







第二章节目录
一、名词基本概念
以下是对Prompt等概念的解释以及研究。
1.Prompt
Prompt 最初是 NLP(自然语言处理)研究者为下游任务设计出来的一种任务专属的输入模板,类似于一种任务(例如:分类,聚类等)会对应一种 Prompt。在 ChatGPT 推出并获得大量应用之后,Prompt 开始被推广为给大模型的所有输入。即,我们每一次访问大模型的输入为一个 Prompt,而大模型给我们的返回结果则被称为 Completion。
简单来说,一次提问为此次prompt,而大模型的回答为此次的completion
2.Temperature
LLM 生成是具有随机性的,在模型的顶层通过选取不同预测概率的预测结果来生成最后的结果。我们一般可以通过控制 Temperature 参数来控制 LLM 生成结果的随机性与创造性。
Temperature 一般取值在 0~1 之间,当取值较低接近0时,预测的随机性会较低,产生更保守、可预测的文本,不太可能生成意想不到或不寻常的词。当取值较高接近1时,预测的随机性会较高,所有词被选择的可能性更大,会产生更有创意、多样化的文本,更有可能生成不寻常或意想不到的词。
也就是说,你对Temperature的参数设置的0或1,决定你自己想要的回答是保守式的有固定答案的,还是后者为开放式的能给读者以启示的。应用的场景不同决定了,你的答案不同。(见人说人话,见gui说gui话)
3.System Prompt
System Prompt 是随着 ChatGPT API 开放并逐步得到大量使用的一个新兴概念,事实上,它并不在大模型本身训练中得到体现,而是大模型服务方为提升用户体验所设置的一种策略。
具体来说,在使用 ChatGPT API 时,你可以设置两种 Prompt:一种是 System Prompt,该种 Prompt 内容会在整个会话过程中持久地影响模型的回复,且相比于普通 Prompt 具有更高的重要性;另一种是 User Prompt,这更偏向于咱们平时的 Prompt,即需要模型做出回复的输入。
我们一般设置 System Prompt 来对模型进行一些初始化设定。
也就是立人设
二、调用大模型
