







底层逻辑:结合同步 FL 和 异步 FL 的优点构建 HiFL,并分别解决同步和异步带来的问题构建 HiFlash 提高通信效率
1. 论文信息
HiFlash: Communication-Efficient Hierarchical Federated Learning With Adaptive Staleness Control and Heterogeneity-Aware Client-Edge Association,IEEE Transactions on Parallel and Distributed Systems,2023,ccfa
2. introduction
2.1. 背景:
FL 需要在多个更新迭代中交换大量模型参数。然而,真实世界中联邦生态里的客户端分散在网络边缘(局域网),通常通过广域网(WAN)和远程传输连接到远程云服务器,这个过程会导致高昂的通信成本和严重的网络拥塞。这种低效率的通信大大降低大规模分布式训练的系统性能,阻碍 FL 系统在实践中的广泛部署。
2.2. 解决的问题:
- 传统 FL 在客户端和云端之间频繁交换大量模型参数 -> 云端通信开销大、存在传输延迟 -> 分层 FL 引入额外的局部计算,用计算开销代替通信开销 -> 权衡计算资源和通信效率 -> 设计 HiFL
-
- 边缘节点-云端为广域网 -> 环境动态 -> 异步 FL
- 客户端-边缘节点为局域网 -> 利用边缘节点的计算资源减少客户端到云端的直接通信,加快局部模型的训练速度 -> 同步 FL
- FL 异步聚合,边缘节点模型训练速度存在差异 -> 过时性问题 -> HiFL 固定过时阈值( 𝜏 大,允许同时进行训练的边缘节点数多,训练时间短,但计算、通信代价增加,收敛慢;𝜏 小,允许同时进行训练的边缘节点数少,训练时间长,但计算、通信代价减少,收敛快)-> 不能适应复杂的 FL 环境 -> 权衡训练时间、资源、收敛速度等因素,利用 DRL 实现自适应的过时控制(设计奖励函数考虑计算、通信资源以及时间开销,通过最大化奖励函数选择合适的动作:过时阈值)
- 不同的客户端在数据分布和计算资源上存在异构性 -> 客户端与边缘节点进行双向选择 (考虑设备之间数据的相似度(JS散度)、计算、通信响应延迟设计代价函数 (边缘节点选择代价小的客户端)+ 客户端选择边缘节点 )-> 减小客户端-边缘节点以及边缘节点-云端的数据分布差异 -> 使每个边缘节点上的数据分布更接近全局IID分布
2.3. 贡献点:
- 为实现高效通信和准确的模型学习,将 对客户端-边缘结点模型同步聚合,对边缘结点-云服务器模型异步聚合 的分层联邦学习方法定义为 HiFL,理论分析证明HiFL的收敛性,包括凸学习目标和非凸学习目标。
- 针对HiFL 中同步与异步训练中存在的问题,提出 HiFL 的增强版 HiFlash ,引入基于HiFL的自适应过时控制(边缘结点-云服务器模型异步聚合)和异构感知的客户端关联(客户端-边缘结点模型同步聚合)。HiFlash可以实现大规模部署,提高模型性能和系统效率。
- 在不影响模型精度的前提下提高系统效率,针对边缘结点-云服务器模型异步聚合 ,设计基于深度q网络(Deep Q-Network, DQN)的自适应过时控制DRL agent,采用精细的学习奖励设计;为减轻数据和资源异质性引起的精度下降和掉队效应, 对客户端-边缘结点模型同步聚合建立了一种高效的低复杂度加权启发式客户端边缘关联算法平衡模型精度和系统效率之间的关系。
- 进行大量实验,结果表明 在不影响模型精度的情况下,HiFlash在通信效率方面明显优于其他基于FL的方法。
3. 问题描述:System model/架构/对问题的形式化描述
3.1. HiFL框架
3.1.1. HiFL 概述
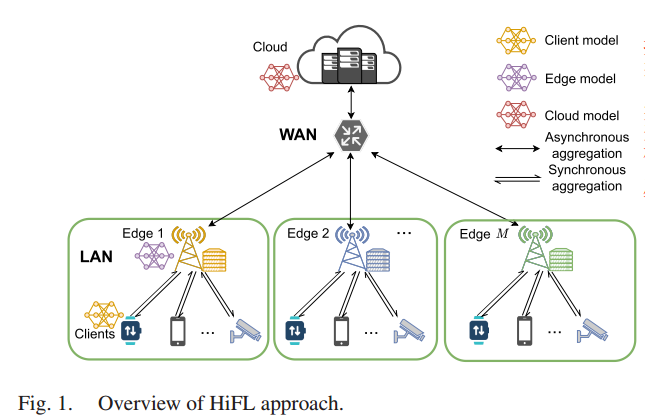
- 在同一局域网 LAN 环境下,模型训练精度高,收敛速度快,更需要在边缘节点和客户端之间进行同步模型聚合
- 在复杂的广域网 WAN 环境下,云端的模型训练存在通信瓶颈(不同边缘的客户端大小不同,远程传输时间波动很大,边缘模型聚合时间也不同),有严重的掉队问题。采用异步聚合减少中心服务器和边缘节点之间模型更新的等待时间,缓解掉队问题

3.1.2. HiFL 目标函数:
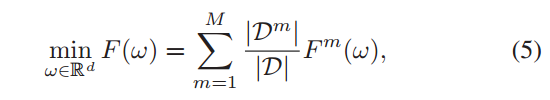
表示所有边缘节点损失函数 𝐹𝑚(𝜔)的加权和,双层嵌套
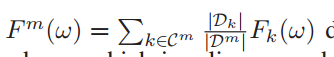
表示边缘节点m对应Cm上所有客户端损失函数的加权和
![]()
表示与边节点m相关联的所有客户端样本的数据量
3.1.3. HiFL 训练过程
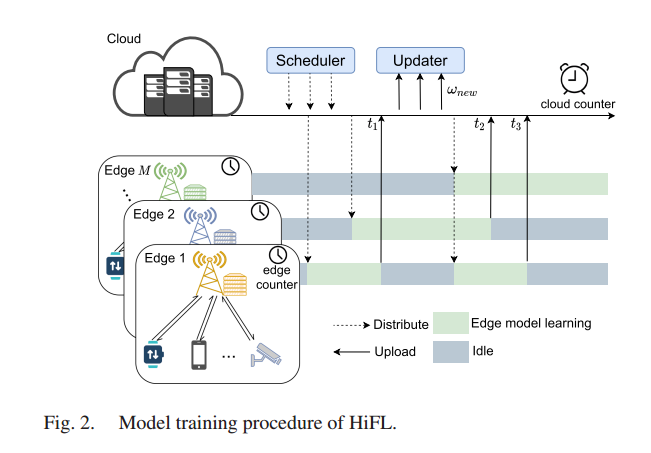
Scheduler 和 Upater 两个核心组件,在云服务器上异步并行运行,实现无等待的目标
- Scheduler 负责最新模型分发(通过指定的DRL代理集成控制功能)
- Upater 负责全局模型聚合
空闲的边缘节点开始进行模型训练,会主动从云服务器下载最新版本的全局模型。服务器检查更新程序,立即将全局模型发送到相应的边缘节点。
接收到全局模型后,边缘节点迅速广播到相关的客户端,利用本地数据集以同步方式与高效的客户端边缘通信协作训练共享边缘模型。
云服务器从边缘节点接收到训练好的模型,更新程序将立即更新全局模型,无需等待其他边缘节点(异步)
为控制异步聚合导致的模型过时,更新器对接收到的模型更新进行了加权惩罚的模型聚合
问题:这些边缘节点【1,2,...M】算不算聚类?
算聚类,按照真实世界的地理位置划分 / 按照客户端-边缘节点的关联策略选择边缘节点与对应客户端集群
这种聚类和传统聚类的主要区别是
- 本文的聚类为了提高联邦学习系统的性能和效率
- 传统聚类为了数据分析或模式识别。
3.2. HiFL解决的问题
3.2.1. 异步边缘云模型聚合:

