







何为人工智能(f(x)=y)
1 定义:人工+智能:人工=》机器;
智能=》学习;
2.机器学习:强调重组已有的经验和规律,研究出一个新的规律,此规律能够更高效的解决现有的问题。 [f(x)=y中的" f "],机器学习就是要通过已知的x和y去获得“f”
线性f和非线性f

KNN
- 什么是KNN
K-Nearest Neighbor algorithm
- "K"分类时要考虑的K个最邻近的样本,分类时,要选择在某个标准下与其最邻近的前K个样本,然后,少数服从多数,这K个样本属于哪个类别的多就属于哪个类别
- "NN"原理:即就近原则,按特征分类。物以类聚,人以群分,但在不同场合,分类标准时不同的,不同的分类标准即定义不同的距离,即相似度。NN有两种样本,一种是已有类别的样本,另一种时没有类别的样本,没有类别的样本会根据与已有类别的样本之间的某种距离选择最邻近样本的距离选择最邻近某种样本的类别作为自己的类别。
- 算法的思想

- 小结
深度学习
ANN:artificial neural network 神经网络
1.深度学习展现的成就(领域)
- 计算机视觉
- 语音识别
- 自然语言处理
- 机器人研发
2.深度学习的概念
深度学习的概念来自人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别获特征,以发现数据的分布式特征表示。
