










文章目录
- 一、基础知识
- 二、Dataset和Dataloader
- 三、TensorBoard
- 四、[Transform](https://pytorch.org/vision/stable/transforms.html)
- 五、神经网络基本骨架 nn.module的使用
- 1、[containers](https://pytorch.org/docs/stable/nn.html#containers)
- 2、[torch.nn.functional.conv2d](https://pytorch.org/docs/stable/generated/torch.nn.functional.conv2d.html#torch.nn.functional.conv2d)
- 3、[torch.nn.Conv2d](https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html#torch.nn.Conv2d)
- 4、池化层
- 5、非线性激活
- 6、[Recurrent layer](https://pytorch.org/docs/stable/nn.html#recurrent-layers)
- 7、线性层
- 8、[torch.nn.Sequential](https://pytorch.org/docs/stable/generated/torch.nn.Sequential.html#torch.nn.Sequential)
- 9、loss_function
- 10、优化器
一、基础知识
1、pycharm实用技巧
- Ctrl+P:显示方法所需参数
2、python中内置函数 _call _ 的用法
_call _就是相当于写类名就可以直接调用
而其他的方法是要具体到方法名才能调用
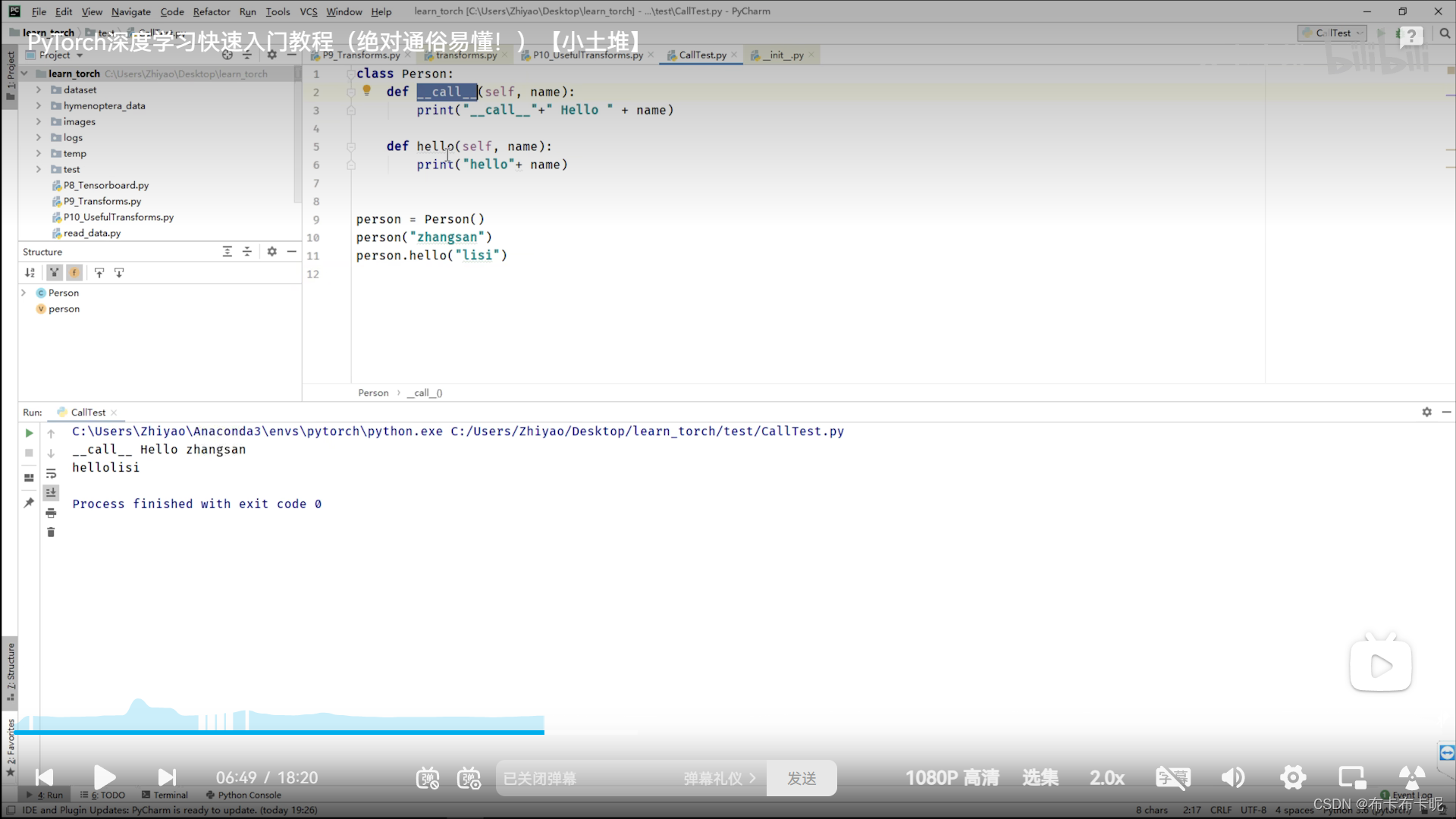
3、torch.reshape()
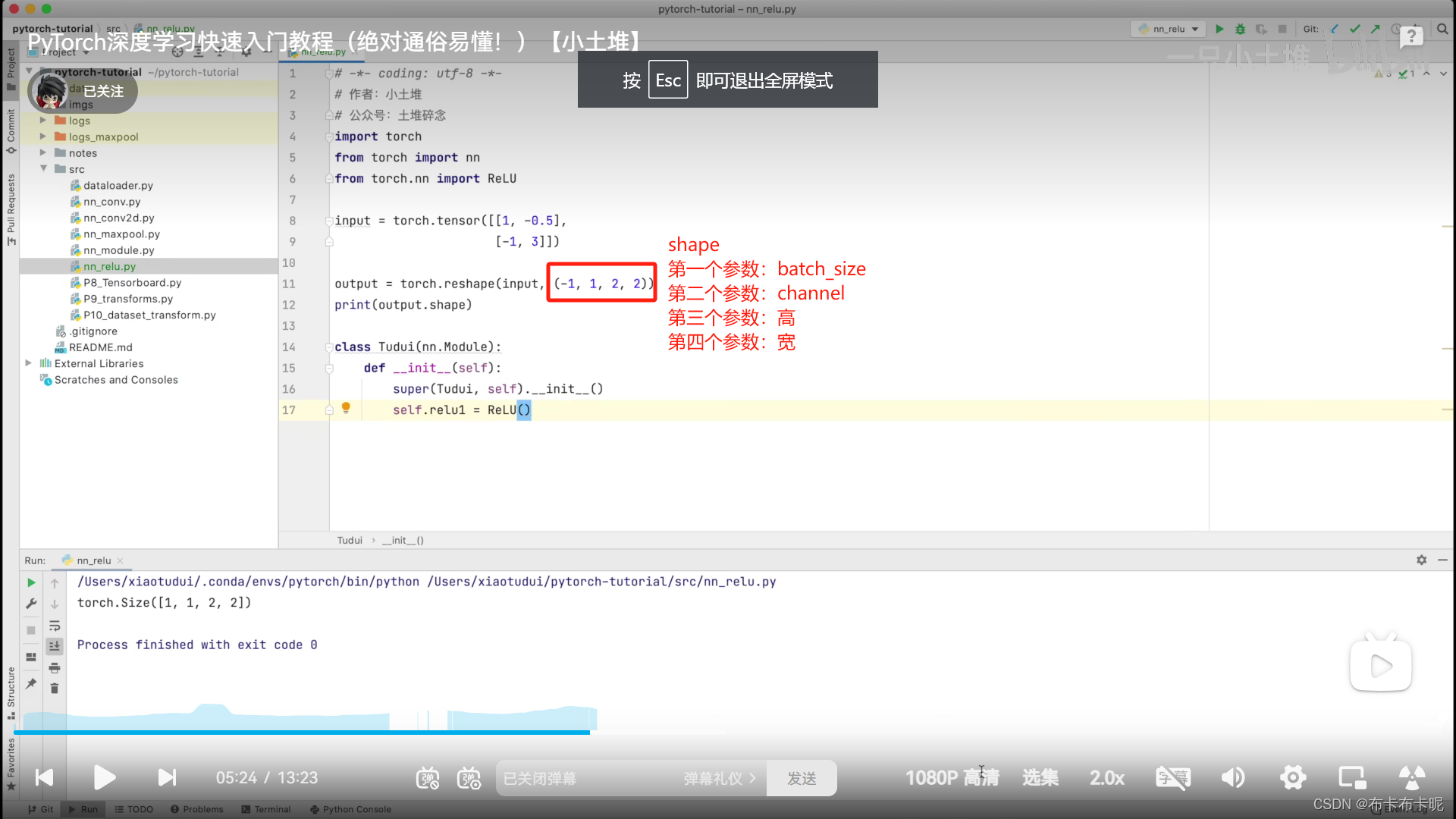
4、N
pytorch官方文档中的N一般表示batch_size
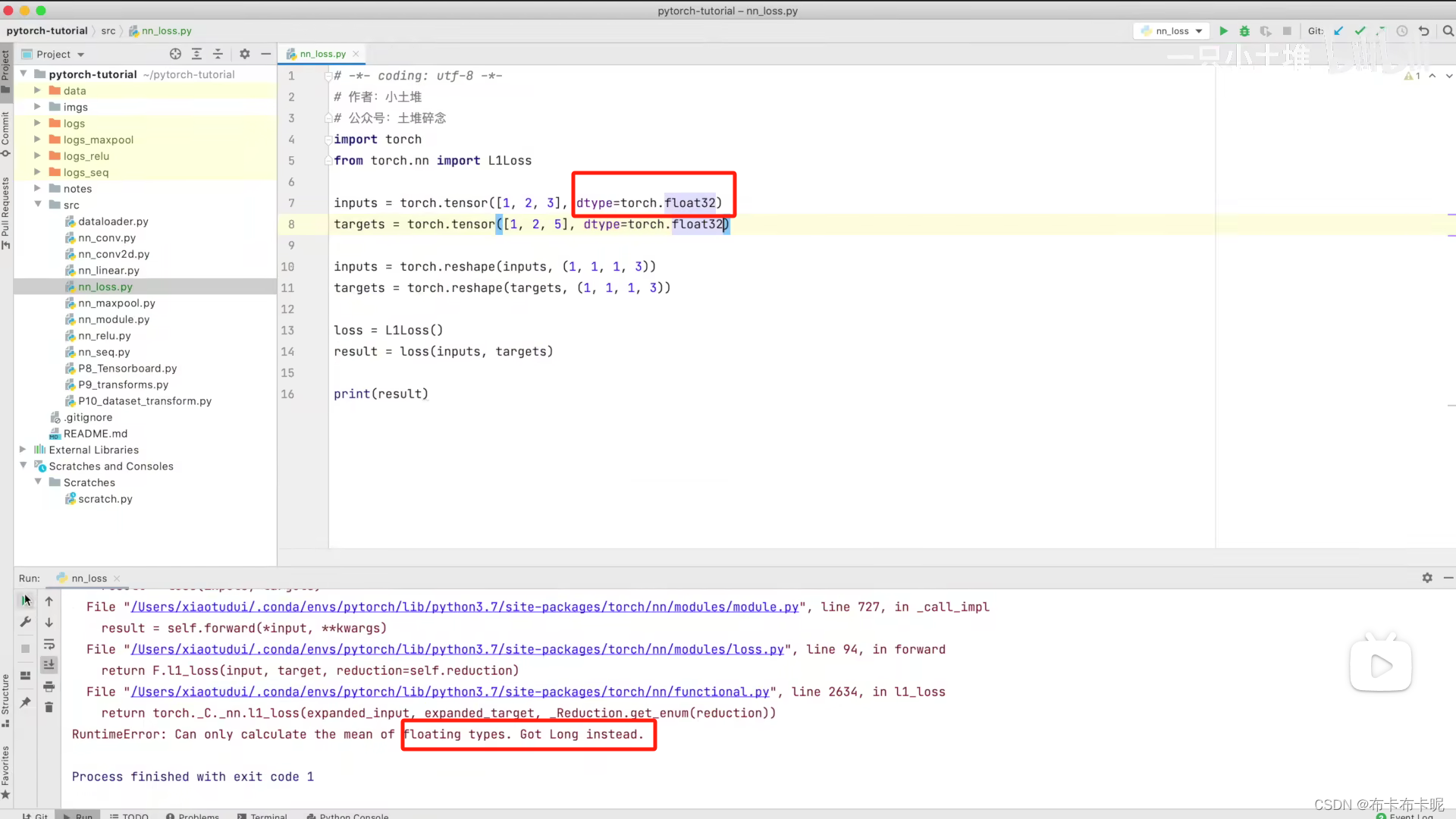
5、dtype=torch.float32
计算时可能会遇到如下错误,修改如下:
6、损失函数、反向传播、梯度、优化器之间的关系
**利用损失函数得出损失,再去反向传播计算出梯度,优化器会根据梯度更新神经网络中的参数(卷积神经网络就是更新卷积核参数)**具体代码见五 9 交叉熵损失函数
二、Dataset和Dataloader
1、Dataset和Dataloader区别
dataset是数据集
dataloader是用来将数据集传到神经网络中的。