![]()
-
(边缘节点 m 在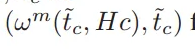
版本下的模型上进行 Hc 次本地训练后得到的模型参数,
版本)
- 其中 ατ 为陈旧度为 τ 的边缘模型
对全局模型的权重。ατ 越小,FL 训练次数越多,ατ 越大,准确率波动越大。通过调整 ατ 的取值,可以自适应地控制模型学习过程中收敛速度和方差减小之间的权衡
HiFlash 的

是这样的
其中,α∈(0,1)为边缘模型的初始模型权值
用惩罚系数υ∈(0,1)来减小 α ,减轻由于较大的过期 τ 引起的误差
3.2.2. 同步客户端-边缘模型聚合:

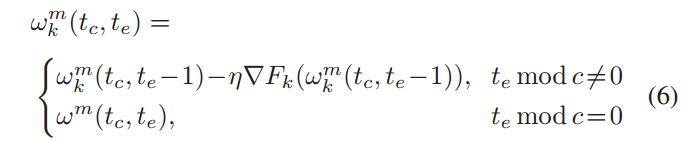
如果边缘时间戳 𝑡𝑒 不是 𝑐(本地更新轮次) 的倍数,客户端 𝑘 会根据其本地数据计算梯度并更新其模型参数。
如果 𝑡𝑒 是 𝑐 的倍数,客户端 𝑘 会停止本地更新,并等待边缘节点 𝑚 的同步信号
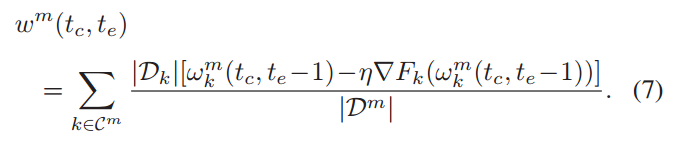
边缘节点 𝑚 会根据其管理的客户端集合 𝐶𝑚 中所有客户端的更新聚合一个新的边缘模型。每个客户端的更新根据其数据集大小 ∣𝐷𝑘∣ 进行加权,然后聚合成边缘节点的模型参数
3.3. HiFL 理论分析:
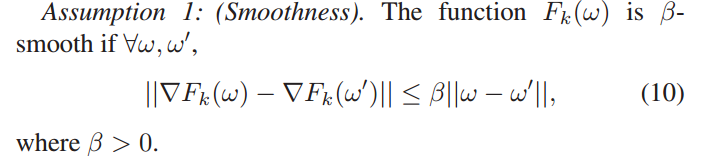
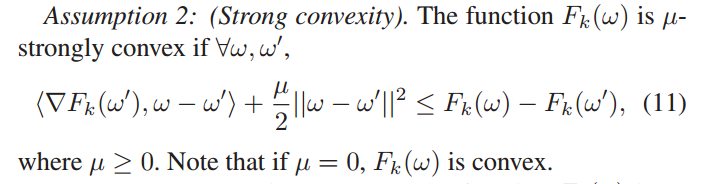
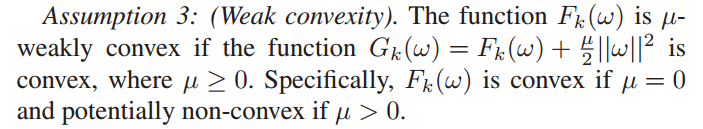
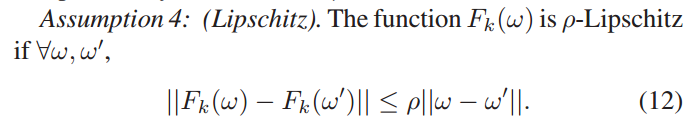

定义1中引入了拟聚类模型学习的概念,以寻找通过同步客户端-边缘结点模型聚合训练的边缘模型与假设训练数据存在于虚拟中央存储库的虚拟聚类模型之间的损失分歧
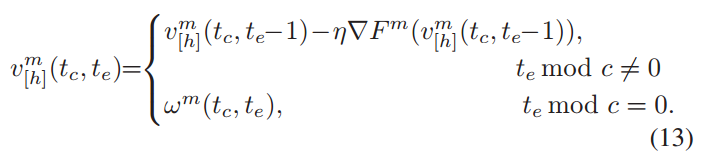




备注 1: 收敛速率 (Convergence Rate)
𝛼𝜏 控制 HiFL 的收敛速率:较小的 𝜏 导致 𝛼𝜏 较大,随着全局聚合次数 𝑇𝑐 的增加,𝜅(收敛因子)

将更快地趋近于0,收敛速率更快
𝛼𝜏 随 𝜏 减小而增加,依据:给陈旧模型分配较低的权
![]()

备注 2: 收敛界限 (Convergence Bound)

