







项目简介
本次讲解Python爬虫,由于不易理解,因此将不断进行更新,分章节进行讲解。
为了大家可以快速的接触爬虫,方便学习和实战,因此围绕实例进行讲解,该代码是本人去年获取官方医院信息来写的代码,近期想整理下来,为更多的小伙伴进行一个分享!
本章节的主题是:什么是爬虫(爬虫用途)>>> 爬虫使用的编程语言 >>> 爬取医院信息实战展示 >>> Pycharm环境配置
记住!记住!记住!一定要在合法的情况下,进行爬取数据!
什么叫爬虫?
爬虫英文名字是spider,spider又可以翻译成蜘蛛,直白的理解,爬虫就像蜘蛛一样在攀爬。
蜘蛛呢是在墙壁上进行爬行,而咱们爬虫是在浏览器上进行爬行。

爬虫的用途
简单介绍完爬虫,那么爬虫有什么用途呢?我相信这是大家比较好奇的一件事
学会爬虫,不仅仅在就业工作方面提供帮助,还会在学科竞赛中极大的提高效率
举例来说:在参加计算机专业相关的学科竞赛中,人工智能的机器学习、深度学习算法,需要大量的训练集进行训练,那么也就意味着需要大量的数据进行获取;数学建模竞赛,部分比赛题目,不提供数据,就需要大家去相关网站上去查阅寻找数据,也用到了爬虫;计算机设计大赛中的数据可视化赛道,这也需要大量的数据等等,需要用到爬虫的还有很多方面,我只是举了片面的例子,当然还是那句话,小伙伴一定要注意了,爬虫一定要合法的使用。
当然啦,小伙伴们也不要太害怕。大家注意一下以下几点就可以啦!
一是只能爬取公开数据,二是不能对目标业务和网站造成影响,三是目标网站的全部或部分内容没有使用反爬措施。
所以说大家不用担心,正常的使用就可以。
爬虫使用的编程语言
目前使用较多的编程语言就是Python语言,是因为Python中的库还有内置函数比较全面,方便了代码的编写。
那么这个爬虫是使用什么编译软件进行爬取的呢?