神经网络
1.神经网络的概念
神经网络反映人类大脑的行为,允许计算机程序识别模式,以及解决人工智能、机器学习和深度学习领域的常见问题。
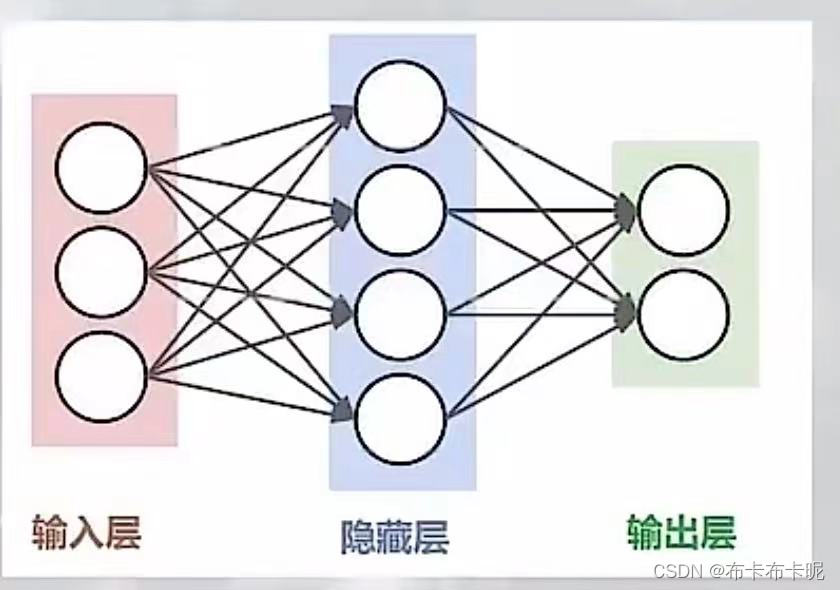
2.神经网络的结构
感知器
感知器是由两层神经元组成的结构,输入层用于接受外界输入信号,输出层(也被称为是感知器的功能层)就是M-P神经元。
3.神经网络的几大要素
- 神经元节点(颜色、纹理、瓜蒂、回音、沙囊、甜等)
- 节点组成的层
- 输入层(颜色、纹理、瓜蒂、回音等神经元组成的层)
- 隐藏层(沙囊、甜等神经网络组成的层)
- 输出层(买、不买等神经元组成的层)
- 参数:
- 各层节点间的权值(不同权重的影响)(weights)
- 各层节点自己的偏移量(bias)(随机因素)
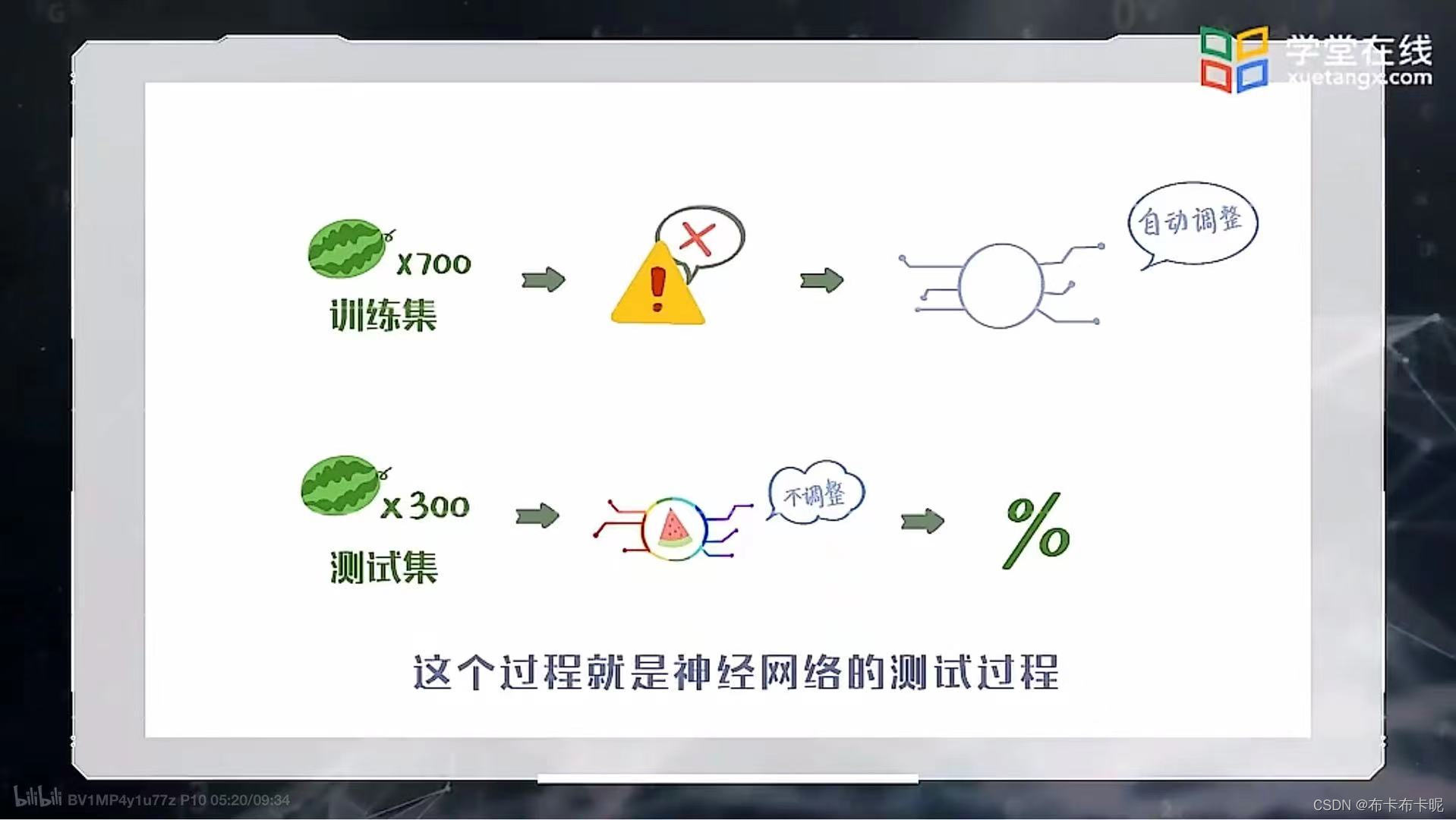
4.神经网络的测试集和训练集
训练过程:形成的是训练集,若学习过程中,神经网络判断出现错误,需要自动调整权重等模型参数
测试过程:形成的是训练集,是用已经训练好的神经网络模型来判断,过程中,不再调整模型参数,只计算模型的预测准确率
5.KNN方法和神经网络方法的区别
KNN方法特征提取涉及过程完全依赖于人(是白盒算法,中间结果是能看见的)