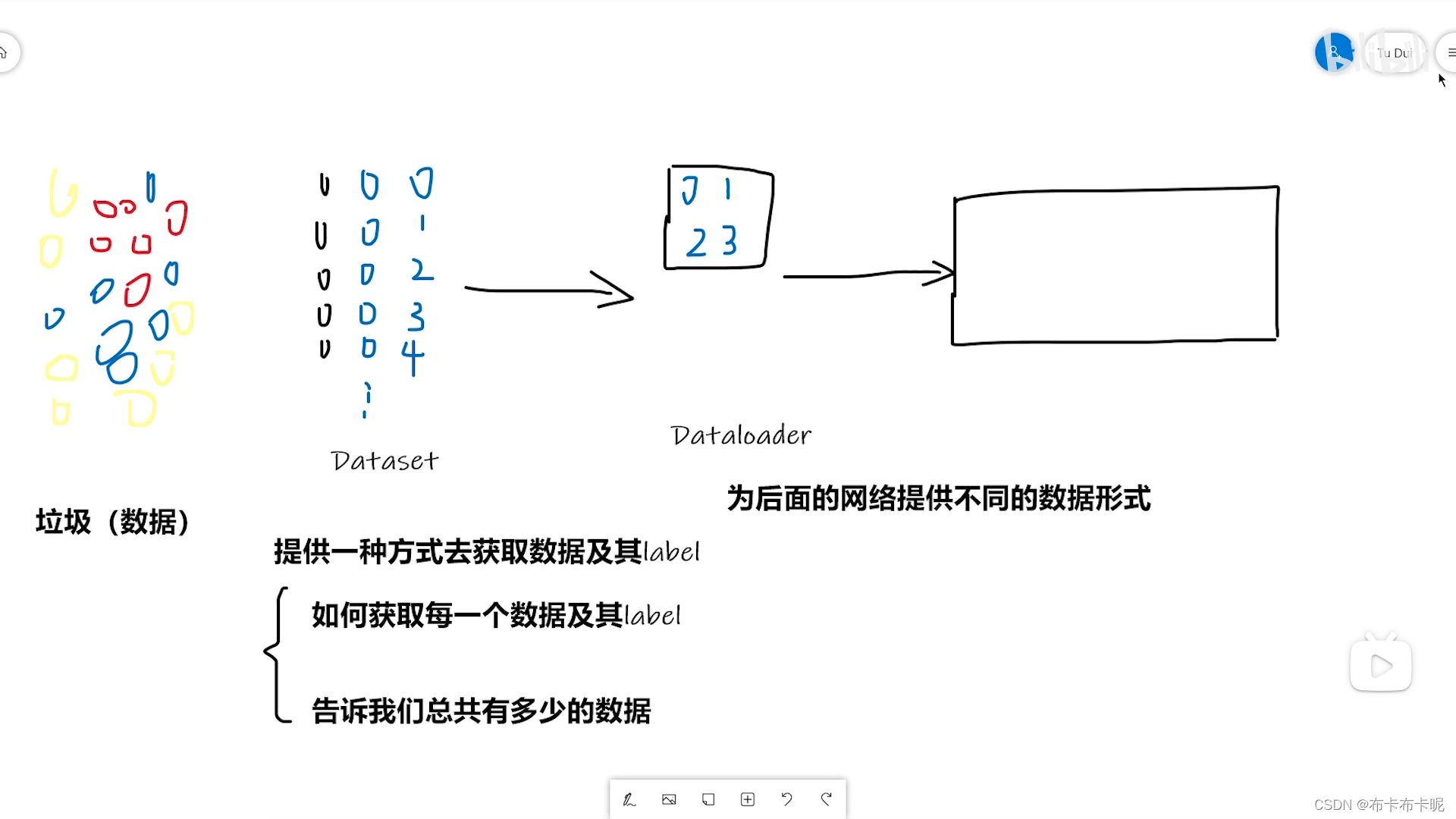
2、Dataset
1)返回格式
2)代码实战
from torch.utils.data import Dataset, DataLoader
import numpy as np
from PIL import Image
import os
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
from torchvision.utils import make_grid
writer = SummaryWriter("logs")
# 表示继承了Dataset类,重写他的__init__、__getitem__和__len__方法
class MyData(Dataset):
def __init__(self, root_dir, image_dir, label_dir, transform):
self.root_dir = root_dir
self.image_dir = image_dir
self.label_dir = label_dir
self.label_path = os.path.join(self.root_dir, self.label_dir)
self.image_path = os.path.join(self.root_dir, self.image_dir)
# listdir()是将dir目录中的内容变成list格式
self.image_list = os.listdir(self.image_path)
self.label_list = os.listdir(self.label_path)
self.transform = transform
# 因为label 和 Image文件名相同,进行一样的排序,可以保证取出的数据和label是一一对应的
self.image_list.sort()
self.label_list.sort()
def __getitem__(self, idx):
img_name = self.image_list[idx]
label_name = self.label_list[idx]
# os.path.join是因为Linux和Windows里文件目录的格式不一样,这个方法帮你自动拼接
img_item_path = os.path.join(self.root_dir, self.image_dir, img_name)
label_item_path = os.path.join(self.root_dir, self.label_dir, label_name)
img = Image.open(img_item_path)
with open(label_item_path, 'r') as f:
label = f.readline()
