







1.摘要
本文提出了一种新的端到端模型,称为双鉴别器条件生成对抗网络(DDcGAN),用于融合不同分辨率的红外和可见光图像。与像素级方法和现有的基于深度学习的方法不同,融合任务是通过生成器和两个鉴别器之间的对抗过程来完成的,此外还有专门设计的内容损失。
2.引言
图像融合的关键是提取源图像中的重要信息并进行融合,为此,研究人员提出了各种特征提取策略和融合规则,如基于多尺度变换的方法,稀疏表示,子空间,显著性,杂交以及其他方法。虽然这些工作取得了很好的效果,但也存在一些不足。
- 在传统方法中,人工设计的规则使得方法越来越复杂和繁琐
- 深度学习的方法的缺点显著
- 总体上,它们关注于提取和保留特征,而没有考虑为了更有利的后续处理和应用而增强重要特征
- 由于硬件的限制,红外图像的分辨率往往较低。可见光图像
降采样或红外图像升采样的方法会导致热辐射信息模糊或纹理细节丢失。
因此,融合不同分辨率的图像仍然是一个具有挑战性的任务。针对上述问题,提出了一种基于双判别条件生成对抗网络(DDcGAN)的生成模型学习方法.融合任务是通过一个发生器和两个鉴别器之间的对抗过程来完成的。整个网络是一个端到端的模型,不需要设计融合规则,通过附加的鉴别器,融合图像可以在更大程度上突出热目标
贡献点:
- 突破了大多数方法只是在某些子部分应用深度学习框架的局限,同时并不局限于应用深度学习来最大限度地减少像素级损失。我们从概率分布的角度出发,基于一个极小极大的两人博弈模型进行了求解,并考虑了内容损失
- 双鉴别器的结构可以避免在一种类型的源图像上引入鉴别器而导致另一种类型的源图像中的信息丢失
- FusionGAN中生成器的目标是生成具有主要红外强度和附加可见光梯度的融合图像,而鉴别器的目标是迫使融合图像具有可见光图像中存在的更多细节。导致红外图像中的信息丢失
- DDcGAN从概率分布的角度进行求解,不仅能够提取、融合和重构特征,而且能够增强源图像中的重要特征,即:热目标和背景之间的对比度。
- 在 D i D_i Di之前的下采样操作和专门设计的损失表现出优异的性能,也适合不同分辨率的图像融合
现有工作的缺点:
- 现有的方法在特征提取或重构时使用神经网络,而整个框架不能摆脱传统方法的局限性
- 利用深度学习进行红外和可见光图像融合的绊脚石是缺乏ground truth,现有方法通过设计内容损失函数来解决。然而,它们可能会带来新的问题
- 大多数人工设计的融合规则导致提取相同的特征,而源图像是不同现象的表现。
