







1. 论文信息
Asynchronous Wireless Federated Learning with Probabilistic Client Selection,IEEE Transactions on Wireless Communications,2023,ccfb
2. introduction
牺牲时间换取精度
- 同步FL 存在掉队者问题(由于带宽、计算资源受限,同步FL需要等待慢速设备才可以聚合,速度慢的设备会影响收敛速率,称其为掉队者) -> 异步FL 不等待慢速设备,允许设备更新完成后实时聚合
- 异步 FL 中丢弃掉队者会导致严重的性能下降->不丢弃(客户端保持本地更新并在任意时间与服务器交换模型:纯异步)
-
- 掉队者违反了参与公平(∆k 保证参与公平)
- 可能使全局模型向局部最优偏移
- 掉队者基于陈旧全局模型训练得到的梯度也会降低模型的性能
2.1. 解决的问题
- 异步 FL 中丢弃掉队者(严重性能下降+违反参与公平) -> 不丢弃:客户端保持本地更新并在任意时间与服务器交换模型 + 保证客户端 𝑘 在每个∆k个轮数间隔内与服务器之间至少进行一次通信 -> 推导基于概率客户端选择的收敛速率(近似)表达式
适应信道多样性和参与公平性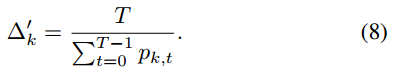
- 无线网络环境:数据异构,带宽资源受限 -> 联合考虑概率客户端选择和带宽分配,构建收敛速度和移动能耗的优化问题(1. 客户端选择能够通过选择信息量最大和/通信开销最小的客户参加训练,解决能效问题+数据异构 2. 利用概率客户端选择来处理能源效率和数据异质性问题还没有引起人们的重视)-> 利用和比算法将原非凸问题转化为凸减法形式,提出求全局最优解的迭代算法
丢弃掉队者会导致严重性能下降的原因:
- 一些客户的过度参与可能会损害模型的性能,即某一组客户的过多参与可能会使全局模型“漂移”到局部最优
