







一、 图的存储方式有很多种,固定自己的一种方式,到时候只需做结构的转化代码即可
- 图存储结构模板
//图结构
public class Graph {
public HashMap<Integer, Node> nodes;
public HashSet<Edge> edges;
}
//节点结构
public class Node {
public int value;
public int in;
public int out;
public ArrayList<Edge> edges;
public ArrayList<Node> nexts;
public Node(int value) {
this.value = value;
int in=0;
int out=0;
edges=new ArrayList<>();
nexts=new ArrayList<>();
}
}
//边结构
public class Edge {
Node from;
Node to;
int weight;
public Edge(Node from, Node to, int weight) {
this.from = from;
this.to = to;
this.weight = weight;
}
}
- 应用场景
给的是数组结构,来表达图的存储形式
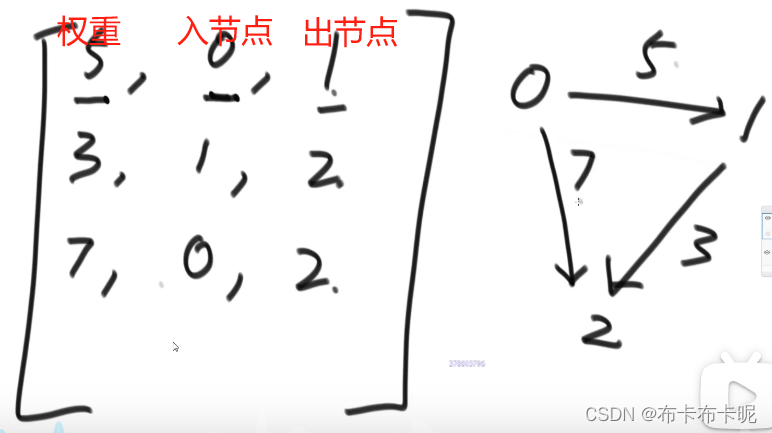
public class CreateGraph {
public Graph createGraph(int[][] matrix){
Graph graph=new Graph();
for(int i=0;i<matrix.length;i++){
int weight=matrix[i][0];
int from=matrix[i][1];
int to=matrix[i][2];
if(!graph.nodes.containsKey(from)){
graph.nodes.put(from,new Node(from));
}
if(!graph.nodes.containsKey(to)){
graph.nodes.put(to,new Node(to));
}
Node fromNode=graph.nodes.get(from);
Node toNode=graph.nodes.get(to);
Edge edge=new Edge(fromNode,toNode,weight);
graph.edges.add(edge);
fromNode.out++;
fromNode.edges.add(edge);
fromNode.nexts.add(toNode);
toNode.in++;
}
return graph;
}
}
二、图的遍历
- 图的宽度优先遍历
