






 本文介绍了XML中特殊字符的处理方法,如使用实体引用避免解析错误,并提供Python脚本示例,用于校验XML文件是否存在非法字符,包括单个文件和多个文件的批量检测。
本文介绍了XML中特殊字符的处理方法,如使用实体引用避免解析错误,并提供Python脚本示例,用于校验XML文件是否存在非法字符,包括单个文件和多个文件的批量检测。
在XML中,有一些特定的字符被视为非法或需要特别处理,因为它们在XML的语法中具有特殊意义。要在XML元素中使用这些特殊字符,需要使用实体引用(Entity Reference)来替换它们。以下是一些常见的XML特殊字符及其对应的实体引用:
-
小于号(
<):在XML中,小于号用来开始标签,因此无法直接用在元素内容中。应该使用实体引用<来代替。 -
大于号(
>):虽然大于号在大多数情况下可以直接使用,但为了避免潜在的错误(如当它紧跟在]]之后时),建议使用实体引用>。 -
和号(
&):和号用于引导实体引用,因此不能直接用在元素内容中。应该使用实体引用&来代替。 -
引号(
"):当引号用于属性值时,如果属性值由双引号括起,则在属性值中的双引号应替换为实体引用"。 -
单引号(
'):与双引号类似,如果属性值由单引号括起,则在属性值中的单引号应替换为实体引用'。
除了这些特殊字符之外,还有一些字符范围是在XML文档中不允许使用的,因为它们是在Unicode中未定义的或者是控制字符。例如,大多数ASCII控制字符(范围从U+0000到U+001F,除了空白符U+0009(TAB)、U+000A(LF)、U+000D(CR)之外)在XML 1.0中是不允许的。如果需要包含这些字符,通常需要通过某种编码或转义机制来处理。
记住,使用实体引用是确保XML文档格式正确的好方法,可以避免因为这些特殊字符而导致的解析错误。
如果要校验文件是否存在非法字符,提前判断文件是否可以被使用,就可以利用Python脚本进行一个校验判断
第一、校验单个的XML格式文件脚本是否存在非法字符
首先创建一个py结尾的文件,将下列脚本放进去,然后用Python3进行执行(注:文件的file_path的值需要进行实际的修改,最好写成绝对路径)
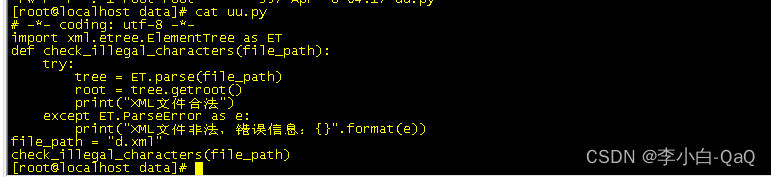
如果出现下面结果,则表示XML文件是正确的。反之,则报错,并且输出非法字符所在位置的行列号
![]()
.第二、校验多个的XML格式文件脚本是否存在非法字符
首先创建一个py结尾的文件,将下列脚本放进去,然后用Python3进行执行(注:脚本的folder_path的值需要进行实际的修改,最好写成绝对路径)
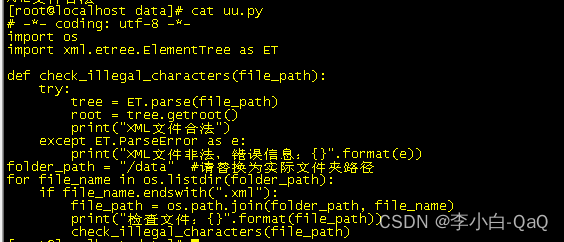
如果出现下面结果,则表示XML文件是正确的。反之,则报错,并且输出检查的文件和非法字符所在位置的行列号


















 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