- 减少客户端参与者会降低模型收敛,增加客户端参与者可以提高模型的收敛性。
概率客户选择:服务器只计算客户端的选择概率,每个客户端根据自己的选择概率自主决定是否将更新后的本地模型发送给服务器。
2.2. 本文贡献点
- 分析了具有概率客户选择的异步 FL 的收敛速度,展示了客户的训练效果与参与概率之间的关系。特别是,考虑了每个客户端必须与服务器至少通信一次的单独间隔 ∆k,以适应信道多样性和参与公平性。
- 提出了一个概率客户端选择和带宽分配的联合优化问题,权衡异步FL的收敛性能和客户端的能耗。利用和比算法将原非凸问题转化为凸减法形式,并提出了求全局最优解的迭代算法。
- 分析得出一些有用的结论:
-
- 更频繁的客户端-服务器通信可以加速模型的收敛
- 客户的公平参与也可以提高模型的性能
- 更多的客户端有利于模型性能,但如果客户端数量超过一定的阈值,数据异构会导致模型性能下降
- 本方案不仅提高了模型性能和能源效率,而且提高了用户之间能源消耗的公平性
3. 问题描述:
3.1. 整体流程:
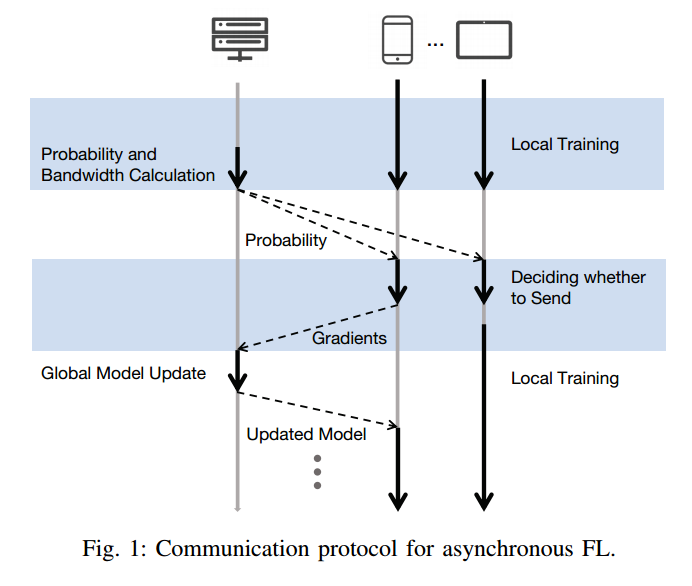
- 客户端 本地计算伪梯度
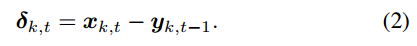
- 服务器 计算客户端选择概率
和带宽分配比率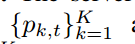
,并将客户端选择概率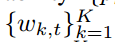
广播给所有客户端(多对多还是一对一?) - 客户端 根据客户端选择概率
决定是否发送本地伪梯度(达到什么条件发送) - 客户端 k∈Ct 通过带宽分配比为
的子通道将本地伪梯度发送给服务器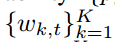
