







Using where:WHERE子句用于限制哪一个行匹配下一个表或发送到客户。除非你专门从表中索取或检查所有行,如果Extra值不为Using where并且表联接类型为ALL或index,查询可能会有一些错误。需要回表查询。
Using temporary:mysql常建一个临时表来容纳结果,典型情况如查询包含可以按不同情况列出列的GROUP BY和ORDER BY子句时;
索引原理及explain用法请参照前一篇:MySQL索引原理,explain详解
二、触发索引代码实例
1、建表语句 + 联合索引
CREATE TABLE `student` (
`id` int(10) NOT NULL,
`name` varchar(20) NOT NULL,
`age` int(10) NOT NULL,
`sex` int(11) DEFAULT NULL,
`address` varchar(100) DEFAULT NULL,
`phone` varchar(100) DEFAULT NULL,
`create_time` timestamp NULL DEFAULT NULL,
`update_time` timestamp NULL DEFAULT NULL,
`deleted` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `student_union_index` (`name`,`age`,`sex`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2、使用主键查询

3、使用联合索引查询

4、联合索引,但与索引顺序不一致

备注:因为mysql优化器的缘故,与索引顺序不一致,也会触发索引,但实际项目中尽量顺序一致。
5、联合索引,但其中一个条件是 >

6、联合索引,order by

where和order by一起使用时,不要跨索引列使用。
三、单表sql优化
1、删除student表中的联合索引。

2、添加索引
alter table student add index student_union_index(name,age,sex);

优化一点,但效果不是很好,因为type是index类型,extra中依然存在using where。
3、更改索引顺序
因为sql的编写过程
select distinct ... from ... join ... on ... where ... group by ... having ... order by ... limit ...
解析过程
from ... on ... join ... where ... group by ... having ... select distinct ... order by ... limit ...
因此我怀疑是联合索引建的顺序问题,导致触发索引的效果不好。are you sure?试一下就知道了。
alter table student add index student_union_index2(age,sex,name);
删除旧的不用的索引:
drop index student_union_index on student
索引改名
ALTER TABLE student RENAME INDEX student_union_index2 TO student_union_index
更改索引顺序之后,发现type级别发生了变化,由index变为了range。
range:只检索给定范围的行,使用一个索引来选择行。

备注:in会导致索引失效,所以触发using where,进而导致回表查询。
4、去掉in

ref:对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取;
index 提升为ref了,优化到此结束。
5、小结
-
保持索引的定义和使用顺序一致性;
-
索引需要逐步优化,不要总想着一口吃成胖子;
-
将含in的范围查询,放到where条件的最后,防止索引失效;
四、双表sql优化
1、建表语句
CREATE TABLE `student` (
`id` int(10) NOT NULL,
`name` varchar(20) NOT NULL,
`age` int(10) NOT NULL,
`sex` int(11) DEFAULT NULL,
`address` varchar(100) DEFAULT NULL,
`phone` varchar(100) DEFAULT NULL,
`create_time` timestamp NULL DEFAULT NULL,
`update_time` timestamp NULL DEFAULT NULL,
`deleted` int(11) DEFAULT NULL,
`teacher_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE teacher (
id int(11) DEFAULT NULL,
name varchar(100) DEFAULT NULL,
course varchar(100) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
### 2、左连接查询
explain select s.name,t.name from student s left join teacher t on s.teacher_id = t.id where t.course = ‘数学’

上一篇介绍过,联合查询时,小表驱动大表。小表也称为驱动表。其实就相当于双重for循环,小表就是外循环,第二张表(大表)就是内循环。
虽然最终的循环结果都是一样的,都是循环一样的次数,但是对于双重循环来说,一般建议将数据量小的循环放外层,数据量大的放内层,这是编程语言的优化原则。
再次代码测试:
student数据:四条
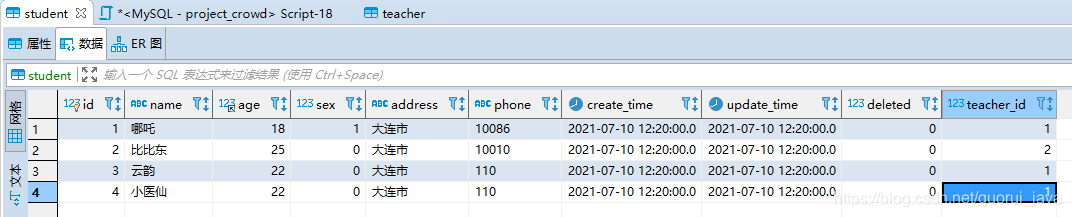
teacher数据:三条
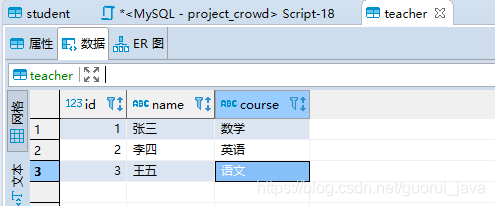
按照理论分析,teacher应该为驱动表。