# img = np.array(img)
img = self.transform(img)
sample = {'img': img, 'label': label}
return sample
def __len__(self):
assert len(self.image_list) == len(self.label_list)
return len(self.image_list)
if __name__ == '__main__':
transform = transforms.Compose([transforms.Resize((256, 256)), transforms.ToTensor()])
root_dir = "dataset/train"
image_ants = "ants_image"
label_ants = "ants_label"
ants_dataset = MyData(root_dir, image_ants, label_ants, transform)
image_bees = "bees_image"
label_bees = "bees_label"
bees_dataset = MyData(root_dir, image_bees, label_bees, transform)
train_dataset = ants_dataset + bees_dataset
# transforms = transforms.Compose([transforms.Resize(256, 256)])
dataloader = DataLoader(train_dataset, batch_size=1, num_workers=2)
writer.add_image('error', train_dataset[119]['img'])
writer.close()
# for i, j in enumerate(dataloader):
# # imgs, labels = j
# print(type(j))
# print(i, j['img'].shape)
# # writer.add_image("train_data_b2", make_grid(j['img']), i)
#
# writer.close()
3、dataloader
1)官网地址
https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader
2)打包
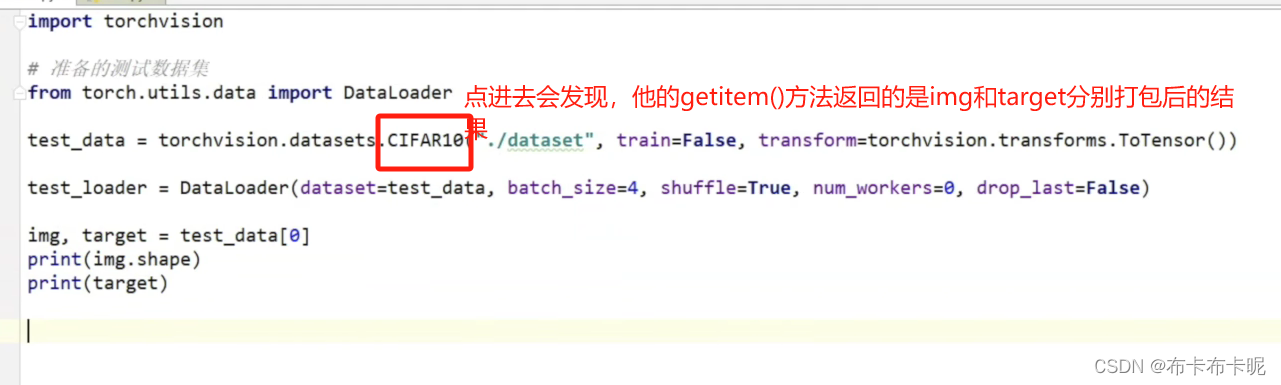
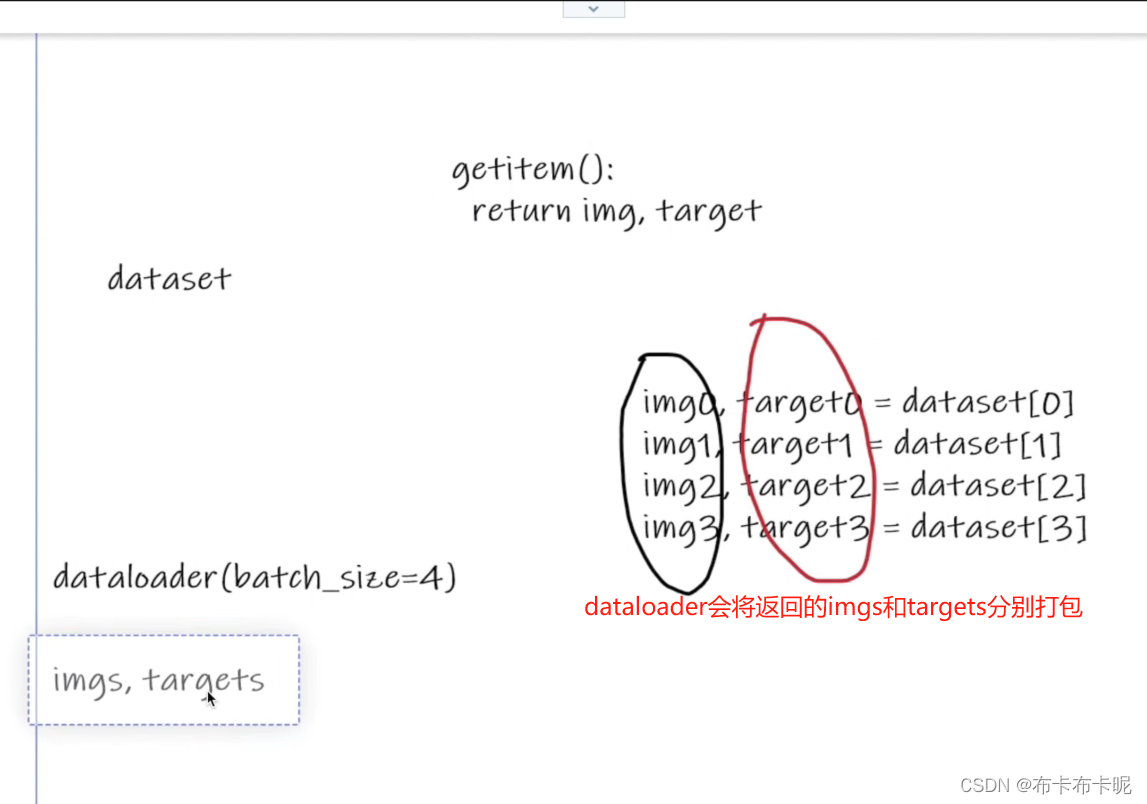
因为dataset的getitem()返回的是 img 和 target 。