教程中有五种大模型的调用,但是我个人需要去学习星火的,因此我这里就暂时先说明星火的调用过程。(以后有时间,有能力了,也会把其余的捡起来的。)
1.调用讯飞星火
目前,讯飞星火大模型 API 已进入 β 测试阶段,每一个讯飞账户都可以申请若干 token 的试用。但是,相对于文心与 GPT 几乎完全一致的 API 调用方式,星火 API 需要使用 WebSocket 来进行调用,对企业友好,但对初学者、新手开发者来说调用难度较大。
1.1 申请调用权限
步骤1:进入讯飞星火官网官网地址
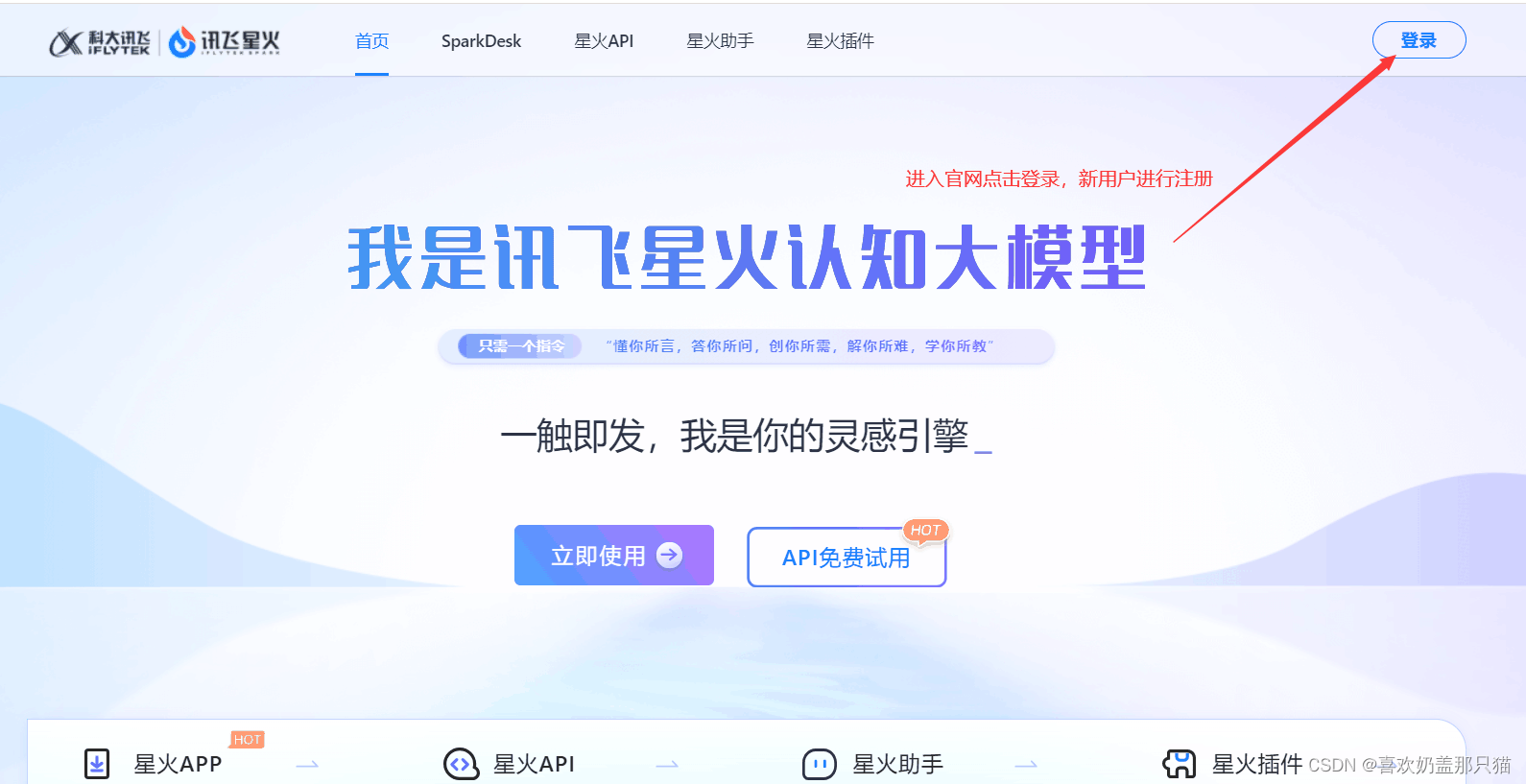 步骤2:登录注册成功后
步骤2:登录注册成功后
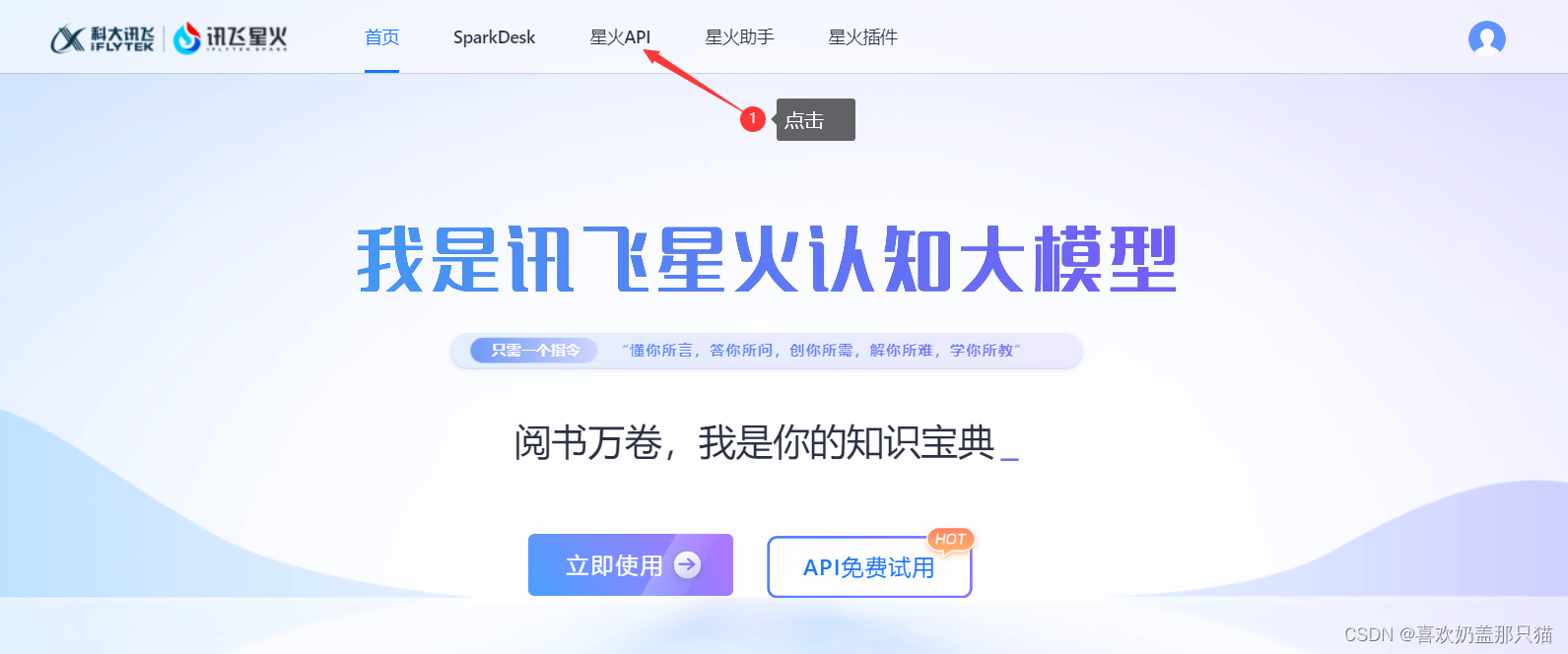 步骤3:点击免费试用
步骤3:点击免费试用
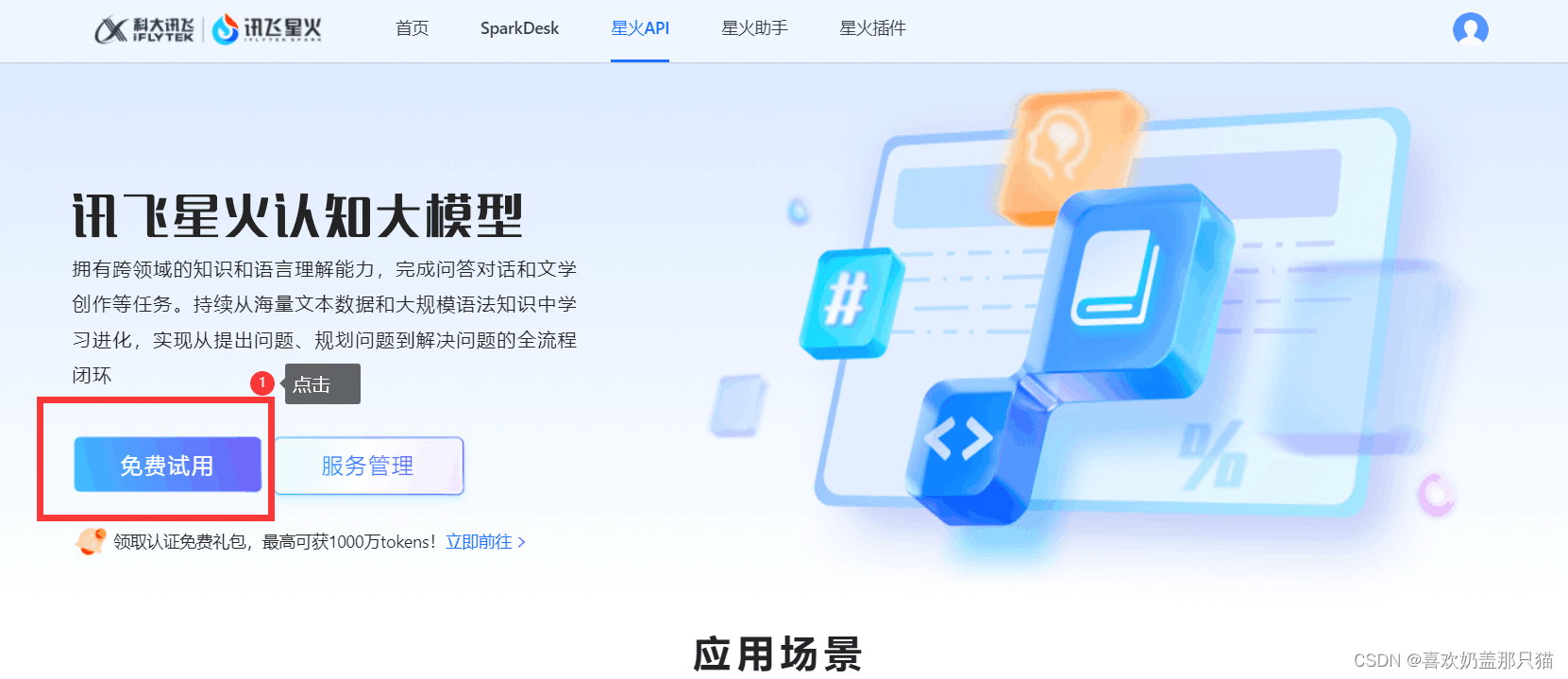 步骤4:进入产品价格页面,点击个人的免费试用
步骤4:进入产品价格页面,点击个人的免费试用
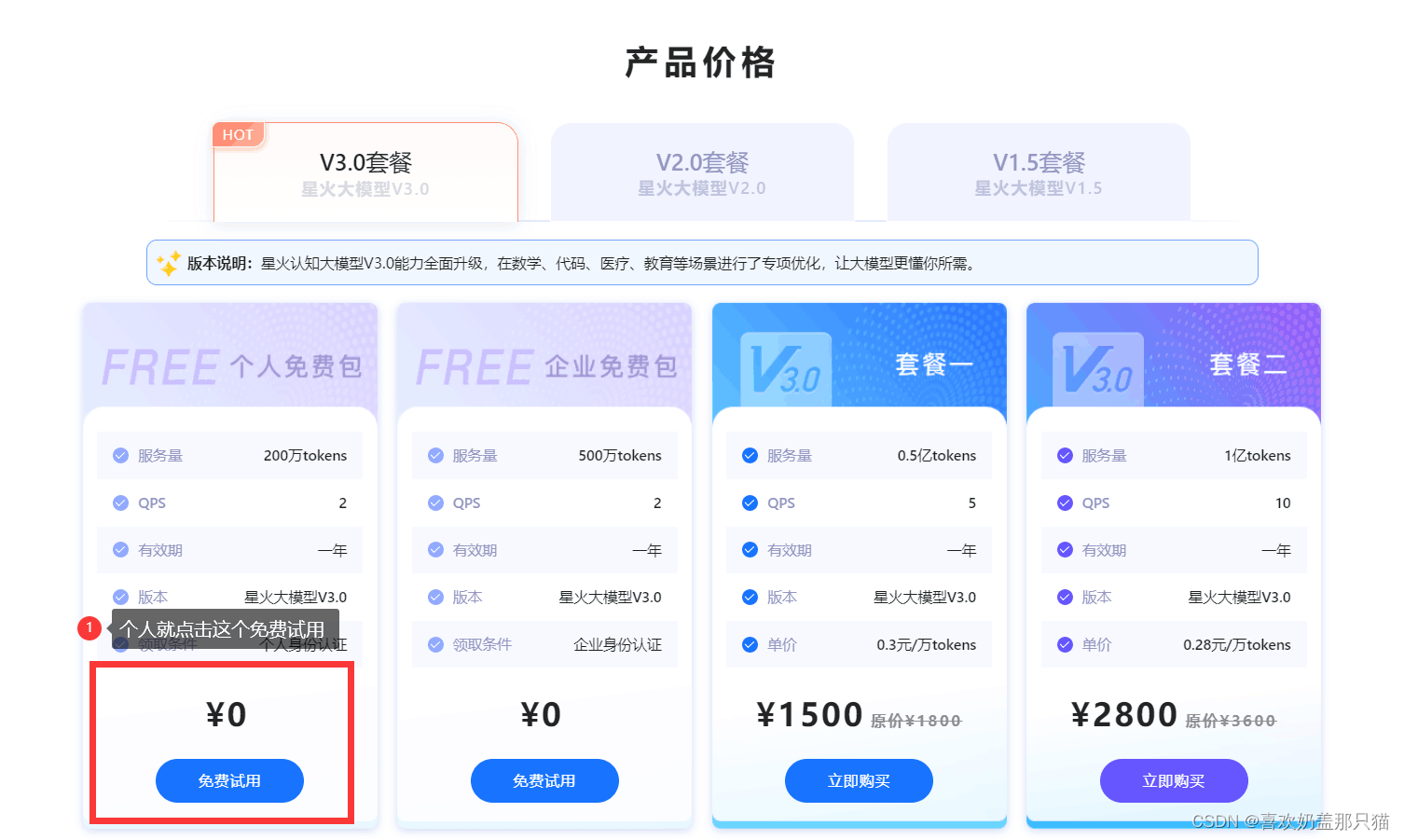 步骤5:滑动,进入身份实名页面
步骤5:滑动,进入身份实名页面
提交后,会显示个人实名认证审核中
 可能需要几个工作日,因此要使用的伙伴,请你提前申请认证
可能需要几个工作日,因此要使用的伙伴,请你提前申请认证
步骤6:再次进入产品价格界面,点击免费试用
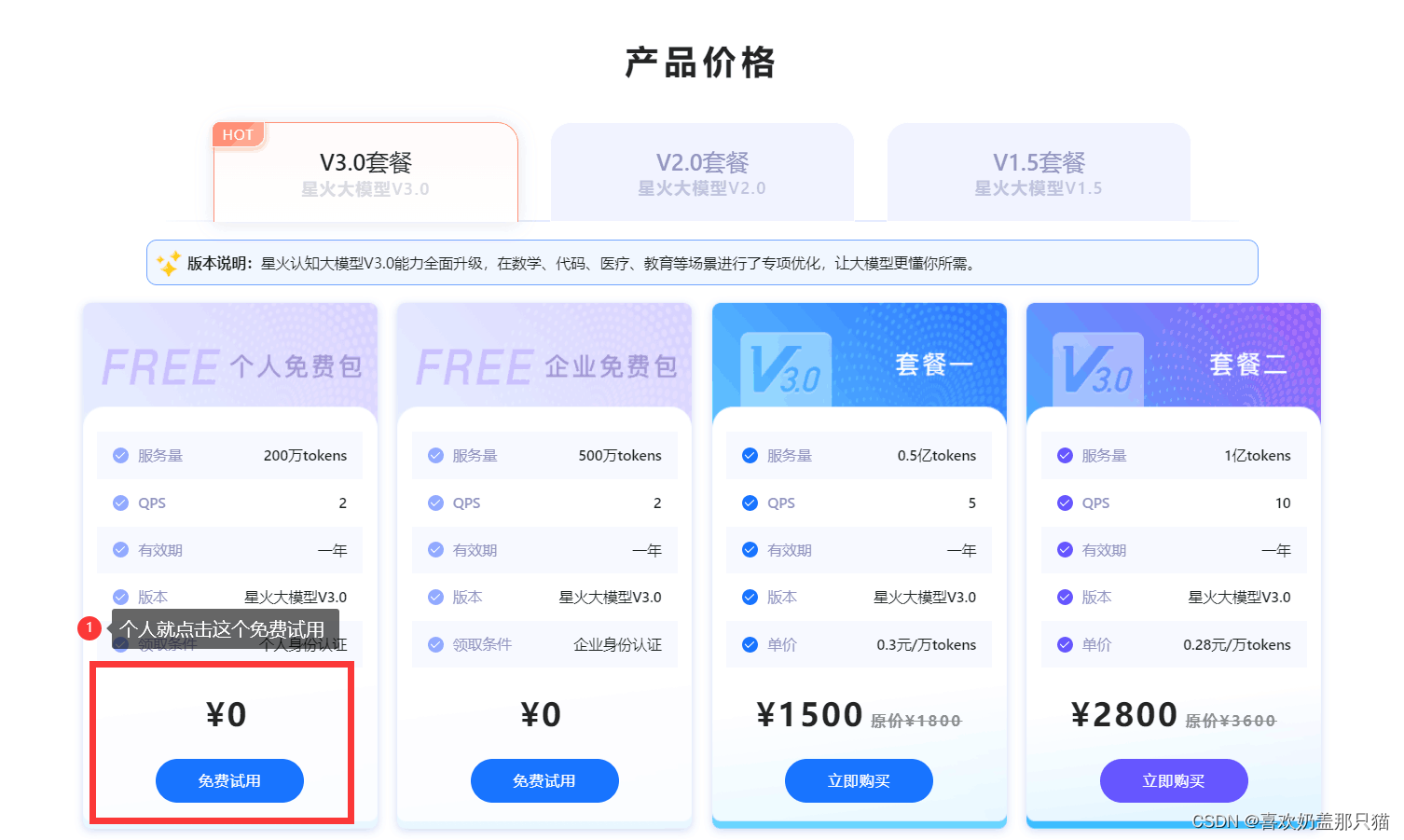 进入界面如下图:点击+号
进入界面如下图:点击+号
 随后,你将进入创建应用界面
随后,你将进入创建应用界面
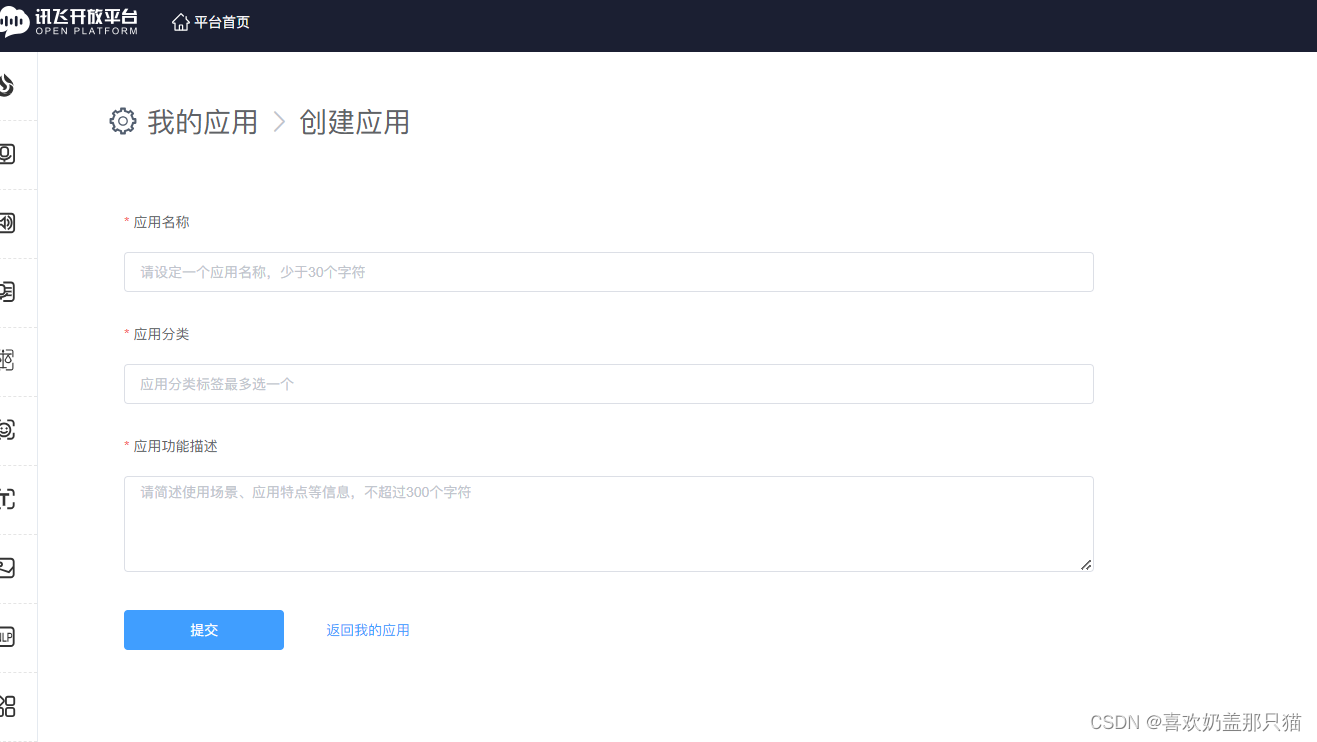 自己创建设计内容,点击提交即可。
自己创建设计内容,点击提交即可。
步骤7:你会再次进入购买界面
 点击勾选同意,确认下单。
点击勾选同意,确认下单。
步骤8:回到API页面,也就是步骤3,点击服务管理
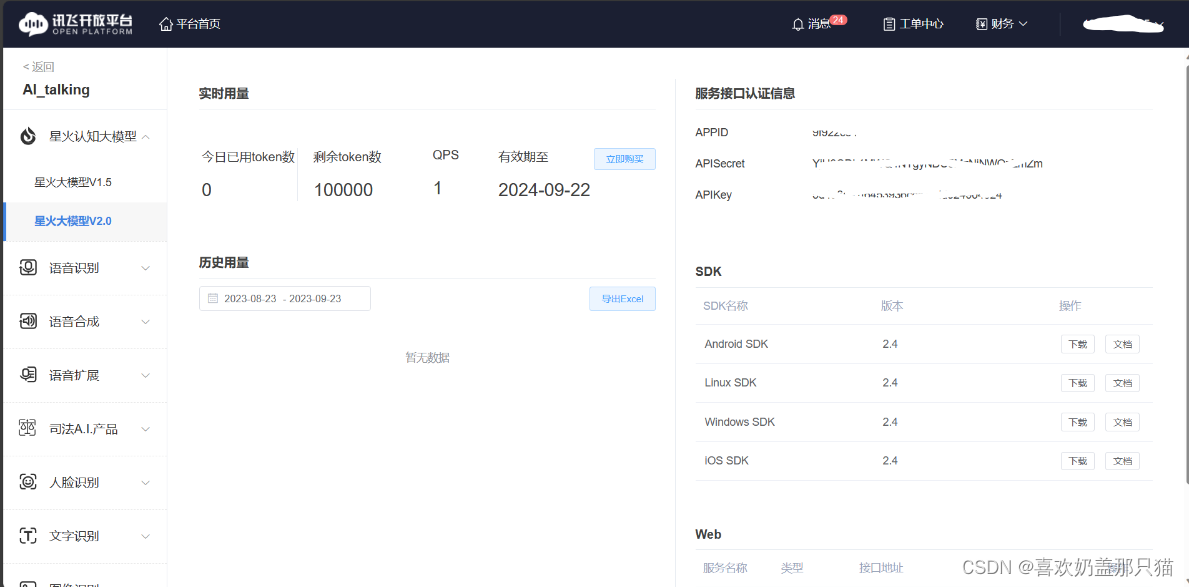
 进入到控制台,就可以看到我们获取到的 APPID、APISecret 和 APIKey 了(在右侧)
进入到控制台,就可以看到我们获取到的 APPID、APISecret 和 APIKey 了(在右侧)