当 𝑇𝑐 趋向于无穷大时,𝜅 趋向于0,强凸函数收敛界限减小为
![]()
,收敛界限主要受客户端随机梯度 𝑉、客户端-边缘节点发散 𝛿max 和边缘节点-云端发散 Δ 的影响,而 𝛿max 和 Δ 的值由客户端-边缘节点关联策略决定。对于弱凸函数,可以发现类似的观察结果。
解决思路:设计合理的客户端-边缘节点关联策略减小这些差异,从而提高算法的收敛性能。
备注 3: 𝜏 对收敛界限的影响 (Impact of 𝜏 on Convergence Bound)
较大的 𝜏 会导致收敛速度减慢,需要更多的全局更新次数 𝑇𝑐 来达到相同的收敛水平。设计算法时时效性控制和更新频率选择的依据。
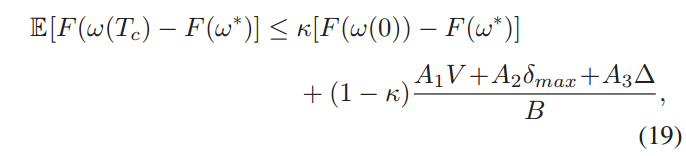
的右侧可以重写为 𝑈=(𝐶1)𝑇𝑐(𝐶2−𝐶3)+𝐶3
其中
![]()
,𝐶2=
![]()
,
![]()
𝐶2 通常非常大,假设 𝐶2−𝐶3>0,因此 𝑈 随着 𝐶1 的增加而单调增加,
随着 𝜏 增加,𝐶1 增加, 𝑇𝑐 如果固定,较大的 𝜏 对应较大的上界 𝑈 ,收敛界宽松;
如果想尽快收敛,尽可能减小 𝜏 ,增大 𝑇𝑐;
对于弱凸函数,可以发现类似的观察结果。
3.4. 实验验证 HiFL 性能缺陷:
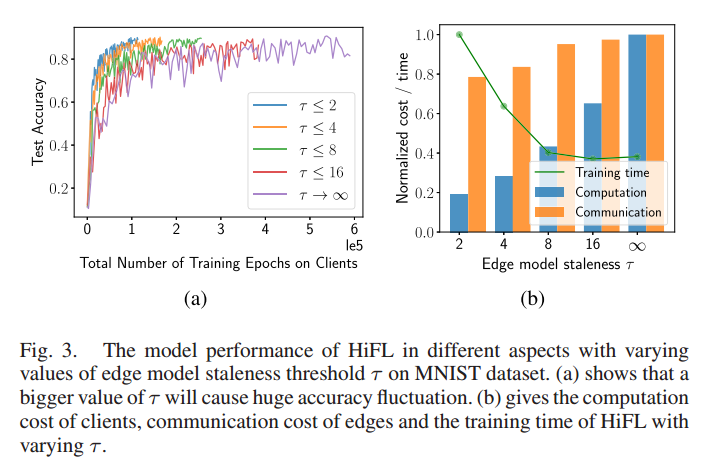
HiFL的三个性能指标:云端的总训练时间、边缘的通信成本和客户端的计算成本
(a)大的模型过时程度 τ 表示可以同时进行训练的边缘节点数量多,导致收敛缓慢、精度波动剧烈
(b)不进行过时控制的 HiFL 会产生更高的通信和计算成本
思路:解决过时问题,考虑云端的总训练时间、边缘的通信成本和客户端的计算成本,利用DRL自适应地进行恰当的过时阈值选择
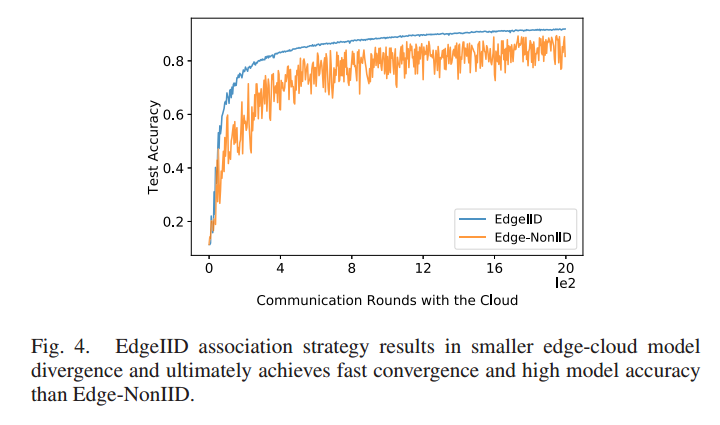
对多种不同的客户端关联策略进行研究,总结不同的 客户端边缘散度 和 边缘云散度 对 HiFL 性能的影响。得出结论:边缘云散度 Δ 作为主导因素,对云模型精度产生负面影响
eg:考虑一个具有云服务器、10个边缘节点和100个客户端的FL系统。每个客户端只拥有MNIST数据集中一个类的样本。edge -IID 意味着客户端被聚到不同的边缘组中,边缘节点上的数据分布是 IID 的(例如,来自10个类的相同数量的样本)。而在 edge - noniid 情况下,一个边缘节点维护的样本来自5个类。
Edge-IID 关联策略将边缘云模型差异较小的客户端分组,最终实现快速收敛和高精度。
思路:解决 non-IID ,减小客户端-边缘节点以及边缘节点-云端的数据分布差异。设计一种异构感知的客户端边缘关联策略,通过智能地选择和组合客户端,使每个边缘节点上的数据分布更接近IID分布
4. HiFlash
HiFlash 是一种增强的 HiFL
在边缘-云层配备了自适应过期控制,利用DRL为边缘节点分配合适的 𝜏 ( 𝜏 大,允许同时进行训练的边缘节点数多,训练时间短,但计算、通信代价增加,收敛慢);
在客户端-边缘层配备了异构感知关联 ,利用客户端与边缘节点的双向选择,尽量减小客户端-边缘节点以及边缘节点-云端的数据分布差异,使得每个边缘节点上的数据分布更接近全局IID分布。
4.1. 边缘节点-云端自适应过时控制
HiFL 存在的问题:固定过时控制需要为所有边缘节点预定义一个过时阈值,这在复杂的动态FL环境 (例如,边缘的高度动态通信能力,当前训练边缘的时变数量) 中效果不佳,降低了模型性能。
对应的解决思路:根据控制域的条件(如客户端的计算资源、边缘的通信能力和训练时间),为加入全局模型训练的边缘节点设计一个自适应边缘陈旧阈值
使用的解决方法:建立系统成本模型,采用深度强化学习方法动态控制陈旧阈值。
4.1.1. 构建系统代价模型
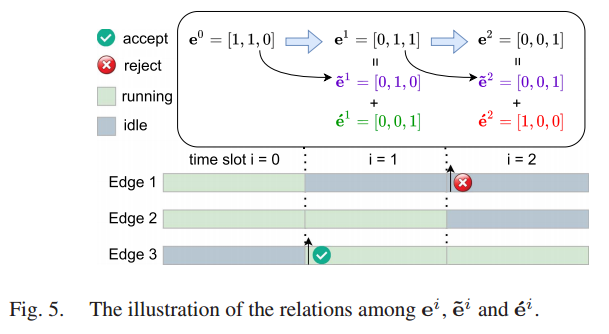
System Cost Model:
为表示环境动态,采用分时结构进行时效控制,将长期的时间范围划分为一系列离散的时隙。由于每个时隙的长度通常很短,假设在时隙 i 开始时最多有一个边缘节点向云发送 check-in request。在时隙结束时,最多有一个边缘节点完成边缘模型训练,并将模型更新上传到云服务器。

