







前言:
Python可用于许多领域。Web应用程序开发,自动化、数学建模、爬虫、大数据等
我们在掌握一门编程语言以后,就可以很容易将这门编程语言的知识应用到其它编程语言,诸多编程语言不同之处在于语法格式,而Python则是以语法简洁入门简单且作用域广而著名,学习Python这门编程语言不会有那么吃力的感觉。
Python在长期使用方面在使用方面逐渐增长(12个月内的平均岗位)
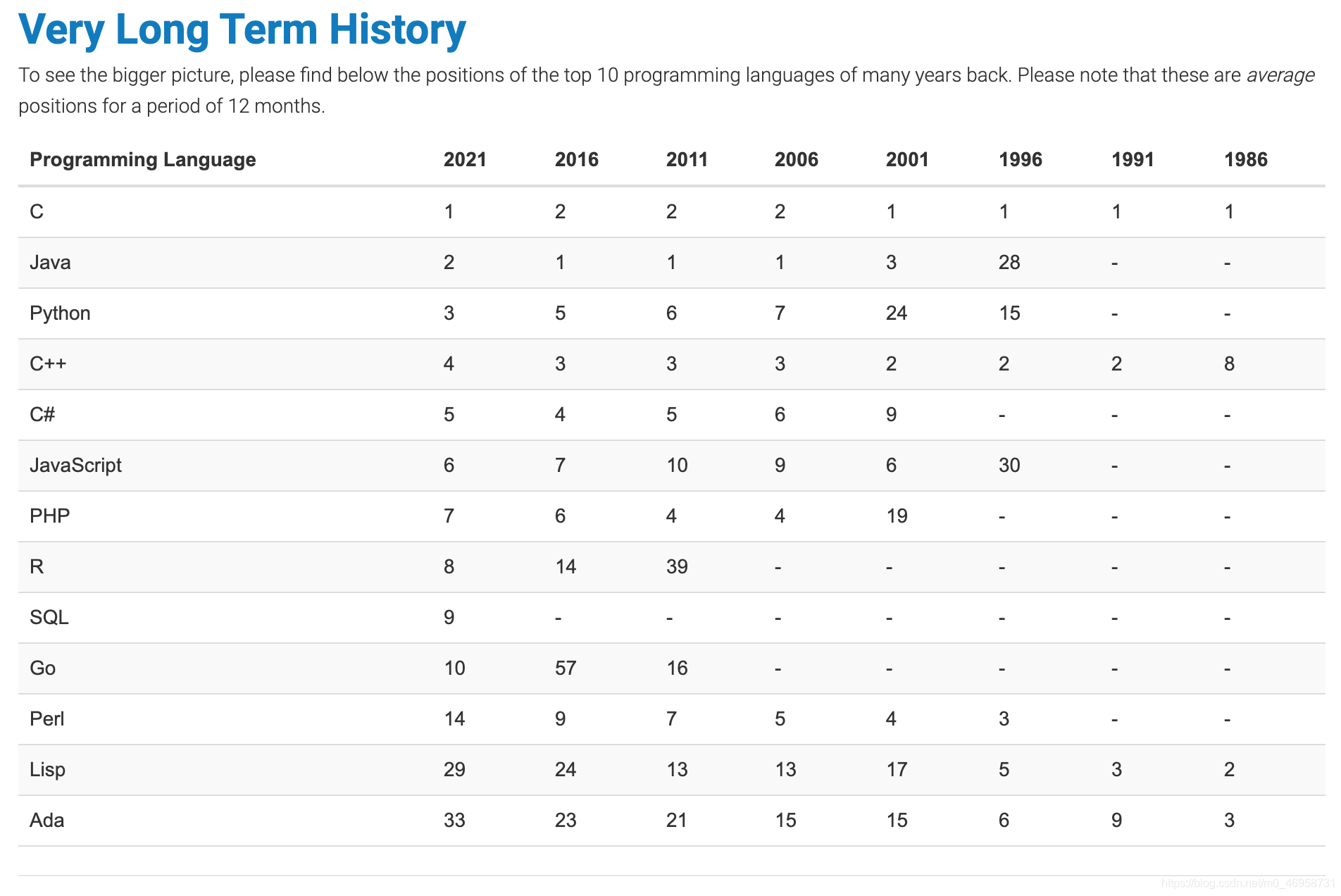
其多次成为年度最受欢迎语言:
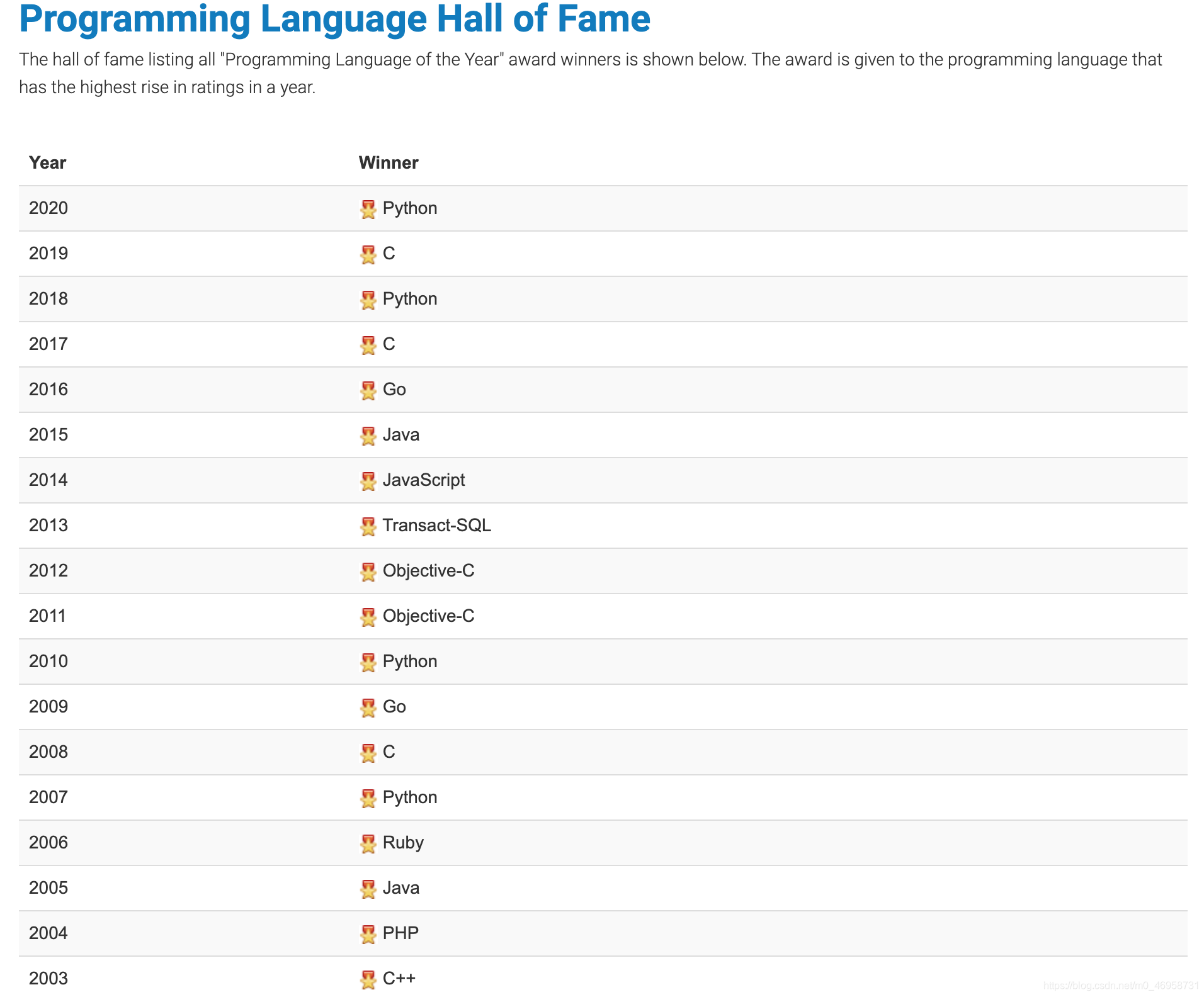
数据来源自:TIOBE Index for January 更新自2021年
综合上序数据信息说明:使用Python的数量在逐渐增加、并对Python给出很多友好的评价,那么我们来了解一下Python的魅力所在把。
文章目录
什么是编程语言,编程语言又有哪些类型?