- 服务器 将全局模型参数更新为
,并将更新后的模型广播给k∈Ct 的客户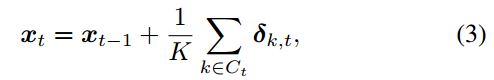
4. 解决方法
4.1. 确定∆k,确保参与公平
推导基于概率客户端选择的收敛速率(近似)表达式
- 构建基于概率客户端选择的收敛速率表达式

客户端选择概率
![]()
与最大通信间隔 ∆k 有直接关系
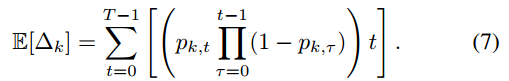
- 转化 ∆k 近似表达
求解 ∆k,不好求解,转化为近似表达,假设所有客户端在T轮中周期性地与服务器交换模型
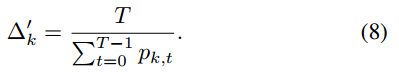
Δk 表示客户端 𝑘 与服务器之间至少进行一次通信的最大轮数间隔,影响了客户端参与模型更新的频率,进而影响整个联邦学习的收敛速度和客户端的能耗。
T 是总的通信轮数,𝑝𝑘,𝑡 是在第 𝑡 轮客户端 𝑘 选择参与的概率。这个公式反映了客户端 𝑘 在 𝑇 轮中平均参与的次数的倒数
代入

- 转换得到收敛速度表达式
引理1

引理1:客户端的 ∆k 越小,模型的收敛速度越好,说明客户端与服务器交换模型的频率越高,模型的性能越好。
为每个客户端 k 分配一个单独的 ∆k
- 首先,得到了一个新的收敛速度,影响了接下来的选择概率和考虑的优化问题的推导。
- 其次,为每个客户端 k 分配一个单独的 ∆k 可以适应信道变化和多用户分集,即允许信道条件较好的客户端更频繁地发送梯度,而信道条件较差的客户端发送频率较低。
引理2:更频繁的客户端-服务器模型交换可以提高收敛性
增大pk,t的值可以减小(10)中定义的异步FL 收敛速率的上界
引理3:客户的公平参与可以促进融合
4.2. 联合考虑概率客户端选择和带宽分配,构建收敛速度和移动能耗的优化问题
- 构建收敛速度和移动能耗的优化问题