运行Python的编译软件有:官方自带的IDLE、Pycharm、VScode还有Anaconda。后期更新博客的时候讲会详细讲解这几个编译软件的特点和关系。
当然在本篇文章使用的是pycharm这个编译软件,大家要注意一下,在下载的时候,一定是官网上去寻找安装包,不要点击带有广告标识的pycharm(有可能电脑会瞬间死机)
在安装的时候呢,小伙伴们要注意了,如果安装专业版的话,只会有30天的试用期。(大家可以去网上搜索一下破解版,但是我不推荐,因为安装社区版就足够用了,我一直都是用的社区版,爬虫啥的足够用,根本没有问题)。
小伙伴们在安装社区版pycharm的时候可以去B站上去搜索相关的安装教程,跟着一步步的下载,一定要注意, 因为在配置pycharm环境的时候很关键,如果环境配置不好的话,无论怎样运行代码都是错误的,痛苦的时间,不仅仅是一天、两天,甚至可能长达一个月之久。所以在配置pycharm环境的时候 一定要注意细节。
爬取医院信息成果展示
现在开始正式的介绍一下这个项目
下边这个链接就是咱们这个项目需要爬取的网址(URL)网址也叫URL
https://www.yixue.com/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%8C%BB%E9%99%A2%E5%88%97%E8%A1%A8
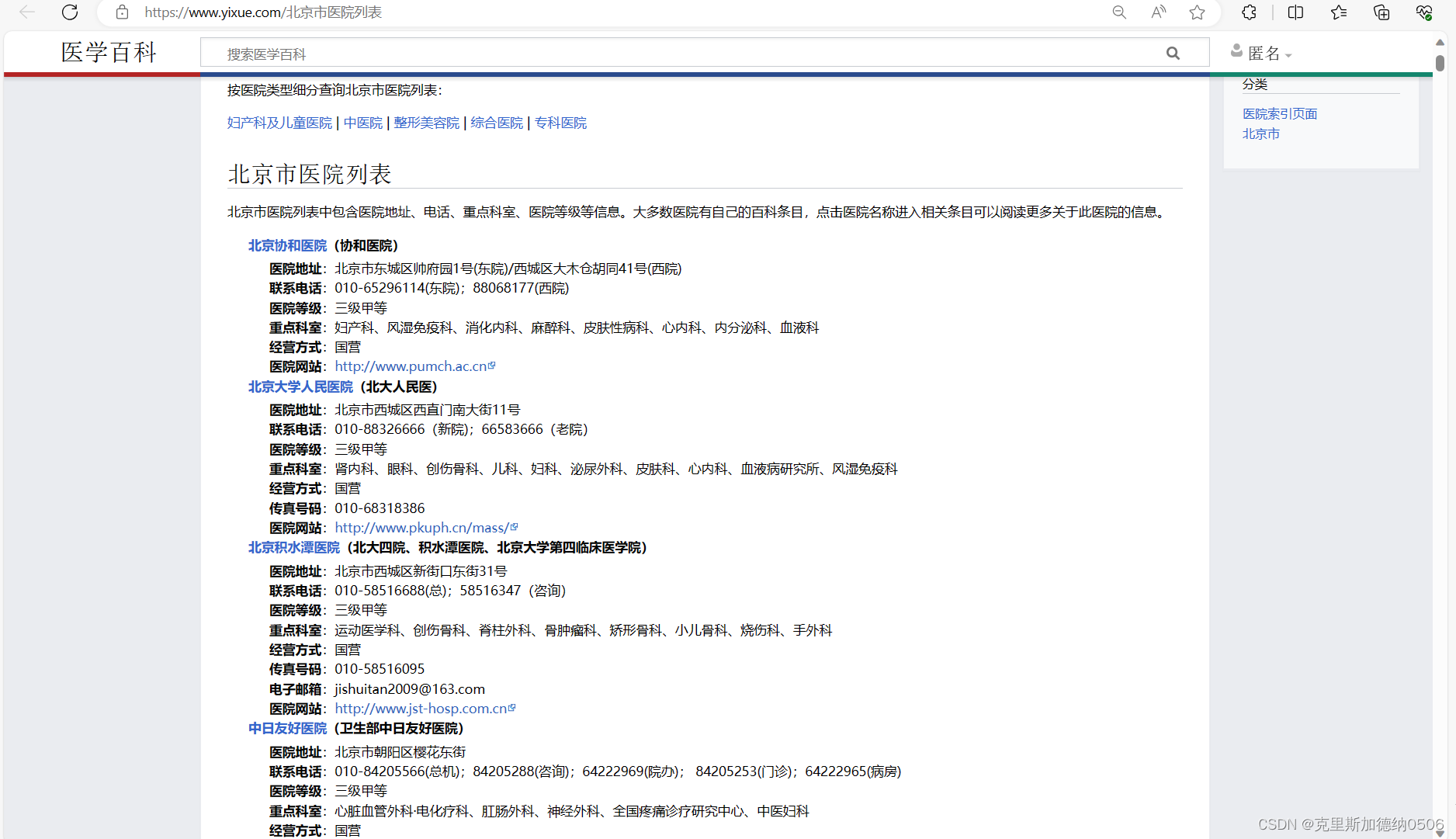
该项目的任务是需要将北京市所有医院的信息,全部爬取出来并且生成EXCEL表格的形式。
下面这张就是爬取结束后的EXCEl表格信息,包含了500多家的医院信息。
这时候有的小伙伴有可能来的兴趣,可不可以爬取全国的医院信息?答案是:当然可以啦,只需要在代码中修改医院的URL的参数就可以爬取。

到这里了,小伙伴们是不是突然对爬虫感兴趣了呀? 在代码运行的短短2秒的时候就可以获取成千上万的数据,是不是很方便。
那废话不多说,直接开始步入正题!
