







 本文提出了一种名为FedASMU的高效异步联邦学习方法,通过动态调整模型聚合权重和使用强化学习选择更新时机,有效解决了非独立同分布和系统异质性带来的挑战。实验证明,FedASMU在各种基准和数据集上优于现有方法,提高了模型准确性和训练效率。
本文提出了一种名为FedASMU的高效异步联邦学习方法,通过动态调整模型聚合权重和使用强化学习选择更新时机,有效解决了非独立同分布和系统异质性带来的挑战。实验证明,FedASMU在各种基准和数据集上优于现有方法,提高了模型准确性和训练效率。
论文信息
FedASMU: Efficient Asynchronous Federated Learning with Dynamic Staleness-Aware Model Update,Proceedings of the AAAI Conference on Artificial Intelligence,2024-03-24(23年10月挂在 arXiv),ccfa
introduction
- 背景:FL 训练中存在 统计异质性(non-IID) 与 系统异质性(计算与通信能力差异) 问题。
- 挑战:统计异质性导致准确率严重下降,系统异质性显著延长了训练过程。
- 解决的问题:统计异构、系统异构
- 贡献点:
● 提出一种 新的 异步FL系统模型:在 server 进行动态模型聚合,根据本地模型的陈旧度和对全局损失的影响来调整其在全局模型的重要程度(权重)
● 提出一种基于 设备 的自适应局部模型调整方法,允许将最新的全局模型整合到局部模型中,减少模型陈旧的影响。模型调整包括 使用强化学习来选择检索全局模型的最佳时间点,以及动态调整本地模型聚合的权重
● 实验验证:用 9 种最先进的基线方法、6个典型模型和5个公开的现实数据集进行了广泛的实验,结果表明FedASMU可以很好地解决异质性问题,并且明显优于基线方法
问题描述:
- 对问题的形式化描述
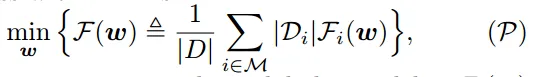
为找最优的全局模型w ,使损失函数 F(w)最小化,其中F(w) 是所有设备上本地损失函数 Fi(w) 平均值
- System model
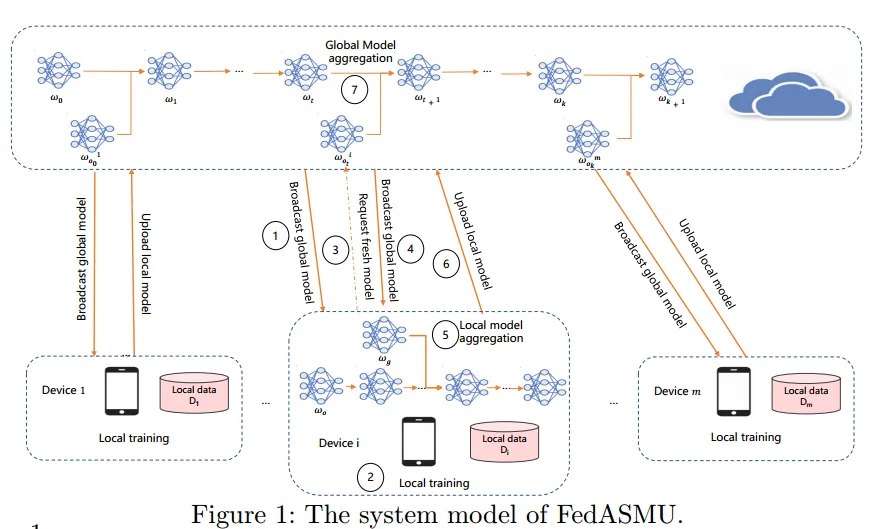
Server 以恒定的时间周期 T 触发 m 个设备进行局部训练。培训过程由多个全局轮次组成。初始的全局模型版本为 0 ,在每个全局轮次完成之后,全局模型的版本增加 1 。每个全局轮次由7个步骤组成