图的遍历和树的区别就是图可能有环 -> 去重 ->用set实现
public class WidthTraversal {
public void traversal(Node node){
if(node == node)
return;
Queue<Node> queue=new LinkedList<>();
Set<Node> set=new HashSet<>();
queue.add(node);
set.add(node);
while(!queue.isEmpty()){
Node cur=queue.poll();
// 题目要广搜后具体要做什么去替代sout
System.out.println(cur.value);
for (Node next : cur.nexts) {
if(!set.contains(next)){
queue.add(next);
set.add(next);
}
}
}
}
}
- 深度优先遍历
仿照宽度优先遍历的话,对于某个节点的所有next,只盯着一个邻居走,等这条路走结束之后,再看这个节点的其他next,为了实现这个效果,这个节点是要被保留在栈里的
public class DepthTraversal {
public void traversal(Node node ){
Stack<Node> stack=new Stack<>();
Set<Node> set=new HashSet<>();
stack.add(node);
set.add(node);
System.out.println(node.value);
while(!stack.empty()){
Node cur=stack.pop();
for (Node next : cur.nexts) {
if(!set.contains(next)){
System.out.println(next.value);
set.add(next);
stack.add(node);
stack.add(next);
break;
}
}
}
}
}
三、图的应用
1、拓扑结构
针对拓扑排序而言:
1)获得入度为0的节点 =》用队列实现
2)当前节点被删掉之后,其邻居节点的入度要修改 =》用map实现,将对应key的值减小
之前我会想着每个去遍历寻找修改之后入读为0的点,但是如果将入度存储下来,不就省去了很多麻烦
public class Topologicalsort {
public List<Node> sort(Graph graph){
Map<Node,Integer> map=new HashMap<>();
Queue<Node> zeroInQueue=new LinkedList<>();
for (Node node : graph.nodes.values()) {
map.put(node,node.in);
if(node.in == 0)