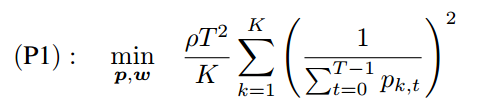
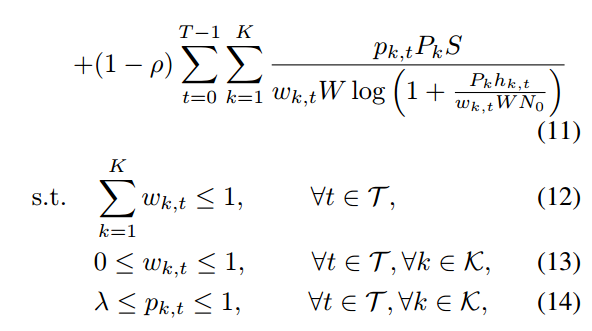
约束(12)和(13)是带宽分配的可行性条件
约束(14)确保每个客户端至少有一定的机会参与异步 FL
- 将问题(P1)转化为等效的参数化减法形式问题,并开发迭代算法来寻找全局最优解


定理2 通过引入附加参数(α, β, γ)将问题(P1)转化为等价的参数化形式(P2),
当(α, β, γ) = (α, β, γ)时,问题(P1)和问题(P2)具有相同的最优解(p∗,w∗)。
将问题(P2) 进一步解耦为客户端选择概率优化和带宽分配两个子问题,分两层求解:
- 在内层中,给定(α, β, γ)求解减式问题(P2)得到(p∗,w∗)。
- 在外层,找到满足
的最优(α∗,β∗,γ∗)
4.2.1. 给定(α, β, γ)求解问题(P2)得到(p∗,w∗)
4.2.1.1. 坐标下降法(BCD)解决客户端选择概率优化
首先,给定(α, γ),每个客户k的客户选择概率优化问题可写成:
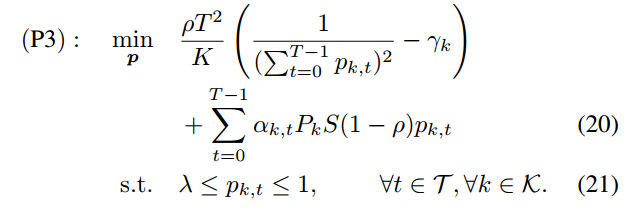
通过求解K个子问题(P3),我们可以得到问题(P2)的最优选择概率p *
坐标下降法(BCD)
将(20)记为L1,设
![]()
,即可得到pk,t的最优值
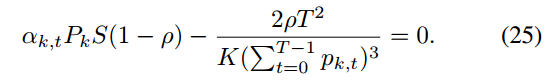
考虑
![]()
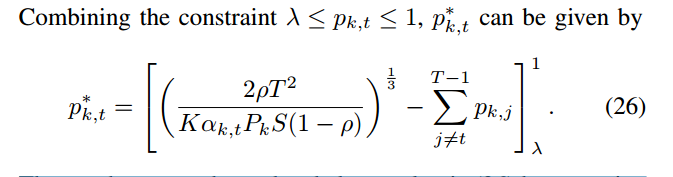
假设其他
![]()
固定,交替优化方法可以最终收敛到问题(P3)的最优解p *
4.2.1.2. 拉格朗日对偶方法解决带宽分配
给定(α, β),每轮t的带宽分配问题可以写成:
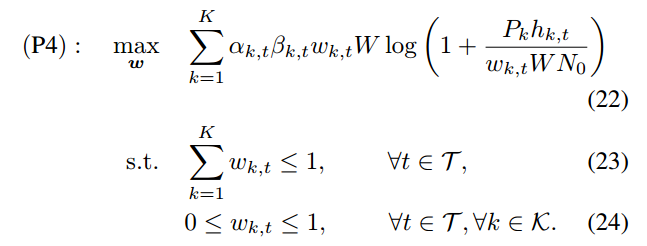