Pycharm环境配置
在这一步小白请留步,大佬就跳过这一章节
双击桌面上的pycharm,进入一个新的页面,进行一下操作,在导入本地文件夹的时候,需要提前在电脑上创建一个文件夹,命名可以任意命名,尽量使用英文命名。

下一步是在当前文件夹下创建新的Python文件,还是一样在命名的时候尽量使用英文名字进行命名,文件名后缀是.py
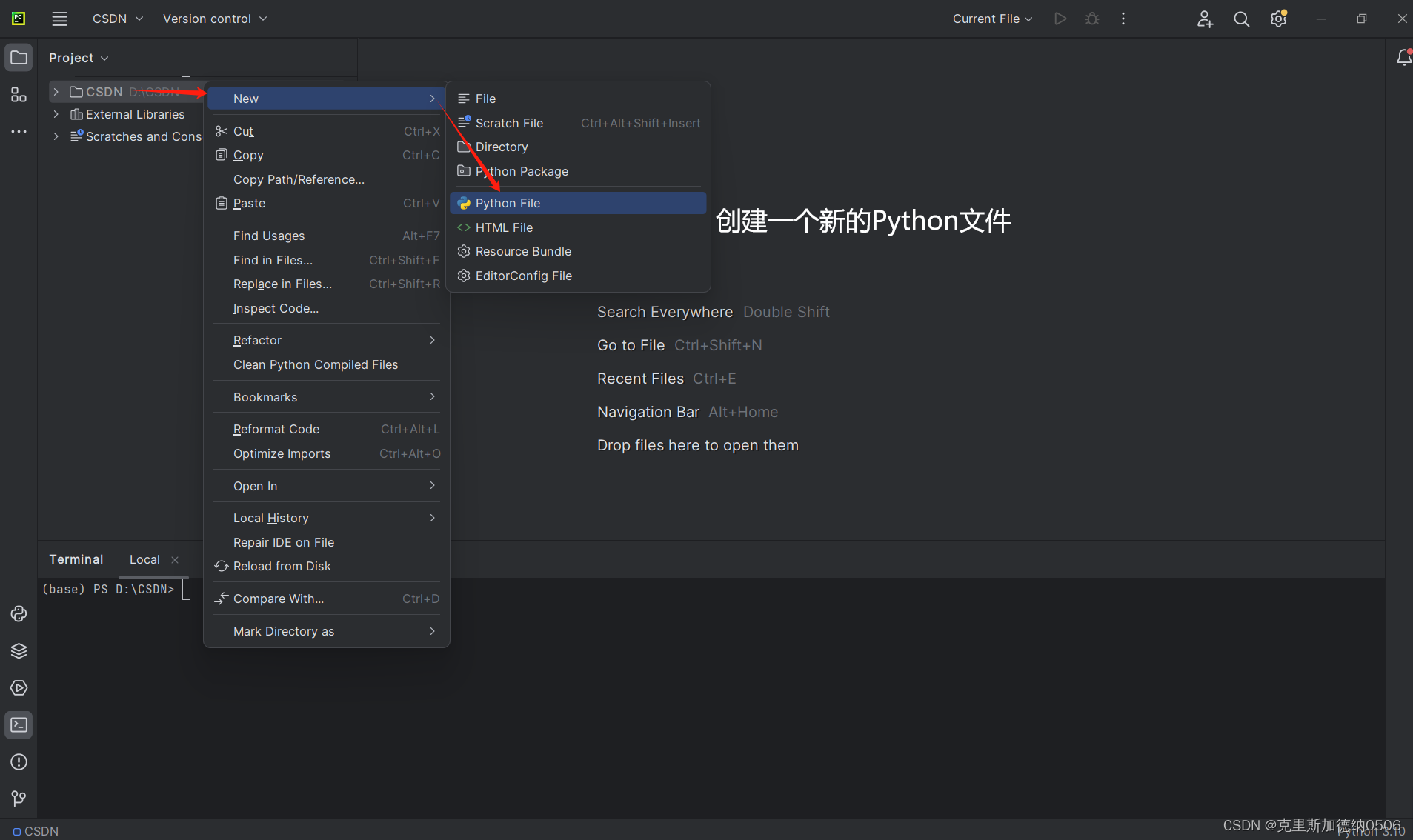
目前,Python文件创建好以后,小伙伴们就需要开始配置环境,安装库啦!