ei =
![]()
+
![]()
- ei:时隙 i 时,对应边缘节点的运行/空闲模式向量
-
前一个时隙未完成模型训练任务的边缘节点向量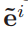
-
发送 check-in request 并被云服务器接受参加FL训练的边缘节点向量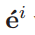
Computation cost:
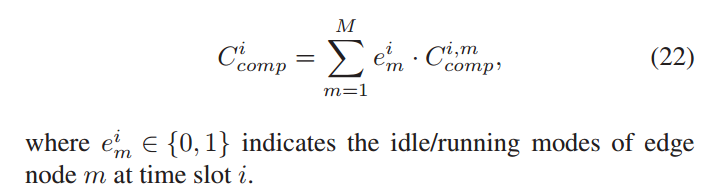
![]()
表示所有客户端在时隙 i 的计算代价,ei m∈{0,1} 表示边缘节点 m 在时隙 i 的空闲/运行模式
-
在给定时隙 i 时,边缘节点 m 的计算代价为其关联客户端的计算代价之和。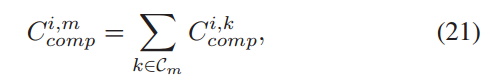
-
表示客户 k 的计算成本。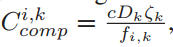
-
- 其中 fi,k 为客户 k 在时隙 i 的处理速度,ζk 为客户 k 的处理密度(每单位数据所需的计算资源)。Dk 为客户 k 的训练数据在一次局部迭代中的总比特数,c为局部迭代的次数。c 和 Dk 的乘积表示客户端k的工作量
Communication cost:
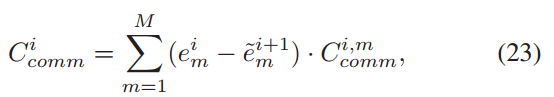
![]()
表示在时隙 i ,所有客户端的通信代价
-
为在时隙 i 时,边缘节点 m 的通信代价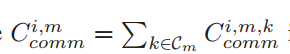
-
为边缘节点 m 与客户端 k 在时隙 i 的通信代价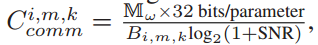
-
- 其中 Bi,m,k 为在时隙 i ,边缘节点 m 为客户端 k 分配的带宽,
为 ω 的参数个数,信噪比 SNR 设为17 dB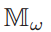
- 其中 Bi,m,k 为在时隙 i ,边缘节点 m 为客户端 k 分配的带宽,
4.1.2. 构建自适应阈值优化问题并表示为MDP
模型过时控制的主要目标是达到目标模型训练性能(例如目标精度Ω)的同时,使HiFL系统的总系统成本(包括云的总训练时间、边缘的通信成本和客户端的计算成本)最小
将自适应阈值优化问题表示为MDP
- 状态 si =
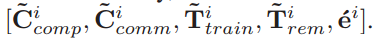
-
- 每个边缘节点完成边缘模型计算估计的所需的计算成本、通信成本、时隙;当前边缘节点的剩余训练时间;当前边缘节点 check-in requst 信息
- 动作 ai 的决策空间为{−1,0,1,…,τmax}。(拒绝请求(-1)、不改变当前状态(0)以及不同的时效性阈值(1到𝜏max))一旦执行动作ai,边缘的空闲/运行模式更改为
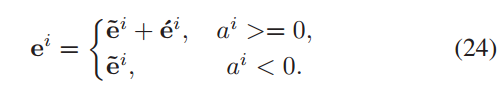
- 奖励
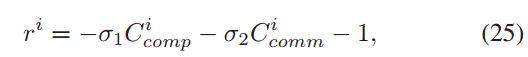
目标:最大化 从时隙 𝑖 开始到达到目标模型准确度所需的总训练时间 𝐼 结束的累积折扣回报 𝑅𝑖,通过选择能够最小化即时回报中成本项的行动来实现
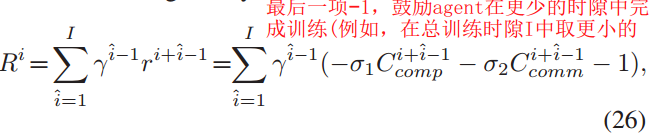
4.1.3. DDQN 算法实现
传统的 Q-learning 算法先估计当前状态下的最佳动作的 Q 值,然后使用这些估计的 Q 值来指导决策。这可能会导致 Q 值的过度估计(Overestimation)。
使用 DDQN,引入两个神经网络,一个用于选择最佳动作(目标网络),另一个用于估计 Q 值(估算网络)。这两个网络交替地被用来选择和估算 Q 值,以减少 Q 值的过度估计问题

