







第三章节目录 大模型开发流程及架构
一、大模型开发整体流程
1.何为大模型开发
我们将开发以大语言模型为功能核心、通过大语言模型的强大理解能力和生成能力、结合特殊的数据或业务逻辑来提供独特功能的应用称为大模型开发。开发大模型相关应用,其技术核心点虽然在大语言模型上,但一般通过调用 API 或开源模型来实现核心的理解与生成,通过 Prompt Enginnering 来实现大语言模型的控制,因此,虽然大模型是深度学习领域的集大成之作,大模型开发却更多是一个工程问题。
在大模型开发中,我们一般不会去大幅度改动模型,而是将大模型作为一个调用工具,通过 Prompt Engineering、数据工程、业务逻辑分解等手段来充分发挥大模型能力,适配应用任务,而不会将精力聚焦在优化模型本身上。因此,作为大模型开发的初学者,我们并不需要深研大模型内部原理,而更需要掌握使用大模型的实践技巧。

2.大模型开发的整体流程
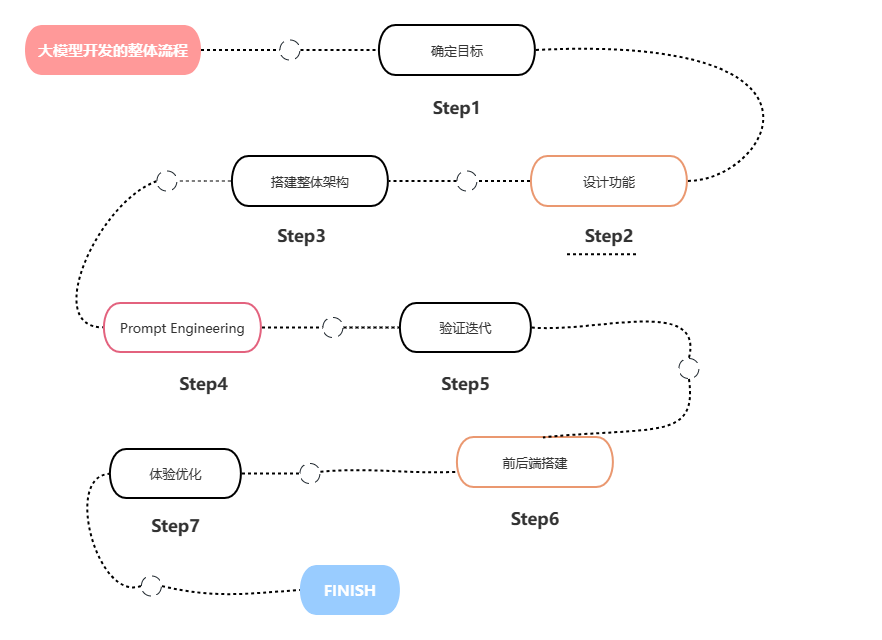
二、项目流程简析
2.1项目规划与需求分析
1.项目目标:基于个人知识库的问答助手
2.核心功能:
- 上传文档、创建知识库;
- 选择知识库,检索用户提问的知识片段;
- 提供知识片段与提问,获取大模型回答;
- 流式回复;
- 历史对话记录;
3.确定技术架构和工具
- LangChain框架
- Chroma知识库
- 大模型使用 GPT、科大讯飞的星火大模型、文心一言、GLM 等
- 前后端使用 Gradio 和 Streamlit
2.2数据准备与向量知识库构建
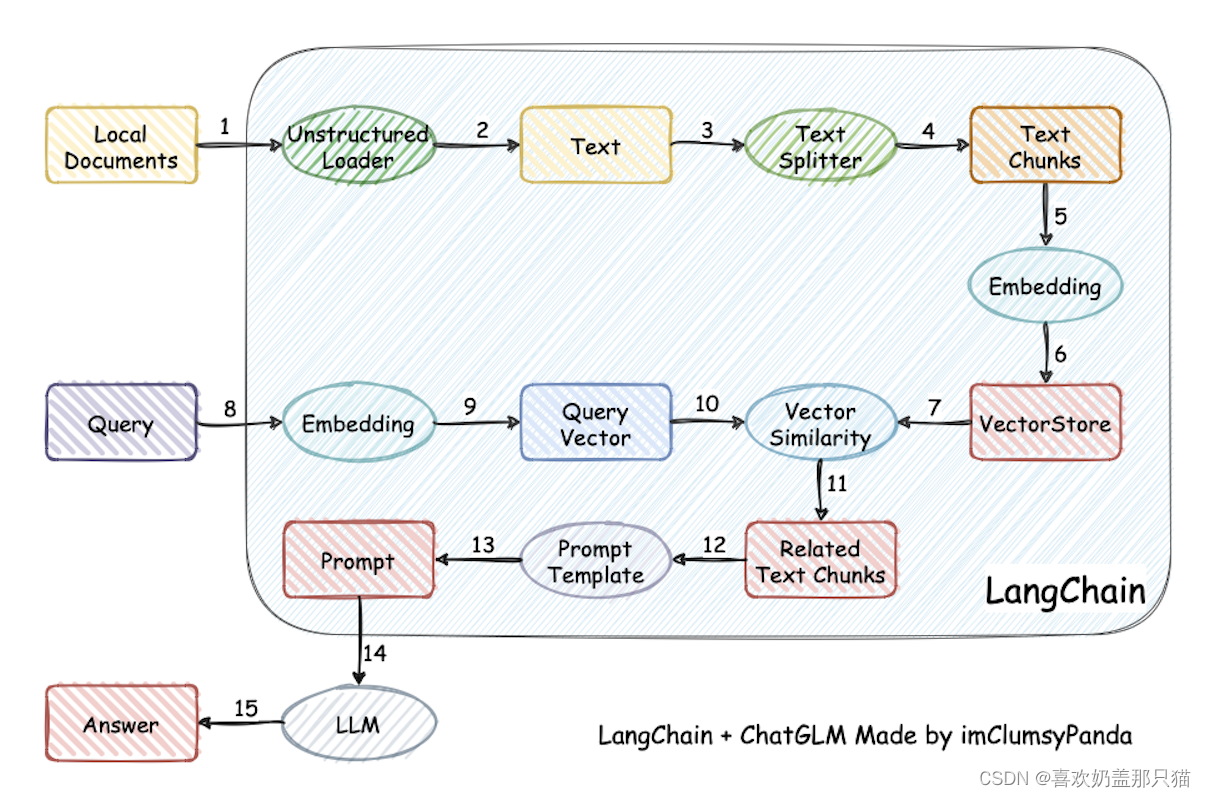
- 收集和整理用户提供的文档。
- 将文档词向量化
- 将向量化后的文档导入Chroma知识库,建立知识库索引
2.3大模型集成与API连接
集成GPT、星火、文心、GLM 等大模型,配置 API 连接。
编写代码,实现与大模型 API 的交互,以便获取问题答案。
2.4核心功能实现
构建 Prompt Engineering,实现大模型回答功能,根据用户提问和知识库内容生成回答。
实现流式回复,允许用户进行多轮对话。
添加历史对话记录功能,保存用户与助手的交互历史。
2.5核心功能迭代优化
进行验证评估,收集 Bad Case。
根据 Bad Case 迭代优化核心功能实现。
2.6前端与用户交互界面开发