神经网络把特征提取交给机器,特征提取的过程无需机器,由机器自动训练完成(是黑盒算法,中间结果看不见,不能估计每个特征对模型的重要性)
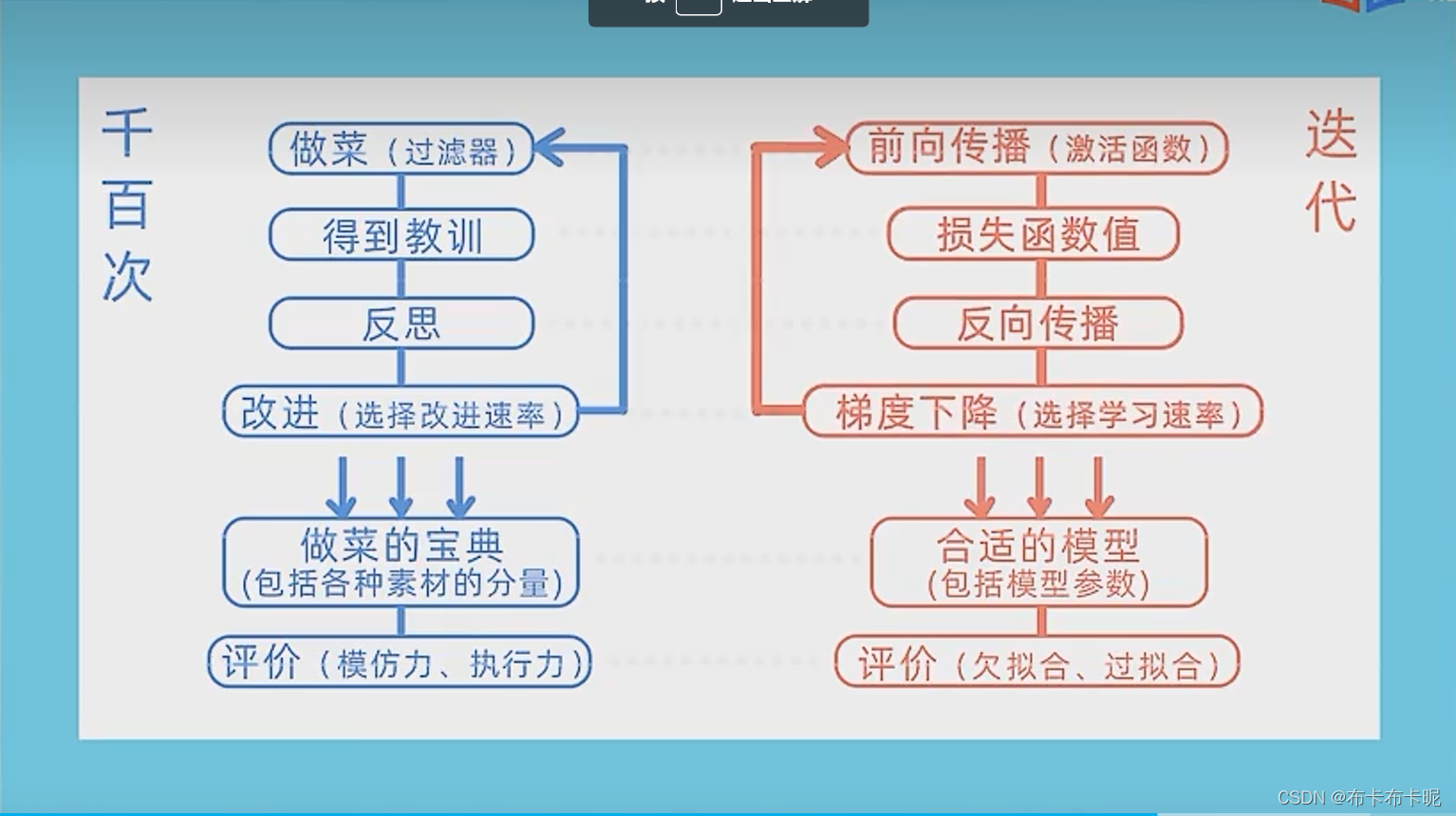
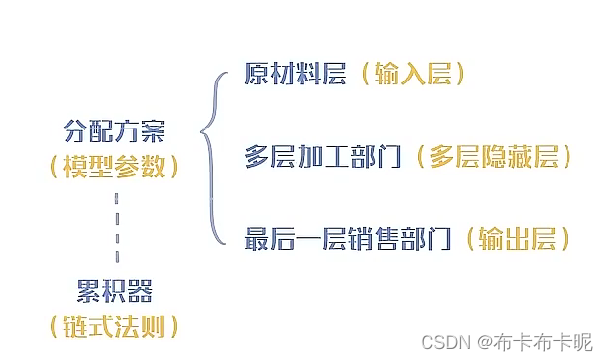
深度学习的过程(以做菜为对比联系)
过程
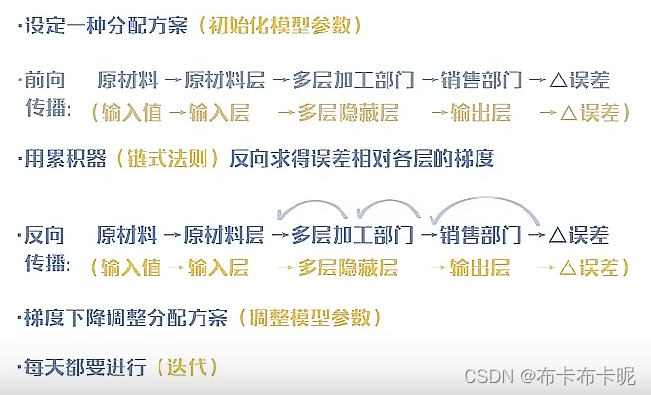
为了自动设定合适的(非人工定义)模型参数(包括各种素材的分量等),例如权重和偏移量。
前向传播(做菜),里面会有激活函数(过滤器)
得到损失函数值(教训)
然后反向传播(反思)
选择学习速率(改进速率)用梯度下降改进模型,例如权重和偏移量(改进)
迭代(千百次反复)
得到合适的模型(做菜的宝典)
模型要避免欠拟合(模仿力不足)和过拟合(模仿力够但执行力不够)
激活函数
- 激活函数=激活+函数
在深度学习中,激活函数作用于隐藏层和输出层的神经元。当神经元的信息达到一定标准,就激活神经元后面的激活函数,把该神经元信息传递到下一神经元。 - 激活函数能够过滤信息,即能够区分出无效信息和有效信息。深度学习中只有有了激活函数才有非线性分类能力,才能拟合各种曲线。
- 激活函数的特性:可微性、单调性、输出值有限
网络参数