编程语言又分为两种:编译型、解释型
-
编译型:在运行前有一个编译过程,由编译器将高级语言代码翻译成CPU可以执行的二进制代码,然后生成可执行文件。典型代表有C/C++
-
解释型:相比编译型,运行前的编译过程是没有的,在运行时由解释器成易于执行的代码,并由解释器逐一将代码解释为机器码并执行,并不生成可执行文件。典型代表有Python
动态语言:
动态语言是在运行时期才检查数据类型的,所以在声明变量的时候可以先不指定数据类型,因为在运行期间变量的数据类型是可变的。它会在运行的时候根据赋予变量的值,来判断这个变量的数据类型,然后记录下来。例如Javascript,PHP,Python等。
静态语言:
静态语言是在编译时期就检查数据类型的,所以必须在声明变量的时候指定数据类型,否则编译会不通过。例如C/C++,Java等
强类型语言:
强类型语言是指,变量的数据类型一旦确定下来,就不能改变了,除非经过强制类型转换。例如Java,C#,Python等。
弱类型语言:
弱类型语言是指一个变量可以赋予不同数据类型的值,因为它可以进行隐式的自动类型转换。例如Javascript,C/C++等。
而Python就是动态强类型语言,其运行过程就是解释型运行
一、变量
学习所有编程语言,变量则是最开始所接触的,也是最为常用的,首先来理解什么是变量:
变量指定是:记录下可以变化的事物状态
变:事物的状态是可变化的
量:事物当前的状态
变量是一种存取机制
变量使用原则:
- 先定义
- 再引用
变量是由三部分组成:
- 变量名(用来访问变量值)
- 赋值符号(把值的内存地址绑定给变量名)
- 变量值 (记录事物的状态,即存的数据)
创建变量相当于申请了一块内存空间,把这个值存进去然后通过赋值符号和变量名进行绑定
变量的定义
test = 20
此时test这个变量名已经可以代表20这个值了test <=> 20,变量的书写最好以赋值符号左右隔开
引用变量
print 是python内置方法,用于将括号里面的内容打印到屏幕上
test = 20
print(test)
>>> 20
注意:如果先使用后定义会出现找不到test这个变量的报错信息
print(test)
test = 20
语法错误:可以看到第二个print少了一个括号,造成语法错误,python如果检测到语法错误,那么全部代码都不会运行起来,需要格外注意
print(123)
print(456
print(789)
逻辑错误:指的是某一段代码出现错误,但并不会影响之前代码的运行。
这里从abc那一行开始中断运行,上面两行代码不会受影响,这里出现的错误是abc变量名未定义
print(123)
print(456)
abc
print(789)
变量名的命名
大前提:见名知意
age=18
level=18
在见名知意的前提下应该遵循以下规范:
变量名是由字母数字下划线组成
不能以数字开头
不能使用python语言的关键字(不需要一次性记住 通过后面学习慢慢记忆)
[‘and’, ‘as’, ‘assert’, ‘break’, ‘class’, ‘continue’, ‘def’, ‘del’, ‘elif’, ‘else’, ‘except’, ‘exec’, ‘finally’, ‘for’, ‘from’, ‘global’, ‘if’, ‘import’, ‘in’, ‘is’, ‘lambda’, ‘not’, ‘or’, ‘pass’, ‘print’, ‘raise’, ‘return’, ‘try’, ‘while’, ‘with’, 'yield]
命名的风格
1、纯小写加下划线:age_of_tom = 18(较长的变量名推荐使用这种)
2、驼峰体:AgeOfTom = 18
变量名只要不在等号左边,代表的是取值操作
age = 18
age = age + 1
print(age)
这里下面的age代表新的变量名,将上面的age这个值取出来加1后再赋值给左边的新age(下面会介绍运算)
变量值有两大特征
id:变量值的身份证,反映的是内存地址
type:变量值的类型
id一样,代表内存地址一样,也就说指向的是同一个内存空间,值肯定是一样
x = 10
y = x
z = 'test'
print(id(x))
140457508094688
print(id(y))
140457508094688
print(id(z))
140654736153552
print(type(x),type(y),type('z'))
<class 'int'> <class 'int'> <class 'str'>
Python的一种优化机制,值相同就没必要重新划分一块空间
x = 10
y = 10
print(id(x))
4351208384
print(id(y))
4351208384
垃圾回收机制
Python中是不需要程序员手动管理内存的,它的GC(Garbage Collection)机制 实现了自动内存管理。GC做的事情就是解放程序员的双手,找出内存中不用的资源并释放这块内存。
引用计数:
当一个变量值被多次引用,那么它的计数也会随之增加
x = 20 # 20这个值的内存地址计数+1
y = 20 # 20这个值的内存地址计数+1
# 当前值为2
del x # 解除了x这个变量名与20这个值内存地址的绑定
# 计数-1
del y # 解除了x这个变量名与20这个值内存地址的绑定
# 计数-1
"""