爬虫常用的库
大家注意哈!这里是比较常用的,我给大家列举几个,并不是代表全部:
请求库:实现HTTP请求操作 requests库 向HTTP发出一个请求,等待服务器响应后,程序进行下一步处理。
解析库:从网页中提取信息 beautifulsoup:html 和 XML 的解析,从网页中提取信息,同时拥有强大的API和多样解析方式。
爬虫框架 Scrapy:很强大的爬虫框架,可以满足简单的页面爬取。用这个框架可以轻松爬下来如亚马逊商品信息之类的数据。
在获取医院信息的实战中,用到了以下几个库:
import re
import requests
import pandas as pd小伙伴们可以发现在该实战项目中,用到了上述中的requests库,而剩余的库,没有涉及到。
聪明的小伙伴可能会猜到,上述的请求库、解析库还有爬虫框架,不是用时进行使用的。简单的理解为,使用requests库时,就不会使用beautifulsoup还有Scrapy框架。
在本次讲解中会围绕requests库进行讲解,后期将会依次对beautifulsoup还有Scrapy框架进行实战讲解。
好啦 既然只有该项目使用 re requests 还有pandas这三个库,那么应该如何安装呢?
一共有两种方法,一种是在终端控制台进行安装所需的库,另一种是在设置中进行安装所需要的库
第一种方法:
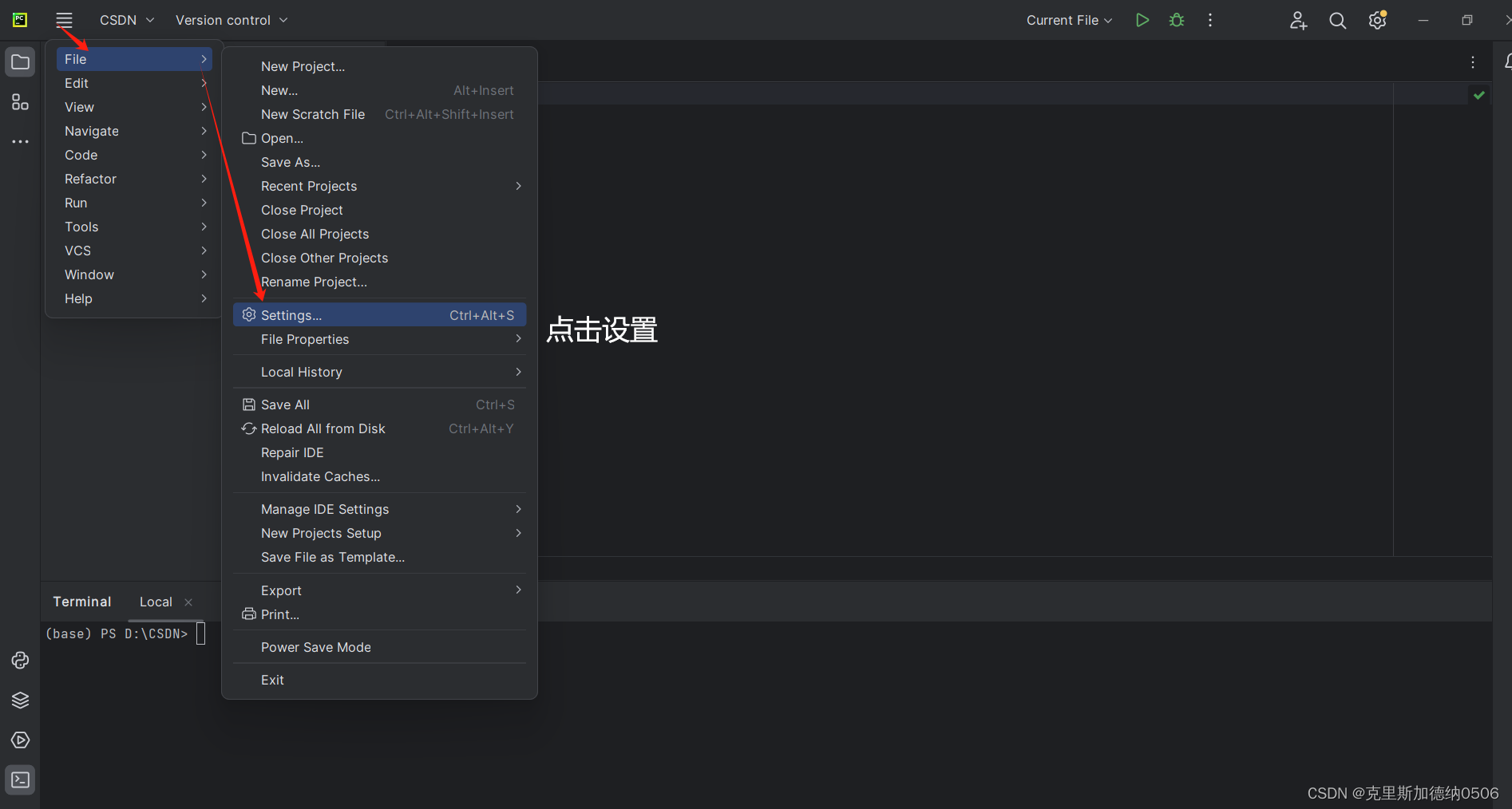
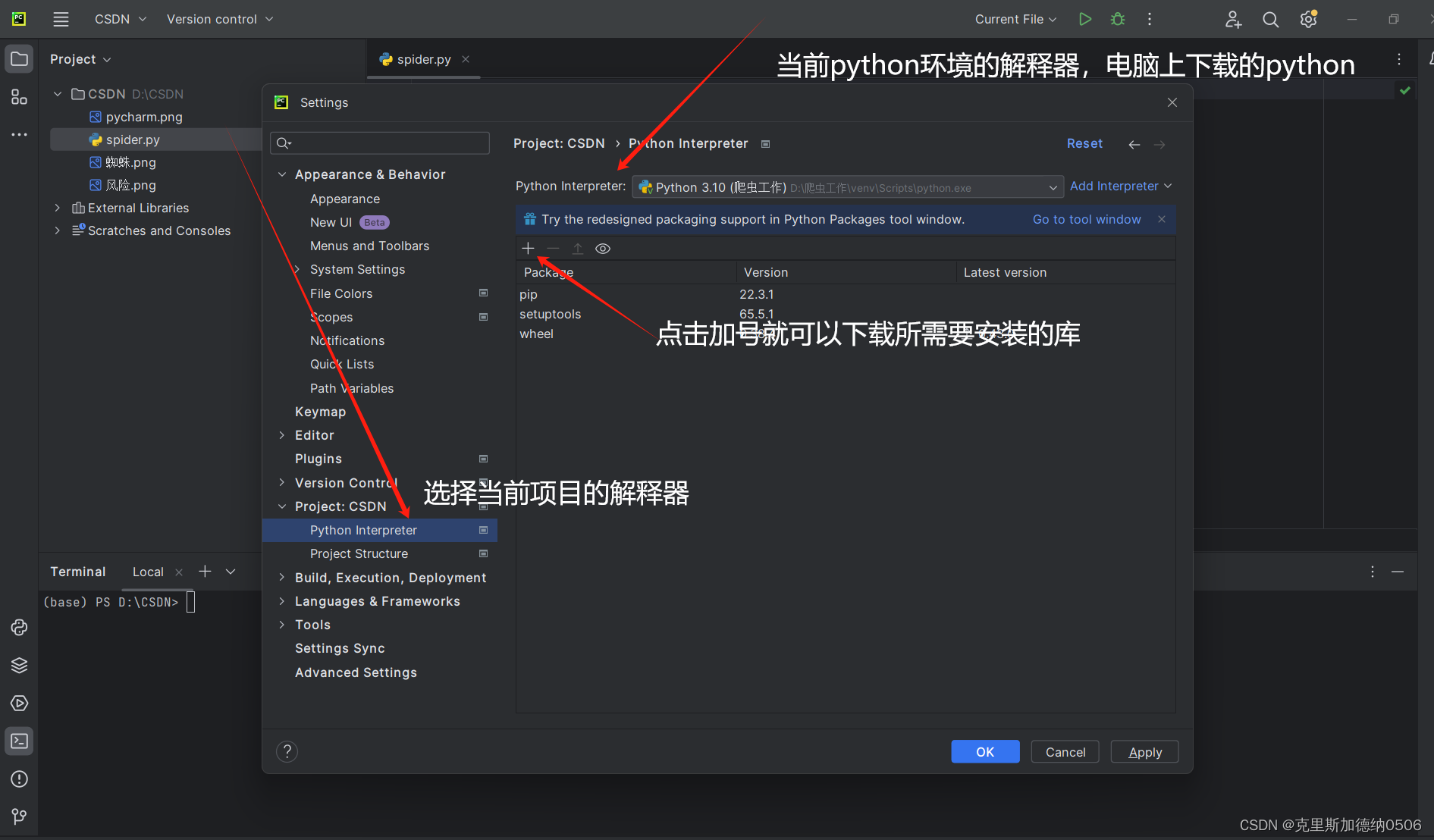
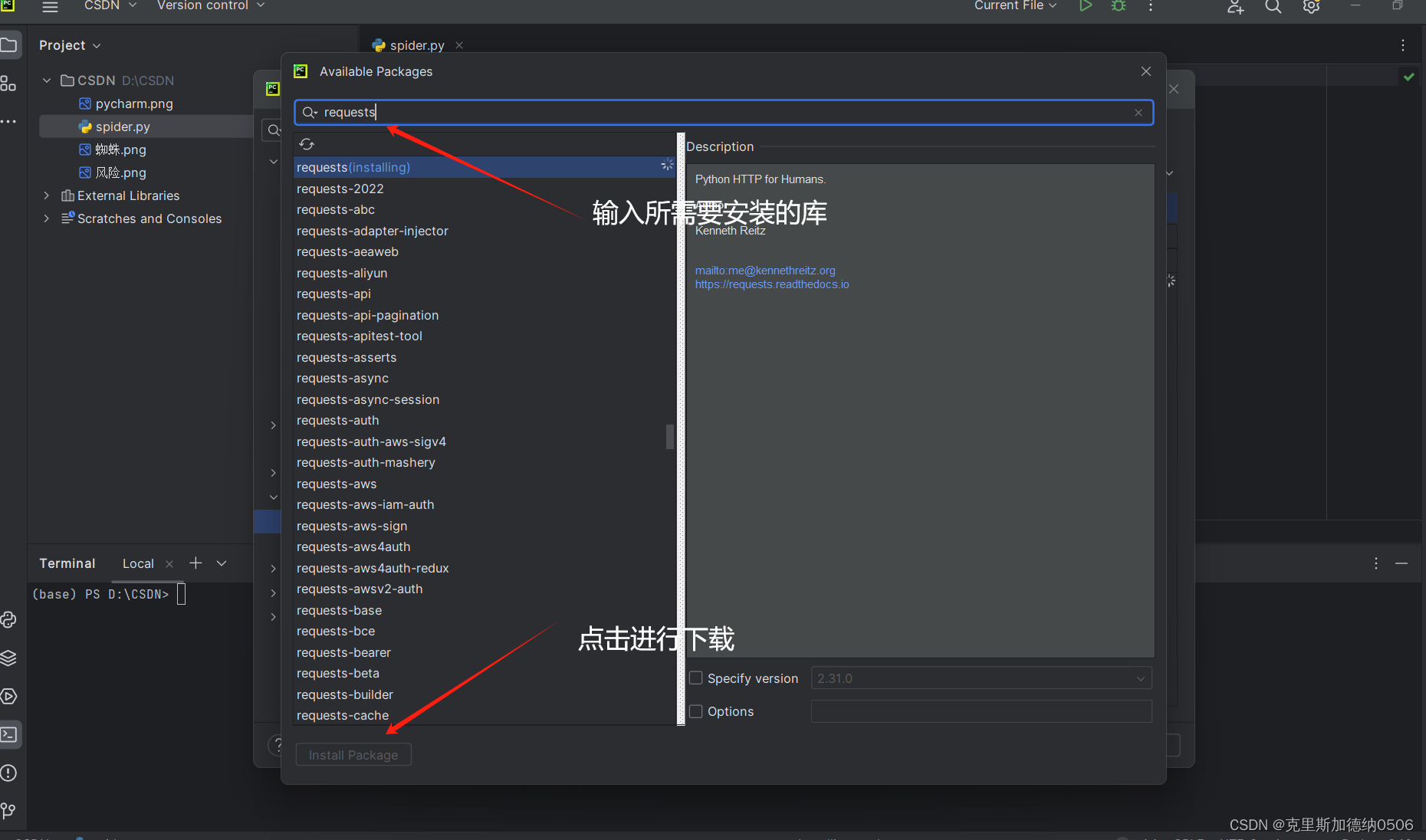
上述流程就是第一种安装库的方式,三个库,小伙伴依次进行安装就可以啦!