通过求解T个子问题(P4),也可以得到问题(P2)的最优带宽分配比w *
拉格朗日乘子法:
引入与约束(12)相关的拉格朗日乘子v = {v0, v1,···,vT−1},问题(P4)的拉格朗日函数可表示为
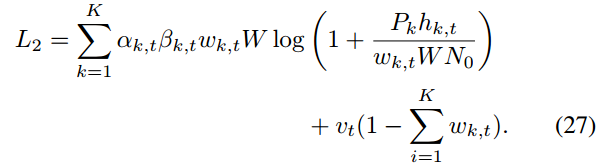
拉格朗日对偶问题由式给出
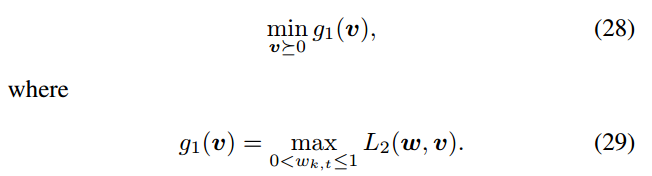
拉格朗日函数L2关于wk的二阶函数t
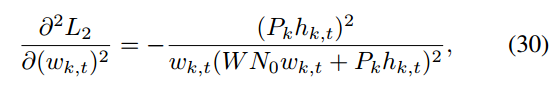
设置
,考虑
![]()

对于对偶问题(28),采用子梯度法求最优拉格朗日乘子v,其中每个vt更新为
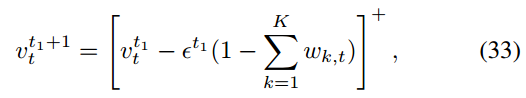
4.2.2. 给定(p∗,w∗),求最优(α∗,β∗,γ∗)
获取最优(p∗,w∗)后,牛顿法改进更新(α, β, γ)
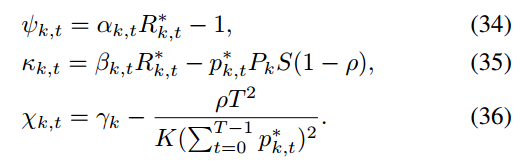
具体推导省略:
4.2.3. 方法改进
结合推导进行分析,执行流程:
先对给定 (α, β, γ) 的内层凸问题(P3)和(P4)进行最优解,然后用改进的牛顿法求解外层问题,其中两层问题在一个循环中交替求解,最终得到问题(P2)的全局最优解

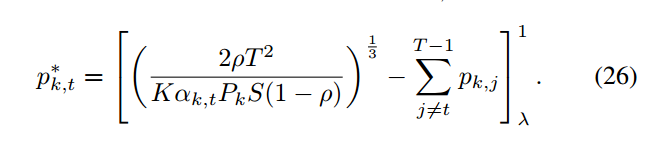

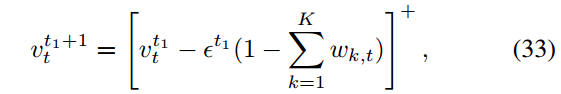
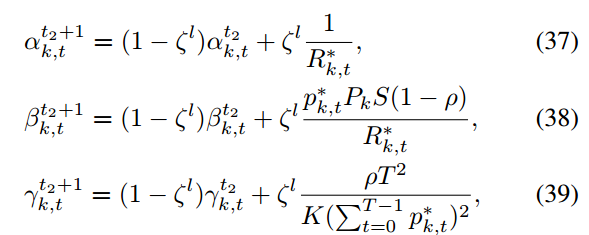
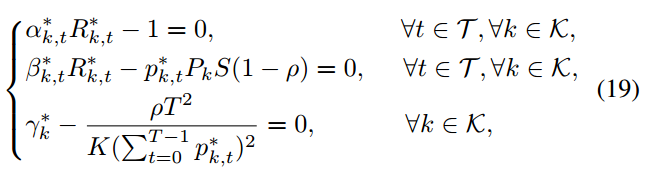
4.2.4. 在线执行
目前提出的算法 1 找到了最优的选择概率和带宽分配比例。但由于
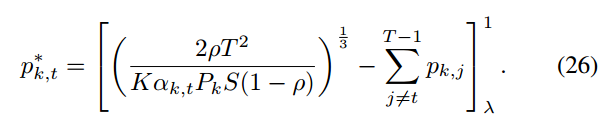