- 超参数:指在开始学习前就设置好的,一般是根据经验确定的变量(学习速率,迭代次数、隐藏层的层数、每个层各自的单元数)。超参数确定模型,并对网络性能产生影响。
- 另一种参数:模型根据数据集自动学习而形成的变量(权重,偏移量)
- 数据集的3类(训练集,验证集,测试集)

- 数据集的3类(训练集,验证集,测试集)
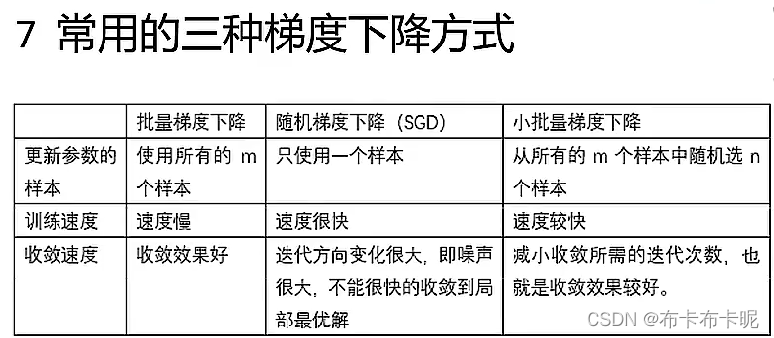
梯度下降(以下山为例)
梯度+下降:是一种优化算法,是目标函数取得极小值的优化算法。深度学习中,是通过找损失函数的极小值来找损失函数对应的极小值点(即让预测的输出值y和实际的y之间的损失函数取极小值的优化算法)

反向传播
一种通过链式法则求解梯度的方法
- 为什么用链式法则
求解梯度是求解目标函数在某参数值的梯度。
深度学习中是求解损失函数在某参数值的梯度 ,梯度是调整参数的依据。 - 为什么“反向”
因为求解损失函数的相对中间环节的梯度需要依赖损失函数对后面环节的梯度=》求解“从后往前”传递梯度效率高。
欠拟合和过拟合
拟合就是用一个预测函数逼近目标函数。拟合的好坏可以用预测函数和目标函数逼近的吻合程度来描述。在机器学习中,泛化能力是衡量预测函数对目标函数的拟合程度的一种评价标准。















 279
279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