- 现有的基于GAN的方法通过引入鉴别器来迫使融合图像获得可见光图像中的更多细节。随着对抗性博弈的进行,热效应的显著性逐渐降低。为了解决这个问题,我们采用了遗传算法,并在遗传算法中加入了双重鉴别器。我们还适应于不同分辨率的图像融合。此外,为了保证训练过程的稳定性,对网络架构和训练策略进行了优化。
3. 网络详情
DDcGAN的整个过程如下图所示,最终目标是学习一个以v和i为条件的生成器网络G,然后,由G生成的融合图像
f
=
G
(
v
,
i
)
f = G(v,i)
f=G(v,i)本网络开发了两个鉴别器网络
D
v
D_v
Dv和
D
i
D_i
Di。它们分别生成一个标量,该标量估计来自真实的数据而不是
G
G
G的输入的概率。不同之处在于
D
v
D_v
Dv和
D
i
D_i
Di的真实的数据是有区别的,甚至是不同类型的。具体地,
D
v
D_v
Dv的目的是区分生成图像
f
f
f的梯度和可见光图像
v
v
v的梯度,而
D
i
D_i
Di被训练来区分原始低分辨率红外图像
i
i
i和下采样的生成/融合图像
ψ
f
ψ_f
ψf,其中
∇
∇
∇是梯度算子,
ψ
ψ
ψ是下采样算子。
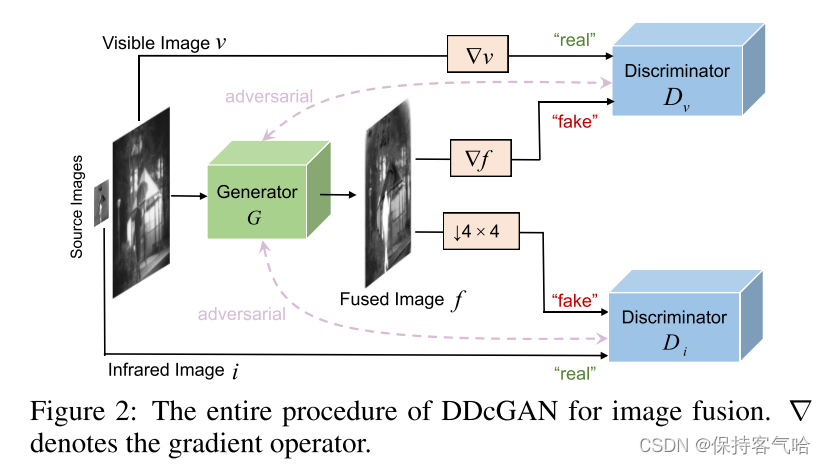
其中G的训练目标可以被公式化为最小化以下对抗目标
m
i
n
G
m
a
x
D
v
,
D
i
E
[
l
o
g
D
v
(
∇
v
)
]
+
E
[
l
o
g
(
1
−
D
v
(
∇
f
)
)
]
+
E
[
l
o
g
D
i
(
i
)
]
+
E
[
l
o
g
(
1
−
D
i
(
ψ
f
)
)
]
\underset{G}{min}\underset{D_v,D_i}{max}E[logD_v(∇v)]+E[log(1-D_v(∇f))]+E[logD_i(i)]+E[log(1-D_i(ψf))]
GminDv,DimaxE[logDv(∇v)]+E[log(1−Dv(∇f))]+E[logDi(i)]+E[log(1−Di(ψf))]
通过生成器和两个判别器的对抗过程,两个分布之间的散度,即
P
∇
F
P_ {∇F}
P∇F和
P
∇
V
P_{∇V}
P∇V之间的散度和
P
ψ
F
P_ {ψF}
PψF,
P
I
P_{I}
PI和同时变小。
P
∇
F
P_ {∇F}
P∇F是生成样本梯度的概率分布,
P
ψ
F
P_ {ψF}
PψF是下采样生成样本的概率分布。
P
∇
V
P_{∇V}
