






前段时间,张元英转圈舞火遍全网,有不少网友相继模仿,想要凑个热闹奈何才艺有限,所以今天就给大家推荐一个用一张照片就能生成跳舞视频的模型,他就是MimicMotion。
如果感兴趣的话,推荐大家使用。当前模型支持生成最大 72 帧、576x1024 分辨率的视频。遇到内存不足的问题,可以适当减少帧数。如果想要本地部署,推荐使用 Nvidia V100 GPU 验证带有 torch 2.x 的 python 3+,具体的方法请上Github看教程。
如果本地没有条件部署,如果电脑本地没有条件部署,可以尝试Data_Flop平台一键式部署,需要的小伙伴可以自行使用。
官网地址:MimicMotion
Data_Flop平台链接:https://www.data-flop.com/shareLogin?5142
论文地址:https://arxiv.org/abs/2406.19680



其实现在AI图像生成已经挺厉害的了,但是视频生成如果仔细看还是能够看出不少的问题,比如动作不好控制、视频长度受限、表情细节不够丰富等等。腾讯和上海交通大学联合推出的开源视频生成框架MimicMotion,主要解决具有置信度感知姿势指导的高质量人体运动视频生成这个问题。
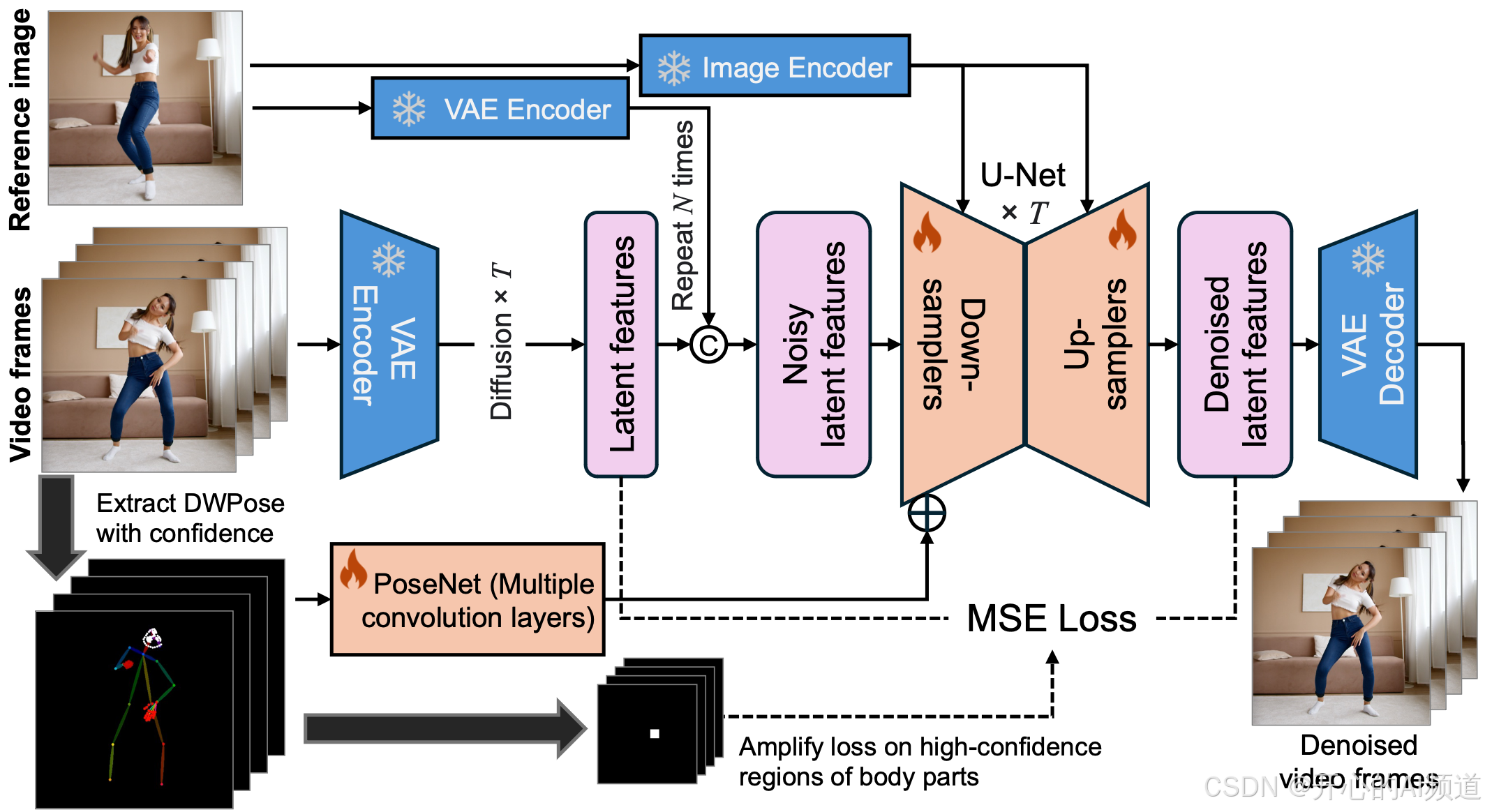
(MimicMotion 框架概述)
从框架图中可以看到,首先,在准备数据的时候,它会收集多种人类动作的视频,然后把这些视频处理,提取出动作姿态的信息,再和一张参考图片一起交给模型。这个模型它有个比较讨巧的办法来处理动作姿态,可以知道哪些姿态信息更可靠,这样生成的视频就更准确。还有它特别关注手的部分,会想办法让手的动作看起来更自然,不会变形。
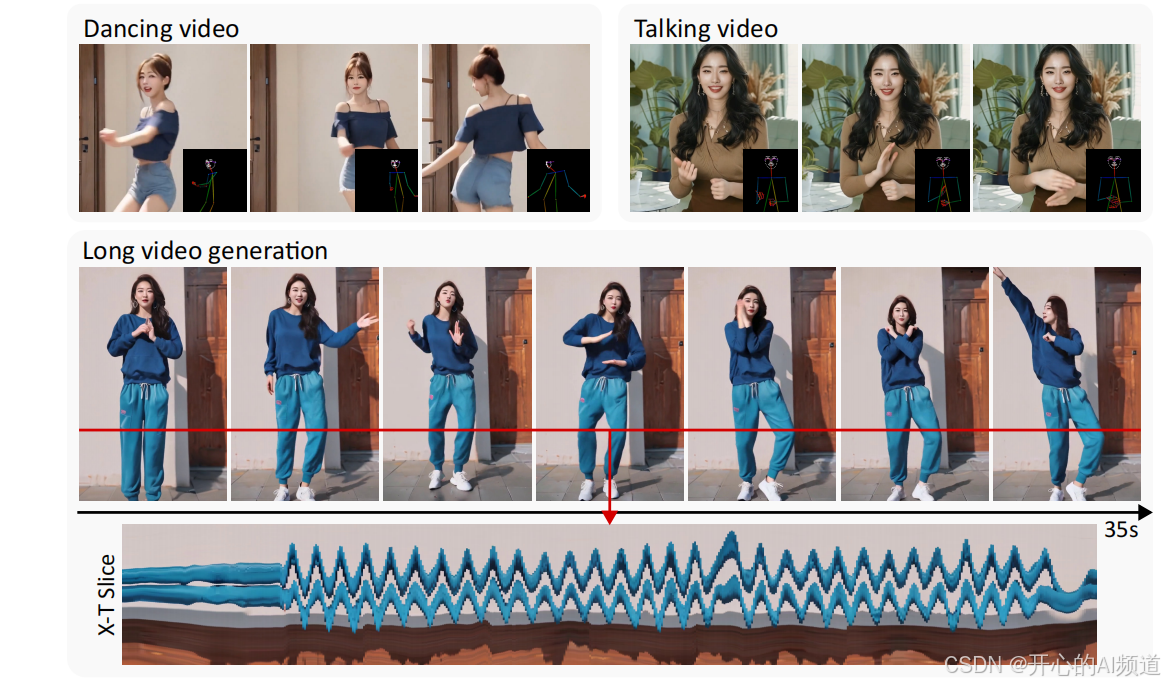
另外,想要生成很长的视频时,模型会把长视频分成一小段一小段的,然后巧妙地把这些小段融合在一起,这样整个长视频就很流畅,不会出现卡顿或者突然变化的情况。
如果需要本地代码,请自取:链接:https://pan.quark.cn/s/7c4cf71c4938,提取码:sJ3U


















 1066
1066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