当前20这个值的内存地址没有被任何变量指定,那么它无法被取出
问题就是它会一直占用这块内存空间,如果是C/C++的话是需要
手动清理这个内存空间的,那么在python里面的话,它会排查
如果计数为0的内存地址直接回收掉,不需要程序员手动来
清理它
"""
二、注释
注释的作用是来对所写代码进行一个说明,或是对整体代码文件进行一个说明
单行注释:对某一段代码进行说明,或是暂时不启用此段代码也可以进行注释,被注释后全部不会被当做代码执行
tom_name = "tom"
tom_age = 18 # tom的年龄
# test = 'python'
使用单行注释的标准格式为 # 后跟空格再跟注释内容,注释也可以用来进行代码测试。这里是 test就不会被python所执行。
多行注释:通常用于对整个代码文件进行说明 也可以对某一个代码功能进行多行详解,写法是3双引号或3单引号
"""
2020年x月x日
这个文件用于代码测试
这是3个双引号多行注释
"""
'''
2020年x月x日
这个文件用于代码测试
这是3个单引号多行注释
'''
三、运算符
算法运算符
假设变量x = 10,y = 31
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 两个对象相加 | x + y 输出结果为 41 |
| - | 两个数相减 | x - y 输出结果为 -21 |
| * | 两个数相乘或是返回一个被重复n次的字符串 | x * y 输出结果为 310 |
| / | x除以y | y / x 输出结果为 3.1 |
| % | 取模 返回触除法的余数 | y % x 输出结果为1 |
| ** | 返回x的y次幂 | x ** y 为10的31次方 |
| // | 取接近商的数 | 9 // 2 结果为4 -9 // 2 结果为5 |
print(10 + 3) 13
print(10 - 3) 10
print(10 * 3) 30
print(10 ** 3) 1000
print(10 / 3) 3.33333335
print(10 // 3) 3
print(10 % 3) 1
print(10 * 3.333) 33.33
print([1,2,3]+[3,4,5]) [1,2,3,4,5]
print([1,2,3]*3) [1,2,3,1,2,3,1,2,3]
比较运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于 比较两个对象是否相等 | (a == b) 返回 False |
| != | 不等于 - 比较两个对象是否不相等 | (a != b) 返回 True |
| > | 大于 - 返回x是否大于y | (a > b) 返回 False |
| < | 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价。注意,这些变量名的大写 | (a < b) 返回 True |
| >= | 大于等于 - 返回x是否大于等于y | (a >= b) 返回 False |
| <= | 小于等于 - 返回x是否小于等于y | (a <= b) 返回 True |
print(10 == 10) # True
print(10 > 10) # False 10不大于10
print(10 >= 10) # True
print("abc" != "ddd") # True
print(10 > 3.1) # True
print(10 > "12") # 数字类型不能于字符串进行比较
print("a12" == "a12") # True
print([1,2,3] == [1,2,3]) # True
print("abc" > "az") # False 字符串比较是一个个字符进行比较,参照ASCII码
l1=[111,222,333]
l2=[111,999]
print(l1 > l2) # 也是取出每一个元素进行对比,这是结果为False 因为222不大于999
变量赋值
链式赋值:多个变量进行相同赋值
a = b = c = 10
print(a,b,c)
10 10 10
交叉赋值:多个变量进行不同赋值
a, b, c = 10, 20, 30 # 同时进行多个变量赋值
print(a,b,c)
10 20 30
x = 10
y = 20
x, y = y, x # x与y的值进行交换
解压赋值
# 第一种:必须满足列表的长度定义变量 不能多也不能少 如果少写一个变量就会报错
l = [1,2,3,4,5]
a,b,c,d,e = l
print(a,b,c,d,e)
1 2 3 4 5
# 第二种:自定义取值 从*开始的位置打包后面的值赋给下划线这个变量(也可以定义别的)
# 最后定义的e变量 表示要取最后一个值,所以这个*打包到它前面就停止了
a,b,*_,e = l
print(a,b,e)
1 2 5
print(_) # 打印它的打包内容
[3,4]
逻辑运算符
and:连接左右两边的条件,左右两边的判断结果都为True,结果才为True
or:连接左右两边的条件,左右两边其中一个为True,结果就为True
2 > 1 and 2 > 3 # 判断为False
2 > 1 or 2 > 3 # 判断为True
