






langchain是什么
lanchain主要目标是将LLM与开发者现有的知识和系统相结合,以提供更智能化的服务
https://zhuanlan.zhihu.com/p/622717995
实现原理:
langchain是什么
lanchain主要目标是将LLM与开发者现有的知识和系统相结合,以提供更智能化的服务
https://zhuanlan.zhihu.com/p/622717995

用法介绍:https://github.com/liaokongVFX/LangChain-Chinese-Getting-Started-Guide
langchain源码解读
源码地址:https://github.com/langchain-ai/langchain/tree/master
下载地址:/LLM/langchain/libs/langchain/langchain (源码外面好多层)
代码结构:

重点目录挨个说:
1.prompt目录
是一些prompt的集合。example_selector,是内置一些few–shot的prompt。首先把所有例子进行向量化处理,再把用户输入的问题向量化后和所有例子做相似度计算,最后选出相似度最高的例子作为few-shot的例子喂给chatgpt。也可以用ngram-重合度作为度量,找最相似的。
2.output_parser目录
实现将输出格式化。
生成prompt,内容为告诉chatgpt:生成格式化的输出。然后讲原输出+该prompt喂给chatgpt
3.memory目录
将对话记录存为memory,可以定义prompt,来存储不同样式的memory。例如summary memory,就是将对话或者文本摘要后进行存储。
4.Vectorstores目录
将文本以向量的形式存储在数据库中,包含chroma,faiss
5.chains目录
串联的方式,集合各个模块,形成pipline。也可以自己构造pipline,相当于一个满足某功能的函数,给输入,返回输出。
其中有如下这么多各种不同功能的chain
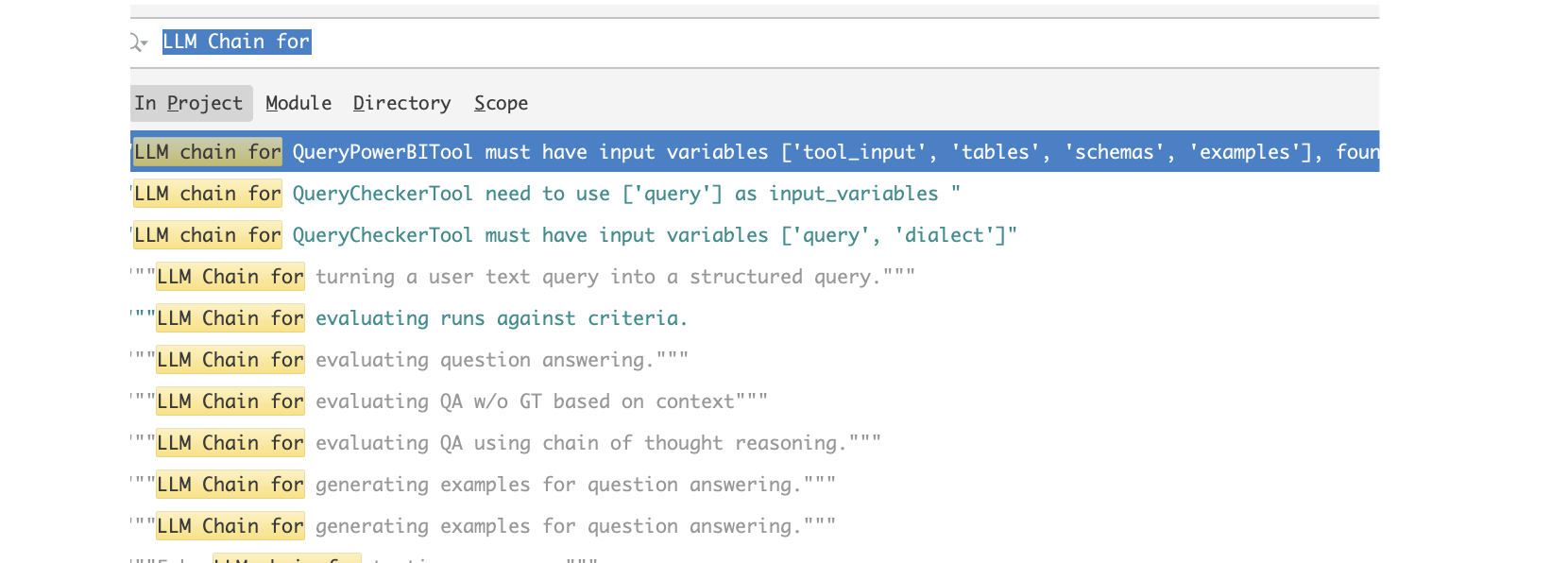
使用方法例子:
参考: https://liaokong.gitbook.io/llm-kai-fa-jiao-cheng/#wan-cheng-yi-ci-wen-da
#1.对文章做总结
from langchain.chains.summarize import load_summarize_chain
# 创建总结链
chain = load_summarize_chain(llm, chain_type="refine", verbose=True)
# 执行总结链,(为了快速演示,只总结前5段)
chain.run(split_documents[:5])
#2.创建检索知识库问答
from langchain.chains import RetrievalQA
# 创建问答对象
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=docsearch.as_retriever(), return_source_documents=True)
# 进行问答
result = qa({"query": "科大讯飞今年第一季度收入是多少?"})
print(result)
#3.从数据库查询结果并回答
from langchain.chains.question_answering import load_qa_chain
chain = load_qa_chain(llm, chain_type="stuff", verbose=True)
chain.run(input_documents=docs, question=query)
#4.构建问答机器人
from langchain.chains import ChatVectorDBChain, ConversationalRetrievalChain
# 初始化问答链
qa = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.1,max_tokens=2048),retriever,condense_question_prompt=prompt)
chat_history = []
while True:
question = input('问题:')
# 开始发送问题 chat_history 为必须参数,用于存储对话历史
result = qa({'question': question, 'chat_history': chat_history})
chat_history.append((question, result['answer']))
print(result['answer'])
#5.执行多个chain
from langchain.chains import SimpleSequentialChain
location_chain = LLMChain(llm=llm, prompt=prompt_template)
meal_chain = LLMChain(llm=llm, prompt=prompt_template)
# 通过 SimpleSequentialChain 串联起来,第一个答案会被替换第二个中的user_meal,然后再进行询问
overall_chain = SimpleSequentialChain(chains=[location_chain, meal_chain], verbose=True)
review = overall_chain.run("Rome")

