






我最近由于学校任务需要学习爬虫,就查阅了各大佬Python爬取疫情网站的疫情数据的方法,浅浅的学习了一下,简单的爬取了丁香医生网站的疫情数据并保存在本地当中。
准备爬取数据 首先要导入爬取数据所需要的工具包
我使用的是requests+BeautifulSoup来爬取数据。
#使用requests+BeautifulSoup爬取数据,丁香是静态数据 腾讯和网易爬取则需要使用selenium库的一些功能进行爬取
from bs4 import BeautifulSoup
import csv
import requests,re
import json
from urllib.request import urlopen, quote接下来就是使用requests获取网页内容。
网址就是在百度上搜丁香医生就可以搜到。
#目标网页(丁香医生)
url = 'https://ncov.dxy.cn/ncovh5/view/pneumonia'
#抓取网页信息
#request.get()方法抓取主页信息
r = requests.get(url)
#改变编码格式,以防乱码
r.encoding = r.apparent_encoding
#输出主页信息
html = r.text
h = BeautifulSoup(html,'lxml')
#lxml为解析器获取的网页信息大概如下图所示,可以在网页信息中找到所需要的数据是在
id = getAreaStat 中的。

接下来就是对爬取到内容进行提取整理,获取真正所需要的数据。
# 从HTML中提取全国各地数据
temp = h.find(id="getAreaStat")
# 从json中使用正则表达式提取世界各国的疫情信息(从[作为开始,]作为结束)
#temp不是string类型,将scrip强制转换成string类型
dat = re.findall(r'\[.+\]',str(temp))[0]
#将string转化为dict
date = json.loads(dat)#获取疫情数据这里一定要将temp进行处理,在进行json.loads()操作时会出现错误,原因就是temp不是String类型。
然后将数据保存到本地。
header = ['城市', '现存确诊', '确诊人数', '疑似病例', '治愈人数', '死亡人数','备注' ]
with open('E:\Python\疫情数据.csv', encoding='utf-8', mode='w',newline='') as f:
f_csv = csv.writer(f)
f_csv.writerow(header)
f.close()
j = 0
while j < len(date):
provinceName = date[j]["provinceName"]
currentConfirmedCount = date[j]["currentConfirmedCount"]
confirmedCount = date[j]["confirmedCount"]
suspectedCount = date[j]["suspectedCount"]
curedCount = date[j]["curedCount"]
deadCount = date[j]["deadCount"]
comment = date[j]["comment"]
f_date=[provinceName,currentConfirmedCount,confirmedCount,suspectedCount,curedCount,deadCount,comment]
with open('E:\Python\疫情数据.csv', encoding='UTF-8', mode='a+',newline='') as f:
f_csv = csv.writer(f)
f_csv.writerow(f_date)
f.close()
j = j + 1csv中的数据大概就是下图这样
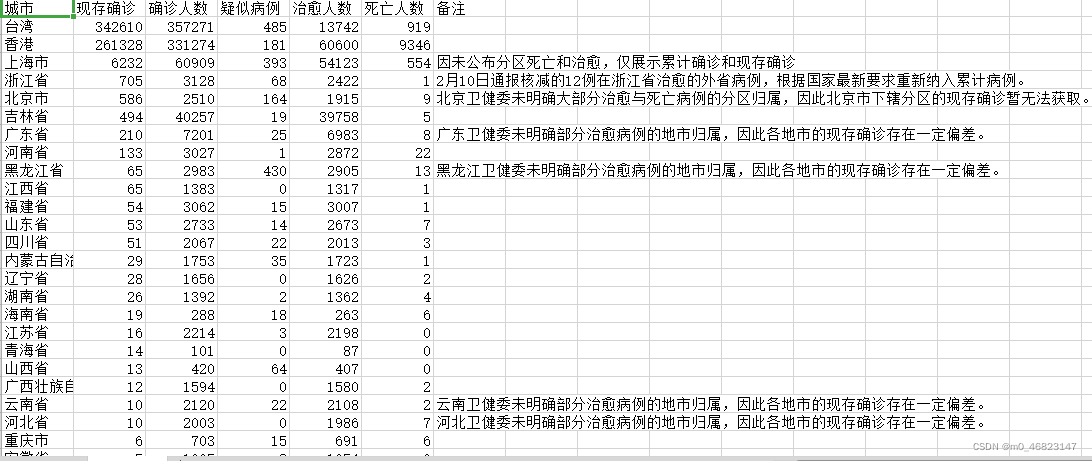
一个简单的全国各省份的疫情数据就爬取完成啦
第一次写多多担待,欢迎来探讨,指出错误~~~















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









