










参考链接: Netron Viewer for neural network, deep learning, and machine learning models
参考链接: GitHub lutzroeder / netron
运行代码,生成两个文件,分别保存整个模型和模型的参数:
import torch
import torchvision
from torchvision import datasets, transforms
from torch.autograd import Variable
import numpy as np
import matplotlib.pyplot as plt
import time
import os
model_path = 'model_name_Conv.pth'
model_params_path = 'params_name_Conv.pth'
Use_gpu = torch.cuda.is_available()
transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(
mean = [0.5],
std = [0.5]
)
]
)
dataset_train = datasets.MNIST(
root = "./data",
transform = transform,
train = True,
download = True
)
dataset_test = datasets.MNIST(
root = "./data",
transform = transform,
train = False #,
#download = True #
)
train_load = torch.utils.data.DataLoader(
dataset = dataset_train,
batch_size = 64,
shuffle = True
)
test_load = torch.utils.data.DataLoader(
dataset = dataset_test,
batch_size = 64,
shuffle = True
)
class AutoEncoder(torch.nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
self.encoder = torch.nn.Sequential(
torch.nn.Conv2d(1,64,kernel_size=3,stride=1,padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2,stride=2),
torch.nn.Conv2d(64,128,kernel_size=3,stride=1,padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2,stride=2)
)
self.decoder = torch.nn.Sequential(
# 上采样层,即torch.nn.Upsample类。这个类的作用就是对我们提取到的
# 核心特征进行解压,实现图片的重写构建,传递给它的参数一共有两个,
# 分别是scale_factor和mode:前者用于确定解压的倍数;后者用于定义图
# 片重构的模式,可选择的模式有nearest、linear、bilinear和trilinear,
# 其中nearest是最邻近法,linear是线性插值法,bilinear是双线性插值
# 法,trilinear是三线性插值法。
torch.nn.Upsample(scale_factor=2,mode="nearest"),
