









SePiCo: Semantic-Guided Pixel Contrast for Domain Adaptive Semantic Segmentation
Abstract
之前的许多方法尝试去减轻有噪声的伪标签带来的影响,但是,他们忽略了具有相似语义概念的跨域像素的内在联系。因此,他们将难以处理跨领域的语义变化,并建立一个类别区分的嵌入空间,导致较弱的辨别力和较差的泛化性。在这篇工作中,作者提出了SePiCo,一种创新的单步骤适应网络,强调了单个像素的语义概念来推进学习类的可辨别性和跨域类平衡嵌入空间,提升了自训练方法的表现。作者首先提出了一个质心相关的像素对比,应用了整个源域上的类别质心或者单张图片的类别质心来指导学习可判别性特征。考虑到在语义概念上可能会缺少类别多样性,作者以一种分布的角度包含了足够数量的例子,称为分布相关像素对比。作者通过统计的有标签源域数据来估计每个语义类别的真实分布。此外,这样的优化目标可以通过隐式地包含无限个(非)相似对来推导出一个封闭形式的上界,使其计算效率高。
Introduction
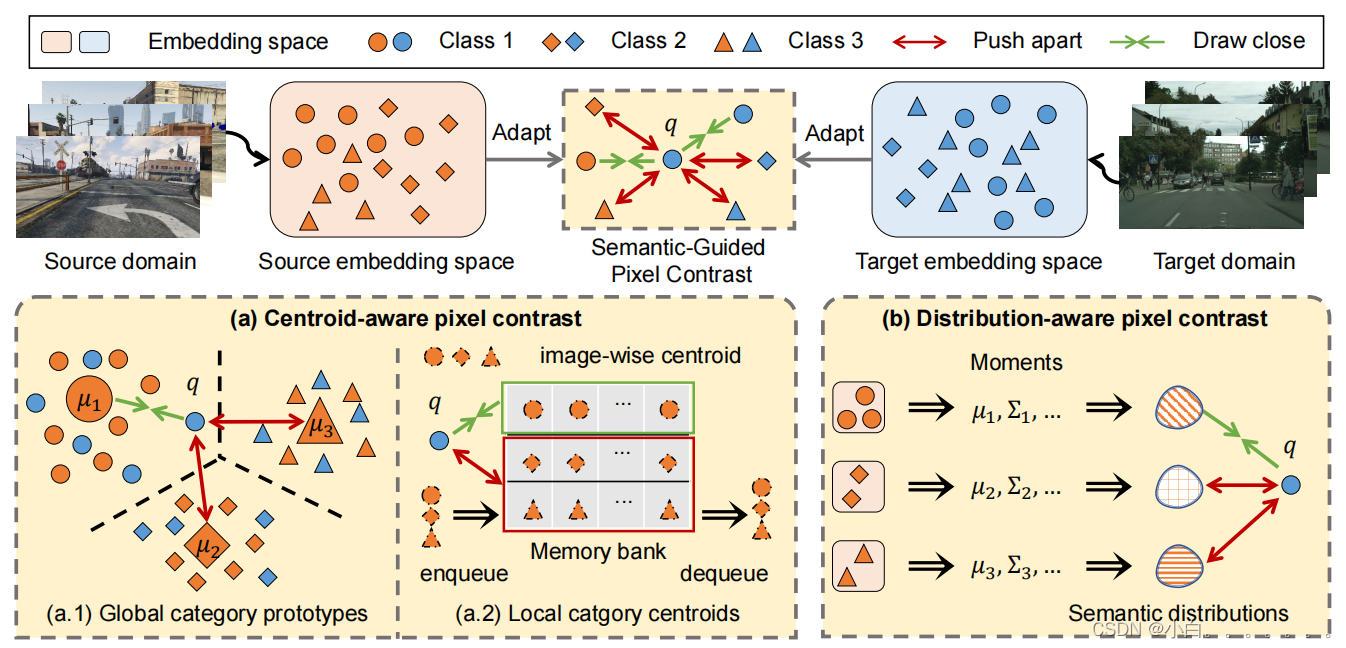
更精确的说,就是构建了一个自训练的方法,引入了几种密集的对比学习机制(centroid-aware pixel contrast,distribution-aware pixel contrast)。其核心是探索合适的语义概念,以指导跨领域的类区分和类平衡像素嵌入空间的学习。对于centroid-aware contrast,如果使用整个源域的全局类别原型,可能会忽视掉一些类别的差异,例如(颜色,形状,亮度等),这样就损害了可学习特征的可判别性。为了增加差异性,一个直接的方法就是增加对比对的数量,本文使用了一个memory bank的机制,将当前源域特征的类别质心放到字典里,将老的特征移除。这样做的缺陷就是会引起类别的偏差,由于一些稀有类(truck,bus,rider)更新的太慢了,而且这么做也是计算昂贵的。
作者假设,每个维度的嵌入空间都遵从一个分布,我们可以观察到,相似语义类别的像素表征都有一个相似的分布,因此,我们寻求源域上每个类别的分布作为一个丰富的,更加可理解的语义描述,根据源域上丰富的监督来估计真实的分布。我们可以从估计的分布中获得各种各样的样本,这是为语义分割等密集预测任务中的表示学习而定制的。
作者提出了PDD(Pixel-wise Discrimination Distance)来验证本文的方法在像素级类别对齐的有效性。
本文贡献:
(1) 在源域和目标域都提升了同个语义概念的像素特征的相似性,增加了不匹配对的区别度,而且对白天和夜晚的情况是鲁棒的。
(2) 通过每个类别的数据获得了期望对比损失的一个封闭的上界。
Method