P∇V是可见光图像梯度的概率分布,
P
I
P_{I}
PI是红外图像梯度的概率分布。
3.1 损失函数
引入内容丢失以将一组约束包括到网络中,因此,在本文中,生成器不仅被训练成能骗过鉴别器,而且还被赋予约束生成的图像与源图像在内容上的相似性的任务。因此,发生器的损失函数由对抗损失
L
G
a
d
v
L^{adv}_G
LGadv和内容损失
L
c
o
n
L_{con}
Lcon组成,权重
λ
λ
λ控制权衡:
L
G
=
L
G
a
d
v
+
λ
L
c
o
n
L_G = L^{adv}_G + \lambda L_{con}
LG=LGadv+λLcon
其中来自判别器的 L G a d v L^{adv}_G LGadv被定义为:
L G a d v = E [ l o g ( 1 − D v ( ∇ f ) ) ] + E [ l o g ( 1 − D i ( ψ f ) ) ] L^{adv}_G = E[log(1-D_v(∇f))]+E[log(1-D_i(\psi f))] LGadv=E[log(1−Dv(∇f))]+E[log(1−Di(ψf))]
由于红外图像中的热辐射信息是以像素强度为特征的,我们使用Frobenius范数来约束下采样融合图像具有与红外图像相似的像素强度。下采样操作可以显著地防止由压缩引起的纹理信息的丢失或由强制上采样引起的模糊。另一方面,可见光图像中的纹理细节主要以梯度变化为特征。因此,TV范数 被应用于约束融合图像以展示与可见图像类似的梯度变化。利用权重
η
η
η来控制权衡,我们可以获得内容损失:
L
c
o
n
=
E
[
∣
∣
ψ
f
−
i
∣
∣
F
2
+
η
∣
∣
f
−
v
∣
∣
T
V
]
L_{con} = E[||\psi f - i||^2_F +\eta||f-v||_{TV}]
Lcon=E[∣∣ψf−i∣∣F2+η∣∣f−v∣∣TV]
其中ψ表示下采样算子,由于其保留了低频信息,因此通过两个平均池化层来实现。
训练鉴别器以在真实的数据和生成数据之间进行鉴别。鉴别器的对抗损失可以计算分布之间的JS散度,从而识别像素强度或纹理信息是否真实。
L D v = E [ − l o g D v ( ∇ v ) + E [ − l o g ( 1 − D v ( ∇ f ) ) ] ] L_{D_v} = E[-logD_v(∇v)+E[-log(1-D_v(∇f))] ] LDv=E[−logDv(∇v)+E[−log(1−Dv(∇f))]]