短路运算:and(有一个错误结果整体都为错误)、or(有正确结果就不看后面的判断)
优先级:not > and > or
not 取反
1 == 3 # 结果为 False
not 1== 3 # 结果为 True
可以判断一下以下的比较结果为 True 还是False
3 > 4 and 4 > 3 or not 1 == 3 and 'x' == 'x' or 3 > 3
先查看not 以及其后面的一个判断条件
再从头开始查看优先级
(3 > 4 and 4 > 3) or (not 1 == 3 and 'x' == 'x') or 3 > 3
括号优先级才是最高的,但这里用到括号主要用于标识
in 用于匹配是否存在该内容 而前面的==是比较两个内容是否相同
name = 'root'
print('r' in name)
True
print('r' == name)
False
四、基本数据类型
在Python中变量不需要声明类型。变量在使用前必须要进行赋值,变量赋值以后才算创建好这个变量
在 Python 中,变量就是变量,它没有类型,我们所说的"类型"是变量所指的内存中对象的类型。
多个变量赋值:
a = b = c = 1 # 多个变量赋值相同
a, b, c = 1, 2, 3 # 多个变量赋值不同
Python3 中有六个标准的数据类型:
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
Python3 的六个标准数据类型中:
不可变数据(3 个):Number(数字)、Str(字符串)、Tuple(元组)
可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)
不可变类型:值改变的情况下,内存地址也变,证明时产生了新的值,即原值不可变=>可hash类型
可变类型:值改变的情况下,内存地址/id不变,证明改变的就是原值,即可变类型=>不可hash类型
type() 可以用来查看数据类型
Number(数字)
Python3 只有一种整数类型 int 表示为长整型,没有Python2的long
# 通常用于存储手机号、qq号、编号、门牌号等等
a = 123 # 整数类型
# 通常用于存储 薪资、身高、体重等等
b = 3.14 # 浮点类型
c = 4+3j # 复数类型
print(type(a),type(b),type(c))
<class 'int'> <class 'float'> <class 'complex'>
a += b # 相当于 a = a + b
print(a)
# 不能对源数据进行更改,但是可以通过相加来进行改变,不再是原来的内存地址了
a = 123
print(id(a))
4411812320
a += 456
print(id(a))
140618798753168
字符串类型(str)
Python 字符串是用两个`单引号`或者两个`双引号`括起来,执行`\`转移 字符串的作用是需要写入字符就需要往这里存储
test_str = 'Hello World'
test_str = "Hello World"
相同的变量名,相同的值则指向内存地址是相同的,不同值的话则是替换的意思
Python 使用反斜杠 \ 转义特殊字符,如果你不想让反斜杠发生转义,可以在字符串前面添加一个 r,表示原始字符串:
test_str = 'Hello \nihao'
print(test_str)
Hello
ihao
str_test = r"Hello\nihao"
print(str_test)
Hello\nihao
因为\n在python里面是代表换行的字符 ,如果坚持这样使用那么在前面添加r
字符串变量值是不可变的,定义了就不能改变,但可以连接或分割
str_test = 'Hello'
test_str = 'World'
test = str_test + test_str # +相对字符串用于两个进行连接
print(test)
HelloWorld
len() 查看变量值的长度
字符串分割:大部分编程语言0代表了第一个,这里指的是获取test变量值的0-5位置的字符,注意:分割 顾头不顾尾 其实只能到截取到第四个
test = 'HelloWorld'
ziye = test[0:5]
print(ziye)
Hello
print(test[-1]) # 代表获取最后一个字符
d
print(test[5:-1]) # 注意 顾头不顾尾 只能获取到 5-倒数第二个字符
Worl
print(test[5:]) # 获取从5-最后一个字符
World
字符串的常用方法
strip() 默认用于去除左右两边的空白
name = ' root '
print(name)
root
print(name.strip())
root
# 首先从最左边往右看 如果有空白就去除,遇到别的字符就停止,再从右往左看去除空白
name = ' ro ot '.strip()
print(name)
ro ot
'''
strip() 如果未加选项默认去除就是空白,但是strip是可以增加去除筛选的
'''
name = '**** root ****'.strip('*') # 这里就是去除*号了
print(name)
root # 注意空白还在
# 或者去除多个
name = '(-)*&123)*)-'.strip('(-)*&')
print(name)