对于这幅图片,其中CBC是指类平衡裁剪,就是频繁裁剪出一些比较稀有的类别以平衡不同类的表现。
L
c
l
L_{cl}
Lcl和
L
s
s
l
L_{ssl}
Lssl就是常规自训练方法使用的损失函数。使用
L
c
l
L_{cl}
Lcl和
L
r
e
g
L_{reg}
Lreg将
F
s
F_s
Fs和
F
t
F_t
Ft来进行像素表示的对比,通过质心感知或者分布感知的语义。
使用源域数据进行最小化CE损失来训练
θ
c
θ_c
θc和
θ
e
θ_e
θe:
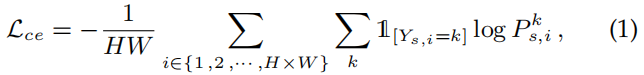
使用教师网络来为目标域图片生成值得信赖的伪标签:

由于这里的伪标签通常是有不少噪声的,这里采用了一个置信度估计:
先算了可靠像素预测的数目:

w=
N
U
M
c
o
n
f
NUM_{conf}
NUMconf/HW
根据目标域数据及其伪标签训练模型:
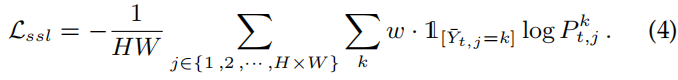
更新教师网络: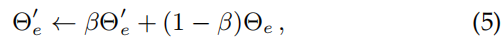
教师模型在弱增强目标域数据上生成伪标签,学生模型在强增强目标域数据上进行训练。
Overall motivation
之前的大部分自训练方法都忽视了明确的域对齐,这样就可能导致一种负迁移现象,即来自不同域的相同语义类别的特征被映射得很远。为了解决这个问题,本文提出了在一个嵌入空间中采用语义指导的表示学习。一种直接的方法就是根据在源域上计算的全局的类别原型来指导源域数据和目标域数据的对齐,但是全局的类别原型只能反映这个类别最普遍的特征,并没有揭开语义信息的潜在强度(每个像素的语义都有区别于原型的特征),导致了错误的表示学习。
本文的方法进行了进一步的优化,存储每张源域图片的局部图像质心到一个队列中,可利用的语义信息与队列的大小成正比。但是这种方法就可能会加重类别的偏差,因为稀有类在队列中出现的次数很少,而且这种方法会消耗很多的计算资源。
最后,为了提升语义类别的多样性,本文就新引入了一个分布感知像素常数来对比的加强每个像素的表征和估计分布的联系。此外,这个分布感知的机制可以看做是在无限的数据上训练,计算效率更高。
Centriod-aware and Distribution-aware Statistics Calcution
根据教师模型在源域数据上得到的F-s,首先通过一个掩码将这些特征分类到k个类别中去,掩膜是根据真语义标签下采样得到的。这样就可以计算出在一张图片上的每个类别的局部质心: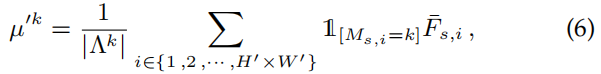
通过这些局部质心以一种在线更新的方式来获取全局的类别质心:


另一方面,用一个K个group的队列来保存最新的K张图片的局部质心:

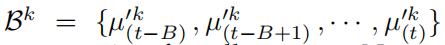
Discussion:
全局质心只能表示每个类别总体的表现,忽略了特征的多样性损害了学习到的表征的区别性。局部质心需要使用队列来存储,来拓展正负样本的集合,这样就需要足够大的队列B,这样既不优雅也没有效率。
作者发现每个类中单个像素的表示具有相似的分布。在这个思想下,作者提出了用丰富的有标签的源域样本来建立分布感知得到语义概念,这需要获得多维向量F-s,i的协方差,协方差计算公式如下:
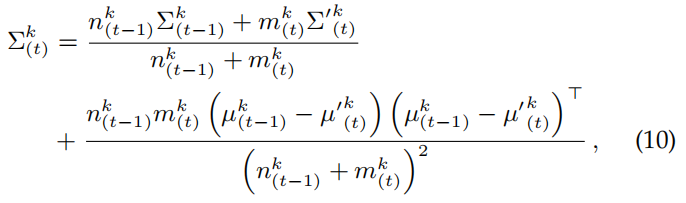
估计出的分布感知的语义统计数据更能提供信息的来指导跨域的像素表示学习。
Semantic-Guided Pixel Contrast
本文的方法设计了一个联合的框架,融合了三种不同的对比损失。旨在像素水平上学习相似/不相似的对,通过质心感知像素对比度或分布感知像素对比度来减轻域差异。
在源域数据和目标域数据上根据正对(q,q+m)和负对(q,qk-n)来是相同语义类别的像素特征更近,不同语义类别的像素特征更远。

M,N分别指正对和负对的数量,
K
−
K^-
K−表示负对的集合(就是指与q不同类别的样本)
下面分别介绍三种对比损失
l
q
p
r
o
t
o
c
l
l_q^{protocl}
lqprotocl,
l
q
b
a
n
k
c
l
l_q^{bankcl}
lqbankcl,
l
q
d
i
s
t
c
l
l_q^{distcl}
lqdistcl来推导出一个结构更好的嵌入空间。
总之,我们可以通过使用统一的对比损失来学习源域和目标域上的判别像素表示:
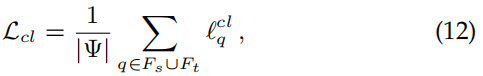
将这个对比损失应用到两个域上,运用到源域中,可以使学生模型学习到更多区别性的特征表示,提升了分割模型的鲁棒性。此外,目标域上像素感知的表示也被对比的适应了,有利于最小化类内距离,最大化类间距离。这里还引入了一个正则化方法,使输入图像的特征表示具有全局的多样化和平滑性,定义为:
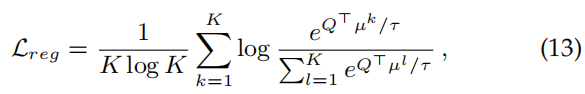
其中Q是指源域或者目标域图片的平均的特征表示:
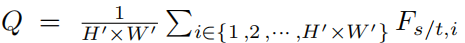
Centroid-aware Pixel Contrast
case 1:ProtoCL(M = N = 1):
这里就是通过全局的类别质心来建立一个正对和k-1个负对,本文考虑了以下公式作为原型像素对比损失函数:
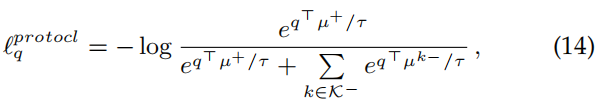
μ
+
μ^+
μ+表示积极的原型(与明确的q属于同一类别),
μ
k
−
μ^{k-}
μk−表示与q不属于同一类的第k类的原型。
case2:BankCL(M = N = B):
这里就是从memory bank获取更多的对比对,考虑了以下公式作为bank像素对比损失函数:

B
+
B^+
B+是指包含了正对的队列,相对应的,
B
−
B^-
B−表示包含负对的队列。
Discussion:
总的来说,总体的原型和局部的质心都可以被用来使具有相似表征的像素点距离更近,将那些表征不相似的像素点推得更远(在嵌入域上)。从式(14)和式(15)可以看出这两者的区别就是正对和负对的数量不一样。受此启发,作者猜测无限对的正对和负对可以建立一个更加鲁棒和具有判别性的嵌入空间。下面通过分布的视角来证实这个猜测。
Distribution-aware Pixel Contrast

p(
q
+
q^+
q+)指与q具有相同标签的正语义分布,p(
q
k
−
q^{k-}
qk−)指与q标签不同的第k类的语义分布。接下来推导出它的封闭式上界:
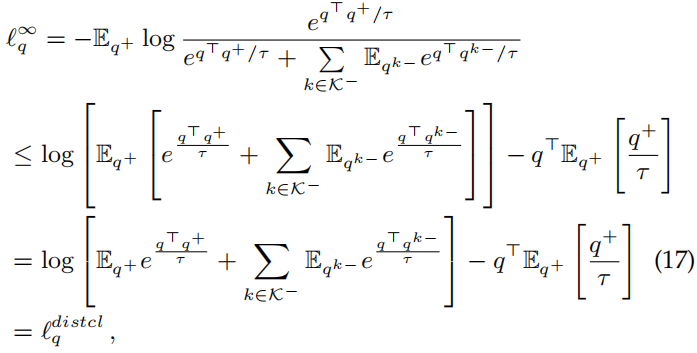

μ是指x的期望,∑是指x的协方差,猜测
q
+
q^+
q+ ~ N(
μ
+
μ^+
μ+,
∑
+
∑^+
∑+),
q
k
−
q^{k-}
qk− ~ N(
μ
k
−
μ^{k-}
μk−,
∑
k
−
∑^{k-}
∑k−),在这样的猜测下:
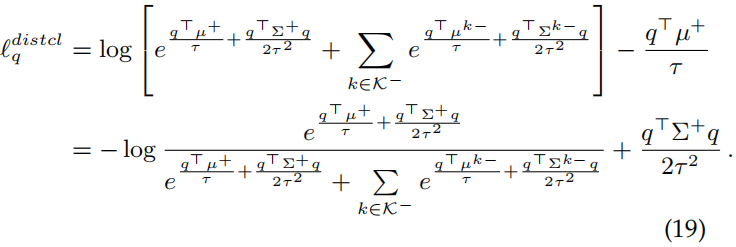
Training Procedure
Class-balanced Cropping(CBC)

Optimization Objective

总的损失函数:
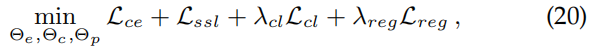
**总结:**我的理解就是用全局质心作为均值,根据bank中图片的局部质心算方差,根据这个均值和方差构建分布感知的像素指导语义分割,沿用了DAFormer里面的稀有类采样方法。















 3629
3629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