sql语句应该改为:
explain select teacher.name,student.name from teacher left join student on teacher.id = student.id where teacher.course = ‘数学’
优化一般是需要索引的,那么此时,索引应该怎么加呢?往哪个表上加索引?
索引的基本理念是:索引要建在经常使用的字段上。
由on teacher.id = student.id可知,teacher表的id字段使用较为频繁。
left join on,一般给左表加索引;因为是驱动表嘛。

alter table teacher add index teacher_index(id);
alter table teacher add index teacher_course(course);

备注:如果extra中出现using join buffer,表明mysql底层觉得sql写的太差了,mysql加了个缓存,进行优化了。
### 3、小结
1. 小表驱动大表
2. 索引建立在经常查询的字段上
3. sql优化,是一种概率层面的优化,是否实际使用了我们的优化,需要通过explain推测。
五、避免索引失效的一些原则
-------------
1、复合索引,不要跨列或无序使用(最佳左前缀);
2、符合索引,尽量使用全索引匹配;
3、不要在索引上进行任何操作,例如对索引进行(计算、函数、类型转换),索引失效;
4、复合索引不能使用不等于(!=或<>)或 is null(is not null),否则索引失效;
5、尽量使用覆盖索引(using index);
6、like尽量以常量开头,不要以%开头,否则索引失效;如果必须使用%name%进行查询,可以使用覆盖索引挽救,不用回表查询时可以触发索引;
7、尽量不要使用类型转换,否则索引失效;
8、尽量不要使用or,否则索引失效;
六、一些其他的优化方法
-----------
### 1、exist和in
select name,age from student exist/in (子查询);
如果主查询的数据集大,则使用in;
如果子查询的数据集大,则使用exist;
### 2、order by 优化
using filesort有两种算法:双路排序、双路排序(根据IO的次数)
MySQL4.1之前,默认使用双路排序;双路:扫描两次磁盘(①从磁盘读取排序字段,对排序字段进行排序;②获取其它字段)。
MySQL4.1之后,默认使用单路排序;单路:只读取一次(全部字段),在buffer中进行排序。但单路排序会有一定的隐患(不一定真的是只有一次IO,有可能多次IO)。
注意:单路排序会比双路排序占用更多的buffer。
单路排序时,如果数据量较大,可以调大buffer的容量大小。
set max_length_for_sort_data = 1024;单位是字节byte。
如果max\_length\_for\_sort\_data值太低,MySQL底层会自动将单路切换到双路。
太低指的是列的总大小超过了max\_length\_for\_sort\_data定义的字节数。
提高order by查询的策略:
1. 选择使用单路或双路,调整buffer的容量大小;
2. 避免select \* from student;(① MySQL底层需要对\*进行翻译,消耗性能;② \*永远不会触发索引覆盖 using index);
3. 符合索引不要跨列使用,避免using filesort;
4. 保证全部的排序字段,排序的一致性(都是升序或降序);
七、sql顺序 -> 慢日志查询
----------------
慢查询日志就是MySQL提供的一种日志记录,用于记录MySQL响应时间超过阈值的SQL语句(long\_query\_time,默认10秒) ;
慢日志默认是关闭的,开发调优时打开,最终部署时关闭。
### 1、慢查询日志
(1)检查是否开启了慢查询日志:
show variables like ‘%slow_query_log%’
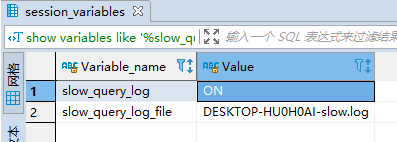
(2)临时开启:
set global slow_query_log = 1;
(3)重启MySQL:
service mysql restart;
(4)永久开启:
/etc/my.cnf中追加配置:
放到\[mysqld\]下:
slow_query_log=1
slow_query_log_file=/var/lib/mysql/localhost-slow.log
### 2、阈值
(1)查看默认阈值:
show variables like ‘%long_query_time%’
(2)临时修改默认阈值:
set global long_query_time = 5;
(3)永久修改默认阈值:
/etc/my.cnf中追加配置:
放到\[mysqld\]下:
long\_query\_time = 5;
(4)MySQL中的sleep:
select sleep(5);
(5)查看执行时间超过阈值的sql:
show global status like ‘%slow_queries%’;
八、慢查询日志 --> mysqldumpslow工具
---------------------------
### 1、mysqldumpslow工具
慢查询的sql被记录在日志中,可以通过日志查看具体的慢sql。
cat /var/lib/mysql/localhost-slow.log
通过mysqldumpslow工具查看慢sql,可以通过一些过滤条件,快速查出需要定位的慢sql。
mysqldumpslow --help
参数简要介绍:
s:排序方式
r:逆序
l:锁定时间
g:正则匹配模式
### 2、查询不同条件下的慢sql
(1)返回记录最多的3个SQL
mysqldumpslow -s r -t 3 /var/lib/mysql/localhost-slow.log
(2)获取访问次数最多的3个SQL
mysqldumpslow -s c -t 3 /var/lib/mysql/localhost-slow.log
(3)按时间排序,前10条包含left join查询语句的SQL
mysqldumpslow -s t -t 10 -g “left join” /var/lib/mysql/localhost-slow.log
九、分析海量数据
--------
### 1、show profiles
打开此功能:set profiling = on;
show profiles会记录所有profileing打来之后,全部SQL查询语句所花费的时间。
缺点是不够精确,确定不了是执行哪部分所消耗的时间,比如CPU、IO。
### 2、精确分析,sql诊断
show profile all for query 上一步查询到的query\_id。
### 3、全局查询日志
show variables like '%general\_log%'
开启全局日志:
set global general\_log = 1;
set global log\_output = table;
十、锁机制详解
-------
### 1、操作分类
# 总结
对于面试还是要好好准备的,尤其是有些问题还是很容易挖坑的,例如你为什么离开现在的公司(你当然不应该抱怨现在的公司有哪些不好的地方,更多的应该表明自己想要寻找更好的发展机会,自己的一些现实因素,比如对于我而言是现在应聘的公司离自己的家更近,又或者是自己工作到达了迷茫期,想跳出迷茫期等等)