1.2 调用原生星火 API 步骤
星火 API 需要通过 WebSocket 进行连接,相对来说配置较为复杂,讯飞给出了配置示例 SparkApi.py 和连接示例 test.py,此处我们仅讲解 test.py 里的调用逻辑,配置示例代码直接使用即可。
这里我用的是Pycharm,大家喜欢用jupter notebook或者jupter lab、vsCode都行,看自己习惯。在Windows系统中运行的项目
之前我下单的是V3.0,你自己要注意自己的版本
步骤一:项目准备
需要自己安装python,配置环境变量
去Datawhale项目仓库
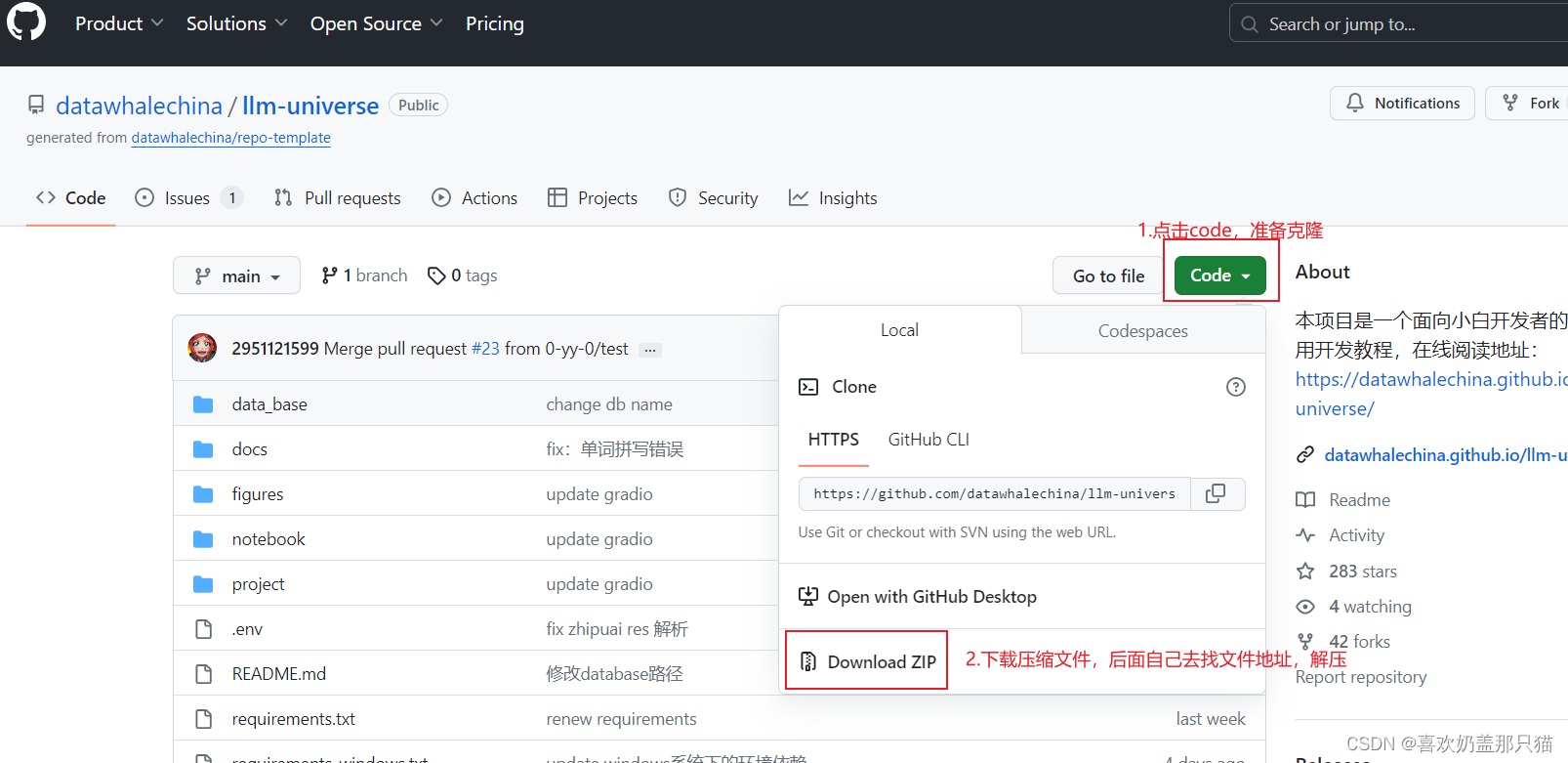
解压后,将文件中的txt,进行操作
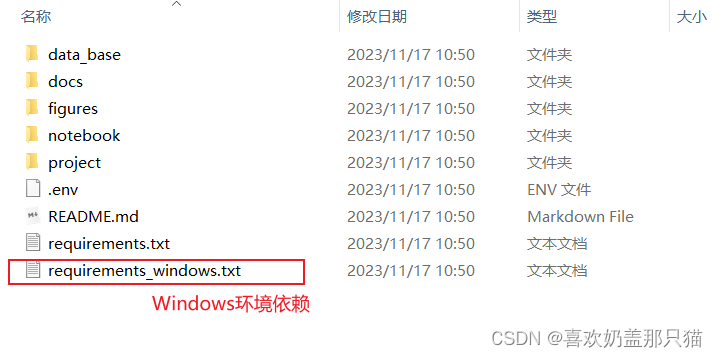
我用的anaconda,
你自己要是不用,可以直接在win+R进入命令行,通过"cd 文件名",(进入到包含requirements_windows.txt这个文件夹里面,复制路径)
输入:pip install -r requirements_windows.txt 回车
会自动安装里面所有的库,对后面的调用做一个准备
如遇报错,请问GPT
以下步骤是有喜欢anaconda就用(非必要)
进入conda

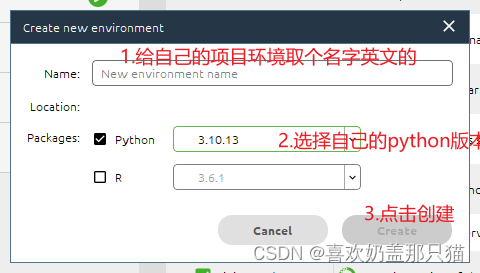
步骤二:新建一个自己的project (名字自己随便取 英文最好)
我就不截图了
在项目中创建一个test.py,代码如下:
import SparkApi
#以下密钥信息从控制台获取
appid = "" #填写控制台中获取的 APPID 信息
api_secret = "" #填写控制台中获取的 APISecret 信息
api_key ="" #填写控制台中获取的 APIKey 信息
#用于配置大模型版本,默认“general/generalv2”
domain = "general" # v1.5版本
# domain = "generalv2" # v2.0版本
#domain = "generalv3" # v3.0版本
#云端环境的服务地址