- Server 随机选择 m’ (m’≤ m )个可用设备,向选定的设备广播全局模型
- 在 m’ 个设备上利用本地数据集进行训练
- 设备进行本地训练的同时,全局模型可能进行更新,为了减少模型陈旧度,设备 i 向Server 请求新的全局模型
- 如果wg 比wo 新的话( g > o ),就广播新的全局模型
- 设备接到新的全局模型后,将全局模型和最新的本地模型聚合为一个新模型,并继续使用新模型进行局部训练。
- 本地训练完成,设备 i 将本地模型上传到 Server
- Server 将本地模型 wio 和最新的全局模型 wt 聚合为新的模型,其中涉及 陈旧度 Ti= t-o+1,当陈旧度达到设定的阈值就舍弃上传的本地模型
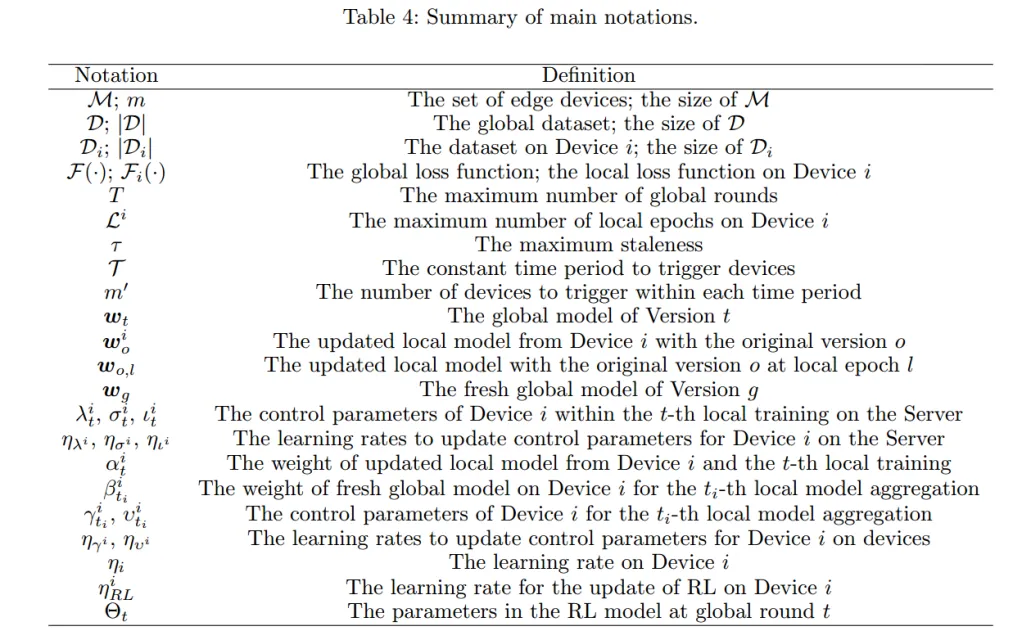
补充:文章中的符号表示
解决方法
执行流程:
- Dynamic Model Update on the Server (步骤 7)
将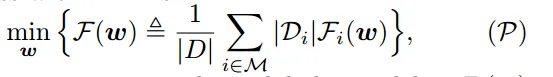
问题拆解成双层优化问题:
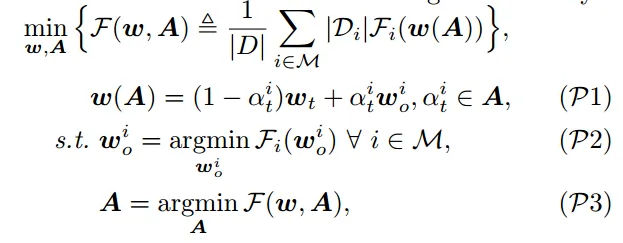
P3 旨在找到一个权重集合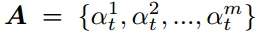
,能够最小化全局模型 w t 和上传的本地模型 w io 的损失函数 F (w ,A )
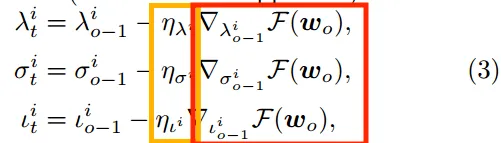
黄色——对应的动态调整的学习率 红色——损失函数对应的偏导数
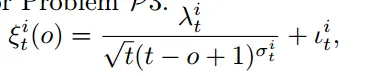
t-o+1表示模型陈旧度,t 表示当前全局模型的版本 对于问题P3,提出了一个动态多项式函数来表示公式 2 中定义的 αit
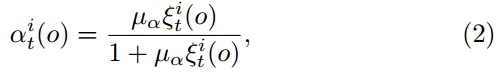
μα 是超参数
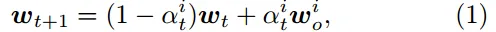
αit 是设备 i 在第 t 个全局轮次上传的本地模型的重要程度(权重)

- Adaptive Model Update on Devices (步骤 3、5)
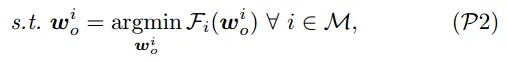
P2 :最小化本地损失函数
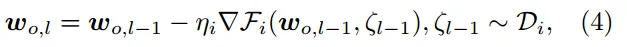
o 为全局模型的版本,l 为局部 epoch 个数,ηi 为设备 i 上的学习率,∇Fi(·) 为基于 Di 中无偏采样的小批 ζl−1