使用 Gradio 和 Streamlit 搭建前端界面。
实现用户上传文档、创建知识库的功能。
设计用户界面,包括问题输入、知识库选择、历史记录展示等。
2.7部署测试与上线
部署问答助手到服务器或云平台,确保可在互联网上访问。
进行生产环境测试,确保系统稳定。
上线并向用户发布。
2.8维护与持续改进
监测系统性能和用户反馈,及时处理问题。
定期更新知识库,添加新的文档和信息。
收集用户需求,进行系统改进和功能扩展。
三、项目架构简析
本项目从底向上依次分为 LLM 层、数据层、数据库层、应用层与服务层:
① LLM 层主要基于四种流行 LLM API 进行了 LLM 调用封装,支持用户以统一的入 口、方式来访问不同的模型,支持随时进行模型的切换;
② 数据层 主要包括个人知识库的源数据以及 Embedding API,源数据经过 Embedding 处理可以被向量数据库使用;
③ 数据库层 主要为基于个人知识库源数据搭建的向量数据库,在本项目中我们选择了 Chroma;
④ 应用层 为核心功能的最顶层封装,我们基于 LangChain 提供的检索问答链基类进行了进一步封装,从而支持不同模型切换以及便捷实现基于数据库的检索问答;
⑤ 最顶层为服务层,我们分别实现了 Gradio 搭建 Demo 与 FastAPI 组建 API 两种方式来支持本项目的服务访问。
项目逻辑
用户:可以通过 run_gradio 或者 run_api 启动整个服务;
服务层调用 qa_chain.py 或 chat_qa_chain 实例化对话检索链对象,实现全部核心功能;
服务层和应用层都可以调用、切换 prompt_template.py 中的 prompt 模板来实现 prompt 的迭代;
也可以直接调用 call_llm 中的 get_completion 函数来实现不使用数据库的 LLM;
应用层调用已存在的数据库和 llm 中的自定义 LLM 来构建检索链;
如果数据库不存在,应用层调用 create_db.py 创建数据库,该脚本可以使用 openai embedding 也可以使用 embedding.py 中的自定义 embedding
五、学习地址
注:由datawhale提供学习















 1320
1320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