Spark_url = "ws://spark-api.xf-yun.com/v1.1/chat" # v1.5环境的地址
# Spark_url = "ws://spark-api.xf-yun.com/v2.1/chat" # v2.0环境的地址
#Spark_url ="ws://spark-api.xf-yun.com/v3.1/chat" #v3.1环境的地址
def getText(role, content, text=[]):
# role 是指定角色,content 是 prompt 内容
jsoncon = {}
jsoncon["role"] = role
jsoncon["content"] = content
text.append(jsoncon)
return text
question = getText("user", "你好")
print(question)
response = SparkApi.main(appid,api_key,api_secret,Spark_url,domain,question)
print(response)
把上面代码中的id、secret、key都填入自己申请好的API
注意自己的API版本,看看自己的云端环境服务地址是什么,千万不要填错地址了,
不要多什么(s)诸如此类~
注意python格式,学过python基础要注意别因为Tab键,后面让自己头痛
步骤三:把在项目仓库中的SparkApi.py文件(在这个路径里面"llm-universe-main\notebook\C2 调用大模型 API")拖进自己的项目,这是官方写好的,拿来就可以调用的文档
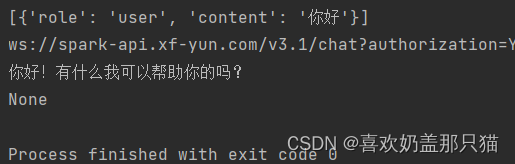
最后检查好,没有报错之后,点击运行test.py就行
结果会显示
在星火控制台,你也可以看到自己调用次数的数据变化
1.3 统一 API 调用方式
将通用大模型 API 封装成本地 API,从而实现同一方式的 API 调用
将项目仓库第二章文件中的这三个py文件拷贝到自己的项目中,如下图:

步骤一:要实现本地 API 封装,实现后为spark_api.py;我们首先需要安装 fastapi 第三方库
步骤二:本地端口服务调用
