 用回归 regression 的思想来处理:直接用 MSE 来作损失函数:

注意到这里实际上我们存在两个任务 → 也就是预测是否是可以回答的问题,一个是确定此时的答案 span,则此时的最终损失函数应该是 verification 部分的损失函数和 answer predicate 两个部分的损失函数:
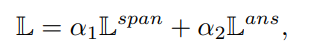
这里以某一个权重 αi 来对两个损失函数作融合
Threshold-based Answerable Verification
最后拍板问题是不是可回答的
此时令该问题对应的文章中各个 token 为开始 / 结束位置的概率的向量分别为 s 和 e,则分别计算:存在答案的得分
s
c
o
r
e
h
a
s
score_{has}
scorehas 和不存在答案的得分
s
c
o
r
e
n
u
l
l
score_{null}
scorenull:
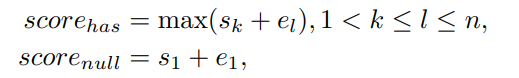
这里继续计算上面两个概率的差值:
s
c
o
r
e
d
i
f
f
=
s
c
o
r
e
h
a
s
−
s
c
o
r
e
d
i
f
f
score_{diff} = score_{has} - score_{diff}
scorediff=scorehas−scorediff留下备用
3.4 Rear Verification
也就是最后确认到底有没有答案
注意到这里同时有两个 verification,也就是 E-FV 和 I-FV,分别代表(略读后对问题是否有答案的判定)和 (精读后对问题是否有答案的判定),此时考虑以某种方式将它们融合起来
定义:
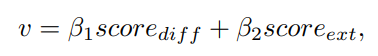
这里的 β1 和 β2 是对应权重,将这里的 v 认为是最终判断有答案的概率,如果这个 v > 预先设定的阈值 δ,此时认为问题确实存在答案,反之不存在,且返回一个空字符串作为 span 预测的结果
4 experiment 实验部分
用到的数据集包括 SQuAD2.0 和 NewsQA,是两个确实引入了回答不了的问题的数据集
看看在 SQuAD 上的效果:

这里的 TAV 也就是直接使用 score_diff 的部分(上面 3.3 的最后一部分)来判断到底有没有答案,如果 score_diff 确实大于某一个阈值 δ 则认为有答案。也就是说 TAV 本身没有用到 E-FV 给出的判断。通过比较可以看到此时同时设置 E-FV 和 I-FV 或许真的可以帮助提升
再看看在 newsQA 的效果:

阅读仓促,存在错误 / 不足欢迎指出!期待进一步讨论~
转载请注明出处。知识见解与想法理应自由共享交流,禁止任何商用行为!















 769
769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









