







在保存元素不是固定范围时,哈希冲突有可能避免吗?
不能避免;因为存储的元素范围远远大于数组的长度
但可以尽可能的减少冲突,那么如何减少?
- 数组大小用素数(Java中不太用)
当 index = hashValue % arr.length 时
- hash函数(hashCode())要尽可能的均匀
- 每次插入元素时的冲突率与元素个数 / 数组长度成(负载因子)正比
(数组长度不变的情况下,元素个数越多越容易冲突;元素个数确定的情况下,数组长度越大越不容易冲突)
可以通过降低负载因子从而降低冲突率
- 我们对冲突率有个上线的阈值,所以我们对负载因子也有个上限阈值
- 要降低冲突率,需要降低负载因子中,负载因子中,元素个数不能动,所以只能增加数组的长度(扩容)
- 了解Java中一般负载因子是0.75

如何解决hash冲突?
- 线性探测
- 拉链法(Java的hashMap选用这种)
1. 线性探测法解决hash冲突
例:
int[] arr = new int[11]
存放元素:7,31,5,8,9,6,20,24
解:
hash函数: 元素 % 11;
7 % 11 = 7; --》1次
31 % 11 = 9; --》1次
5 % 11 = 5;--》1次
8 % 11 = 8; --》1次
9 % 11 = 9;(9 + 1)% 11 = 10; --》2次
6 % 11 = 6; --》1次
20 % 11 = 9; (20 + 1)% 11 = 10;(21 + 1) % 11 = 0; --》3次
24% 11 =2; --》1次
问题1:对所有在hash表中的元素做查找,其平均比较次数是多少?
答:(1+1+1+1+2+1+3+1)/ 8 = 11/8
问题2:对所有不在hash表中的元素做查找,其平均比较次数是多少?
答:(2+1+2+1+1+8+7+6+5+4+3)/ 11 = 40 / 11
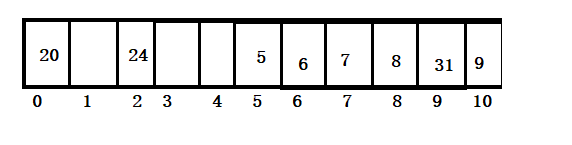