123
split() 字符切割,用于找到字符串中的指定字符进行分隔开来
# 一般用于有规律的字符串进行分隔
name = 'root:tom:jack'.split(':') # 指定分隔符
print(name)
['root','tom','jack'] # 分隔以后会放到列表里面
str类型常用方法过多,介绍字符串的常用方法的阅读博客:
https://blog.csdn.net/m0_46958731/article/details/109864061
列表(List)
List是Python中最常用的数据类型。
列表中的数据类型可以是整数、字符串、列表(嵌套)、字典、集合、元组
列表是写在放括号内的[]
同字符串一样,列表是可以进行索引和截取的。
截取方式:变量名[头上标:头下标]
# List定义 取值
test_list = [123,'abc']
print(test_list)
[123,'abc']
print(test[0])
123
List嵌套
list_test = [123,'abc',['这是嵌套,,,','this is 嵌套...']]
print(list_test[2])
['这是list嵌套,,,','this is list 嵌套...']
print(list_test[2][1])
'this is 嵌套...'
List 反序
test_list = [1,2,3,4,5,6]
print(test_list[::-1])
[6, 5, 4, 3, 2, 1]
列表元素修改
test_list = [1,2,3,4,5,6]
test_list[0] = 10
print(test_list)
[10,2,3,4,5,6]
往列表追加内容
test_list = [1,2,3,4,5,6]
test_list.append(7)
print(test_list)
[1, 2, 3, 4, 5, 6, 7]
往列表插入内容
test_list = [1,2,3,4,5,6]
test_list.insert(1,'this is insert') # 在第一个插入内容 原来的会往后移动
print(test_list)
[1, 'this is insert', 2, 3, 4, 5, 6]
删除列表元素
这里介绍三种方法,实现的效果都是删除元素
pop() 可以通索引删除元素,不索引的话默认删除最后一个元素
test_list = [1,2,3,4,5,6]
test_list.pop() # 可以索引 不索引的话默认删除末尾元素
print(test_list)
[1,2,3,4,5]
print(test_list.pop(0)) # 可以拿到删除的元素值(并不是所以方法可以拿到返回值)
1
print(test_list)
[2,3,4,5,6]
del 通过索引删除
test_list = [1,2,3,4,5,6]
del test_list[1] # 注意:这里不能向上面一样拿到返回值,语法错误
print(test_list)
[1,3,4,5,6]
remove() 方法通过元素值删除
test_list = ['a','b','c','d']
test_list.remove('c') # 注意:不能取到删除的元素值,会返回一个None值(空)
print(test_list)
['a', 'b', 'd']
Dict(字典)
与列表不同的是,字典取值是通过key来取value的,字典的内容也可以存放各个数据类型的值,实例:
dic = {key:value} # 字典是 key:value对应的
# 字典的定义
dic = {'name':'tom','age':18,'height':180,'salary':15300}
# 字典取值 通过key(键)来获取对应的值
print(dic['name'])
tom
# 字典 嵌套列表
dic = {'name':'tom','hobby':['music','movie','basketball']}
print(dic['hobby'][1])
movie
修改字典的内容
dic = {'name':'tom','age':18,'height':180,'salary':15300}
dic['name'] = 'jack'
print(dic)
{'name': 'jack', 'age': 18, 'height': 180, 'salary': 15300}
字典追加内容
dic = {'name': 'jack', 'age': 18, 'height': 180, 'salary': 15300}
dic['width'] = 200
{'name': 'jack', 'age': 18, 'height': 180, 'salary': 15300, 'width': 200}
字典删除内容
通过key删除内容
dic = {'name': 'jack', 'age': 18, 'height': 180, 'salary': 15300}
print(dic)
{'name': 'jack', 'age': 18, 'height': 180, 'salary': 15300}
# 万能删除方法
del dic['name']
print(dic)
{'age': 18, 'height': 180, 'salary': 15300}