torch.nn.Conv2d(128,64,kernel_size=3,stride=1,padding=1),
torch.nn.ReLU(),
torch.nn.Upsample(scale_factor=2,mode="nearest"),
torch.nn.Conv2d(64,1,kernel_size=3,stride=1,padding=1)
)
def forward(self,input):
output = self.encoder(input)
output = self.decoder(output)
return output
model = AutoEncoder()
if Use_gpu:
model = model.cuda()
#print(model)
optimizer = torch.optim.Adam(model.parameters())
loss_f = torch.nn.MSELoss()
# has_been_trained = os.path.isfile(model_path)
has_been_trained = False
if has_been_trained:
epoch_n = 0
else:
epoch_n = 10
time_open = time.time()
for epoch in range(epoch_n):
running_loss = 0.0
print("Epoch {}/{}".format(epoch + 1,epoch_n))
print("-"*20)
# cxq=1
for data in train_load:
# print("$$$$$$$$$$$$",cxq)
# cxq+=1
X_train,_ = data
noisy_X_train = X_train + 0.5*torch.randn(X_train.shape)
noisy_X_train = torch.clamp(noisy_X_train,0.0,1.0)
if Use_gpu:
X_train, noisy_X_train = Variable(X_train.cuda()), Variable(noisy_X_train.cuda())
else:
X_train, noisy_X_train = Variable(X_train), Variable(noisy_X_train)
train_pre = model(noisy_X_train)
loss = loss_f(train_pre, X_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
print("Loss is:{:.4f}".format(running_loss/len(dataset_train)))
time_end = time.time() - time_open
print("程序运行时间:{}分钟{}秒...".format(int(time_end/60),int(time_end)%60))
###################################################################################
if has_been_trained:
model = torch.load(model_path)
else:
torch.save(model, model_path)
torch.save(model.state_dict(), model_params_path)
X_test,_ = next(iter(test_load))
# print(X_test.shape) #torch.Size([64, 1, 28, 28])
X_test = X_test[0:4,:,:,:]
img_original = torchvision.utils.make_grid(X_test)
img_original = img_original.numpy().transpose(1,2,0)
mean = [0.5]
std = [0.5]
img_original = img_original * std + mean
img_original = np.clip(img_original,0.0,1.0)
plt.figure("原始图像")
plt.imshow(img_original)
#plt.show()
mosaic = 0.5 * torch.randn(X_test.shape)
img_mosaic = torchvision.utils.make_grid(X_test + mosaic)
img_mosaic = img_mosaic.numpy().transpose(1,2,0)
mean = [0.5]
std = [0.5]
img_mosaic = img_mosaic * std + mean
img_mosaic = np.clip(img_mosaic,0.0,1.0)
plt.figure("马赛克图像")
plt.imshow(img_mosaic)
#plt.show()
img_demosaic = X_test + mosaic
img_demosaic = torch.clamp(img_demosaic,0.0,1.0).cuda()
img_demosaic = Variable(img_demosaic)
img_demosaic = model(img_demosaic)
img_demosaic = img_demosaic.cpu().data
img_demosaic = torchvision.utils.make_grid(img_demosaic)
img_demosaic = img_demosaic.numpy().transpose(1,2,0)
mean = [0.5]
std = [0.5]
img_demosaic = img_demosaic * std + mean
img_demosaic = np.clip(img_demosaic,0.0,1.0)
plt.figure("去除马赛克的图像")
plt.imshow(img_demosaic)
plt.show()
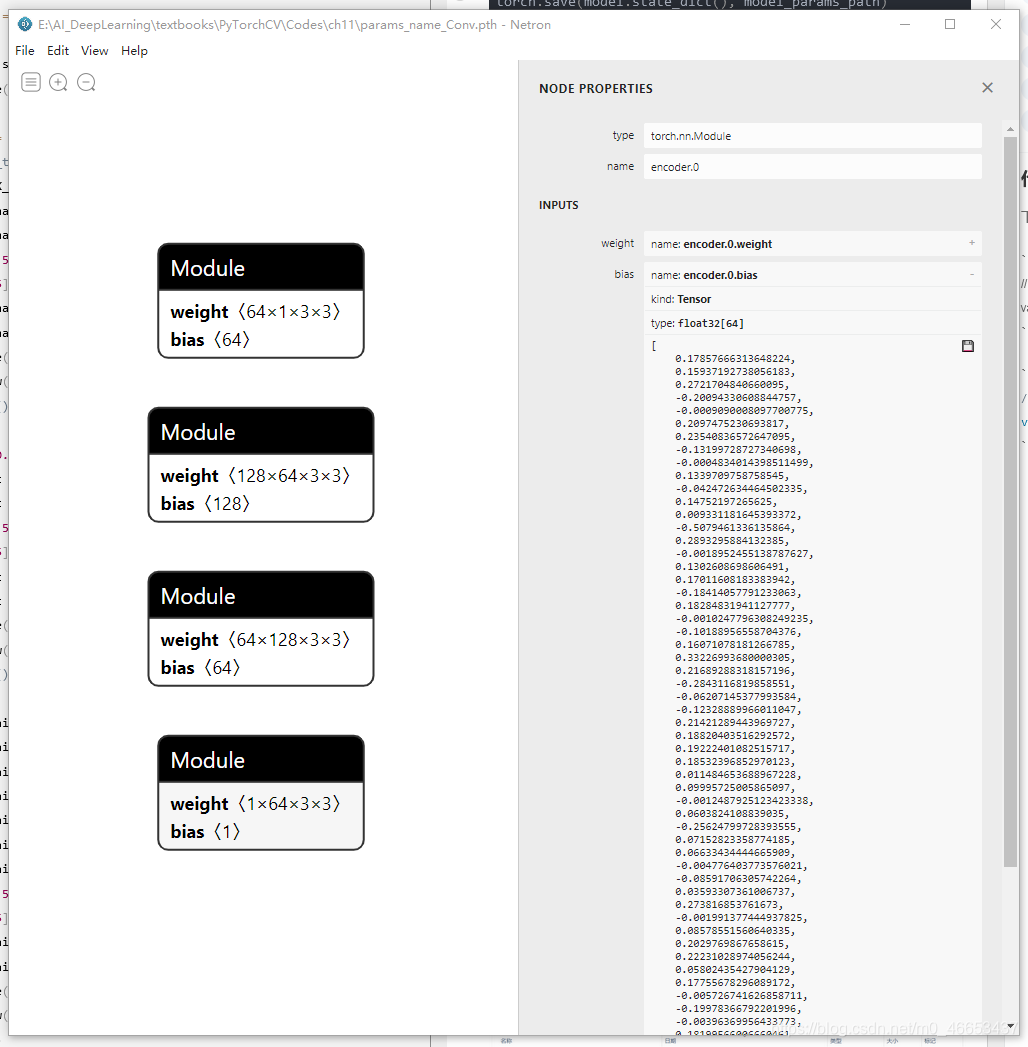
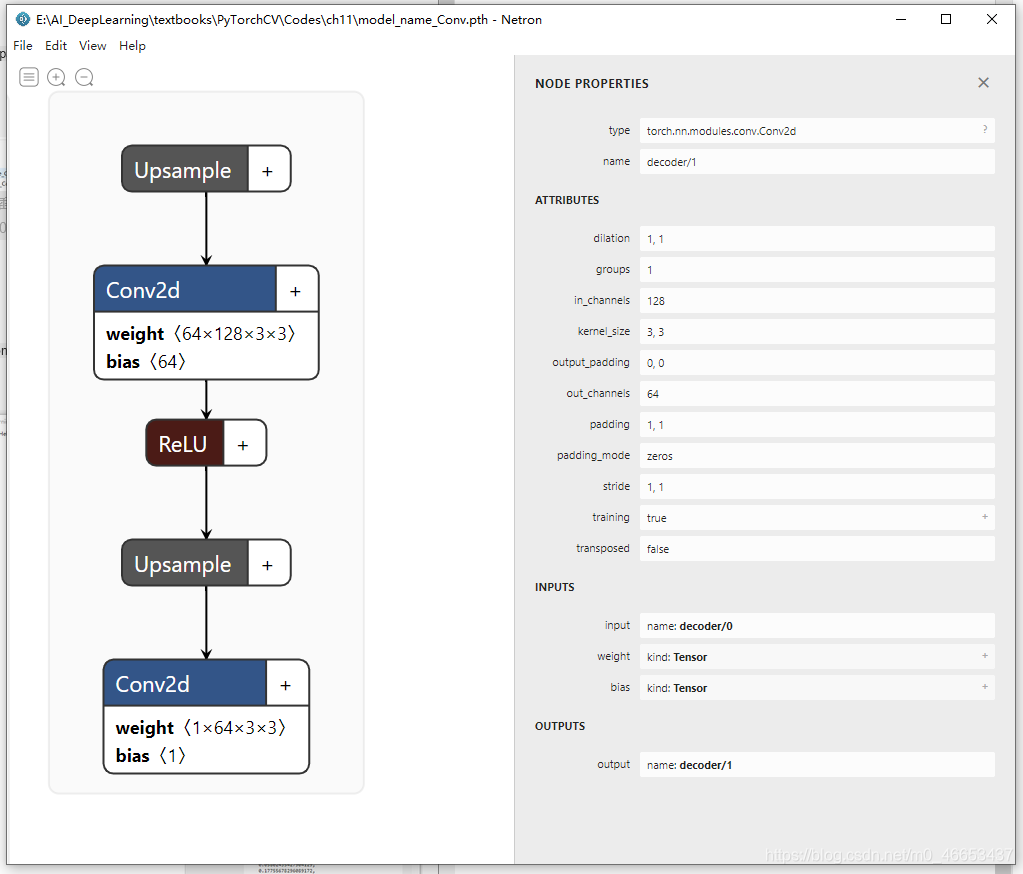
生成文件:params_name_Conv.pth和model_name_Conv.pth.

使用Netron打开这两个文件,查看其内容:















 816
816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