L D i = E [ − l o g D i ( i ) + E [ − l o g ( 1 − D i ( ψ f ) ) ] ] L_{D_i} = E[-logD_i(i)+E[-log(1-D_i(\psi f))] ] LDi=E[−logDi(i)+E[−log(1−Di(ψf))]]
内容丢失是通过将一个额外的重构网络引入到DDcGAN中实现的。这个重构网络被用来计算输入图像的内容特征。DDcGAN通过将生成的图像和输入图像的内容特征进行比较来引入额外的约束条件。这个比较过程的结果是一个“内容损失”,它衡量了生成的图像与输入图像在内容上的相似度。
3.2 网络架构
3.2.1 Generator Architecture
生成器网络是编码器-解码器网络,在编码器之前有2个上采样层,如下图所示。针对红外图像分辨率较低的特点,首先通过最近邻插值引入两层上采样层,实现两种分辨率之间的变换。这2层的输出是上采样的红外图像。上采样的红外图像和原始可见光图像被连接并馈送到编码器。特征提取和融合过程都在编码器中执行,并产生融合的特征图。然后将这些映射馈送到解码器以进行重构。
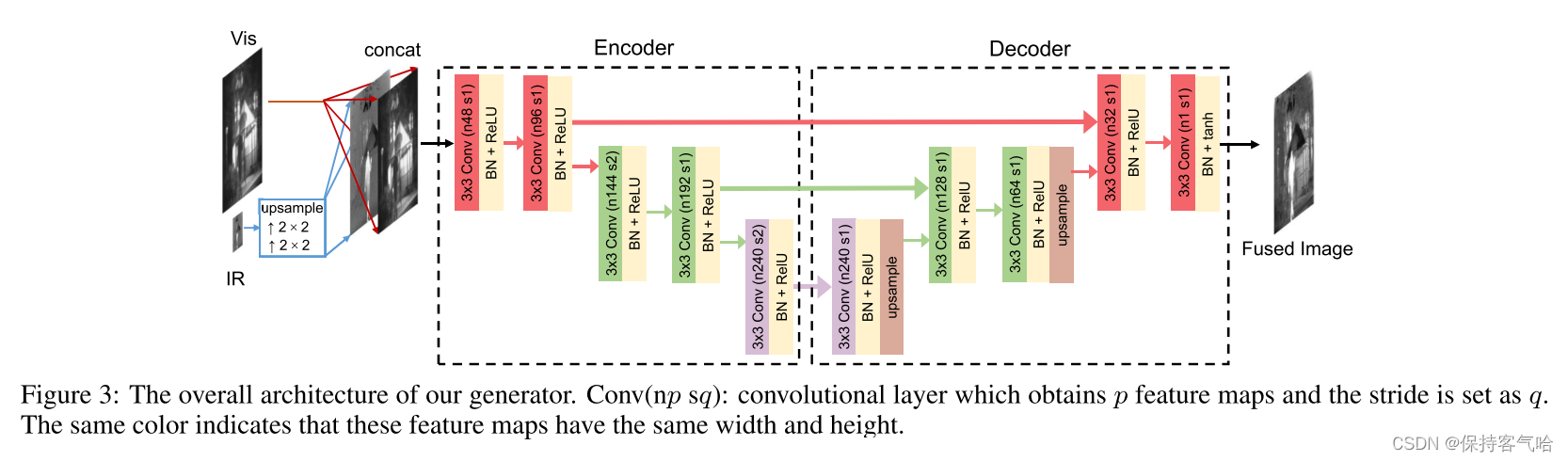
编码器由5个卷积层组成。输出特征图的数量和每个卷积层的跨距如上图所示。如果红色的特征图大小为W ×H,则绿色和紫色的特征图大小分别为W/2 ×H/2和W/4 ×H/4。考虑到编码器中第二层和第四层中步长设置为2所导致的损失,这里使用了U-net架构
这些特征图与解码器自身获得的特征图级联以用于后续卷积和上采样操作。解码器是5层CNN,每层的设置如图3所示。所有卷积层的跨距被设置为1。由第一和第三卷积层获得的特征图类似地通过最近邻插值进行上采样。为了避免梯度爆炸/消失,加快训练和收敛速度,采用了批量归一化(BN)和ReLU激活函数。
3.2.2 Discriminator Architecture
判别器的设计目的是对发生器起对抗作用。具体地,
D
v
D_v
Dv旨在区分生成图像的梯度与可见光图像的梯度,
D
i
D_i
Di旨在区分生成图像与红外图像。然而,这两种类型的源图像是不同现象的表现,因此具有相当大的不同分布。换句话说,
D
v
D_v
Dv和
D
i
D_i
Di对G的指导存在冲突。在我们的网络中,我们不仅要考虑生成器和鉴别器之间的对抗关系,还要考虑
D
v
D_v
Dv和
D
i
D_i