1.在终端中输入uvicorn spark_api:app 命令启动
启动之后,默认会在本地 8000 端口开启 API 服务。
启动 API 之后,我们可以向本地 8000 端口发起 Request 请求来访问 API:
2.所以,在自己的项目中随便创建一个py文件,输入代码:并run这个文件
import requests
def get_completion_spark(prompt, temperature = 0.1, max_tokens = 4096):
api_url = "http://127.0.0.1:8000/spark"
headers = {"Content-Type": "application/json"}
data = {
"prompt" : prompt,
"temperature" : temperature,
"max_tokens" : max_tokens
}
response = requests.post(api_url, headers=headers, json=data)
print("response:", response)
print()
print()
return response.text
if __name__ == "__main__":
ans = get_completion_spark("你好")
print(ans)
这就算完成了统一API的调用方式。
若是想看自己如何自定义LLM,就看所给代码 spark_llm.py
2.调用 ChatGPT
3.调用百度文心
4.调用智谱 AI
5.调用智谱 AI 生成 embedding
三、langchain 核心组件详解
1. 模型输入/输出
LangChain 中模型输入/输出模块是与各种大语言模型进行交互的基本组件,是大语言模型应用的核心元素。模型 I/O 允许您管理 prompt(提示),通过通用接口调用语言模型以及从模型输出中提取信息。该模块的基本流程如下图所示。
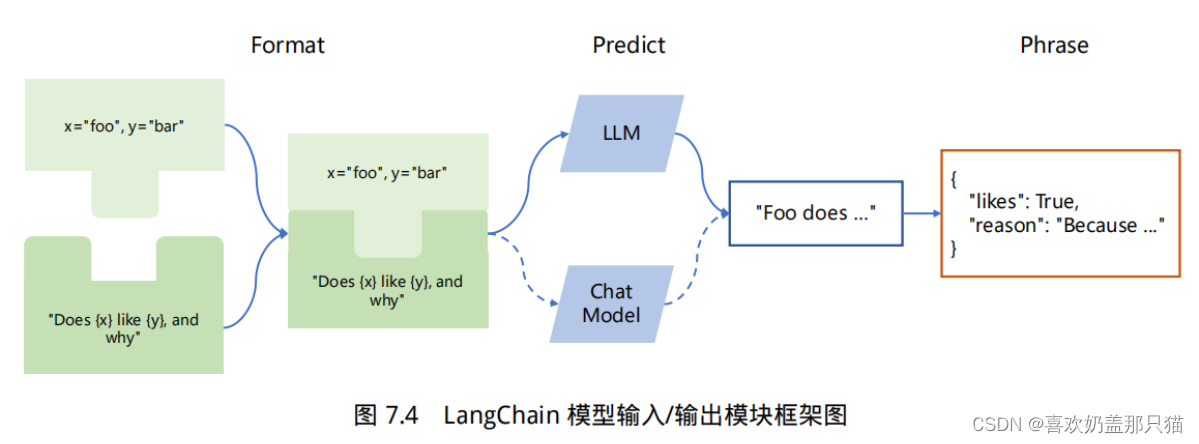
主要包含以下部分:Prompts、Language Models以及 Output Parsers。用户原始输入与模型和示例进行组合,然后输入给大语言模型,再根据大语言模型的返回结果进行输出或者结构化处理。
