









Deliberated Domain Bridging for Domain Adaptive Semantic Segmentation
Abstract
许多UDA的工作就是尝试通过各种中间空间来逐步缓解域差异的现象,称为域桥接(DB)。在这篇工作中,我们求助于数据混合来建立了一个deliberated domain bridging(DDB)。DDB的核心包含两个步骤,一个步骤是双路径的域桥接(dual-path domain bridging)来生成两个中间域,使用了一个粗粒度和细粒度数据混合的技术。另一个步骤是交叉路径知识蒸馏,以两个通过中间样本进行训练的互补模型作为"教师",以多"教师"知识蒸馏的方式培养出一个优秀的"学生"模型。这两个步骤以一种交替的方式工作,相互强化,产生具有较强适应能力的DDB。
Introduction
在这篇文章中,我们同时在输入空间和标签空间中构建中间表示,通过基于混合的数据增强技术。首先,我们将数据混合的方法分为两类:全局混合和局部替换。全局混合的方式可能会造成像素级模糊的问题(比如行人和车重叠在一起),基于局部替换的混合方法可以更好的保护分割主体的语义完整性。其次,为了能够充分利用局部替换的数据混合方法,我们进一步从两个补充的角度来更深度的探索它。通过粗的区域级的混合(CutMix)和细粒度的类级混合(ClassMix)。粗的区域级混合域桥接帮助模型去利用上下文信息来减少语义的混淆(比如大巴火车这间的难以区分)。互补的,细粒度的类级混合域桥接可以帮助模型去充分的探索每个类别的特性,使得每个主体是可区分的。但是,这两个方法趋向于使模型过多的依赖于上下文信息或者类别固有的特征,在目标域上分别导致了类的偏差和混淆。
在这篇文章中,作者提出了DDB来小心地利用数据混合技术将源域上的知识逐步转移到目标域上。作为一个优化策略,DDB包含了两个交替的步骤,Dual-Path Domain Bridging (DPDB)和Cross-path Knowledge (CKD)。第一步,利用粗的区域级混合技术和细粒度的类级混合技术来构建两个互补的桥接路径用来训练两个教师模型,取得了双粒度的域桥接。第二步,CKD使用两个互补的教师模型在目标域上指导一个理想的学生模型来实现适应性分割。这两个优化的步骤交替进行,学生模型和教师模型共同进步。
Deliberated Domain Bridging for DASS
Revisting Existing DB Methods.
global interpolation mix:
x
n
e
w
x_{new}
xnew = λ·
x
s
x_s
xs + (1-λ)·
x
t
x_t
xt
y
n
e
w
y_{new}
ynew = λ·
y
s
y_s
ys + (1-λ)·
y
t
y_t
yt
就是通过一个比率将源域样本和目标域样本的标签和图像混合在一起。
local replacement mix
x
n
e
w
x_{new}
xnew = M⊙
x
s
x_s
xs + (1-M)⊙
x
t
x_t
xt
y
n
e
w
y_{new}
ynew = M⊙
y
s
y_s
ys + (1-M)⊙
y
t
y_t
yt
通过掩码来实现局部替换
Analyzing DB Methods with Toy Game.
通过实验表明,粗/细粒度的域桥接方法可能相互促进也可能相互制约。
Analyzing the Local Replacement Based DB Methods with Visualization.
经过数据的可视化,我们发现粗/细粒度的域桥接方法都有各自的优缺点,现在最重要的是找到一个互补的方法来结合它们获得一种双赢的效果。
Progressively learning from Dual-grained Domain Bridging
Dual-Path Domain Bridging (DPDB).
首先,利用CutMix和ClassMix技术来构建coarse region-path(CRP)和fine class-path(FCP)。
然后,最小化像素级交叉熵(CE)损失来减轻域差异(使用源域数据训练模型)