dataloader会将一个batch中的所有img打包成imgs(target同理)
5)shuffle
洗牌是针对epoch的,而不是batch。
shuffle=True 在每个 epoch 前都会重新洗牌数据,每个 epoch 的数据顺序都是不同的。
4)代码实战
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 他的返回就是所有的数据集
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
# dataloader就是把一个batch中所有的img打包成imgs...
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
#每次的test_loader都是一个batch的数据
for data in test_loader:
imgs, targets = data
# 这是python格式化字符串的写法,将format后面的变量赋给大括号里
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
writer.close()
三、TensorBoard
1、TensorBoard的add_scalar()和add_image()
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
# SummaryWriter()形参表示将时间文件写入哪个文件夹
writer = SummaryWriter("logs")
image_path = "data/train/ants_image/6240329_72c01e663e.jpg"
# PIL读出来的图片格式是PIL的,tensorboard的add_image()方法不支持这种图片格式,具体支持什么点进方法中去看
img_PIL = Image.open(image_path)
# np读出来的虽然tensorboard的add_image()方法支持这种图片格式,但是存在通道不对应的问题,具体支持什么点进方法中去看
img_array = np.array(img_PIL)
# type()方法是当前变量的类型
print(type(img_array))
# 图片.shape()展现图片格式(CHW还是HWC...)
print(img_array.shape)
# 形参中的“1”表明是step1,因为在同一个title中,可以有多个step,通过滑动来展现,也说明了一个多个图片可以放在一个title下
writer.add_image("train", img_array, 1, dataformats='HWC')
# y = 2x
for i in range(100):