2. 数据连接
大语言模型(Large Language Model, LLM), 比如 ChatGPT , 可以回答许多不同的问题。但是大语言模型的知识来源于其训练数据集,并没有用户的信息(比如用户的个人数据,公司的自有数据),也没有最新发生时事的信息(在大模型数据训练后发表的文章或者新闻)。因此大模型能给出的答案比较受限。如果能够让大模型在训练数据集的基础上,利用我们自有数据中的信息来回答我们的问题,那便能够得到更有用的答案。
为了支持上述应用的构建,LangChain 数据连接(Data connection)模块通过以下方式提供组件来加载、转换、存储和查询数据:Document loaders、Document transformers、Text embedding models、Vector stores以及Retrievers。数据连接模块部分的基本框架如下图所示。

3. 链(Chain)
虽然独立使用大型语言模型能够应对一些简单任务,但对于更加复杂的需求,可能需要将多个大型语言模型进行链式组合,或与其他组件进行链式调用。链允许将多个组件组合在一起,创建一个单一的、连贯的应用程序。例如,可以创建一个链,接受用户输入,使用 PromptTemplate 对其进行格式化,然后将格式化后的提示词传递给大语言模型。也可以通过将多个链组合在一起或将链与其他组件组合来构建更复杂的链。
大语言模型链(LLMChain)是一个简单但非常强大的链,也是后面我们将要介绍的许多链的基础。我们以它为例,进行介绍:
import warnings
warnings.filterwarnings('ignore')
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
# 这里我们将参数temperature设置为0.0,从而减少生成答案的随机性。
# 如果你想要每次得到不一样的有新意的答案,可以尝试调整该参数。
llm = ChatOpenAI(temperature=0.0)
#初始化提示模版
prompt = ChatPromptTemplate.from_template("描述制造{product}的一个公司的最佳名称是什么?")
