







对于常见的函数都是单行函数,说白了就是一一映射,输入一个值则输出对应的值,但是MySQL中还存在聚合函数就是输入一组值则返回一个值,常见的例如:sum、max等
很多时候需要对数据中的某些字段进行分组,探究每组内的数据信息,这时就需要使用group by这个函数,该函数可以根据指定字段的值进行分组
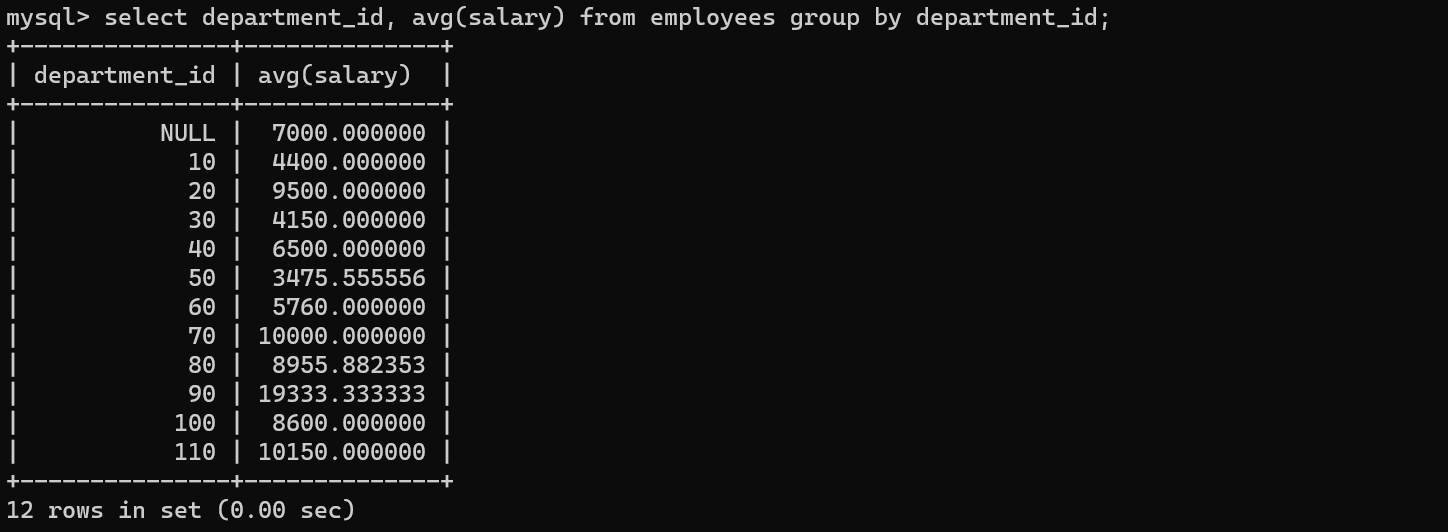
案例1:查询每个部门的平均工资
SELECT
department_id,
avg( salary )
FROM
employees
GROUP BY
department_id;
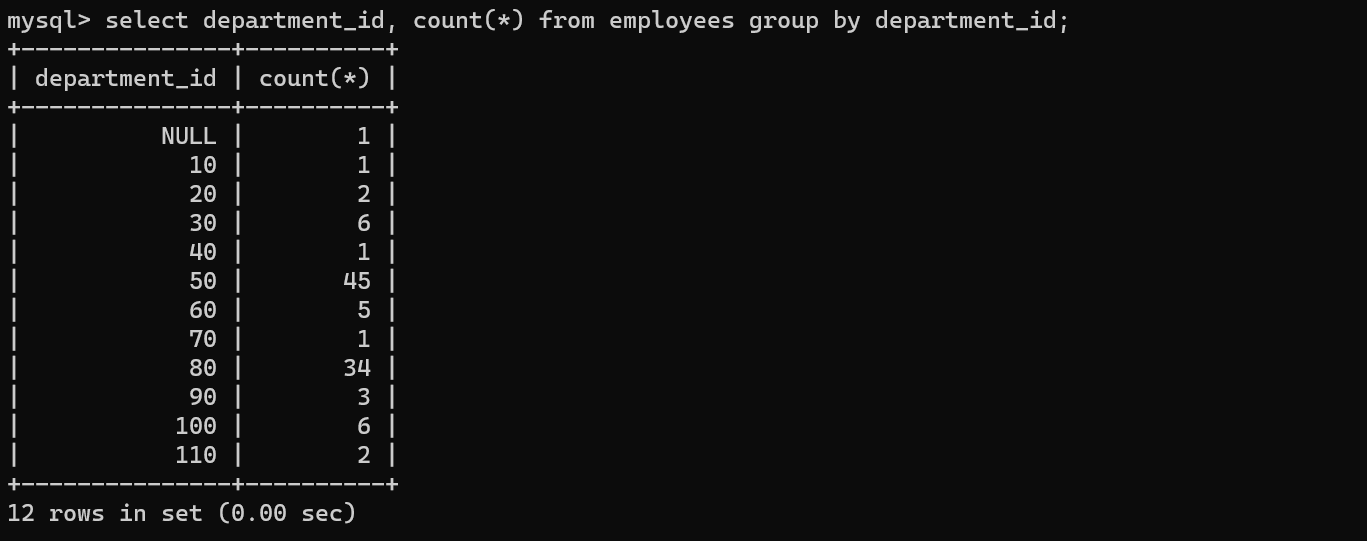
案例2:查询每个部门的人数
SELECT
department_id,
count(*)
FROM
employees
GROUP BY
department_id;
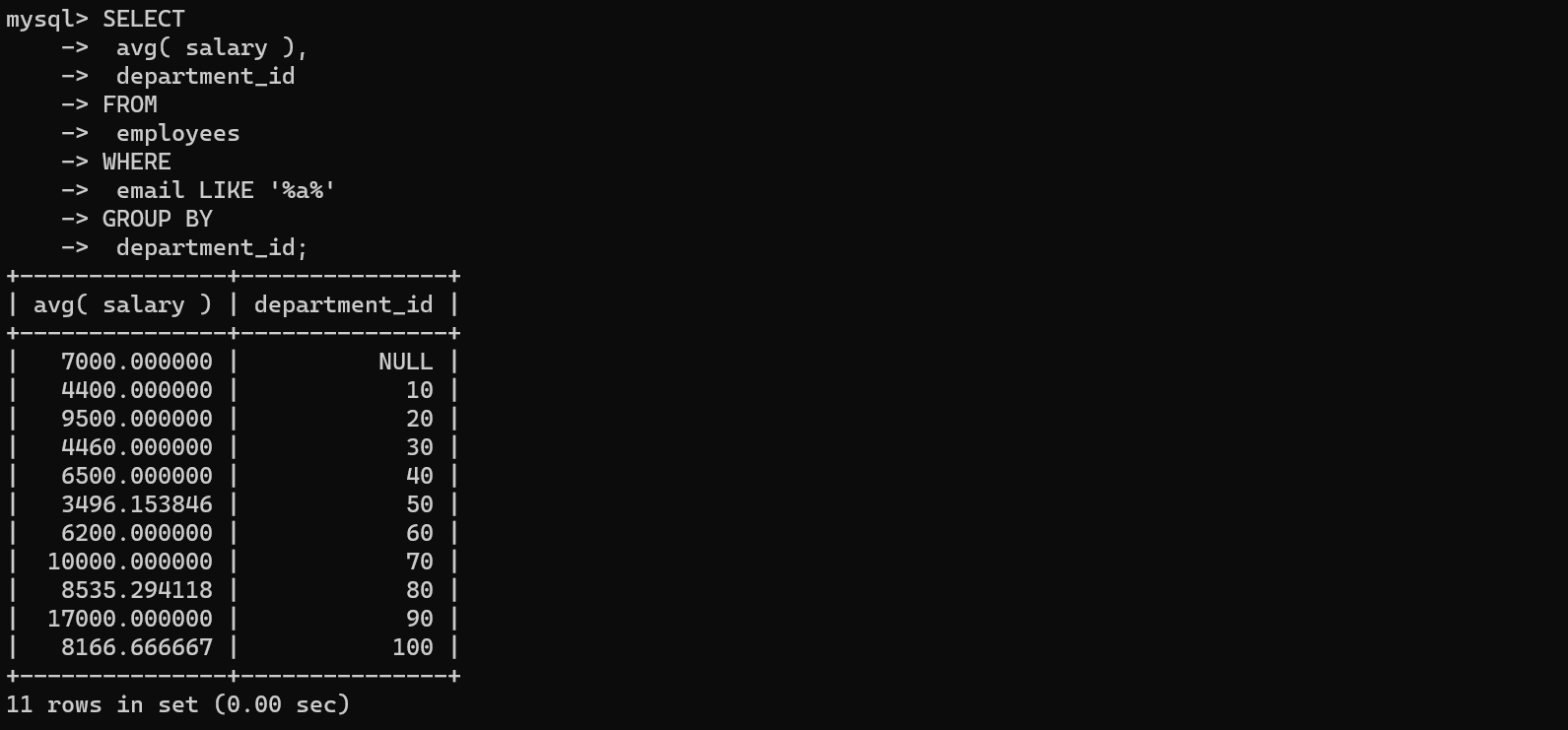
案例3:查询邮箱中包含a字符的,每个部门的平均工资
该案例中首先使用了where从起始表中筛选出含有a的,然后再从剩下的数据执行groupby函数进行聚合
SELECT
avg( salary ),
department_id
FROM
employees
WHERE
email LIKE '%a%'
GROUP BY
department_id;
案例4:查询部门员工数大于2的部门id
该sql首先根据部门id进行分组,然后对每个分组进行having判断,判断聚合后的每个组元素个数是否大于2
对于where和having都是用于筛选条件的,但是二者又有一些不同
| 数据源 | 位置 | 关键字 | |
|---|---|---|---|
| 分组前筛选 | 原始表 | group by子句的前面 | where |
| 分组后筛选 | 分组后的结果集 | group by子句的后面 | having |
SELECT
department_id,
count(*) AS num
FROM
employees
GROUP BY
department_id
HAVING
num > 2;

案例5:按员工姓名的长度分组,查询每一组的员工个数,筛选员工个数大于5的有哪些?