中选择概率 pk,t 的计算需要其他回合的概率,所以算法 1 可以采用离线方式进行操作。为了解决这个问题,将算法扩展到一个在线算法。问题(P1)可以改写为假设每个客户 pk,t 在所有回合的选择概率是相同的,即对于所有回合t,pk,t = pk(这个假设在文献中被广泛使用)
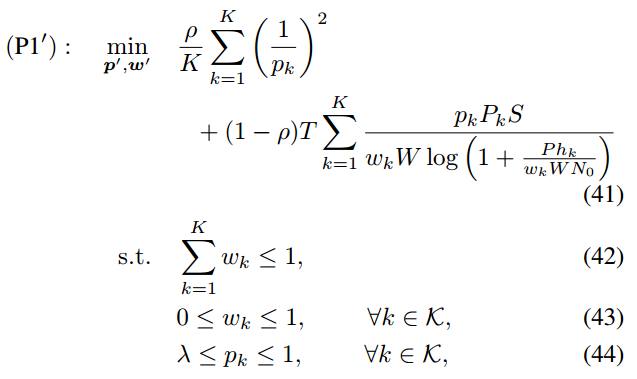
问题(P1 ')与问题(P1)具有相同的结构,可以扩展所提出的算法1来解决问题(P1 ')。(P1 ') 转化为具有给定辅助参数(α, β, γ) 的参数化减法形式问题
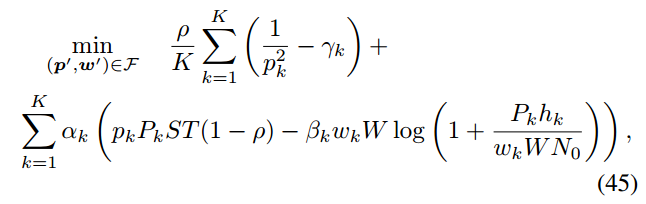
最优的w * k可以由(31)给出
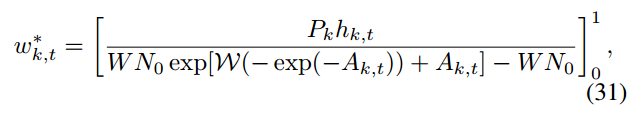
最优的p * k:
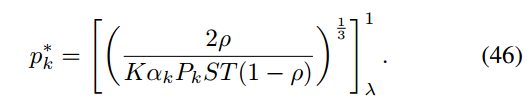
5. 效果:
5.1. 实验设置

数据集:MNIST 和 CIFAR-10
首先根据标签将数据集划分为10个数据块,然后将每个数据块进一步划分为d·K 10个分片,最后为每个客户端分配d个不同标签的分片。而局部数据集的非iid级别可以用d来控制,d的值越小,数据分布的异构程度越高
神经网络模型:
针对 MNIST 数据集训练了一个简单的多层感知器(MLP)模型,该模型由一个隐藏层和200个节点组成,该神经网络的模型大小为S = 6.37 × 106位。将批量大小设置为10,学习率设置为0.01,并且客户端每个通信轮执行5个本地迭代。
使用 AlexNet 训练 CIFAR-10 数据集,该模型大小为4.57 × 108位。批处理大小设置为128,学习率设置为0.01,客户端每轮执行1次本地迭代。
基准测试方案:
- 随机方案:所有客户端以相同的概率p决定是否与服务器通信
- 贪婪方案:在每一轮通信中,选择前k个信道增益最大的客户端参与模型训练