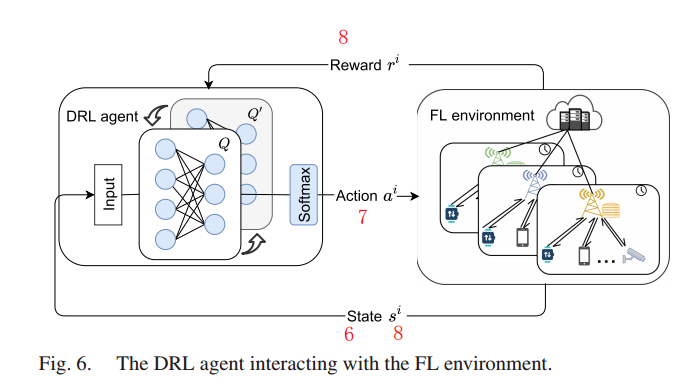
将当前状态信息 si 输入动作值函数 Q, DQN 生成动作 ai 作为 FL 模型训练的边缘节点的过时阈值 𝜏 。在与 FL 环境进行几轮交互后,DRL agent 从经验记忆中抽取一些状态-动作对来求解
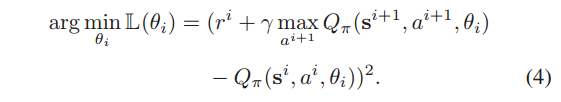
转变成:
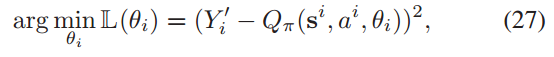
- 目标值与当前网络预测值差的平方。这个值越小意味着网络预测与实际目标值越接近。
-
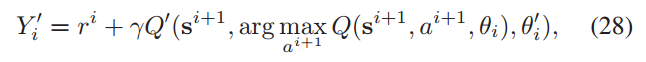
动作值函数Q(si, ai)通过梯度下降最小化L(θi)来更新,即
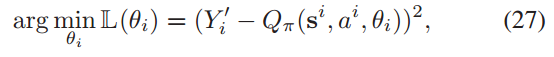
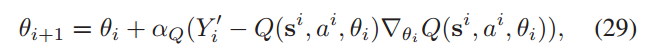
DDQN算法在每一步迭代中调整网络参数,使得预测值更接近目标值,从而提高 agent 在环境中的决策质量。这个过程重复进行,直到网络参数收敛到一个稳定的状态,此时 agent 能够做出接近最优的决策。
DDQN通过以下方式减少高估问题:
- 双网络结构:使用两个网络(一个估算网络和一个目标网络),目标网络的参数更新得更慢,提供了一个更稳定的Q值估计作为目标值。
- 最大化操作:在选择目标Q值时,使用 argmaxargmax 操作选择下一个状态的最大Q值对应的动作,但仅使用这个动作的Q值来更新当前状态的Q值,而不是简单地使用所有可能动作的最大Q值。(感觉像缓存一个旧的版本,为了维稳,利用陈旧,解决高估问题?)
这样,DDQN在更新Q值时,既考虑了最优动作的潜在价值,又避免了对所有动作的Q值都进行过度乐观的估计,从而减少了高估问题,提高了学习过程的稳定性
4.2. 客户端-边缘节点异构感知策略
4.2.1. 构建代价函数
边缘设备之间的不相似性:
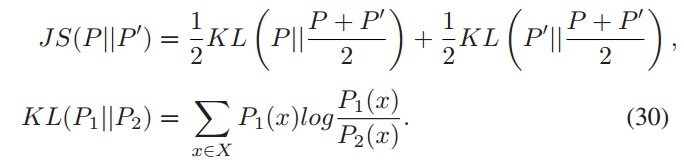
JS散度用于衡量边缘节点上的数据分布与全局IID分布之间的差异,较小的JS值意味着边缘节点上的数据分布更接近全局IID分布,这有助于提高联邦学习模型训练的效率和准确性。通过选择具有较小JS值的客户端-边缘节点关联策略,可以减少数据分布的偏差,从而有助于提升模型的整体性能。
边缘节点 m 相关联的客户端 k 的响应延迟:
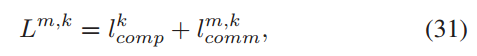
Lm,k :客户端 𝑘 与边缘节点 𝑚 之间的响应延迟,是计算延迟和通信延迟的总和。
-
:客户端 𝑘 的计算延迟的平均值,基于客户端 𝑘 在时间跨度上计算延迟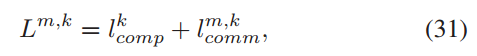
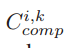
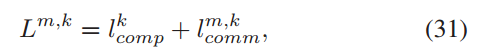
-
:边缘节点 𝑚 与客户端 𝑘 之间的通信延迟的平均值,这是基于两者之间通信延迟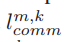
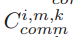
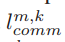
边缘模型聚合的响应时间为边缘节点 m 相关联的客户端 k 的响应延迟的最大值
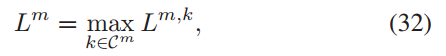
目标是使这个值最小,因此在优化通信和计算效率的情况下,选择的具有较低响应延迟的客户端,即要求
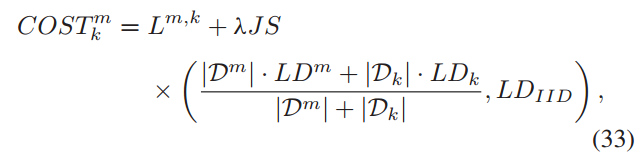
最小
4.2.2. 双向选择实现客户端-边缘关联:

边缘节点通过双向选择实现客户端-边缘节点关联:
边缘节点选择客户端:
- 如果边缘节点m的客户端集群为空,则边缘节点在其通信范围内的未关联客户端中选择响应时延最小的客户端。
- 否则,边缘节点根据关联成本
选择未关联的客户端,成本越低表示客户端与边缘节点的关联越优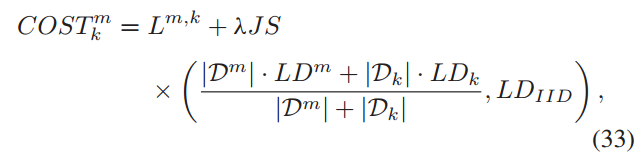
客户端选择边缘节点:如果当前有多个边缘节点选择了一个客户端,则该客户端将随机选择一个边缘节点
双向选择过程一直持续,直到所有客户端都与一个边缘节点相关联
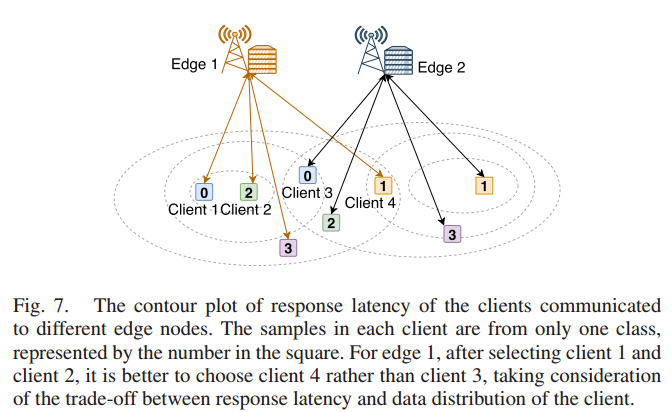
5. 效果:重点是实验设计,每一部分实验在验证论文中的什么结论
5.1. 各种超参数设置的性能评估
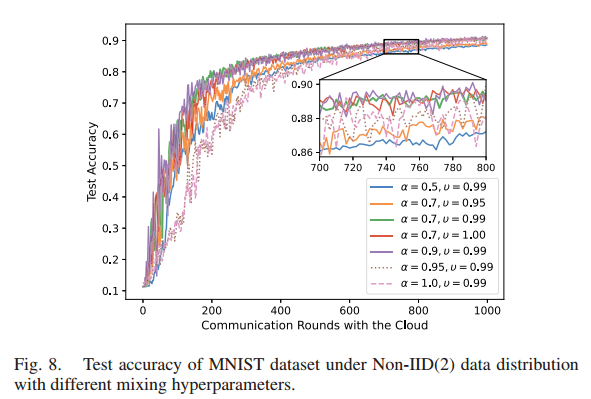
评估不同设置 α 和 υ 下 HiFL 的测试精度。在不同混合超参数设置的非iid(2)数据分布下,HiFL具有鲁棒性,可以收敛。但是,α值过大或过小都会导致收敛速度变慢。
通过网格搜索实验,确定后续实验设置中选择 α = 0.7, υ = 0.99
当α太大时(例如,α = 0.95, α = 1.0),当前全局模型无法保留来自前一轮的关于全局模型的信息。
而较小的α(例如,0.5)将阻止全局模型从新上传的边缘模型中学习。
5.2. 模型精度与计算效率评价
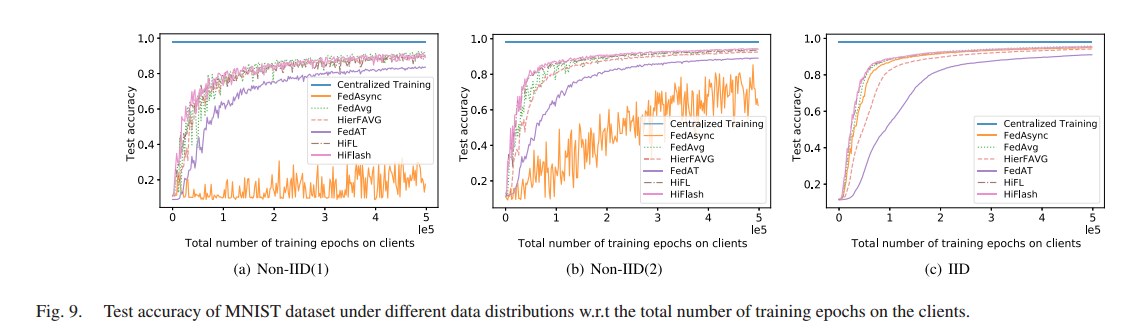
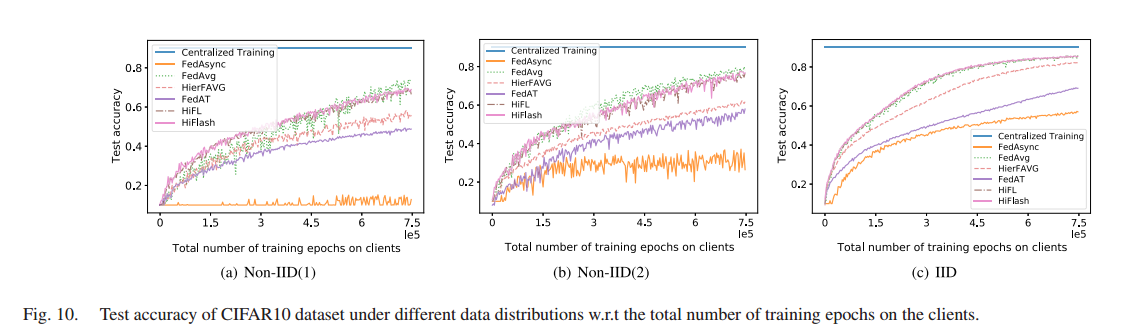
研究三种数据异质性下不同训练方法的模型精度和计算效率。HiFlash 的性能优于其他方法
考虑到分层 FL 在一个全局轮中执行更多的局部计算以减少与云的昂贵通信,选择根据客户端的训练 epoch 总数来评估测试准确性。
分别以MNIST和CIFAR10数据集为例,研究了三种数据异质性下不同训练方法的模型精度和计算效率。由于集中式训练方法将所有的数据收集到云端进行模型学习,因此不会在设备上产生任何计算成本。只使用集中学习的测试精度,为其他比较方法提供模型精度的上界。
HiFL和HiFlash结合了同步和异步模型聚合的优点,抑制了模型陈旧的负面影响,在IID情况下可以达到与FedAvg方法相当的训练性能。对于非iid的情况,HiFL 和 HiFlash 在比较客户端总训练次数的测试准确性时,表现略低于fedag。这是因为HiFL和HiFlash中的多轮客户端边缘聚合可能会导致一定程度的梯度发散,从而降低模型性能。此外,由于HiFL和HiFlash采用异步模型聚合设计,与 FedAvg 相比,它们不可避免地存在过时效应。
HiFL 和 HiFlash 的性能优于其他分层FL方法(如HierFAVG)。由于分层FL的设计是为了以更多的局部计算为代价来减少昂贵的通信,因此分层设置下 FedAvg 的扩展 HierFAVG 与 FedAvg 相比计算效率较低。这是因为对于相同数量的局部训练 epoch , HierFAVG 比 fedag 执行更少的边缘云聚合。而 HiFL 和 HiFlash 中的异步更新机制很好地平衡了全局模型和上传边缘模型,与 HierFAVG 和 FedAvg 相比,HiFL 和 FedAvg 之间的性能差距明显缩小,表明 HiFL 和 HiFlash 中的异步聚合比其他分层 FL 方案更具计算效率。
HiFL 和 HiFlash 的性能优于其他基于同步或异步的方法。例如,异步 FL 方法(如FedAsync和FedAT)的测试精度低于 HiFL 和 HiFlash ,因为它们忽略了有偏差的数据分布和模型过时对云模型精度的负面影响。
FedAsync算法曲线剧烈振荡的原因有两点:
(1)FedAsync算法中的全局模型在一个客户端上传其更新后的模型后就会更新,而无需等待离散者。这种异步聚合给生成的全局模型的性能带来了很大的不确定性,特别是在非iid情况下。而其他算法则融合不同的客户端模型,以保证全局模型的泛化能力;
(2)陈旧效应使FedAsync收敛速度变慢,在面对较大的陈旧时导致性能不稳定
5.3. 通信效率评价
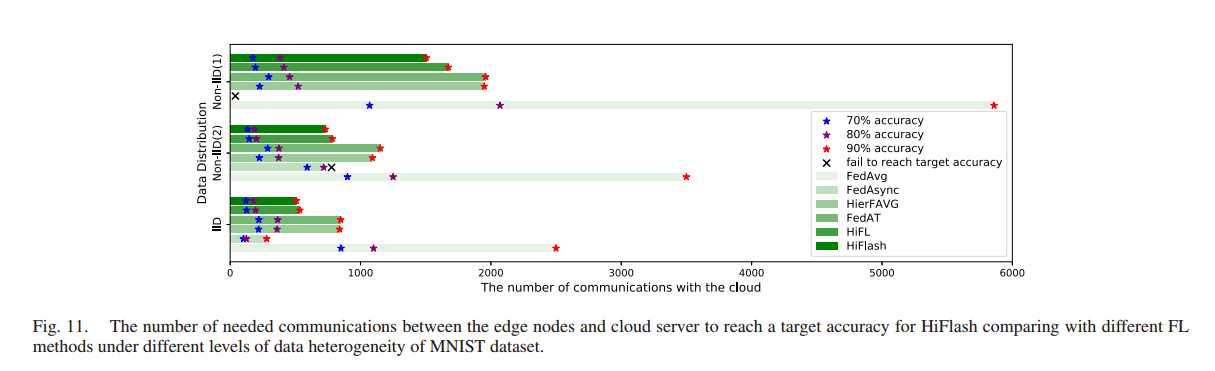