2. 拉链法: 使用另一种数据结构来解决冲突的元素

如果不是int类型怎么办? 例如定义一个Person类型的对象存放到hash表
所有的Object类下,都有一个int hashCode() 方法;把一个对象转变为int 对象(不一定是合法下标),所有还需要把int 类型转化为一个合法的下标,即需要模上数组长度--》int index = hashValue % array.length;
//把对象转化为int类型
int hashValue = key.hashCode();
//把hash值转为合法的下标
int index = hashValue % arr.length;
class Node {
Integer key;
Node next;
public Node(Integer key) {
this.key = key;
}
}
//元素类型:Integer
//使用拉链法解决冲突
public class MyHashTable {
//需要一个数组
private Node[] arr = new Node[11];
//记录hash表中有的元素个数
private int size;
//true:key之前不在hash表中
//false:key之前在hash表中
//插入的时间复杂度与链表的长度有关
public boolean insert(Integer key) {
//把对象转化为int类型
int hashValue = key.hashCode();
//把hash值转为合法的下标
int index = hashValue % arr.length;
//遍历index位置处的链表,确定key在不在链表中
Node cur = arr[index];
while (cur != null) {
if (key.equals(cur.key)) {
return false;
}
cur = cur.next;
}
//把key装入到节点中,并插入到对应的链表中
//头插尾插都可以
Node node = new Node(key);
node.next = arr[index];
arr[index] = node;
//维护元素个数
size++;
//通过维护负载因子,进而维护较低的冲突率
if (size / arr.length * 100 >= 75) { //size / arr.length >= 0.75两边同时×100
//扩容
expandTheCapacity();
}
return true;
}
//时间复杂度O(n)
private void expandTheCapacity() {
Node[] newArr = new Node[arr.length * 2]; //2倍
//复制原来的元素
//不能直接按链表的搬运,因为元素保存的下标的数组长度有关
// 数组长度变了,下标也会变,所以需要把每个元素重新计算一次
for (int i = 0; i < arr.length;i++) {
//遍历每条链表
Node cur = arr[i];
while (cur != null) {
//复制节点
Integer key = cur.key;
int hashValue = key.hashCode();
int index = hashValue % newArr.length;
//头插
Node node = new Node(key);
node.next = newArr[index];
newArr[index] = node;
cur = cur.next;
}
}
arr = newArr;
}
//值在并且删除成功返回true
//值不在返回false
public boolean remove(Integer key) {
int hashValue = key.hashCode();
int index = hashValue % arr.length;
Node cur = arr[index];
Node prv = null;
while (cur != null) {
if (key.equals(cur.key)) { //找到了该元素
//开始删除
if (prv != null) {
prv.next = cur.next;
} else {
//cur是链表的头结点
arr[index] = cur.next;
}
size--;
return true;
}
prv = cur;
cur = cur.next;
}
return false;
}
public boolean contains(Integer key){
int hashValue = key.hashCode();
int index = hashValue % arr.length;
Node cur = arr[index];
while (cur != null) {
if (key.equals(cur.key)) {
return true;
}
cur = cur.next;
}
return false;
}
}hash表的Java实现:
纯key模型:HashSet
public static void main(String[] args) {
Set<Integer> set = new HashSet<>();
set.add(1);
set.add(2);
set.add(3);
System.out.println(set);
System.out.println(set.add(1)); //false
System.out.println(set);
set.remove(3); //true
System.out.println(set);
System.out.println(set.contains(4)); //false
System.out.println(set.contains(2)); //true
}key-value模型:HashMap
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<>();
System.out.println(map.put("ta",1)); //null
System.out.println(map); //{ta=1}
System.out.println(map.put("ta",2)); //1
System.out.println(map.put("ya",22)); //null
map.put("aa",33);
System.out.println(map); //{aa=33, ya=22, ta=2}
for (String k : map.keySet()) {
System.out.print(k + " "); //aa ya ta
}
}自定义类使用HashSet 和HashMap 的key时,需要注意:
- 必须重写hashCode() 和 equals() 方法
- 如果你认为两个对象相等,则hashCode() 值相等,并且equals返回true
如果p1.equals(p2) 返回true,则最好是 p1.hashCode() == p2.hashCode()
- 如果 p1.hashCode() == p2.hashCode(),不需要保证p1.equals(p2)返回true,因为可能出现hash冲突
hash表的时间复杂度:插入、删除、查找的平均复杂度为O(1) 泊松分布
如果有意识的构造hash冲突。当链表长度超过8时,不能用链表存储冲突元素,而是用高效的搜索数据结构(Java中选用红黑树(搜索树)),大大减少了查找时间
自定义类使用HashSet和HashMap的注意点:需要重写hashCode() 和 equals()!!!
import java.util.Objects;
import java.util.HashMap;
import java.util.HashSet;
class Person {
String name;
Integer age;
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(name, person.name) &&
Objects.equals(age, person.age);
}
@Override
public int hashCode() {
// 复写为0不影响查找,但是是错误的,所有元素都hash冲突了
//return 0;
return Objects.hash(name, age);
}
}
public class Main {
public static void main(String[] args) {
Person p1 = new Person("ya",18);
Person p2 = new Person("ya",18);
HashSet<Person> hashSet = new HashSet<>();
hashSet.add(p1);
System.out.println(hashSet.contains(p2)); //目前返回false
//要想返回true,应该如何做?
//重写hashCode() 和 equals() 方法
}
public static void main1(String[] args) {
Person p1 = new Person("ya",18);
Person p2 = new Person("ya",18);
HashMap<Person,String> hashMap = new HashMap<>();
hashMap.put(p1,"ya");
System.out.println(hashMap.get(p2)); //ya
HashMap<String,Person> hashMap1 = new HashMap<>();
hashMap1.put("ya",p1);
System.out.println(hashMap1.get("ya"));
}
}















 1996
1996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