**需要面试题以及项目大纲的朋友点赞+收藏后,[点击这里免费](https://gitee.com/vip204888/java-p7)获取!诚意满满!!**
**Java面试精选题、架构实战文档:[传送门](https://gitee.com/vip204888/java-p7)**
**整理不易,觉得有帮助的朋友可以帮忙点赞分享支持一下小编~**
九、分析海量数据
--------
### 1、show profiles
打开此功能:set profiling = on;
show profiles会记录所有profileing打来之后,全部SQL查询语句所花费的时间。
缺点是不够精确,确定不了是执行哪部分所消耗的时间,比如CPU、IO。
### 2、精确分析,sql诊断
show profile all for query 上一步查询到的query\_id。
### 3、全局查询日志
show variables like '%general\_log%'
开启全局日志:
set global general\_log = 1;
set global log\_output = table;
十、锁机制详解
-------
### 1、操作分类
# 总结
对于面试还是要好好准备的,尤其是有些问题还是很容易挖坑的,例如你为什么离开现在的公司(你当然不应该抱怨现在的公司有哪些不好的地方,更多的应该表明自己想要寻找更好的发展机会,自己的一些现实因素,比如对于我而言是现在应聘的公司离自己的家更近,又或者是自己工作到达了迷茫期,想跳出迷茫期等等)
[外链图片转存中...(img-gaHCKaka-1628084041647)]
**需要面试题以及项目大纲的朋友点赞+收藏后,[点击这里免费](https://gitee.com/vip204888/java-p7)获取!诚意满满!!**
**Java面试精选题、架构实战文档:[传送门](https://gitee.com/vip204888/java-p7)**
**整理不易,觉得有帮助的朋友可以帮忙点赞分享支持一下小编~**
**你的支持,我的动力;祝各位前程似锦,offer不断!**















 1025
1025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