比较不同 FL 方法在不同的数据异构程度下达到目标精度所需的边缘节点与云服务器之间的通信次数。HiFlash 总能用最少的通信达到最高的精度
将 FL 进程中的通信次数定义为边缘节点(或两层FL框架中的客户端)与用于模型交换的云服务器之间的总通信次数。与云端的通信次数越少,表示传输到云的模型数据量越小。
对于MNIST数据集,不同方法所需的通信次数随着目标精度的提高和客户端数据异构性的提高而增加。除了FedAsync算法外,无论数据分布和目标精度如何,HiFL方案都是其他基于FL的方法中通信效率最高的。例如,在Non-IID(2)分布的MNIST数据集上,HiFL的通信次数比FedAT减少31.9%,比HierFAVG减少28.2%,比fedag减少77.6%,目标准确率为90%。尽管在MNIST数据集的IID设置中,FedAsync可以用比我们提出的HiFL方法更少的通信数达到目标精度,但它无法处理参与客户端固有的数据异质性(例如Non-IID(2)和Non-IID(1)情况)。例如,FedAsync在Non-IID(2)分布下无法达到90%的目标准确率,在Non-IID(1)分布下甚至无法达到70%的目标准确率。案例,表明FedAsync不适用于数据以非iid方式分布的实际FL场景。
分层FL方法(例如,HiFL, HierFAVG)显著减少了由于客户端边缘聚合而导致的与云的昂贵通信。此外,增强的HiFlash框架,配备自适应状态控制,与HiFL相比,可以进一步加快模型训练过程,减少与云的通信轮数(例如,在Non-IID(1)数据分布情况下,减少10%的通信轮数)。这一结果与收敛性分析一致,即通过将τ控制在较小的值,模型将在更少的通信回合Tc内收敛。因此,客户端聚合和过期控制有助于提高HiFL和HiFlash的通信效率。
对比FedAvg和HierFAVG方法,FedAvg方法每轮训练中有10个客户端与云通信,而HierFAVG方法中有5条边与云通信。此外,HierFAVG在每轮客户机上使用更多的本地计算来减少全局训练轮数,因此,在通信成本(例如与云的通信次数)方面,HierFAVG比fedag要好得多。
对于更复杂的数据集(如CIFAR10),与所有基于FL的方法相比,HiFlash可以在所有数据分布情况下以最小的通信轮数达到不同的目标精度。如图12所示,在非iid(1)数据分布场景下,HiFlash需要6403个与云的通信数才能达到60%的目标准确率,比FedAT、HierFAVG分别小23.07%、42.23%和89.82%和fedag。结果表明,无论是基于异步的FedAT还是基于同步的HierFAVG方法,HiFlash都优于现有的分层FL算法。
基于FEMNIST数据集的评价结果
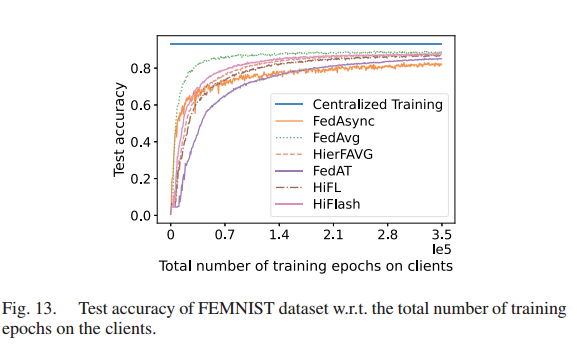
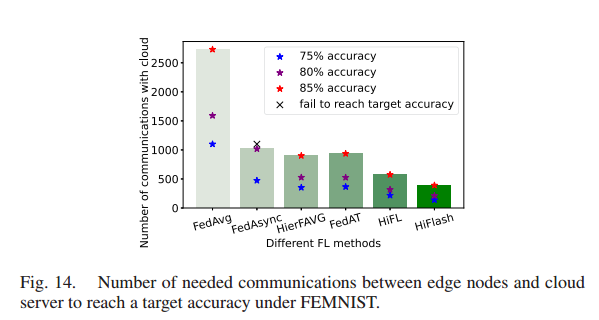
评估了 HiFlash 在 FEMNIST 数据集下的性能。评估结果表明,HiFlash方法可以应用于标签分布和特征分布都存在偏差的真实数据集。
- 客户端的数据分布是 non-IID 的(特征分布、标签分布和数量分布)。HiFlash 仍然优于其他分层 FL 方法(如HierFAVG),这与 MNIST 数据集下的实验结果相似。
- 与其他FL方法相比,HiFlash 方法与云端的通信次数最少。
5.4. 准确性-通信权衡
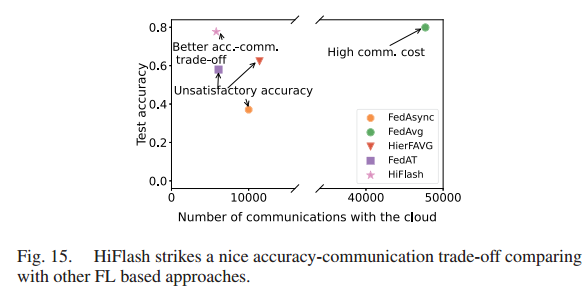
研究不同 FL 方法的准确性和通信权衡:HiFlash 虽然模型精度略有下降,但显著降低了通信成本
以非iid(2)分布的 CIFAR10 数据集为例,绘制了最高的模型精度和与云端的通信轮数。流行的 FedAvg 方法存在通信成本高的问题,基于异步的 FedAsync 和分层 FL 方法(例如HierFAVG和FedAT) 未能达到令人满意的精度。相反,HiFlash能够在模型精度和通信效率之间取得很好的平衡。