zeroInQueue.add(node);
}
List<Node> list=new ArrayList<>();
Node cur = zeroInQueue.poll();
while(!zeroInQueue.isEmpty()){
list.add(cur);
for (Node next : cur.nexts) {
// 这边容易出错,可能只讲next的in--了,但是map里next的value没有变化
map.put(next,map.get(next)-1);
if(map.get(next) == 0)
zeroInQueue.add(next);
}
}
return list;
}
}
2、最小生成树(K和P)
无论是哪种算法,都要判断加了边(点)之后有没有形成环,用集合机制实现,不在同一个集合里的可以添加,之后将两个分别所属的集合做合并操作(并查集实现是常数级别的)
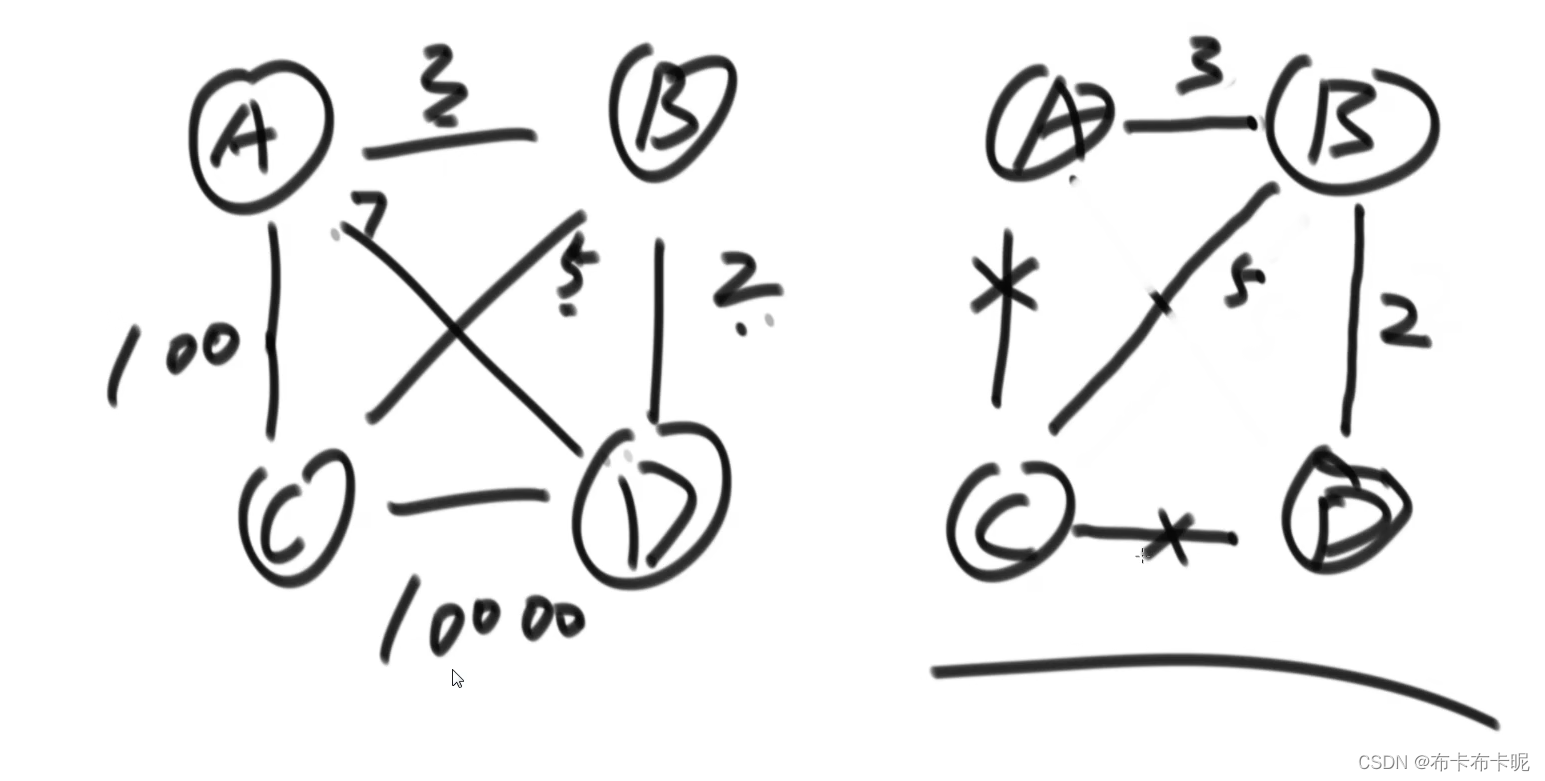
1)不直接用并查集实现判环、和并(模仿并查集写)
public class MyUnionFind {
Map<Node, List<Node>> setMap =new HashMap();
public MyUnionFind(List<Node> nodes){
for (Node node : nodes) {
ArrayList<Node> list=new ArrayList<>();
list.add(node);
setMap.put(node,list);
}
}
public boolean isSameSet(Node from,Node to){
return setMap.get(from) == setMap.get(to);
}
public void unionSet(Node from,Node to){
List<Node> fromSet = setMap.get(from);
List<Node> toSet = setMap.get(to);
for (Node node : toSet) {
fromSet.add(node);
setMap.put(node,fromSet);
}
}
}
2)边的值从小到大输出
用优先级队列PriorityQueue实现,形参为升序比较器(继承Comparator接口)
比较器中compare方法返回的是负数就是升序排序,正数就是降序排序
3)K算法(边)
public class K {
class EdgeComparator implements Comparator<Edge>{
@Override
public int compare(Edge o1, Edge o2) {
return o1.weight-o2.weight;
}
}
public Set<Edge> kruscal(Graph graph){