# 通过pop方法放入key 删除字典元素
dic.pop('name')
dic.popitem() # 删除字典最后一个元素
字典的常用方法
快速初始化一个字典
# 按元素来进行字典赋值,第一个选项(可填多个)作为key,第二个选项作为value
dic = {}.fromkeys(['name','age'],None) # 拿出一个元素,赋一个值
print(dic)
# {'name':None,'age':None}
dic = {}.fromkeys('abc',None) # 字符串里,每一个字符都算一个元素
print(dic)
# {'a': None, 'b': None, 'c': None}
# 也就是下一章要讲解的遍历
获取字典数据
dic = {'k1':11,'k2':22,'k3':33}
# 获取指定的key值,如果有则返回对应的value,没有的话返回None
print(dic.get('k1'))
11
print(dic.get('aaaa'))
None
# 获取字典的key
res = dic.keys()
print(res)
dict_keys(['k1', 'k2', 'k3'])
# 获取字典的values
res = dic.values()
print(res)
dict_values([11, 22, 33])
# 获取字典的key or items
dic = {'k1':11,'k2':22,'k3':33}
print(dic.items())
dict_items([('k1', 11), ('k2', 22), ('k3', 33)])
# 通过下一章学习for遍历,再对其进行解压赋值可以将每一个内容一次性全拿出来
字典数据操作
# 新增字典值,在没有这个值的情况下,带有返回值value 可以是已存在的key 或是新增key
dic = {'k1':111,'k2':222}
dic.setdefault('k2',2) # 如果没有这个值则增加,已存在则没有效果
print(dic)
{'k1': 111, 'k2': 222}
dic.setdefault('k3',33) # 没有这个值时,则添加进字典
print(dic)
{'k1': 111, 'k2': 222,'k3':33}
# 更新字典内容
dic = {'k1':111,'k2':222}
dic2 = {'k1':100,'k3':300} # 一个新的字典,对旧的字典进行更新
dic.update(dic2) # 如果已存在内容,则更新,不存在内容,则添加
print(dic)
{'k1': 100, 'k2': 222, 'k3': 300} # 将dic2的内容更新到dic1
Tuple(元组)
元组使用方法和列表类似,但元组已存的数据不能对其进行更改但是可以更改其子元素
# 元组的定义,
test_tuple = (1,2,3,4)
print(test_tuple)
(1,2,3,4)
test_tuple[0] = 10 # 元组创建时的数据不可变,此行报错
# 元组不能增加内容
# 元组的引用
print(test_tuple[1])
2
注意:如果元组只有一个数据,一定要跟上逗号,不然数据会被当成数字类型处理,
因为在做数字类型计算的时候也可以用到括号
test_tuple = (1,)
修改元组子元素的内容
只要没有修改元组里的元素本身,那么里面数据是可变类型就可以更改
test_tuple = (1,2,3,['a','b','c'])
print(test_tuple)
(1, 2, 3, ['a', 'b', 'c'])
print(id(test_tuple[3]))
140602894031872
# 可以修改列表里的子元素 而修改列表子元素与元组无关,且列表为可变数据类型
test_tuple[3][0] = 'A'
print(test_tuple)
(1, 2, 3, ['A', 'b', 'c'])
print(id(test_tuple))
140602894031872 # 通过观测可以看到列表自身并没有发生改变
注意:
test[3] = 12 # 这就表示修改了元素本身,所以直接报错
元组的内置方法
tp = (1,2,3,4,1,2,2,'a','d',333,'d')
print(tp.count(2)) # 找到2这个数字出现的次数
3
print(tp.index('d')) # 找到第一d出现的位置索引
8
Set(集合)
用于对相同数据进行去重,关系运算,经过集合后的数据顺序会被打乱,使用集合具备前提:集合内元素必须是不可变类型、集合内元素唯一。限制较多,不常用数据类型了解即可
# 集合的基本使用
# 集合定义方法:在{}内用逗号隔开多个不可变类型数据
# 不可以放列表,因为列表是可变类型,如果放入可变数据类型,直接报错
res = {1,2,3,4,1,2,'aaa',3.3,(1,2,3)}
{1,2,3,4,(1,2,3),'aaa'} # 去掉了重复元素1 2
# 数据类型转换
res = set('hello')
{'h','e','o','l'} # 经过set以后 顺序会乱,但是放进的都是去重过的内容
# 通过set以后 内容顺序会被打乱,如果对顺序有要求,不建议使用集合
lis = [111,22,333,111,'aaa',(1,2,3,4)]