# tensorboard的add_scalar()方法第一个参数是title,如果多个scaler用了一个title,可能发生问题,所以每个scaler用一个title
writer.add_scalar("y=2x", 3*i, i)
# 最后要用tensorboard的close()关掉tensorboard
writer.close()
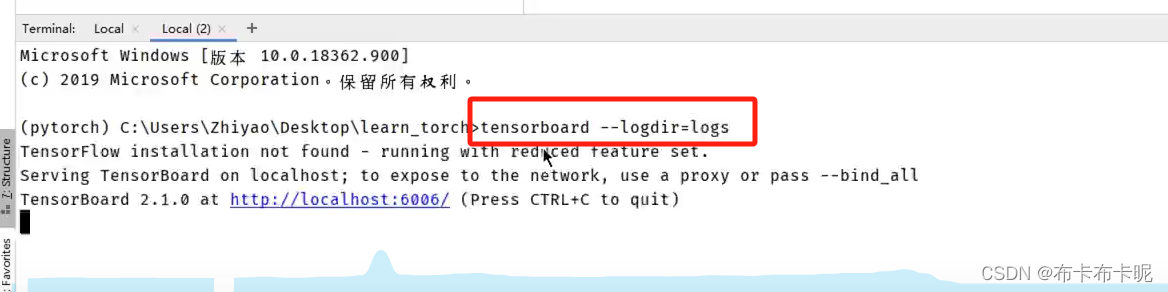
2、tensorboard使用命令
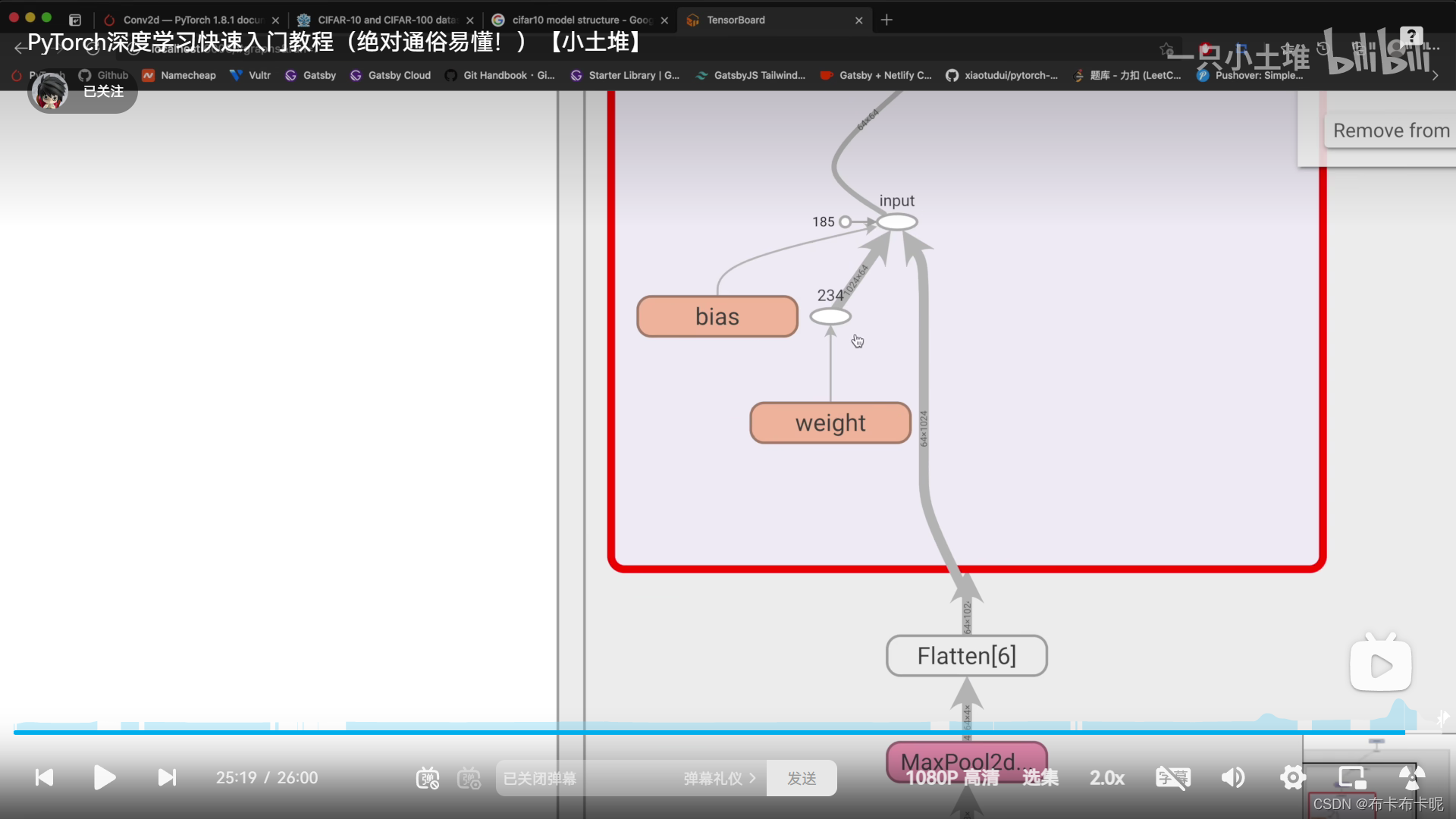
3、tensorboard中的add_graph
可以直观的展现模型结构,很优秀
四、Transform
在torchvision里。
主要是对图片进行变换。
Transform里有很多对图片进行变化的方法,将输入的图片变成想要的返回格式的图片。
1、Transform结构及用法
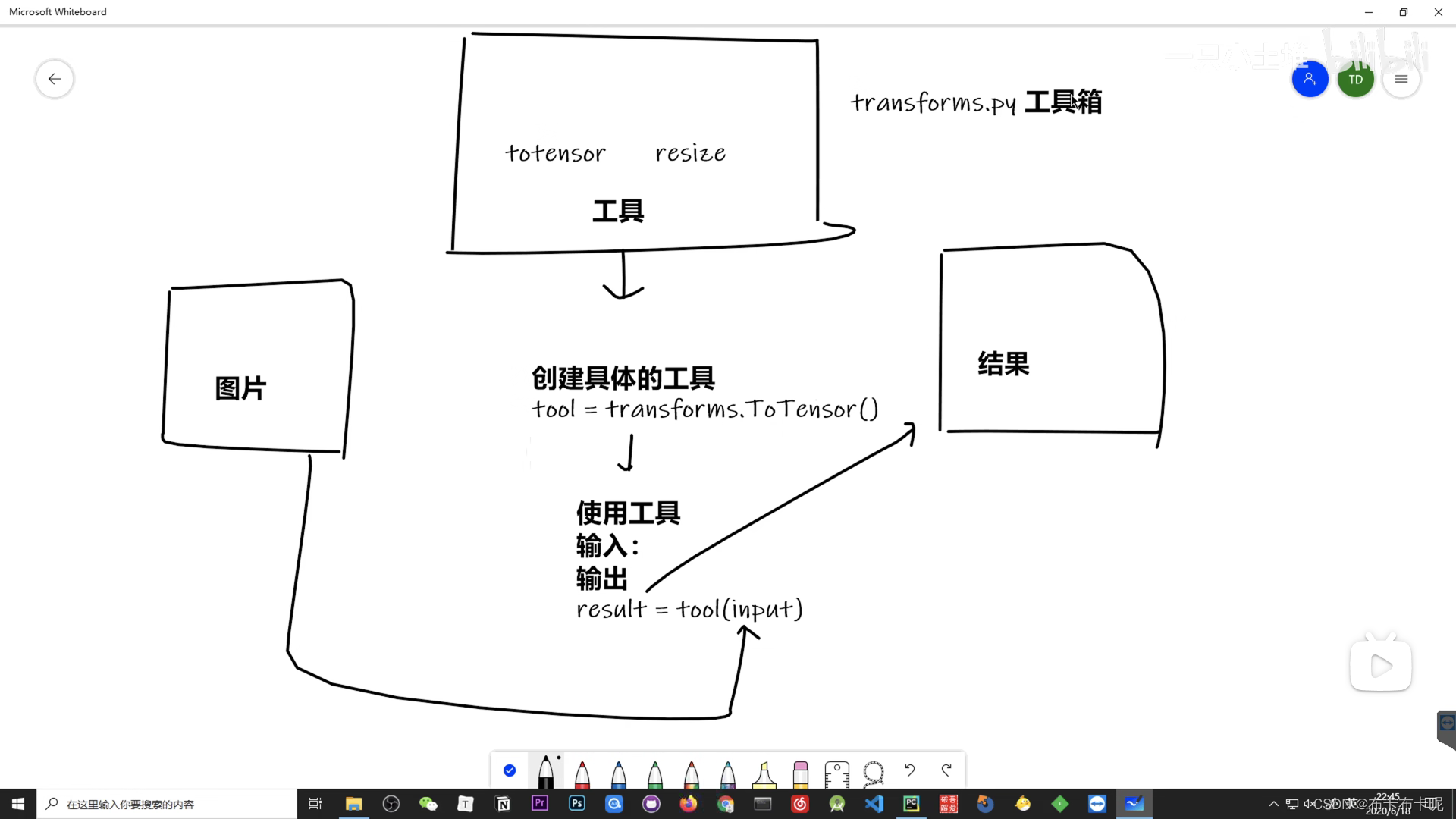
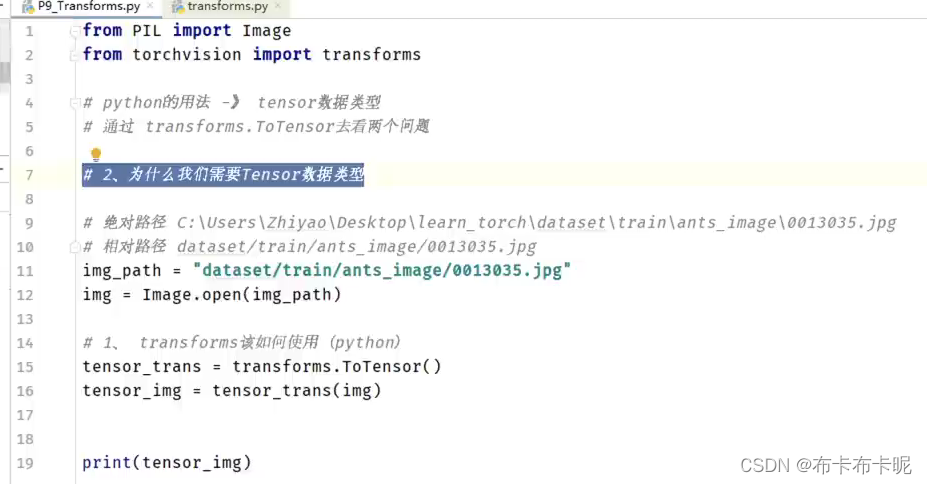
2、为什么需要tensor
tensor数据类型包装了反向神经网络所需要的参数

3、常见的transforms

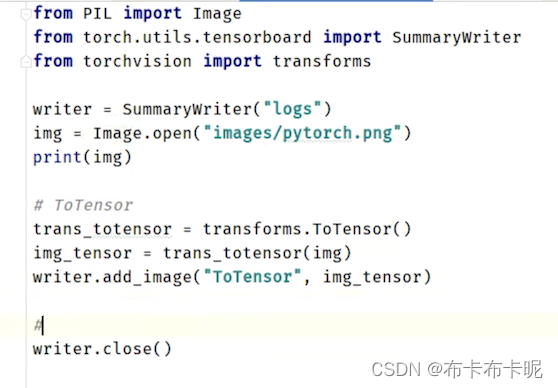
1)ToTensor
输入可以是PIL或者numpy的ndarray,转成tensor
2)Normalize
输入必须是tensor的

3)Resize
将PIL image变换大小,输出还是PIL的

4)Compose
不改变高和宽的比例,只进行等比缩放
其实就是多种变化的组合,按照写的方法列表去执行流程,就是执行一个方法链,更方便了。


5)RandomCrop
随机裁剪,输入PIL image 输出也是。
如果是一个int型数,裁剪的就是正方形
如果是一个序列(长,宽),裁剪的就是指定长宽的。

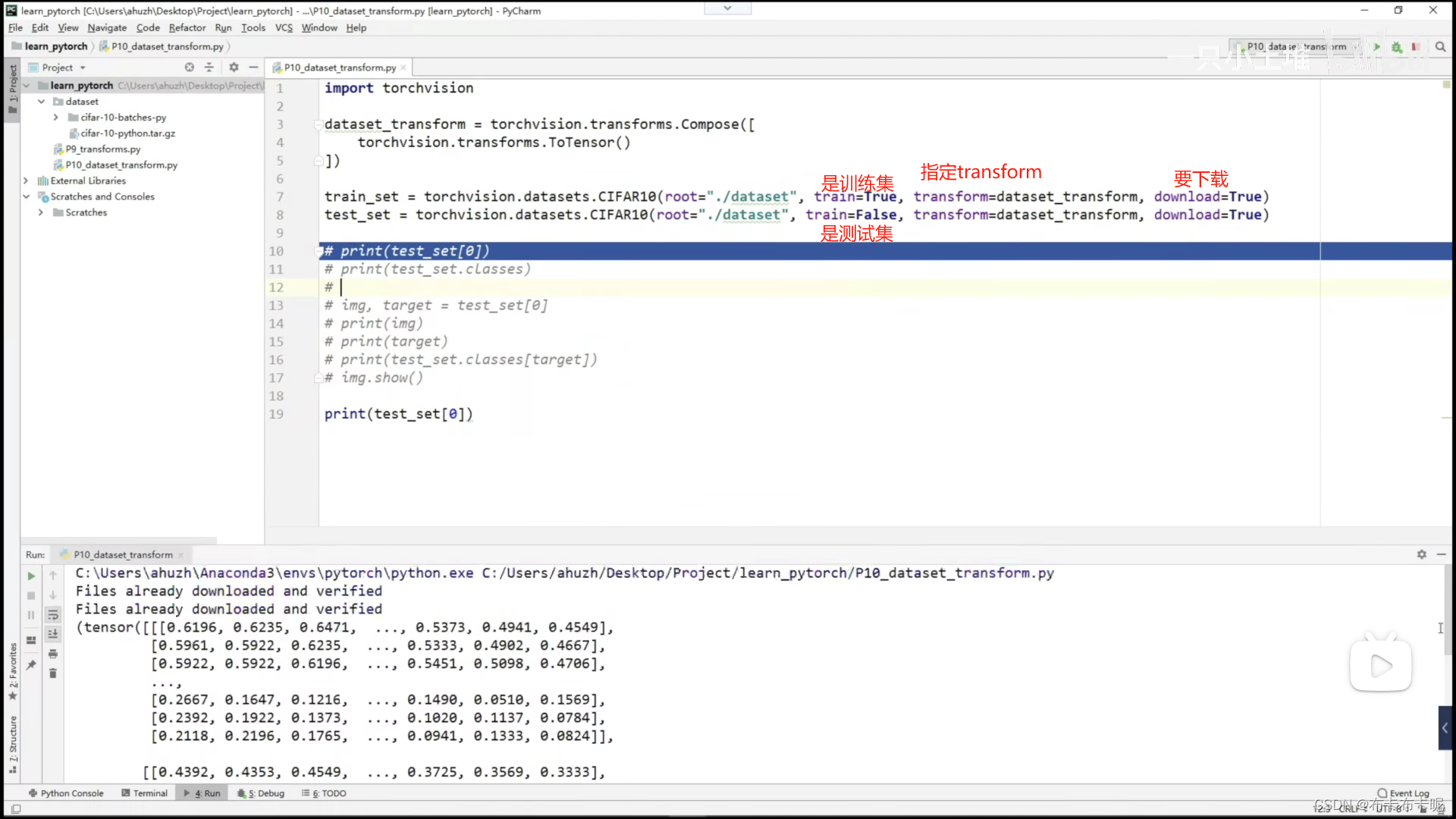
4、dataset和transforms联用
transforms更多的是用在dataset中。
指定数据集时就指明transform,表明将数据集中的每个数据都做这个transform转化。
建议download一直设置为True。
五、神经网络基本骨架 nn.module的使用
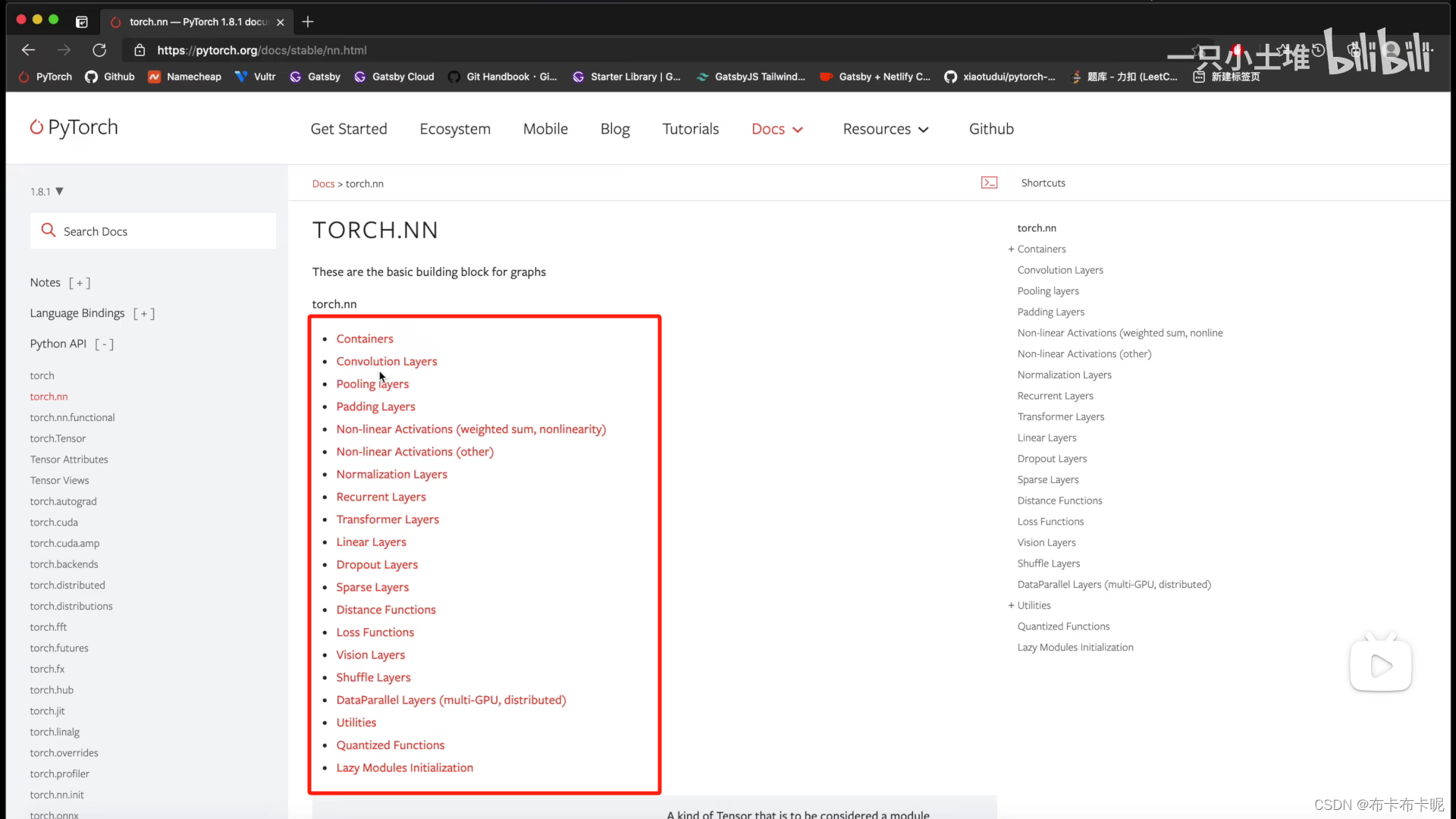
module就相当于父类,用的时候继承并重写方法即可。
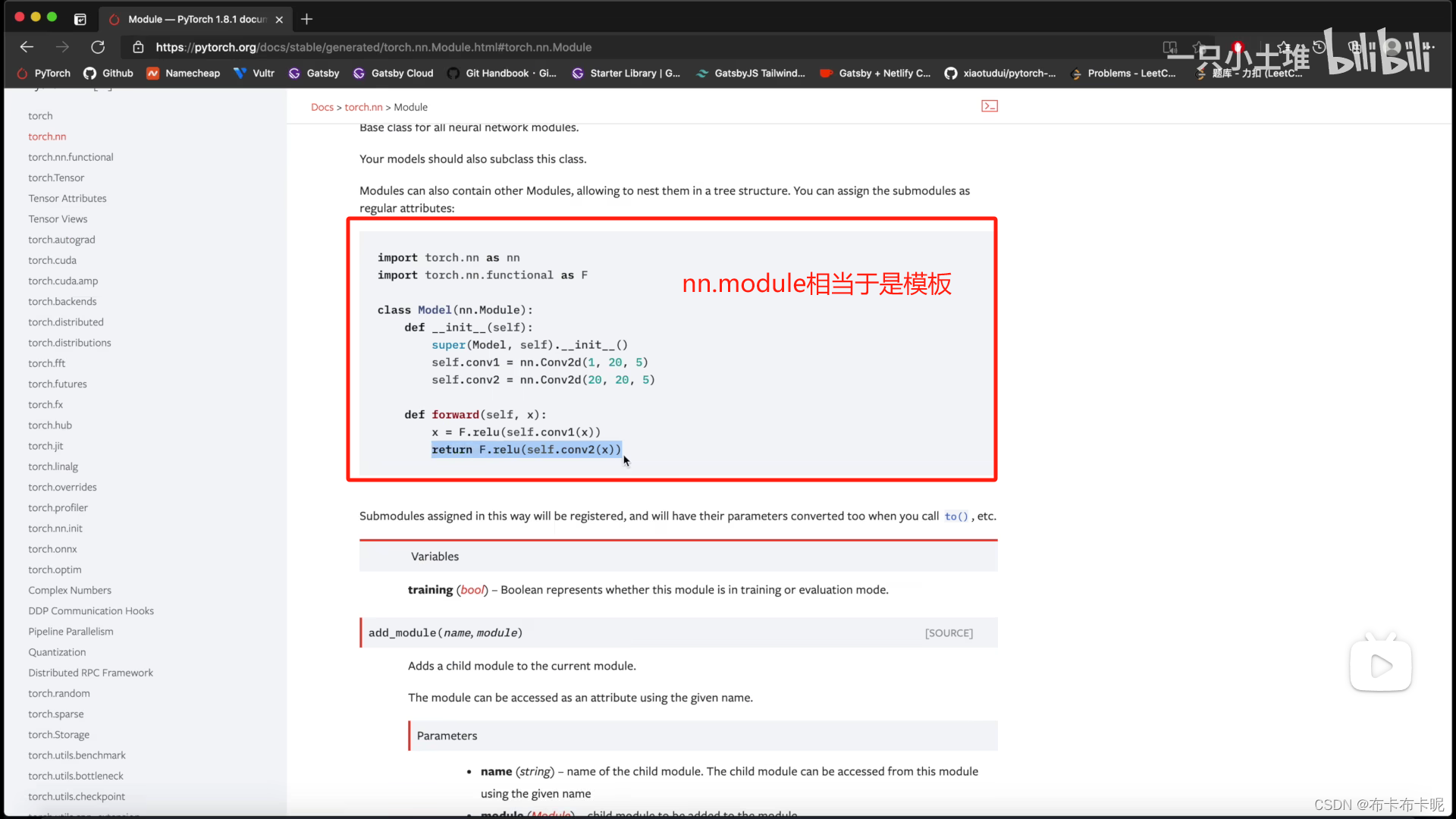
1、containers
1)containers中的Module
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):
output = input + 1
return output