Set<Edge> set=new HashSet<>();
PriorityQueue<Edge> priorityQueue=new PriorityQueue<>(new EdgeComparator());
MyUnionFind myUnionFind=new MyUnionFind(new LinkedList<>(graph.nodes.values()));
for (Edge edge : graph.edges) {
priorityQueue.add(edge);
}
while (!priorityQueue.isEmpty()){
Edge cur=priorityQueue.poll();
Node from = cur.from;
Node to = cur.to;
if(!myUnionFind.isSameSet(from,to)){
set.add(cur);
myUnionFind.unionSet(from,to);
}
}
return set;
}
}
4)P算法
P算法每次加进来的是个节点,只需对每个加进来的节点和以前的集合来判环,不会像K算法会出现加边导致两个集合连接的要处理两个集合是否可能组成环的事,所有P算法只需要set处理
public class P {
class EdgeComparator implements Comparator<Edge> {
@Override
public int compare(Edge o1, Edge o2) {
return o1.weight-o2.weight;
}
}
public Set<Node> prim(Graph graph){
Set<Node> result=new HashSet<>();
// Set<Node> set=new HashSet<>();
PriorityQueue<Edge> priorityQueue=new PriorityQueue<>(new EdgeComparator());
for (Node node : graph.nodes.values()) {
if(!result.contains(node)){
result.add(node);
for (Edge edge : node.edges) {
priorityQueue.add(edge);
}
while (!priorityQueue.isEmpty()){
Edge edge = priorityQueue.poll();
if(!result.contains(edge.to)){
result.add(edge.to);
for (Edge edge1 : edge.to.edges) {
priorityQueue.add(edge1);
}
}
}
}
}
return result;
}