- 基于年龄的方案:在每一轮通信中,以顺序交替的方式选择 k 个客户端。k 的值被设置为与建议方案中选择的客户端数量相同,以便进行公平比较。
5.2. 超参实验
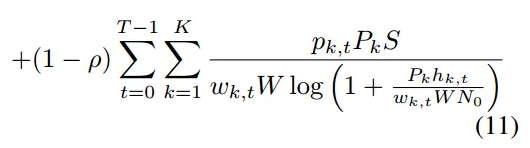
系数 ρ 可以衡量优化目标中的收敛性能和能耗,较大的 ρ 更关注收敛性,较小的 ρ 更关注能量
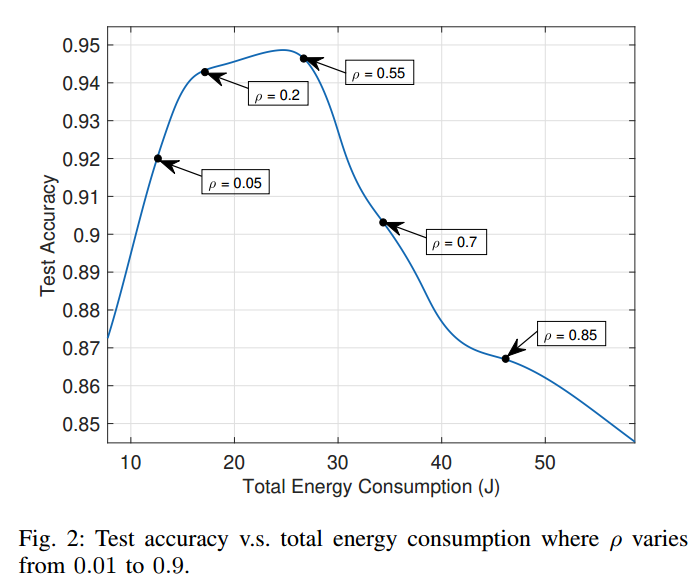
随着 ρ 的增大,优化的重点从最小化能量消耗转向提高收敛性能
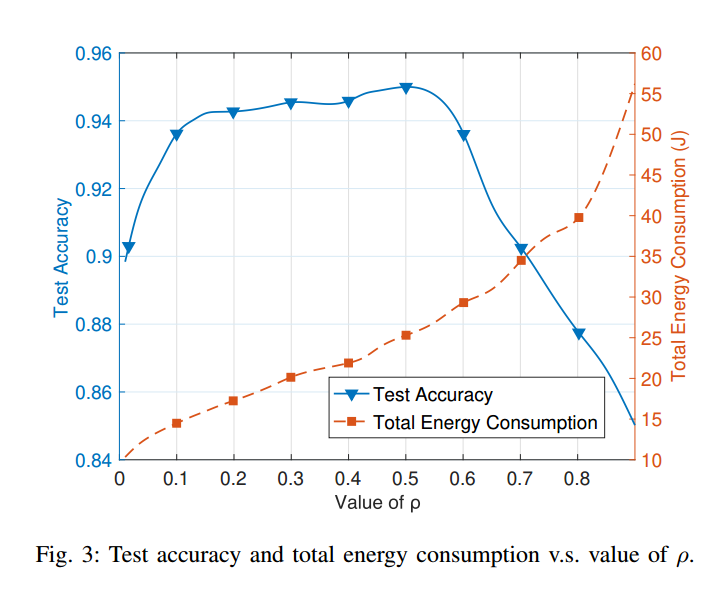
当 ρ 值从 0.01 增加到 0.1 时,更多的客户端参与模型训练,虽然这增加了总能耗,但全局模型能够从客户端获取更多的信息,更快地收敛,获得更高的测试精度。
当 ρ 较大时,即当 ρ 从 0.1 增加到 0.9 时,测试精度先保持稳定,然后逐渐降低。这是由于客户机的数据异构性,导致客户机的本地更新之间存在很大差异。因此,聚合后得到的全局模型偏离了全局损失减小的最优方向,从而导致测试精度的降低
在实际应用中,在合适的范围,例如在 0.01 到 0.1 之间选择 ρ ,可以选择较大的 ρ 作为模型收敛的焦点,同时选择较小的 ρ 来满足较低的能量预算
5.3. 性能比较
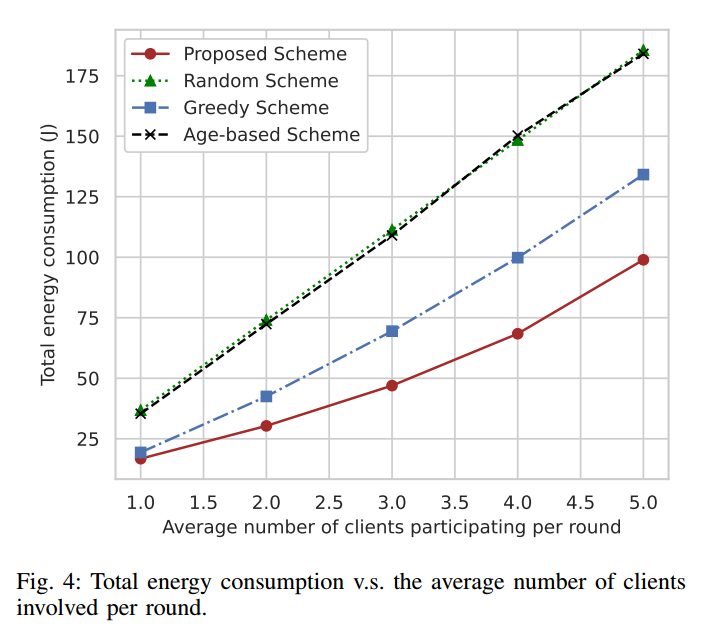
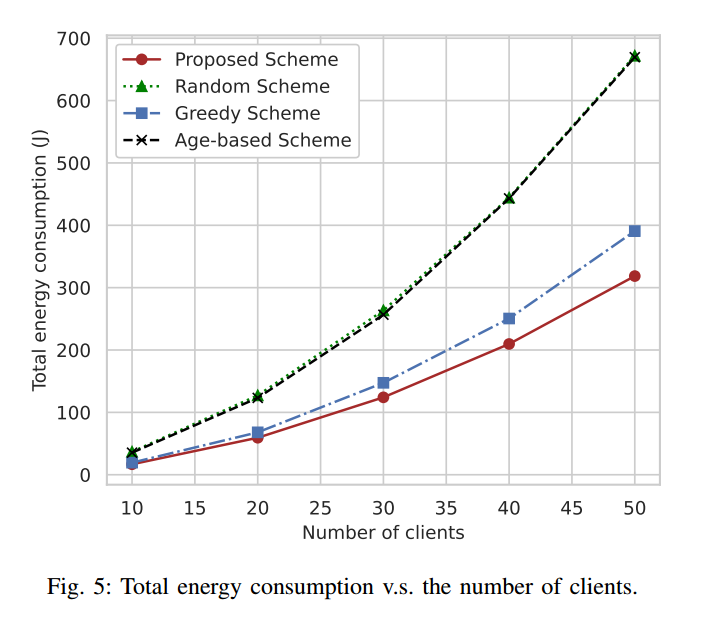
图 4 显示 100 轮通信中总能耗随每轮平均客户端数量的变化情况,其中客户端数量设置为 10
图 5 显示 100 轮通信中总能耗随客户端数量变化的变化情况,其中客户端参与率统一设置为0.1
本文提出的方案大大减少了能源消耗
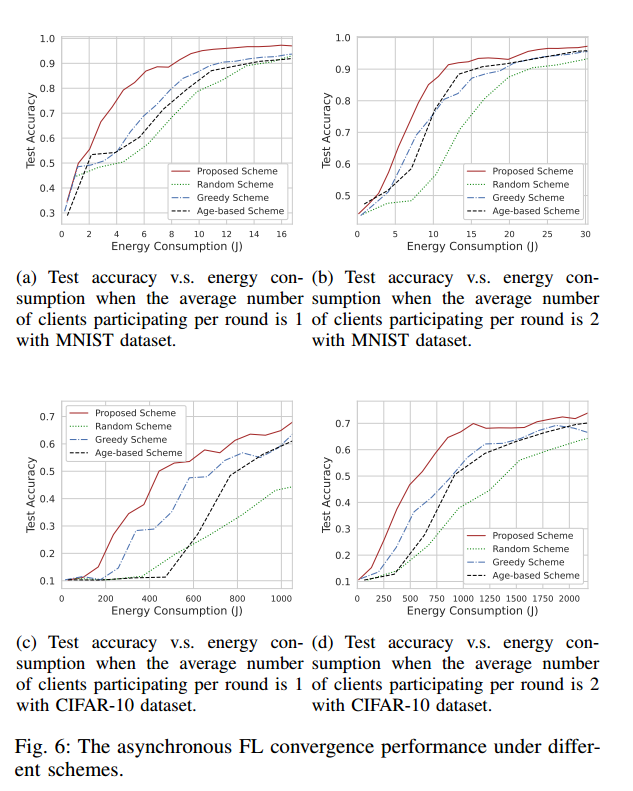