这里的
M
C
M_C
MC指的是在CRP上训练的模型。
我们通过EMA的方式生成了一个教师网络,用于生成去噪的像素级伪标签。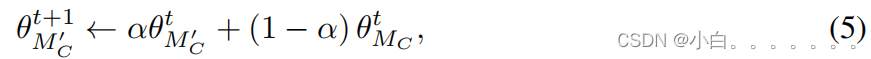
作者通过coarse region-path的方法生成了桥接图片
x
c
r
p
x_{crp}
xcrp和标签
y
c
r
p
y_{crp}
ycrp
生成了一个基于置信度的权重映射在训练过程中规范化目标域样本:
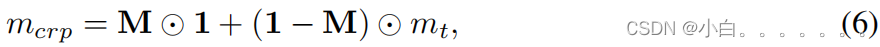
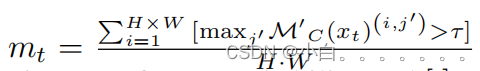
在region-path bridging上最小化交叉熵损失:
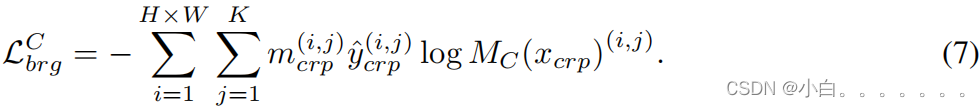
在CRP上总的损失函数: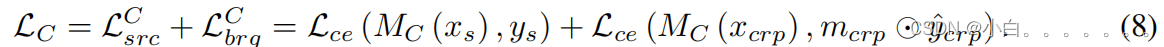
同样的,作者在FCP上做了相同的工作,损失函数记为
L
F
L_F
LF,下一个问题就是如何合适的整合这两种互补的知识。
Cross-path Knowledge Distillation(CKD).
受之前工作的启发,可以在输出空间中使用知识蒸馏将知识从教师网络转移到学生网络。在这里,我们对其进行了改革,从两个互补的教师中提取知识,并自适应地将整合后的知识转移给一个学生。请注意,这里只是在未标记的目标域中整合和转移互补的知识。
具体来说,就是对两名教师的输出进行了自适应加权和整合,作为指导,以驱动学生模型在未标记的目标领域中学习分割。此外,我们实验选择了“硬”蒸馏,即集成预测的softmax对数来生成一个独热向量,并利用CE损失监督学生模型MS。详细的蒸馏损失可以写成:
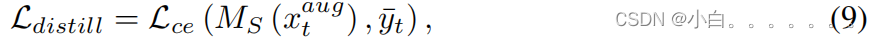
xaugt表示经过颜色抖动,高斯模糊增强的目标域样本,y-t由教师网络的softmax 对数加权集成获得。
直观地说,不同的样本,甚至一个样本中的不同像素,都需要两个教师模型的不同贡献来进行集成。通过计算分类层前的特征响应f(i)与每个类别的质心η(j)之间的距离,我们自适应地在目标域内生成一个像素级的权重图w(i,j)。在每个位置上,特征响应离某一类别的一个质心越近,就越有可能属于该类别,因此对集成效应的贡献就越大。这里以CRP举例,我们先求目标域上的类别质心:
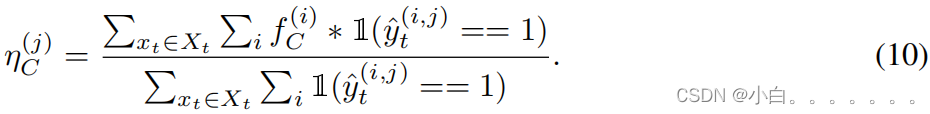
计算距离,生成权重图:
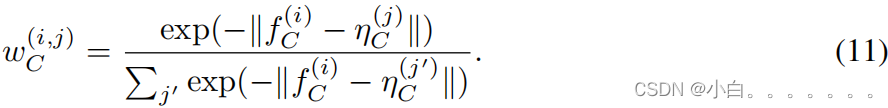
同样的,我们也在FCP上计算出了对应的权重图w(i,j)F,组合这两个权重图我们就得到了y-:
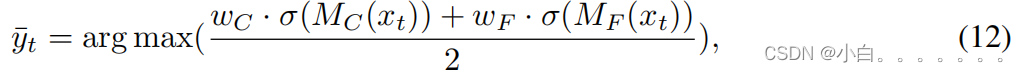
Ο()代表的是softmax函数。此外,学生模型也要源域数据的监督来生成区别性的特征:

学生模型总的损失函数可以表示为:

Alternation Optimization Strategy.
通过整合来自两个专家教师模型的互补知识,我们可以得到一个更好的学生模型。反过来,这个学生模型可以在下一轮一轮中初始化教师模型,从而产生两个更强的教师模型。他们互相宣传,取得了双赢的效果。最终,我们可以在最后一轮结束后获得最强大的学生模式。
总结:
就是通过两种不同的数据增强方法来训练两个教师模型,并通过知识蒸馏来生成一个最终的学生模型















 2007
2007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