tudui = Tudui()
x = torch.tensor(1.0)
output = tudui(x)
print(output)
2、torch.nn.functional.conv2d
conv2d是二维卷积
conv3d是三维卷积

1)代码实例
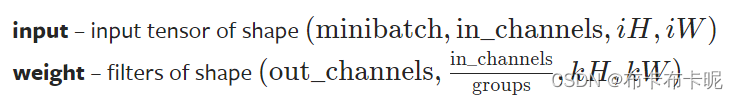
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
# conv2d的input是有要求的(如上图),所以要先进行reshape操作
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(input.shape)
print(kernel.shape)
output = F.conv2d(input, kernel, stride=1)
print(output)
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
# 默认padding=0,即不进行padding
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)
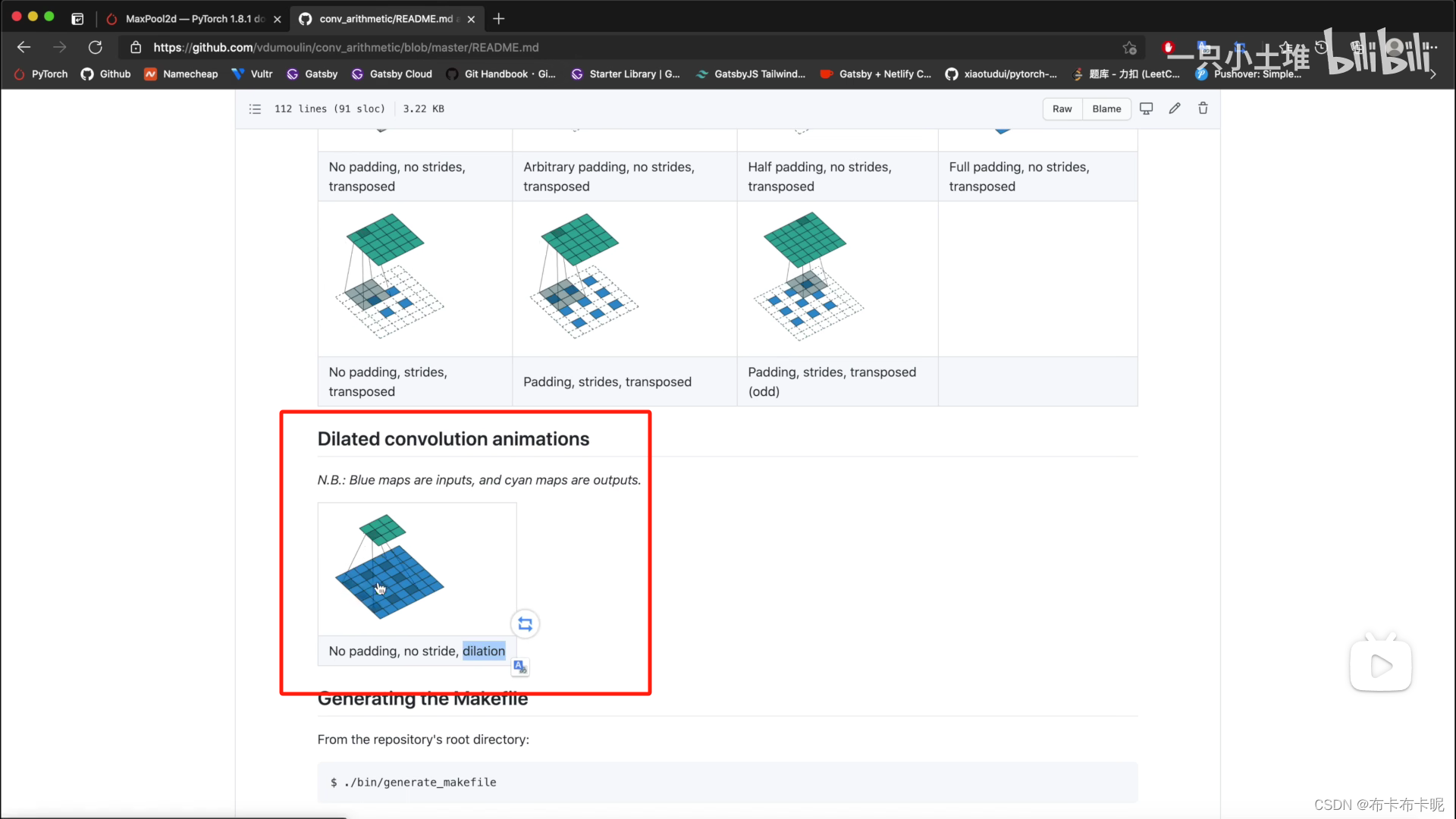
2)空洞卷积dilation
dilation
3、torch.nn.Conv2d

out_channel=2时,输入不要2个,根本原因是有了2个卷积核,分别对输入进行卷积操作之后,得到2个输出,就是2通道了。

import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
writer = SummaryWriter("../logs")
step = 0
for data in dataloader:
imgs, targets = data
# 因为“tudui”是个神经网络,他的形参是神经网络的输入,自然会走到forward里
output = tudui(imgs)
print(imgs.shape)
print(output.shape)
# torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# 因为要在tensorboard中展示,要求channel必须是3通道的,所以做了个reshape操作。torch.Size([64, 6, 30, 30]) -> [xxx, 3, 30, 30]
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step = step + 1
4、池化层
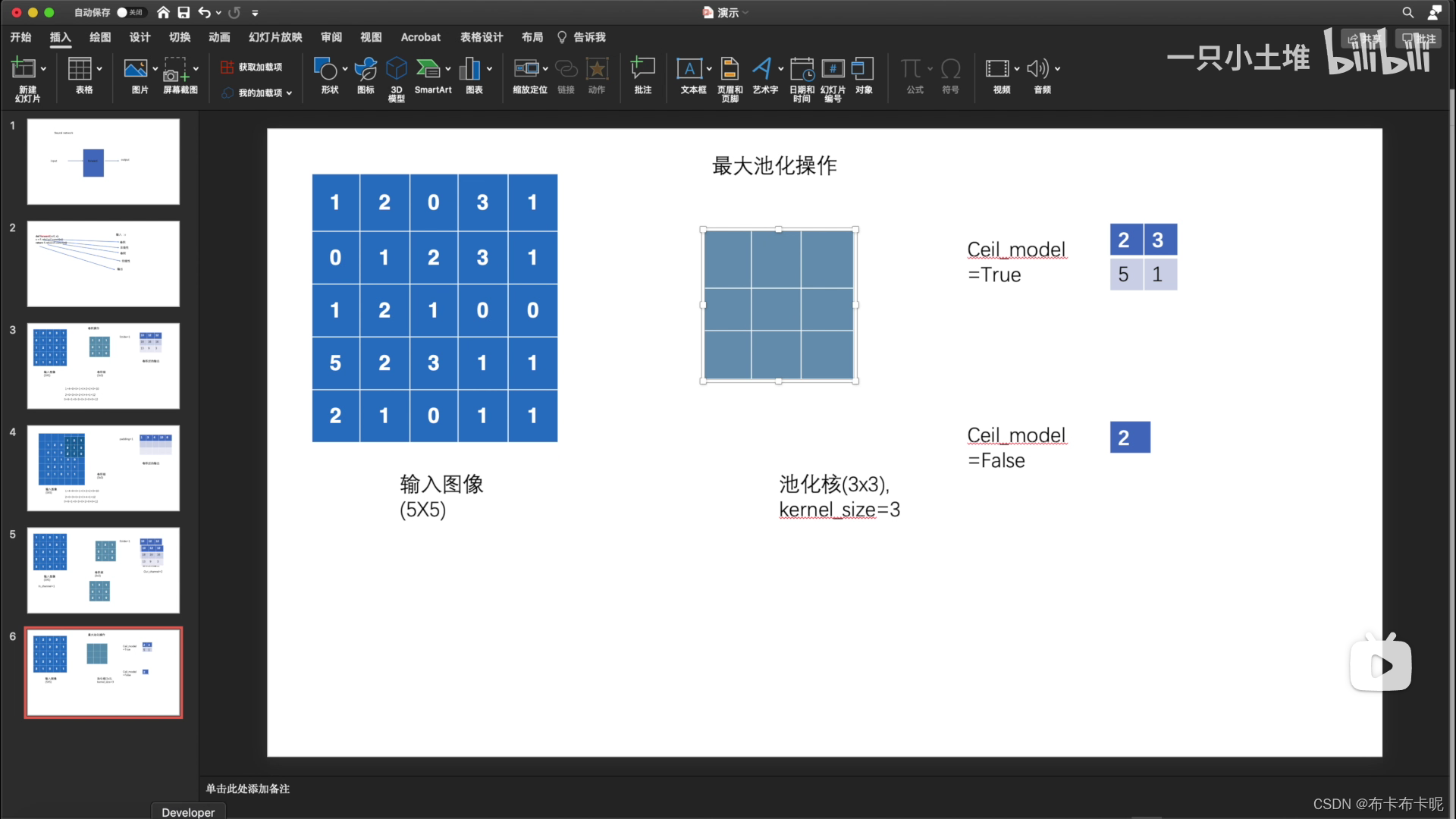