Di的平衡。否则,随着训练的进行,一个鉴别器的强或弱将最终导致另一个鉴别器的低效率。在我们的工作中,这种平衡是通过架构设计和训练策略来实现的
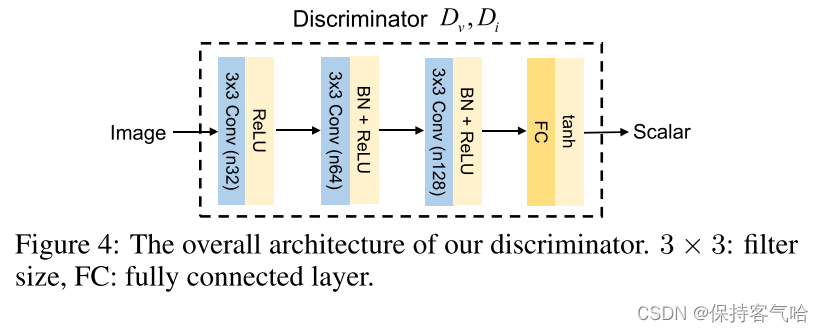
D v D_v Dv和 D i D_i Di共享相同的架构,如图4所示。所有卷积层的跨距被设置为2。在最后一层中,我们使用双曲正切激活函数来生成标量,该标量根据源图像而不是G来估计输入图像的概率。
3.3 训练
数据集:TNO
选择36幅红外和可见光图像并裁剪成27000+个面片对作为训练数据集。假设可见光图像的分辨率为红外图像的4 × 4,可见光区域的大小为84×84,红外区域的大小为21 × 21。λ设为0.8,η设为3。学习速率被设置为0.002,具有指数衰减。batch size为24,epoch设置为1。
原则上不是每批轮流训练G、Dv和Di一次,而是如果不能区分从G生成的数据,则训练Dv或Di更多次,反之亦然。
在测试阶段,仅使用发生器生成融合图像。由于在我们的生成器中没有完全连接的层,所以输入可以是整个图像而不是图像块。
3.3.1 实验结果
将DDcGAN与5种最新方法进行了比较,由于之前方法要求源图像具有相同的分辨率,所以在执行这些方法之前对低分辨率红外图像进行上采样。定性比较首先进行定性实验,下图展示了对比结果

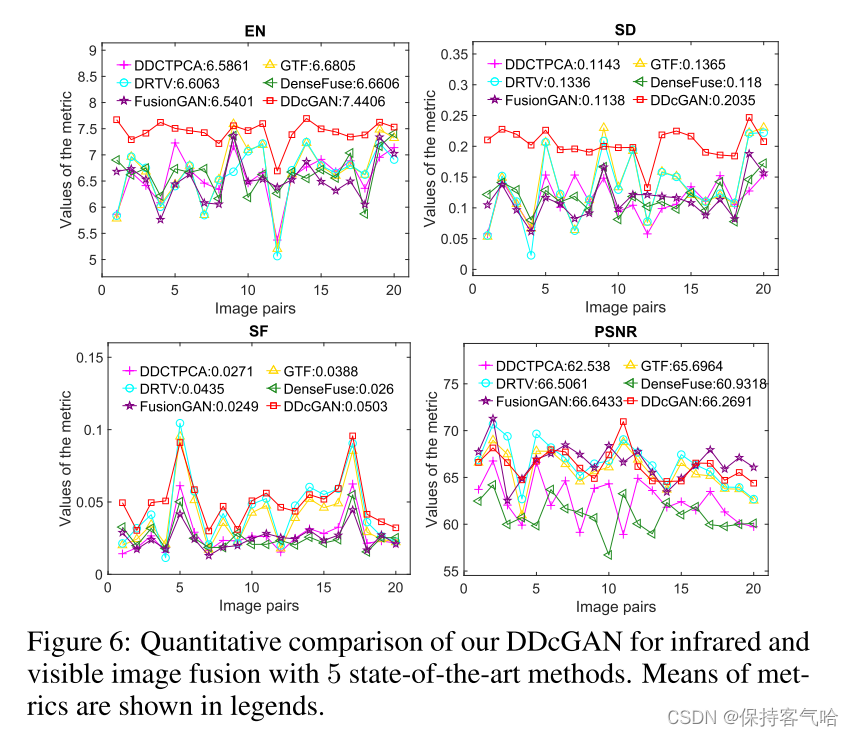
之后作者又进行了定量比较,将DDcGAN与上述竞争对手在数据集的其余20个图像对上进行了定量比较。四个指标,即:熵(EN)、标准差(SD)、空间频率(SF)和峰值信噪比(PSNR)用于评估。结果总结见下图
4.总结
在本文中,我们提出了一种新的基于深度学习和GAN的红外和可见光图像融合方法,通过构建一个双鉴别器条件GAN,命名为DDcGAN。该方法不需要ground truth融合图像进行训练,能够融合不同分辨率的图像,且不会引入热辐射信息模糊和可见纹理细节损失。与其他五个最先进的融合算法的四个指标的广泛比较表明,我们的DDcGAN不仅可以识别最有价值的信息,但也可以保持最大或接近最大量的信息源图像。在我们未来的工作中,我们将把我们的DDcGAN应用于不同分辨率的多模态医学图像,例如,低分辨率正电子发射断层摄影(PET)图像和高分辨率磁共振成像(MRI)图像。














 3096
3096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