#将大语言模型(LLM)和提示(Prompt)组合成链
chain = LLMChain(llm=llm, prompt=prompt)
#运行大语言模型链
product = "大号床单套装"
chain.run(product)

除了上例中给出的 LLMChain,LangChain 中链还包含 RouterChain、SimpleSequentialChain、SequentialChain、TransformChain 等。
- RouterChain 可以根据输入数据的某些属性/特征值,选择调用不同的子链(Subchain)。
- SimpleSequentialChain 是最简单的序列链形式,其中每个步骤具有单一的输入/输出,上一个步骤的输出是下一个步骤的输入。
- SequentialChain 是简单顺序链的更复杂形式,允许多个输入/输出。
- TransformChain 可以引入自定义转换函数,对输入进行处理后进行输出。
4. 记忆(Meomory)
在 LangChain 中,记忆(Memory)指的是大语言模型(LLM)的短期记忆。为什么是短期记忆?那是因为LLM训练好之后 (获得了一些长期记忆),它的参数便不会因为用户的输入而发生改变。当用户与训练好的LLM进行对话时,LLM 会暂时记住用户的输入和它已经生成的输出,以便预测之后的输出,而模型输出完毕后,它便会“遗忘”之前用户的输入和它的输出。因此,之前的这些信息只能称作为 LLM 的短期记忆。
正如上面所说,在与语言模型交互时,你可能已经注意到一个关键问题:它们并不记忆你之前的交流内容,这在我们构建一些应用程序(如聊天机器人)的时候,带来了很大的挑战,使得对话似乎缺乏真正的连续性。因此,在本节中我们将介绍 LangChain 中的记忆模块,即如何将先前的对话嵌入到语言模型中的,使其具有连续对话的能力。
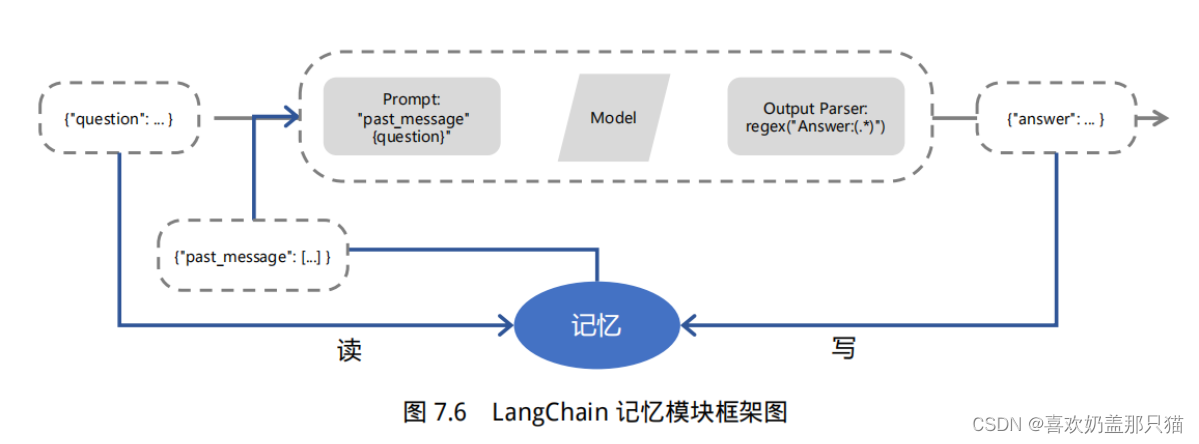
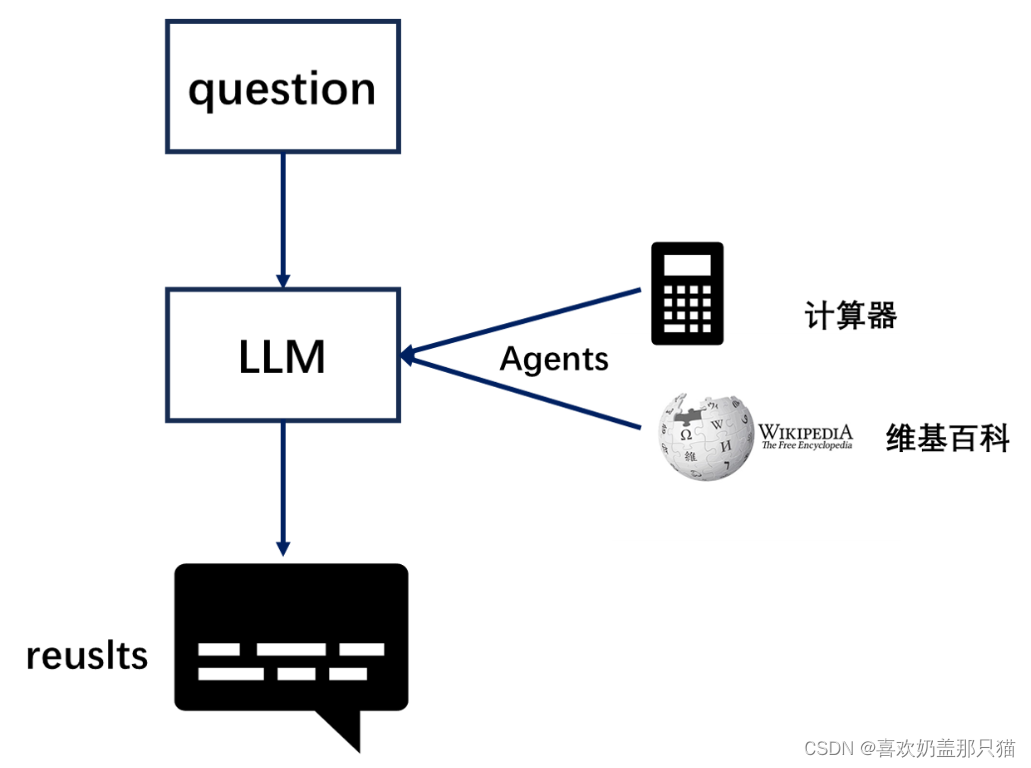
5. 代理(Agents)
大型语言模型(LLMs)非常强大,但它们缺乏“最笨”的计算机程序可以轻松处理的特定能力。LLM 对逻辑推理、计算和检索外部信息的能力较弱,这与最简单的计算机程序形成对比。例如,语言模型无法准确回答简单的计算问题,还有当询问最近发生的事件时,其回答也可能过时或错误,因为无法主动获取最新信息。这是由于当前语言模型仅依赖预训练数据,与外界“断开”。要克服这一缺陷, LangChain 框架提出了 “代理”( Agent ) 的解决方案。代理作为语言模型的外部模块,可提供计算、逻辑、检索等功能的支持,使语言模型获得异常强大的推理和获取信息的超能力。
6.回调(Callback)
LangChain提供了一个回调系统,允许您连接到LLM应用程序的各个阶段。这对于日志记录、监视、流式处理和其他任务非常有用。
Callback 模块扮演着记录整个流程运行情况的角色,充当类似于日志的功能。在每个关键节点,它记录了相应的信息,以便跟踪整个应用的运行情况。例如,在 Agent 模块中,它记录了调用 Tool 的次数以及每次调用的返回参数值。Callback 模块可以将收集到的信息直接输出到控制台,也可以输出到文件,甚至可以传输到第三方应用程序,就像一个独立的日志管理系统一样。通过这些日志,可以分析应用的运行情况,统计异常率,并识别运行中的瓶颈模块以进行优化。
Callback 模块的具体实现包括两个主要功能,对应CallbackHandler 和 CallbackManager 的基类功能:
- CallbackHandler 用于记录每个应用场景(如 Agent、LLchain 或 Tool )的日志,它是单个日志处理器,主要记录单个场景的完整日志信息。
- 而CallbackManager则封装和管理所有的 CallbackHandler ,包括单个场景的处理器,也包括整个运行时链路的处理器。"
在哪里传入回调 ? :构造函数回调、请求回调
你想在什么时候使用这些东西呢? :
- 构造函数回调对诸如日志、监控等用例最有用,这些用例不是针对单个请求,而是针对整个链。
- 请求回调对流媒体等用例最有用,你想把单个请求的输出流向特定的 websocket 连接,或其他类似用例。
附:如何自定义 LLM
LangChain 为基于 LLM 开发自定义应用提供了高效的开发框架,便于开发者迅速地激发 LLM 的强大能力,搭建 LLM 应用。LangChain 也同样支持多种大模型,内置了 OpenAI、LLAMA 等大模型的调用接口。但是,LangChain 并没有内置所有大模型,它通过允许用户自定义 LLM 类型,来提供强大的可扩展性。
要实现自定义 LLM,需要定义一个自定义类继承自 LangChain 的 LLM 基类,然后定义两个函数:① _call
方法,其接受一个字符串,并返回一个字符串,即模型的核心调用;② _identifying_params 方法,用于打印 LLM 信息。
以百度文心为例
步骤一:首先我们导入所需的第三方库:
import json
import time
from typing import Any, List, Mapping, Optional, Dict, Union, Tuple
import requests
from langchain.callbacks.manager import CallbackManagerForLLMRun
from langchain.llms.base import LLM
from langchain.utils import get_from_dict_or_env
from pydantic import Field, model_validator
步骤二:
由于百度文心使用双重秘钥进行认证,用户需要先基于 API_Key 与 Secret_Key 来获取 access_token,再使用 access_token 来实现对模型的调用,因此我们需要先定义一个 get_access_token 方法来获取 access_token:
def get_access_token(api_key : str, secret_key : str):
"""
使用 API Key,Secret Key 获取access_token,替换下列示例中的应用API Key、应用Secret Key