}
- 最短距离
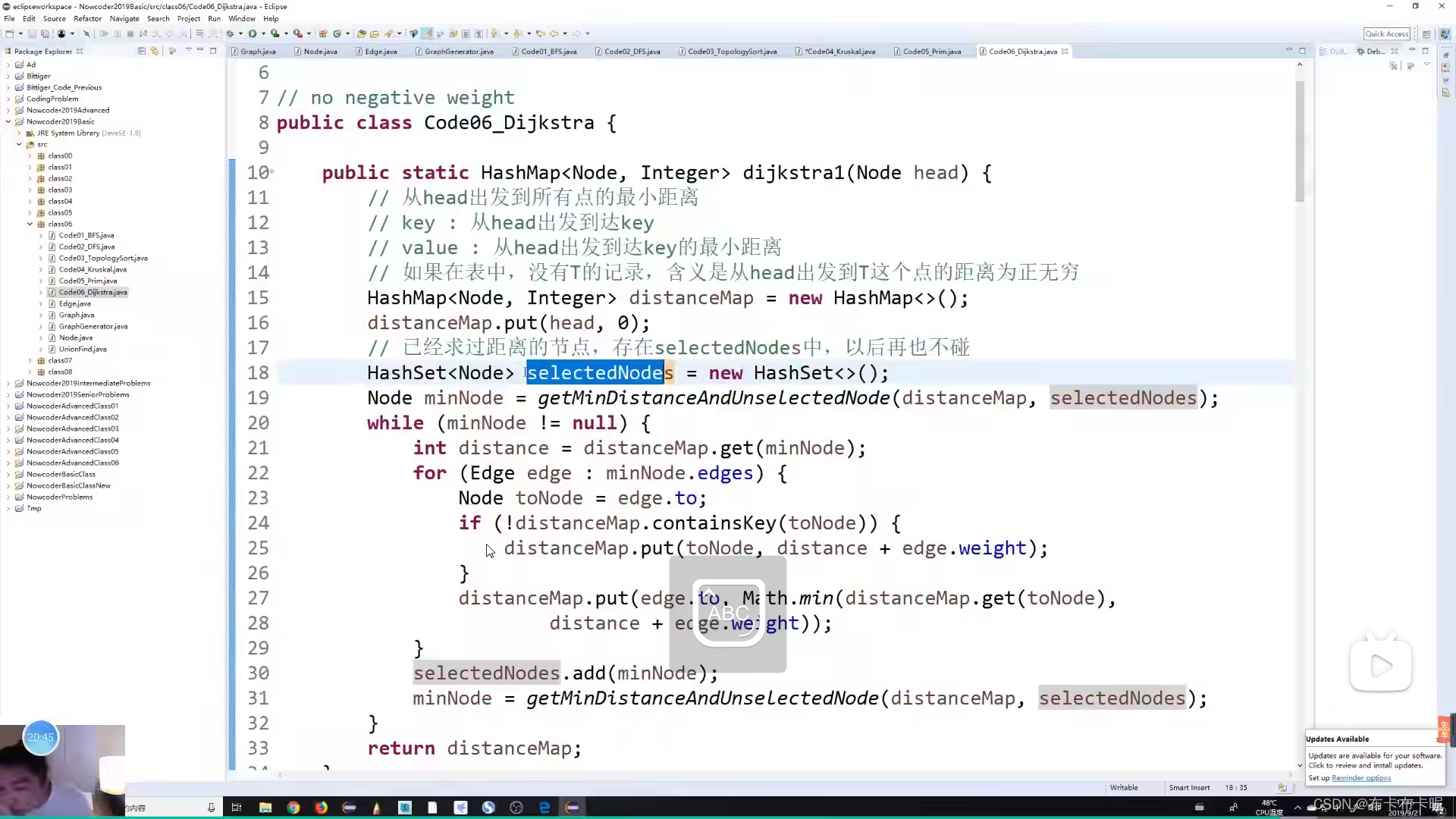
1)Dijkstra
给定一个点,要求这个点到其余所有点的最短距离
public class Dijkstra {
public HashMap<Node,Integer> dijkstra(Node head){
HashMap<Node,Integer> distanceMap=new HashMap<>();
HashSet<Node> selectedNodes=new HashSet<>();
distanceMap.put(head,0);
Node curNode = getMinDistanceAndUnselectedNode(distanceMap, selectedNodes);
while(curNode != null){
int curDistance=distanceMap.get(curNode);
for (Edge edge : curNode.edges) {
Node to = edge.to;
if(!distanceMap.containsKey(to)){
distanceMap.put(to,curDistance+edge.weight);
}
distanceMap.put(to,Math.min(curDistance+edge.weight,distanceMap.get(to)));
}
selectedNodes.add(curNode);
curNode=getMinDistanceAndUnselectedNode(distanceMap,selectedNodes);
}
return distanceMap;
}
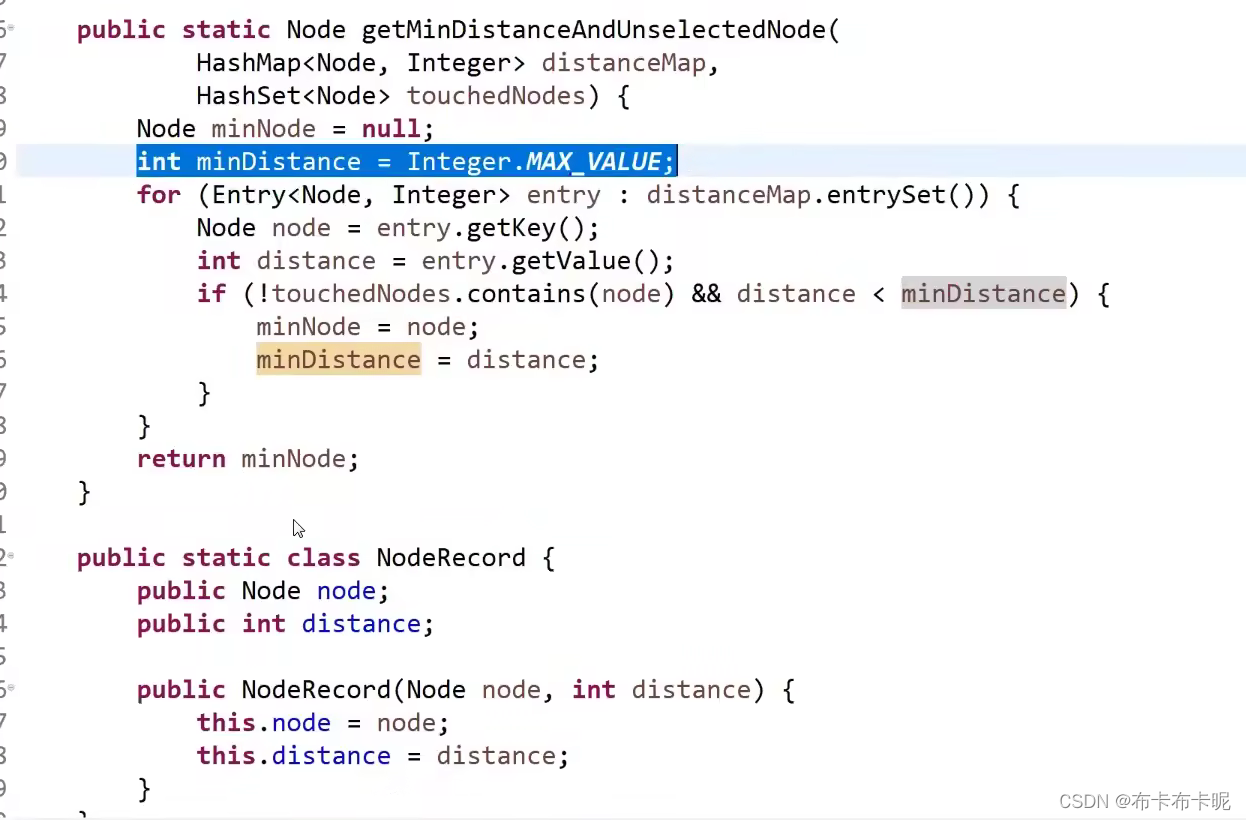
public Node getMinDistanceAndUnselectedNode(HashMap<Node,Integer> distanceMap,HashSet<Node> selectedNodes){
int minDistance=Integer.MIN_VALUE;
Node node=null;
for (Map.Entry<Node, Integer> entry : distanceMap.entrySet()) {
if(!selectedNodes.contains(entry.getKey()) && entry.getValue()<minDistance){
minDistance=entry.getValue();
node=entry.getKey();
}
}
return node;
}
}














 739
739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