SELECT
LENGTH( last_name ) AS length,
count(*) AS num
FROM
employees
GROUP BY
length
HAVING
num > 5;
首先是按照姓名的长度进行分组,这里为了方便可以起别名,分组之后每个组的结果集都是名字相同长度的,再使用having筛选出每个组员工个数大于5的组
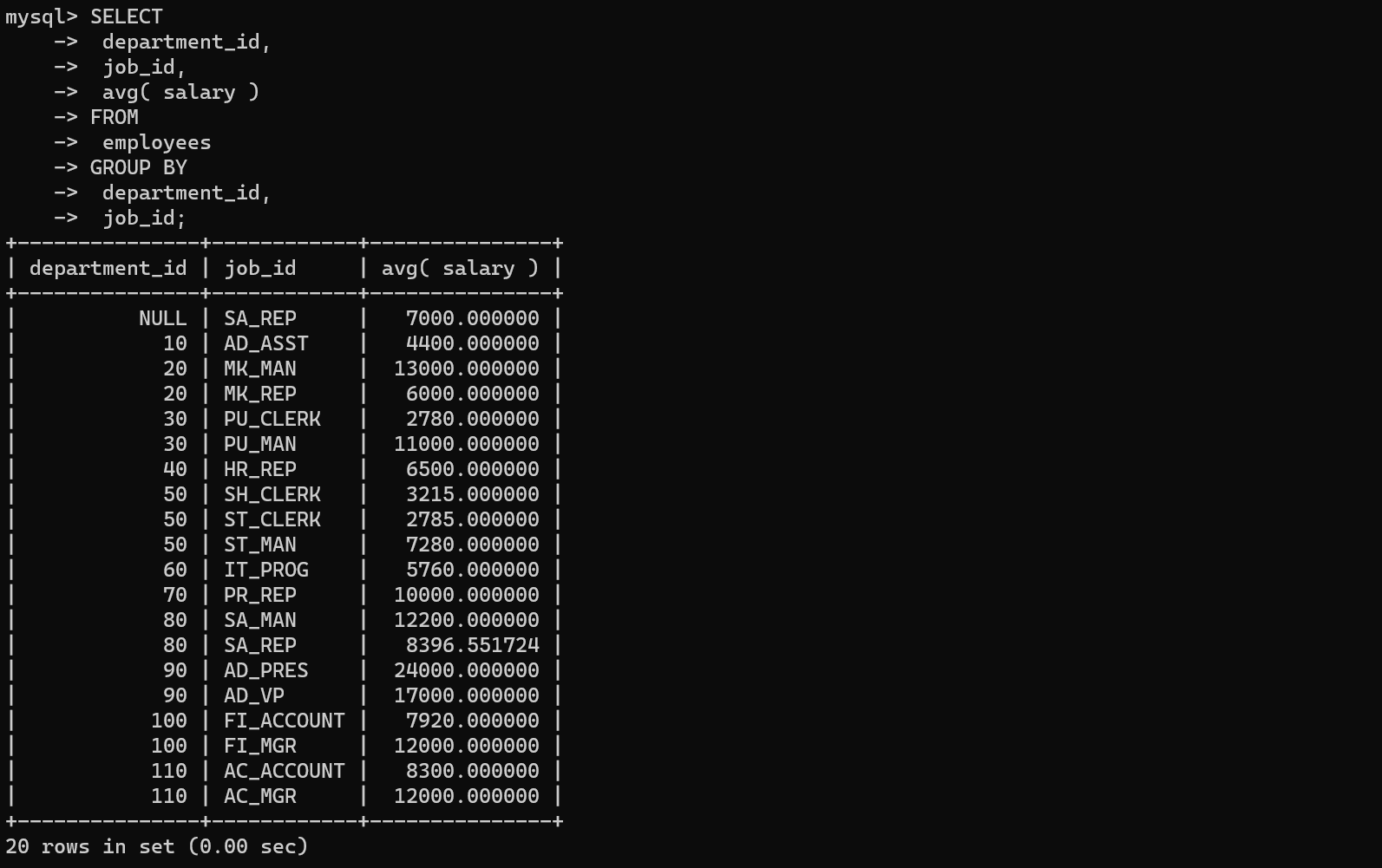
案例6:查询每个部门每个工种的员工的平均工资
group by也是支持按照多个字段进行分组的
SELECT
department_id,
job_id,
avg( salary )
FROM
employees
GROUP BY
department_id,
job_id;
案例7:查询每个部门每个工种的员工的平均工资,并且按平均工资的高低显示
这个排序是全局排序,就是聚合后每个组的内容合并到一起之后进行排序的,并不是组内排序
SELECT
department_id,
job_id,
avg( salary )
FROM
employees
GROUP BY
department_id,
job_id
ORDER BY
avg( salary ) DESC;















 538
538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