的梯度
关键:确定 发送请求的时隙 和 聚合新全局模型的权重
Intelligent Time Slot Selection(RL)
当请求提前发送时,服务器执行的更新很少,最终更新的本地模型可能仍然严重过时
当请求发送较晚时,本地更新无法利用新的全局模型,准确性较低
The intelligent time slot selector 由 Server 的 元模型 和 每个设备上的本地模型 组成,元模型为每个设备生成初始时隙决策,并在设备执行第一次局部训练时更新。本地模型使用初始时隙完成初始化,并在随后的局部训练期间在设备内进行更新,为新的全局模型请求生成个性化的适当时隙。利用基于长短期记忆(LSTM)的网络,为元模型提供一个完全连接层,并为每个本地模型使用 q -学习方法。元模型和局部模型都会生成每个时隙的概率。利用ϵ-greedy策略进行选择。
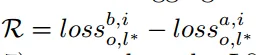
R 是模型聚合前的损失值与模型聚合后的损失值之差,
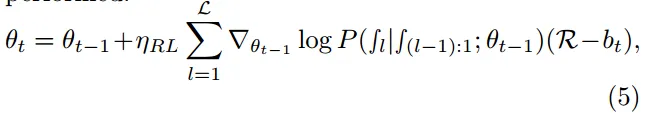
θt 表示元模型第 t 次更新后元模型中的参数,ηRL表示 RL 训练过程的学习率,L 表示本地 epoch 的最大次数,∫L 对应第 L
个本地 epoch 后发送请求(1) 或 不发送请求(0) 的决定,bt 是减少模型偏差的基值
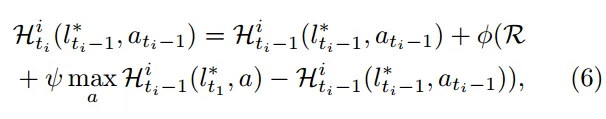
Hi:设备 i 上的决策和奖励之间的映射 ,它被更新为历史值和奖励的加权平均值 φ 和 ψ 是超参数 ati−1 ∈ {add, stay, minus},
● add
● stay
(保持不变)???
● minus
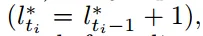
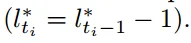
Dynamic Local Model Aggregation
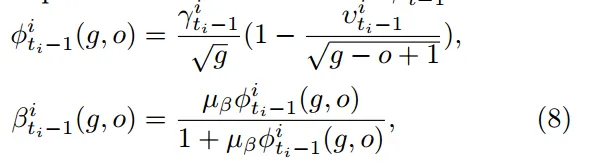
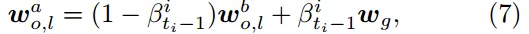

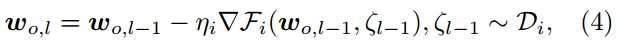

- 挑战问题怎么解决:
- 统计异构:动态模型聚合方法确保了即使在数据分布不均匀的情况下,也能保持全局模型的准确性,因为它能够识别并优先考虑那些更准确、更新的模型。