st = set(lis) # 将列表内容逐个放进集合里
{333, 111, (1, 2, 3, 4), 22, 'aaa'}
关系运算符
s1 = {'Tom1','Tom2','Tom3','Tom4','Tom5','Tom6'}
s2 = {'Tom4','Good','Tom5'}
# & 交集
print(s1 & s2) # 取出两个集合相同的内容
# {'Tom4', 'Tom5'}
# 差集
print(s1 - s2) # 取出s2 没有的数据
# {'Tom1', 'Tom3', 'Tom2', 'Tom6'}
# | 并集
print(s1 | s2) # 将两个集合内容合在一起(集合默认带有去重效果,两个相同只会保留一个)
# {'Tom1', 'Tom3', 'Good', 'Tom5', 'Tom4', 'Tom2', 'Tom6'}
# ^ 对称差集
print(s1 ^ s2) # 并集 减去 交集(合在一起,减去重复元素)
# {'Good', 'Tom3', 'Tom2', 'Tom1', 'Tom6'} (Tom4、Tom5没了)
print(s1 == s2) # 里面元素内容是否相同(不需要排序一样)
# False
# 父集
print(s1 >= s2) # 表示s1里面 完整包含了s2的全部内容,如果成功则打印True
# False (因为下面多了一个Good)
s1 = {1,2,3}
s2 = {3,2,1}
# 子集
print(s1 >= s2) # 表示s2里面 是否完整包含了s1的全部内容,如果成功则打印True
# True
# 上序可以说 即当父集 也为子集,因为内容完全相同
删除更新内容
# 更新、删除
s1.update({1,2,3,7}) # 更新内容,如果不存在则添加进去
print(s1)
{1, 2, 3, 4, 5, 7}
st = {'aaa',22,'ccc',33}
st.pop() # 随机删除集合元素
print(st)
{222,333,'ccc'}
st = {'aaa',22,'ccc',33}
st.remove('dddd') # 删除指定元素,如果内容不存在则报错
print(st)
st = {'aaa',22,'ccc',33}
st.discard('dddd') # 删除指定元素,如果内容不存在不会报错(推荐使用这种)
print(st)
bool(布尔类型)
bool 只有两个值:True、False
True 代表真、False 代表假
另外一些其它的值也可以代表 True、False
它们分为显性和隐性
显性:
print(1 == True) # 1 可以直接代表 True
True
print(0 == False) # 0 可以直接代表 False
True # 比较成功结果才为True
'''
False [] {} "" '' None 这些都可以代表 False
True 1 以及除开0的其它数字
'''
bool() # 把内容转换成bool类型
print(bool([]) == False) # True
print(bool({}) == False) # True
print(bool("") == False) # True
print(bool('') == False) # True
# 这些 判断都成立 表示它们确实可以代表False
print(bool(-1) == False) # 结果为False 因为数字只有0可以代表False
print(bool(-1) == True) # True
隐性
print(5 > 10) # False
print(10 > 5 and 5 < 10) # True
print(not 5 > 10 and 20 > 15) # True
print(False > True) # False
五、类型转换
当数据类型符合转换标准才能够转换
x = '123'
x = int(x) # x变量值 带有数字字符 可以转换成数字不会报错
print(type(x))
<class 'int'>
x = 'abc'
x = int(x) # 内容不符合转换,直接报错
x = [1,2,3,4,5]
x = str(x) # 所有类型都可以转换成字符串
print(type(x))
<class 'str'>
x = '[1,2,3,4,5]'
x = list(x) # 内容符合 才可以转换成列表类型
print(type(x))
<class 'list'>
# 内容转字典
lis = [('k1',111),('k2',222),('k3',333)]
dic = dict(lis) # 将内容转换成字典
print(dic)
{'k1': 111, 'k2': 222, 'k3': 333}
dic = dict(k1=111,k2=222,k3=333) # 第二种方法,也可以将上面这样理解
print(dic)
{'k1': 111, 'k2': 222, 'k3': 333}
技术小白记录学习过程,有错误或不解的地方请指出,如果这篇文章对你有所帮助请
点赞收藏+关注谢谢支持!

















 29万+
29万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