第二种安装方式就是从终端控制台上进行安装所需要的库:
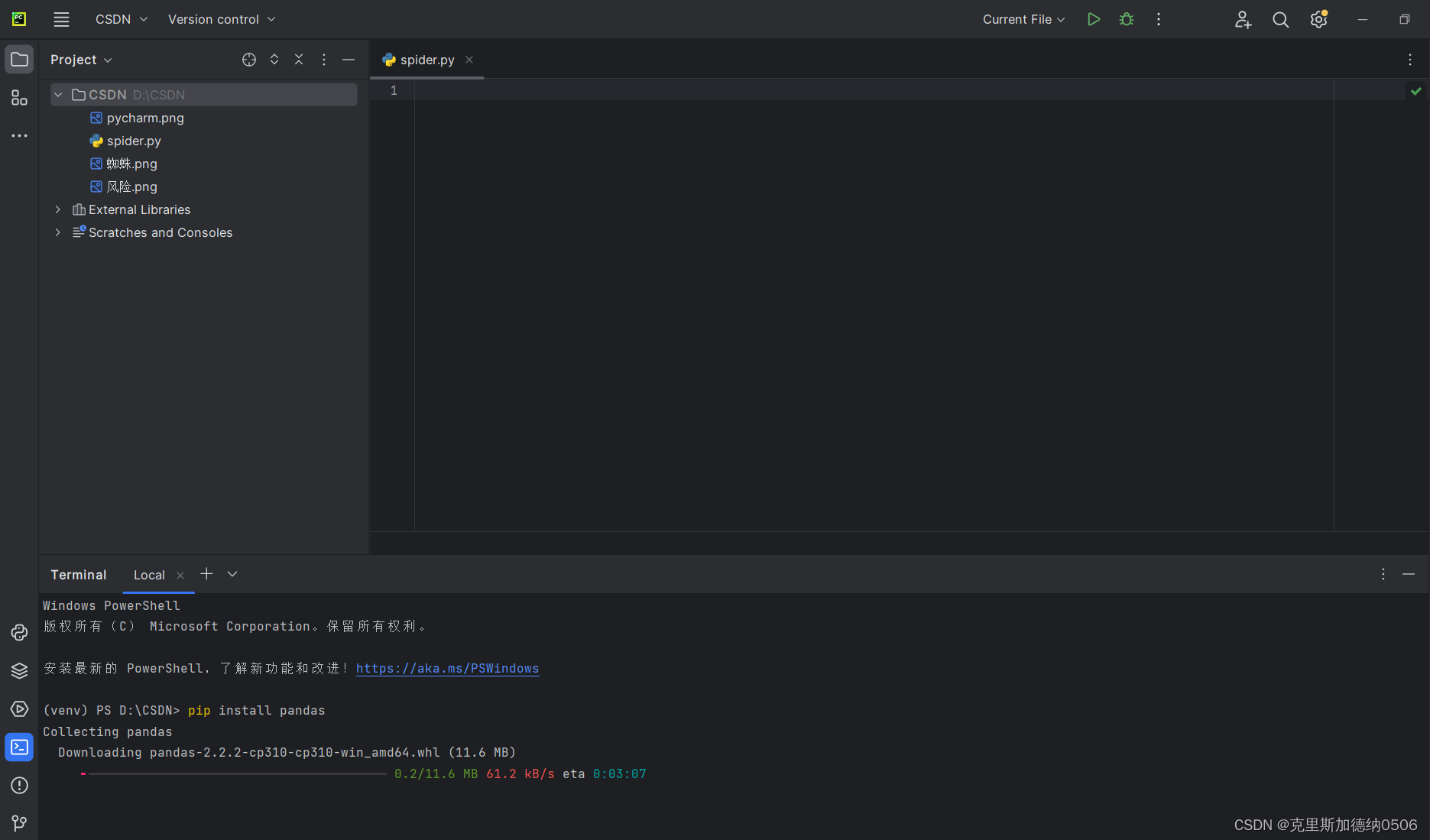
小伙伴们可以看到页面下方,在终端输入pip install pandas
就可以正确的安装库啦,在安装别的库的时候 分别是 pip install re 还有 pip install requests
这两种方法无论哪一种都可以正确的安装配置库
在环境配置完成后,咱们就可以开始写代码啦!
小伙伴们! 咱们下期见!!! 下期为大家详细的讲解爬虫代码!















 2408
2408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