- 动态模型聚合机制能根据每个设备上传的模型的陈旧性和对全局损失的影响来调整其权重
- 用动态的多项式函数计算每个设备上传模型的重要性权重 αit,考虑模型的陈旧性和本地损失
- 较新的模型和在统计上更具代表性的模型会对全局模型的更新产生更大的影响,从而减少由于数据分布不均匀导致的准确性下降
- 系统异构:自适应本地模型调整方法通过及时地将全局模型的最新信息整合到本地模型中,减少了由于设备性能差异导致的训练效率问题,同时保持了全局模型的更新和同步
- 自适应机制允许设备在本地训练过程中主动请求最新的全局模型,并将其与本地模型进行聚合
- 用基于强化学习的智能时隙选择器确定最佳的请求全局模型的时间点,减少本地模型的陈旧性
- 通过动态调整本地模型与最新全局模型的聚合权重,确保在设备计算和通信能力不均匀的情况下,也能有效地整合各个设备上的更新
性能保证(performance guarantee):
理论分析,使用什么理论,怎么分析/解决
效果:重点是实验设计,每一部分实验在验证论文中的什么结论
- 实验设置
取 1 个 Server 和 100 个设备
9种 sota
5个 公共数据集
6个 模型
-
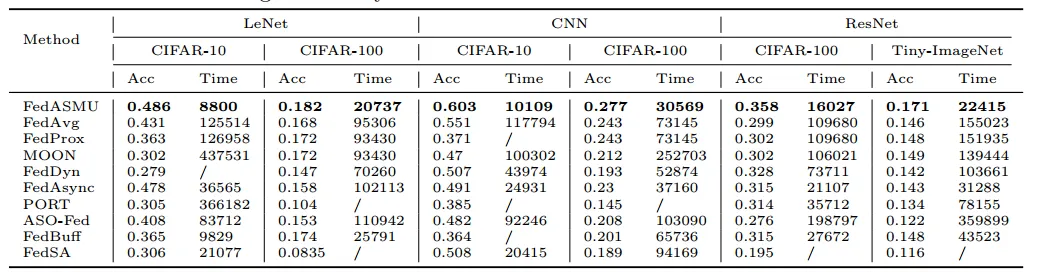
对比实验
-
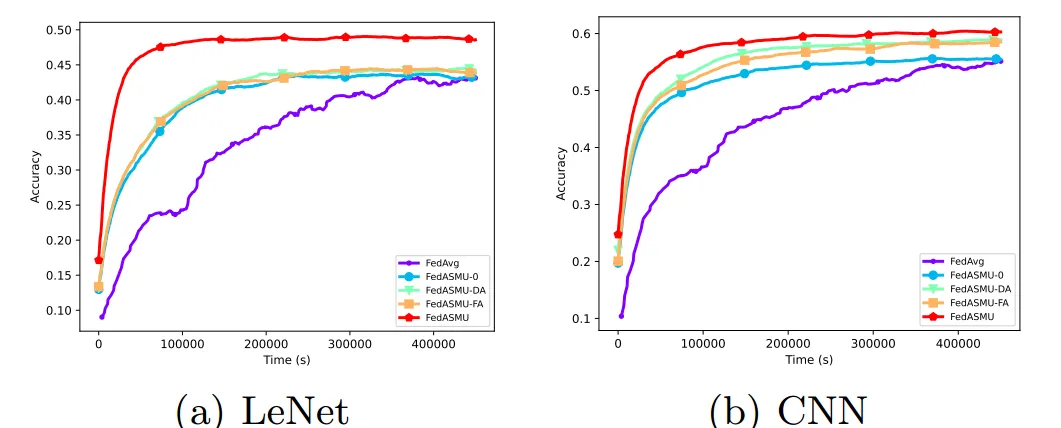
消融实验
-
超参数确定实验
超参对实验结果的影响不大,很容易进行微调
(备选)自己的思考
论文对你的启发,包括但不限于解决某个问题的技术、该论文方法的优缺点、实验设计、源码积累等。
● 元学习 和 强化学习
● 本文没给出源码(尝试搜索一下)
● AAAI 的文章是属于已有的角度深耕
- 不是每一篇论文都有以上内容,但是尽可能按照以上思路读论文、总结论文。
- 注意用自己的话总结以上内容,不要整篇翻译论文,而且不推荐使用类似知云翻译这种软件读论文。建议直接读英文原文,有不理解或者不知道的词可以翻译记录。
- 读论文的过程中,一定要多问为什么,多考虑这个问题存不存在、这个方法能不能解决,不要盲目迷信论文作者。
- 读论文的目的在于调研本领域的研究内容,发现问题,提出自己的想法,刷论文数量没有意义,需要发现读过论文对自己研究的价值。
- 当发现论文中存在自己不了解的技术或者方法,首先进行调研,不要有畏难的心理,多掌握一门工具能帮助你解决自己的研究问题。
小白正在努力学习,诚恳欢迎各位大佬指点!!!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