6.callback目录
回调系统,允许挂接到LLM应用程序的任何阶段。
langchain—chatglm实现简易问答系统/聊天机器人
代码组件包介绍
用langchain实现一个基于文本的问答机器人

用langchain实现一个简易的聊天机器人
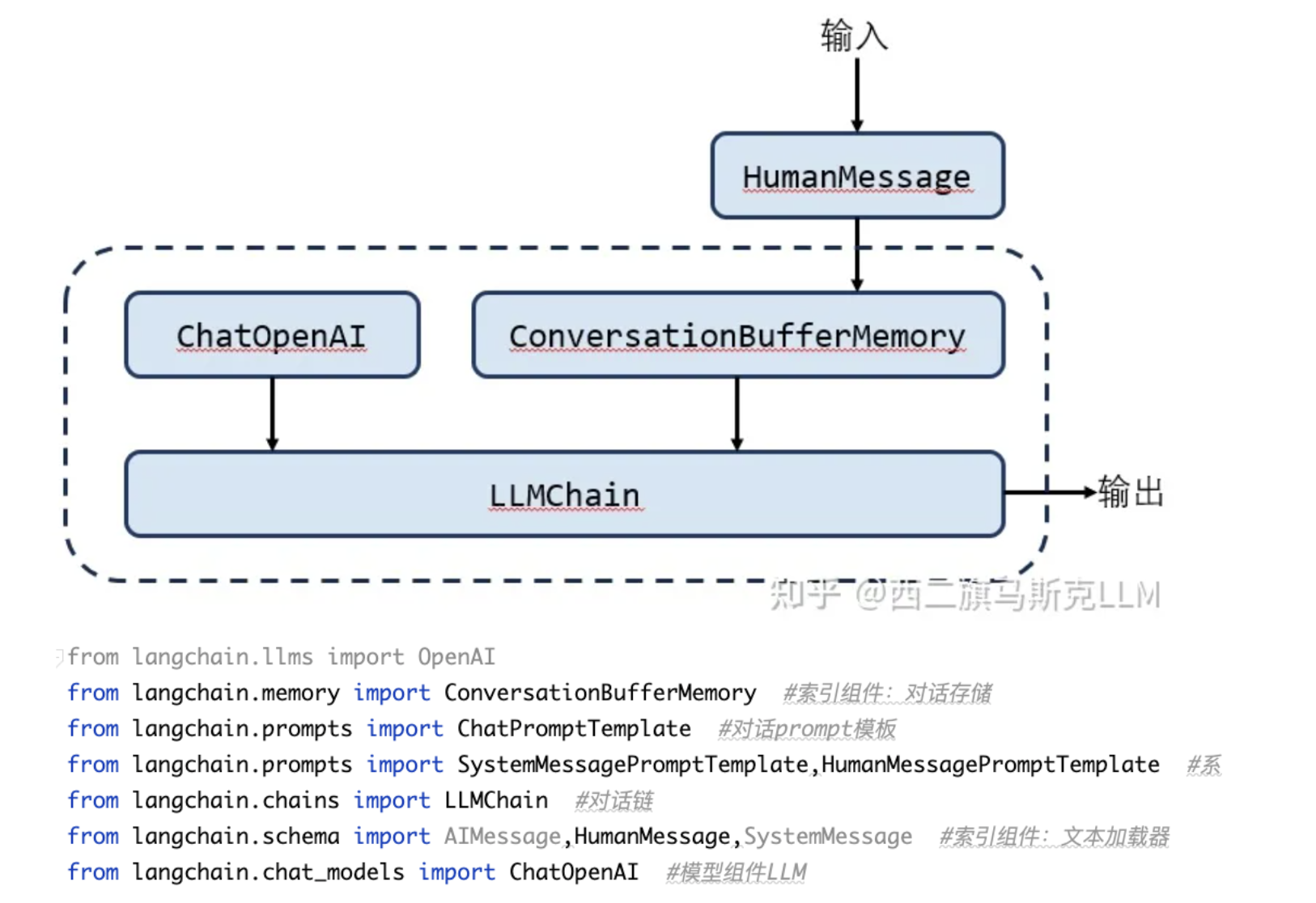
langchain的各模块介绍
https://zhuanlan.zhihu.com/p/644938147
文本分割器
langchain默认使用RecursiveCharacterTextSplitter:
-
RecursiveCharacterTextSplitter():按字符串分割文本,递归地尝试按不同的分隔符进行分割文本。
默认使用[“\n\n” ,"\n" ," ",""] 这四个特殊符号作为分割文本的标记, 参数说明: chunk_size:被切割的字符串的最大长度 chunk_overlap:如果仅仅使用chunk_size来切割时,前后两段字符串重叠的字符数量。 separators=["\n\n", "\n", " ", ""] #可以设置分隔符,单换行符,多换行符 separators=["\n\n", "\n", "(?<=\. )", " ", ""] 增加了正则表达式"(?<=\. )",它的意思是保证句号前面一定会存在字符,这样就避免了句号被保留在句首的情况。 -
CharacterTextSplitter():按字符来分割文本。
按字符分割,默认情况下CharacterTextSplitter是忽略空格的,默认的字分割符是双换行符即\n\n, 可以设置separator = ' ' 来考虑空格 -
MarkdownHeaderTextSplitter():基于指定的标题来分割markdown 文件。
可以使用 MarkdownHeaderTextSplitter 来保留块中的标题元数据: -
TokenTextSplitter():按token来分割文本。
可以用于英文分割。一个token是最小词语单位,大约有4个字符
使用意见:CharacterTextSplitter比RecursiveCharacterTextSplitter稍好,利用明确的段落分隔符可以避免一些初级问题发生,一些高级的问题两者都会发生。