1)torch.nn.MaxPool2d
最大池化的目的:保留数据的特征,但是减少数据量
a、代码实战
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, input):
output = self.maxpool1(input)
return output
tudui = Tudui()
writer = SummaryWriter("../logs_maxpool")
step = 0
for data in dataloader:
imgs, targets = data
# 因为现在的每个data是一个batch里的数据,所以一个batch的数据在一个step中
writer.add_images("input", imgs, step)
output = tudui(imgs)
writer.add_images("output", output, step)
step = step + 1
writer.close()
5、非线性激活
非线性越多的话,才能训练出符合各种曲线或者特征的模型。
如果没什么非线性的话,模型的泛化能力就不好。
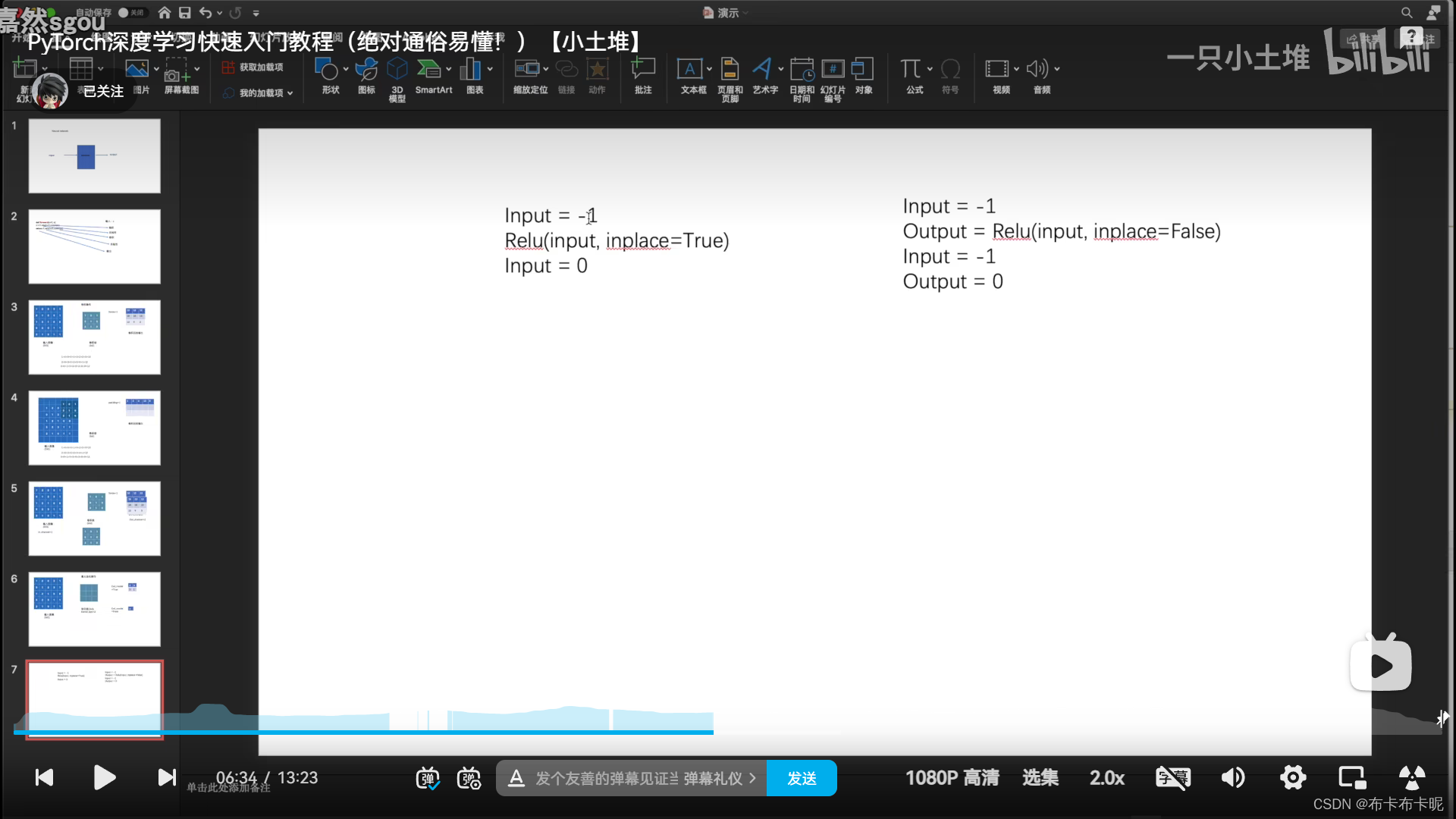
1)torch.nn.ReLU
a、参数解释
inplace=True:输出替代原来的值
inplace=False:保留原始数据(建议)
b、代码实战
import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)
dataset = torchvision.datasets.CIFAR10("../data", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
tudui = Tudui()
writer = SummaryWriter("../logs_relu")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, global_step=step)
output = tudui(imgs)
writer.add_images("output", output, step)
step += 1
writer.close()
6、Recurrent layer
用于文字任务
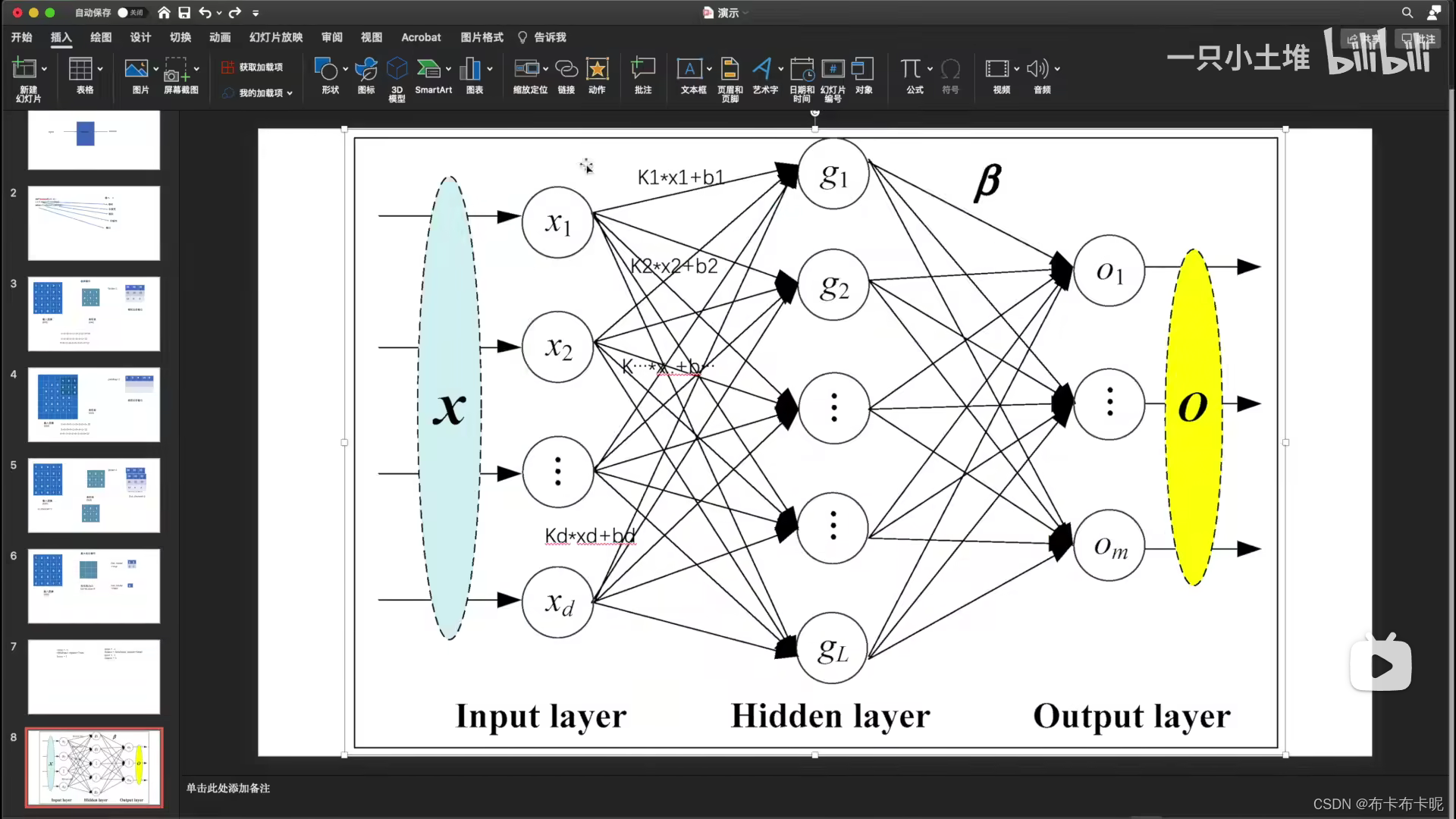
7、线性层
1)torch.nn.Linear
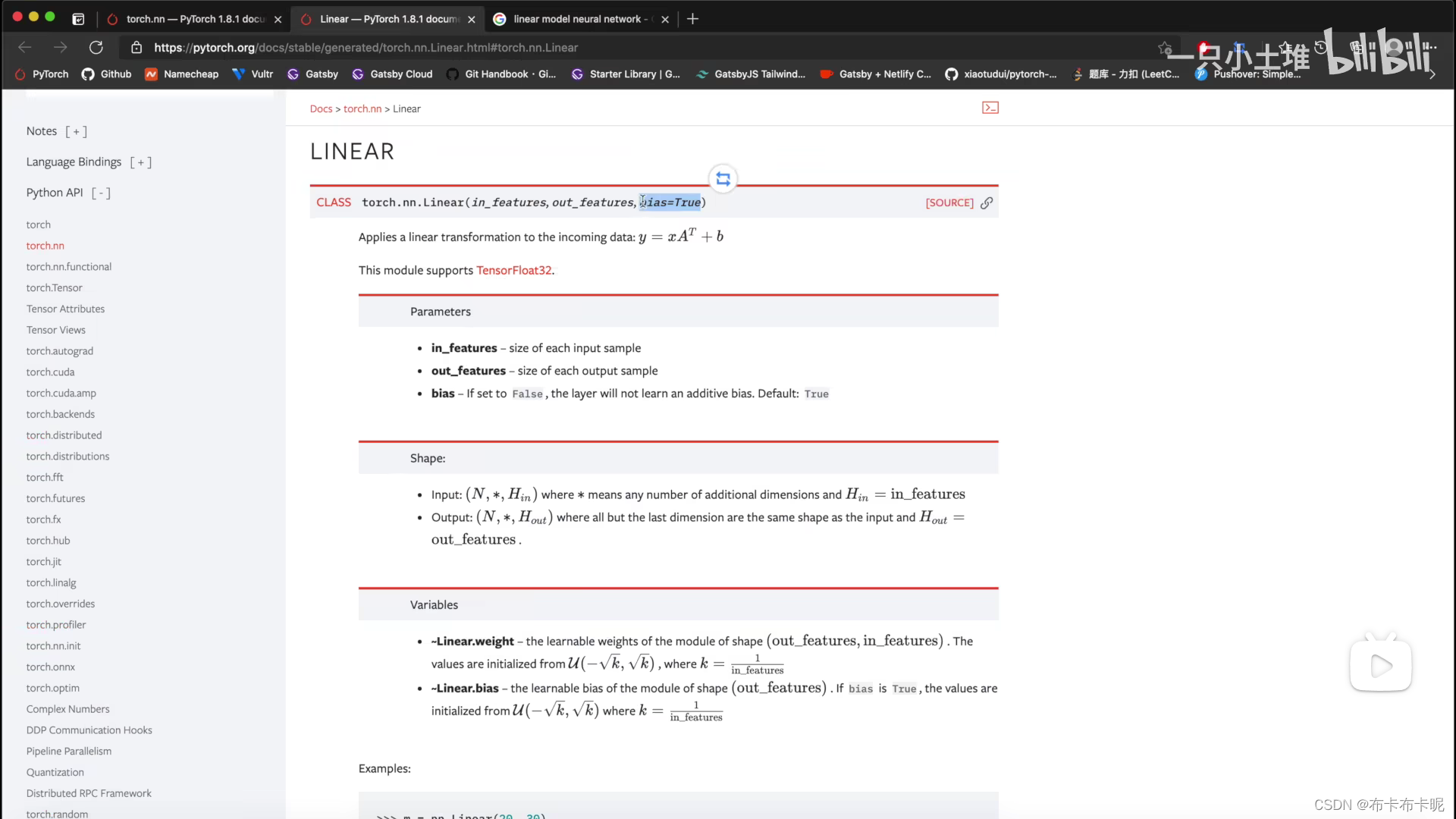
a、代码实战
# -*- coding: utf-8 -*-
# 作者:小土堆
# 公众号:土堆碎念
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