"""
# 指定网址
url = f"https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={api_key}&client_secret={secret_key}"
# 设置 POST 访问
payload = json.dumps("")
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
# 通过 POST 访问获取账户对应的 access_token
response = requests.request("POST", url, headers=headers, data=payload)
return response.json().get("access_token")
步骤三:接着我们定义一个继承自 LLM 类的自定义 LLM 类:
# 继承自 langchain.llms.base.LLM
class Wenxin_LLM(LLM):
# 原生接口地址
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/eb-instant"
# 默认选用 ERNIE-Bot-turbo 模型,即目前一般所说的百度文心大模型
model_name: str = Field(default="ERNIE-Bot-turbo", alias="model")
# 访问时延上限
request_timeout: Optional[Union[float, Tuple[float, float]]] = None
# 温度系数
temperature: float = 0.1
# API_Key
api_key: str = None
# Secret_Key
secret_key : str = None
# access_token
access_token: str = None
# 必备的可选参数
model_kwargs: Dict[str, Any] = Field(default_factory=dict)
步骤四:接下来我们实现一个初始化方法 init_access_token,当模型的 access_token 为空时调用:
def init_access_token(self):
if self.api_key != None and self.secret_key != None:
# 两个 Key 均非空才可以获取 access_token
try:
self.access_token = get_access_token(self.api_key, self.secret_key)
except Exception as e:
print(e)
print("获取 access_token 失败,请检查 Key")
else:
print("API_Key 或 Secret_Key 为空,请检查 Key")
步骤五:接下来我们实现核心的方法——调用模型 API:
def _call(self, prompt : str, stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any):
# 除 prompt 参数外,其他参数并没有被用到,但当我们通过 LangChain 调用时会传入这些参数,因此必须设置
# 如果 access_token 为空,初始化 access_token
if self.access_token == None:
self.init_access_token()
# API 调用 url
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/eb-instant?access_token={}".format(self.access_token)
# 配置 POST 参数
payload = json.dumps({
"messages": [
{
"role": "user",# user prompt
"content": "{}".format(prompt)# 输入的 prompt
}
],
'temperature' : self.temperature
})
headers = {
'Content-Type': 'application/json'
}
# 发起请求
response = requests.request("POST", url, headers=headers, data=payload, timeout=self.request_timeout)
if response.status_code == 200:
# 返回的是一个 Json 字符串
js = json.loads(response.text)
return js["result"]
else:
return "请求失败"
步骤六:然后我们还需要定义一下模型的描述方法:
# 首先定义一个返回默认参数的方法
@property
def _default_params(self) -> Dict[str, Any]:
"""获取调用Ennie API的默认参数。"""
normal_params = {
"temperature": self.temperature,
"request_timeout": self.request_timeout,
}
return {**normal_params}
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters."""
return {**{"model_name": self.model_name}, **self._default_params}
通过上述步骤,我们就可以基于 LangChain 定义百度文心的调用方式了。(将此代码封装在 wenxin_llm.py 文件中)
四、学习地址
在线学习地址
项目仓库学习地址
langchain 官方文档
面向开发者的 LLM 入门课程
注:由datawhale提供学习















 464
464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