文本嵌入
https://zhuanlan.zhihu.com/p/645655496
向量存储是指被切割的文档需要经过向量化操作以后存储到向量数据库的过程,因为大型语言模型(LLM)无法理解文字信息(只能理解数字),所以我们必须对文字信息进行编码,这里说的编码就是只嵌入(Embeddings), 嵌入操作可以将文本转换成数字编码并以向量的形式存储在向量数据库中,

当用户对文档内容提出问题时,用户的问题也会经嵌入操作后被转换成向量并与向量数据库中的所有向量做相似度比较,最后找出与问题最相关的n个向量,
当找到与用户问题最相关的n个向量以后,这些向量会被还原成原始文本,然后将用户的问题和这些文本信息发送给LLM, LLM会针对用户的问题对这些文本内容做提炼和汇总,最后给出正确合理的答案,

prompt 使用
1. 常规prompt模板的使用
from langchain import PromptTemplate
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}." #先定义模板,并设定待输入的变量
)
prompt_template.format(adjective="funny", content="chickens") #输入变量
2.聊天信息模板prompt的使用
from langchain.prompts import ChatPromptTemplate 聊天模板
#ChatPromptTemplate.from_messages 接受各种消息表示形式。
template = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])
messages = template.format_messages(
name="Bob",
user_input="What is your name?"
)
messages
langchain各种范例实现
















 1777
1777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