tudui = Tudui()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
# 将图片展平
output = torch.flatten(imgs)
print(output.shape)
output = tudui(output)
print(output.shape)
8、torch.nn.Sequential
相当于模型链
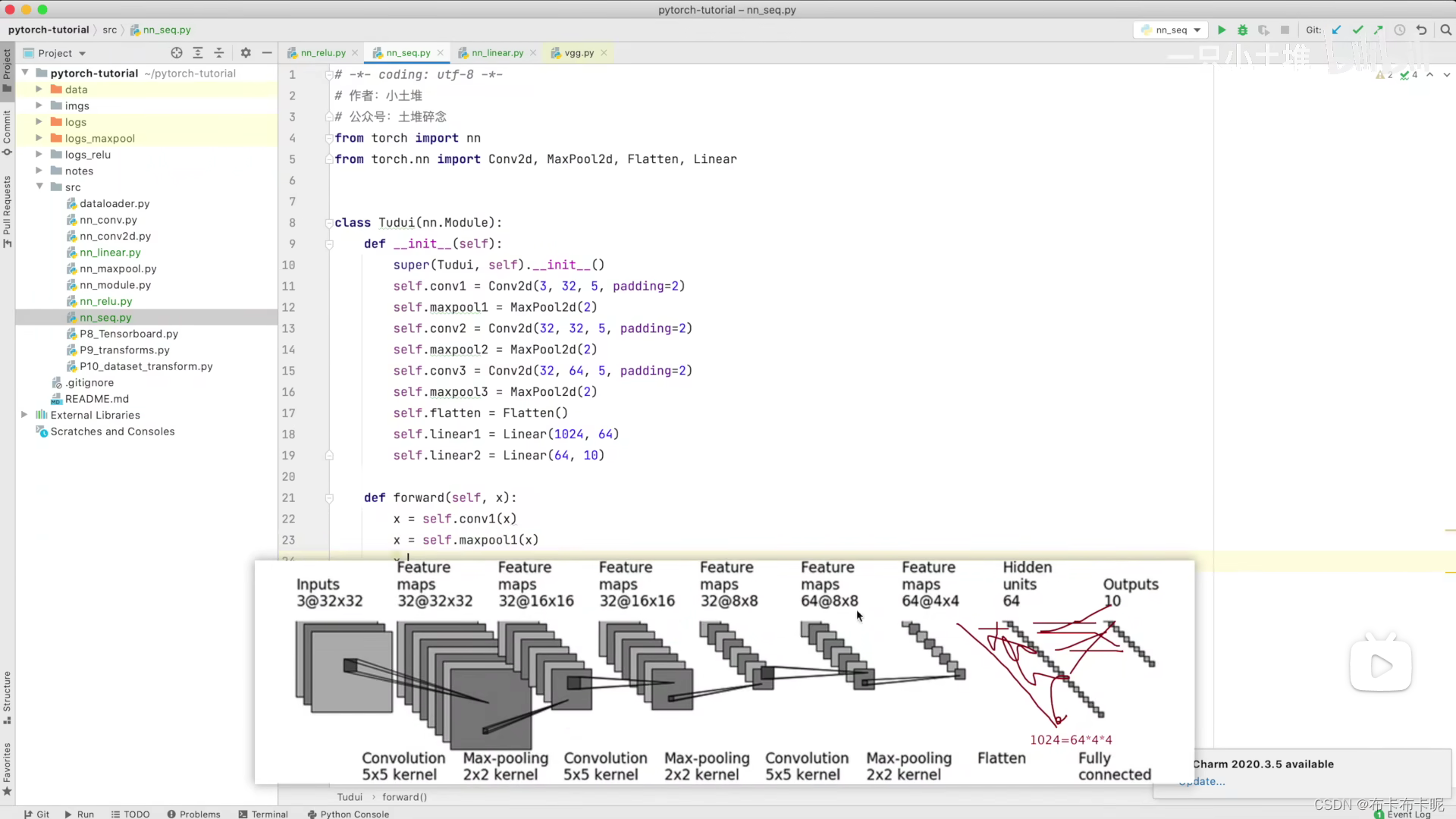
1)代码实战
# -*- coding: utf-8 -*-
# 作者:小土堆
# 公众号:土堆碎念
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
tudui = Tudui()
print(tudui)
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
writer = SummaryWriter("../logs_seq")
writer.add_graph(tudui, input)
writer.close()
9、loss_function
利用损失函数得出损失,再去反向传播计算出梯度,优化器会根据梯度更新神经网络中的参数(卷积神经网络就是更新卷积核参数)

1)交叉熵损失函数
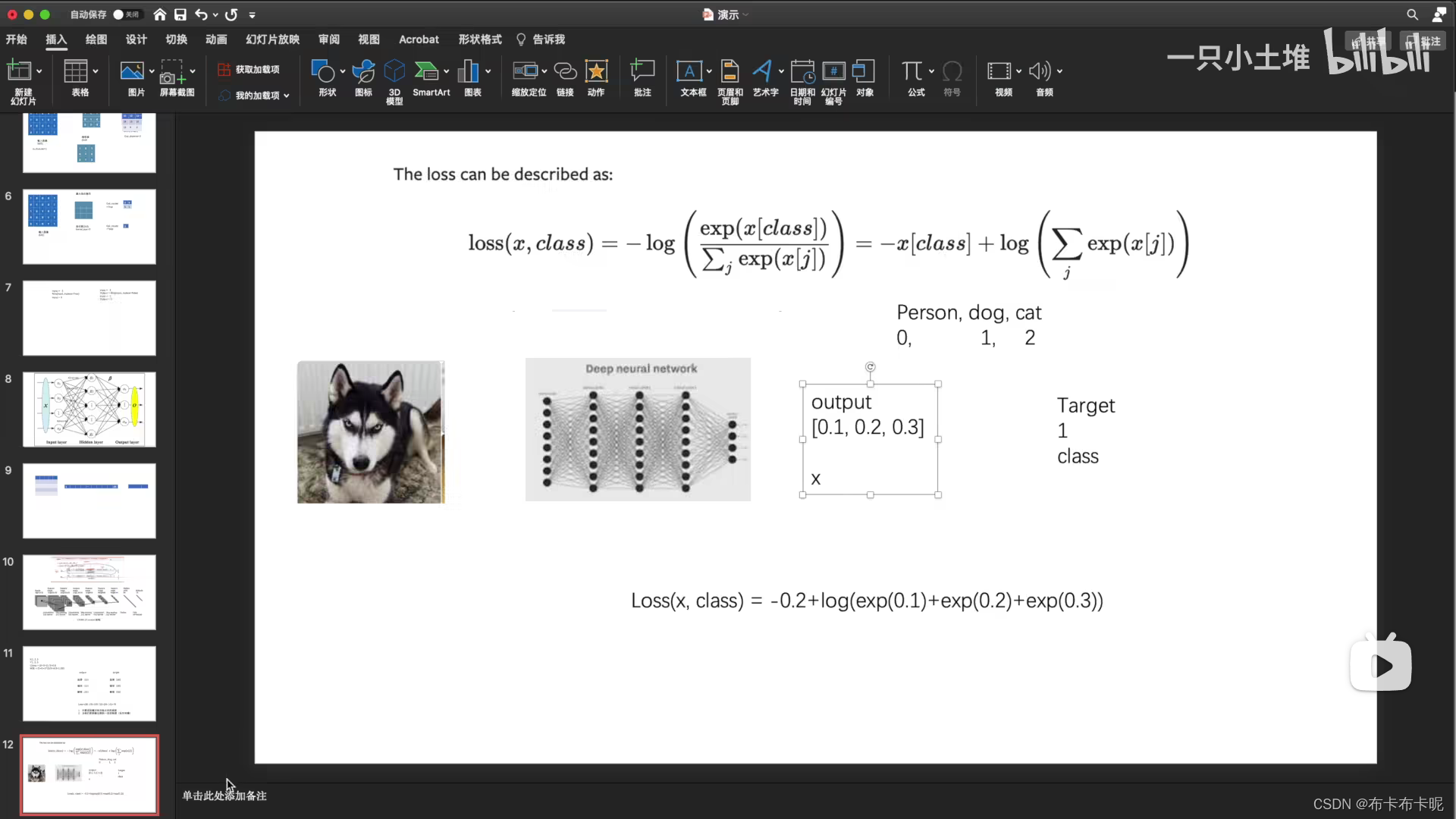
a、代码实战
# -*- coding: utf-8 -*-
# 作者:小土堆
# 公众号:土堆碎念
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets)
# 只有损失去反向传播了,才会得出梯度,为接下来优化器提供依据
result_loss.backward()
print("ok")
10、优化器
梯度一定要清零
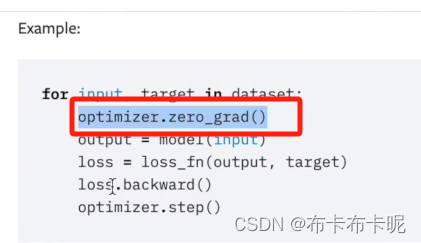
1)优化器用到神经网络中
import torch
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
scheduler = StepLR(optim, step_size=5, gamma=0.1)
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad()
result_loss.backward()
scheduler.step()
running_loss = running_loss + result_loss
print(running_loss)















 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