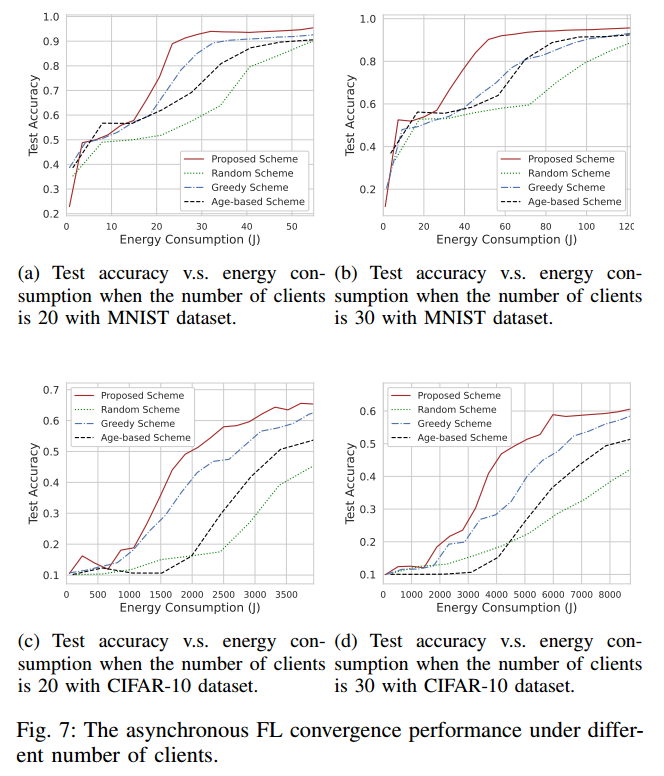
图 6 中,每轮平均参与的客户数设置为 1 或 2
图 7 中,客户参与率统一设置为 0.1
在相同的能耗下,随机方案的性能最差,本文方案的精度最高。该方案通过联合带宽分配和概率客户端选择有效地降低了能量消耗。
5.4. 对不同网络条件的适应性
场景1:客户端 1 到客户端 5 分布在距离服务器 100 ~ 200 米半径的区域内,其余客户端随机分布在cell中,模拟了一些客户端始终在服务器附近的场景。
场景2:客户端 1 到客户端 5 分布在距离服务器 900 ~ 1000 m半径范围内,其余客户端随机分布在小区内,模拟了一些客户端始终远离服务器的场景。
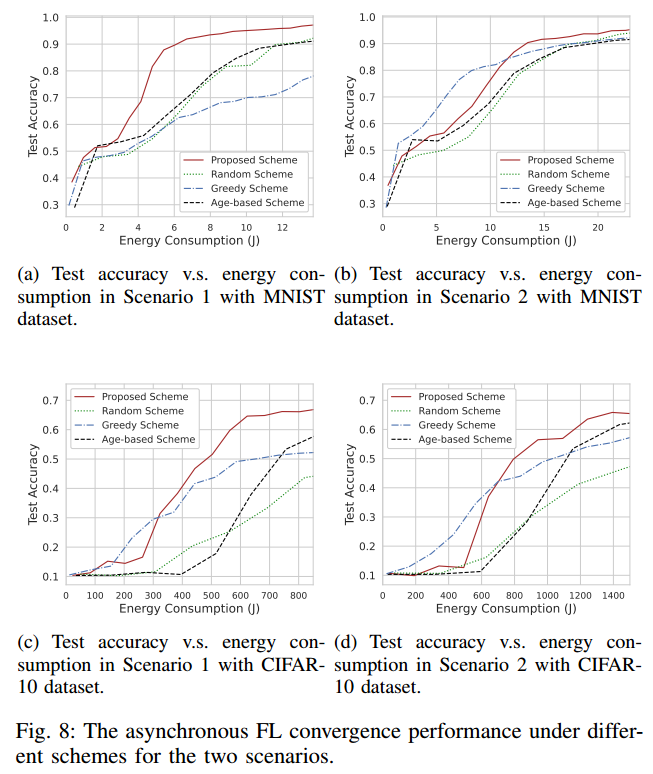
图 8 显示了两种场景下的模型精度
在训练结束的过程中,在相同的能量消耗下,贪婪方案的模型性能较差,精度甚至低于MNIST数据集中的随机方案,文章提出的方案仍然保持了最优的精度
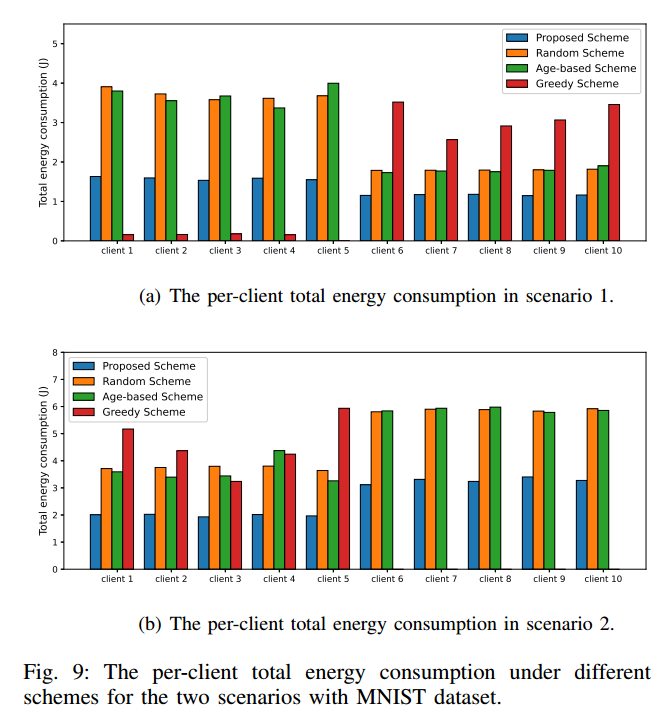
图 9 显示使用 MNIST 数据集的两种场景下,建议方案和两个基准方案下的每个客户端的总能耗。
从图 9 可以看出,在场景 1 中,贪心方案多次选择极度分布的客户端,而在场景 2 中,极度分布的客户端被完全忽略,说明贪心方案只会天真地选择通道条件好的客户端,从而导致客户端参与不公平,使全局模型向局部最优漂移。
相比之下,该方案中每个客户的总能耗更加平衡,在公平性方面与随机方案和基于年龄的方案相似。
同时,由于该方案涉及到信道感知的客户端选择,因此该方案的每客户端总能耗远低于随机方案。

















 1917
1917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