具体来说,HiFlash显著降低了通信成本(例如,比fedag降低了87%),但模型精度略有下降(例如,2.1%)。与分层FL方法(例如,FedAT和HierFAVG)相比,HiFlash能够实现5%以上的通信成本降低和16%的模型精度提高。此外,随着数据异质性的增加,HiFlash的优势可以被放大(见图11和图12)。
5.5. 过时阈值控制效果
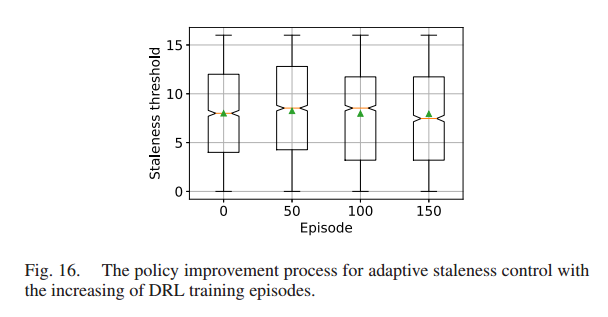
用于自适应过时控制的 DRL agent 在与 FL 环境交互并从 DRL 训练集中学习的过程中,不断改进过期阈值决策策略。从倾斜的数据分布中可看出,HiFlash 中更多的决策选择了比随机决策策略更小的过期阈值,实现了高效的模型训练。
采用箱线图(boxplot)图形化地描述了不同训练集中陈旧阈值决策分布的五个数总结,由最小观测值、下四分位数、中位数、上四分位数和最大观测值组成。上四分位数,中位数和较低的四分位数组成一个有隔间的盒子。不同部分之间的间距表示数据分布的方差和偏度,绿色三角形表示过时阈值的平均值。
- 第 0 个 episode 的决策策略为 HiFL 中采用的随机过时控制策略
- 第 150 个 episode 的改进策略为HiFlash方法所采用
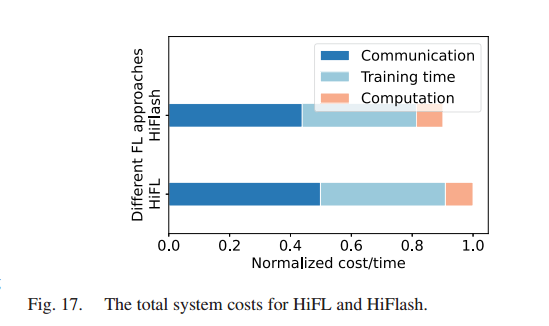
HiFL 和 HiFlash 的总系统成本。HiFlash 通过自适应过时控制策略获得比 HiFL 低的系统成本低
为比较 HiFL 和 HiFlash 的系统成本(包括客户端的计算成本、边缘的通信成本和云的训练时间),将系统成本归一化为[0,1],简单地除以最大值。采用这种归一化方法,计算成本和通信成本相应降低。
- HiFL的归一化成本为1,说明HiFL带来了较高的系统成本。
- HiFlash 通过自适应过时控制策略获得低系统成本(虽然 HiFlash 中的 DQN 训练会带来额外的计算开销,但可以在计算资源充足的云服务器上以离线的方式进行)。
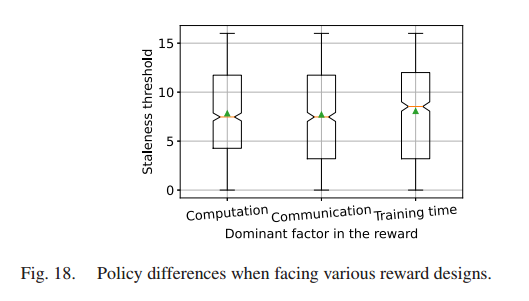
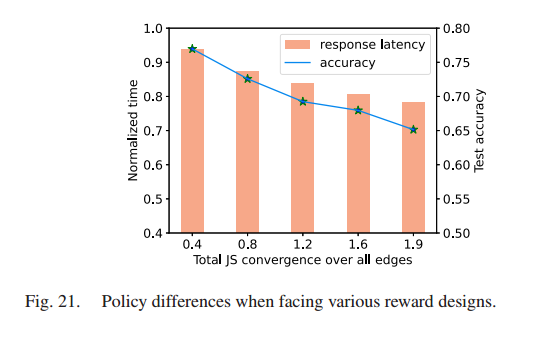
给计算成本、沟通成本和训练时间分配不同的权重(调整σ1和σ2的值),检验不同奖励设计下的策略差异。
- 当对资源成本(如计算和通信成本)赋予较高权重时,由于担心严重的过时效应,进行过时控制的DRL代理倾向于选择较小的阈值。
- 当训练时间的权重较高时,采用更大的过时阈值做出更多的决策,促进模型的并行性
5.6. 异构感知客户端边缘关联的影响
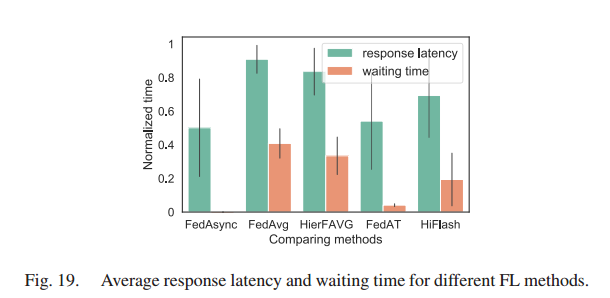
评估在客户端-边缘聚合阶段,边缘相关的客户端的响应延迟Lmk和等待时间Lm。
HiFlash可以在响应延迟和数据异构之间进行权衡,获得令人满意的模型性能
对于HiFlash,设置λ = 300,为每个边缘节点形成一个更加标签平衡的数据集。由于数据异构性和延迟减少之间的权衡,平均响应延迟可能更长。
FedAsync 的平均响应延迟和等待时间是最低的,因为它不需要等待掉队者。FedAT 与 HiFL 相似,也是异步分层FL方案,具有更低的响应延迟和等待时间。但只关注减少客户端边缘关联过程中的延迟,没有考虑缓解数据异构性。FedAsync 和 FedAT 都会导致如图9和图10所示的精度降低,以及如图11和图12所示的更多通信。
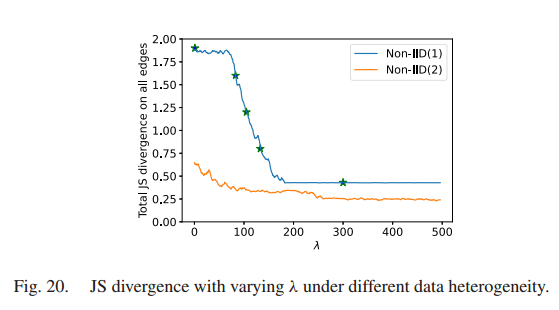
λ 越大,和响应延迟相比,越关心边缘节点上的数据分布,总 JS 散度随着 λ 的增大而减小。
JS散度越大,边缘数据分布的偏差越大,精度下降越显著。
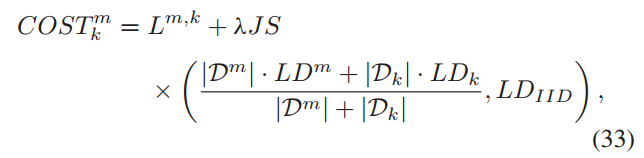
通过控制参数λ,HiFlash 可以灵活地为边缘节点在响应延迟和模型精度之间取得平衡
6. (备选)自己的思考
6.1. 与 FedAvg 比多了多少计算与通信代价
6.2. 和 GitFL 比的相同与不同
聚类方法及其原理
十分钟掌握当前主要聚类方法及其原理(适用于新手入门)_哔哩哔哩_bilibili




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











