







存储日志数据集(HDFS)
数据仓库构建(Hive)
数据分区表构建
数据预处理 (Spark计算引擎)-使用Zeppelin进行写SQL
订单指标分析
Sqoop数据导出到传统数据库(Mysql)
Superset数据可视化
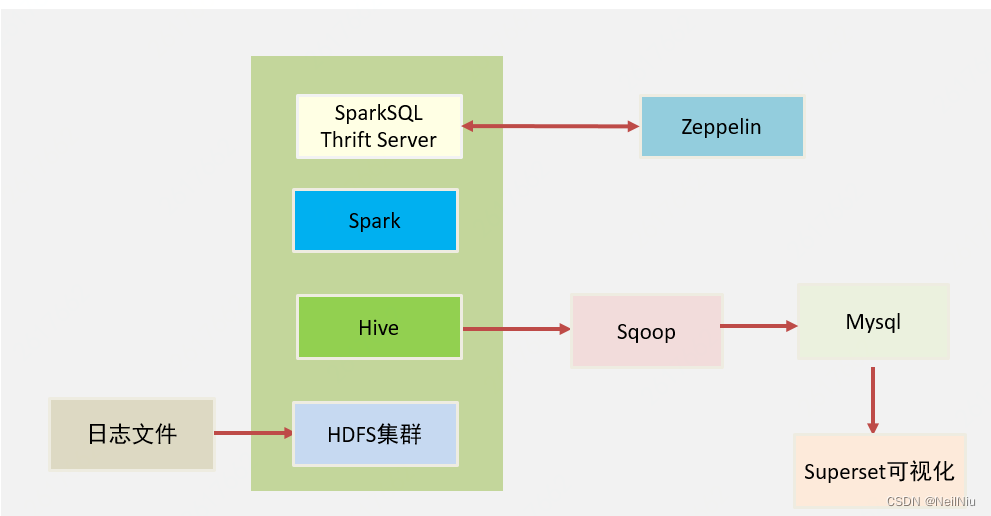
项目架构
架构方案:
1、基于Hadoop的HDFS(数据存储)文件系统来存储数据
2、为了方便进行数据分析,将这些日志文件的数据映射为一张一张的表,所以,我们 基于Hive(数据仓库工具)来构建数据仓库,所有的数据,都会在Hive下进行管理,提高数据处理的性能。
3、基于Spark(计算引擎)来进行数据开发,所有的应用程序都将运行在Spark集群上,这样可以保证数据被高性能的处理。
4、使用Zeppelin(在Zeppelin写SQL效率高,直接在终端写效率低)来快速将数据进行SQL指令交互。
5、使用Sqoop导出分析后的数据到传统型数据库(Mysql),便于后期应用
6、使用Superset(数据可视化工具)来实现数据可视化展示
架构图
一、数据仓库构建-数仓分层
首先将日志数据上传到HDFS保存下来,每天都可以上传,HDFS可以保存海量的数据,然后使用Hive,将HDFS中的数据文件,对应到Hive的表中。但是一般情况下日志数据是不能够直接进行分析的。所以需要我们对日志文件的原始数据进行预处理,才能进行分析。
我们会有这么几类数据考虑:
1、原始日志数据(业务系统中保存的日志文件数据)
2、预处理后的数据
3、分析结果数据
这些数据都通过Hive进行处理,因为Hive将数据映射为一张张的表,然后可以通过编写SQL来处理数据,简单、快捷、高效,为了区分以上这些数据,我们将这些数据对应的表分别保存在不同的数据库中。
为了方便组织、管理上面的三类数据,我们将数仓分为不同的层,简单来说,就是分别将三类不同的数据保存在Hive的不同数据中。
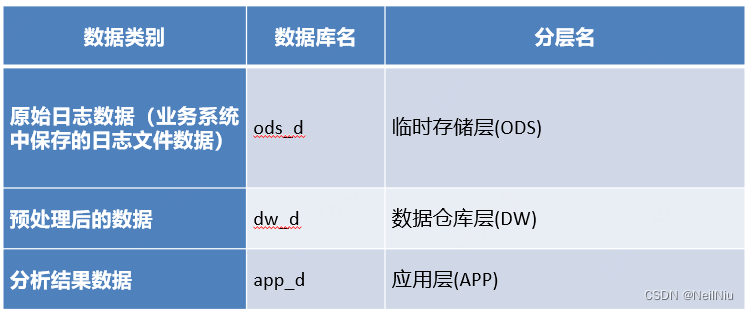
第一层临时存储层ODS,就是存储原始日志数据
第二层数据仓库层DW,就是存储预处理后的数据,就是分析的数据
第三层应用层APP。
根据数仓架构的三层,创建三个数据库,分别用来管理每一层的表数据。
-- 创建ods库
create database if not exists ods_d;
-- 创建dw库
create database if not exists dw_d;
-- 创建app库
create database if not exists app_d;二、数据分区表构建
1)、ods创建用户打车订单表
根据用户打车订单数据,创建按照日期分区的表:
2)、ods创建取消订单表
根据用户取消订单数据,创建按照日期分区的表
3)、ods创建订单表支付表
根据用户订单支付数据,创建按照日期分区的表
4)、ods创建用户评价表
根据用户评价数据,创建按照日期分区的表
5)、基于T+1的日期分区
大规模数据处理,必须要构建分区,每天都会进行分析,采用的是T+1模式。今天数据,第二天才能看到分析结果。
1、创建本地路径,上传日志文件
mkdir -p /export/data/test
2、通过load命令给表加载数据,并指定分区
load data local inpath '/export/data/test/order.csv' into table t_user_order partition(dt='2020-04-12');
三、数据预处理
数据预处理-用户订单处理
数据有了之后,需要对ods层中的数据进行预处理,数据预处理是数据仓库开发中的一个重要环节,主要目的是让预处理的数据更容易进行数据分析,并且能够将一些非法的数据处理掉,避免影响实际的统计结果。
预处理内容:
1、过滤掉order_time长度小于8的数据,如果小于8,表示这条数据不合法,不应该参加统计
2、将一些0,1表示的字段,处理为更容易理解的字段,例如:subscribe字段,0表示非预约,1表示预约,我们需要添加一个额外的字段,用来展示非预约和预约,这样分析的时候,便于看懂数据。
3、order_time字段为2020-4-12 1:15,为了将来更方便处理,统一使用类似2020-04-12 01:15来表示,这样所有的order_time字段长度是一样的,并且将日期获取出来。
4、为了方便将来按照年、月、日,小时统计,我们需要新增这些字段。
5、后续要分析一天内,不同时段的订单量,需要在预处理过程中将订单对应的时间段提前计算出来,例如:1:00-5:00为凌晨。
数据预处理-用户订单处理
1)、一天各个时段对应关系
2)、dw层创建宽表(宽表含义,要比ods层的表字段多)
在进行预处理之前,先把预处理之后保存数据的表创建出来。
3)、建宽表语句
create table if not exists dw_test_user_order_wide4)、预处理SQL语句
5)、HQL编好后,方便分析,需要将预处理的数据写入到之前创建的宽表中,注意:宽表也是一个分区表,所以,写入的时候要指定对应的分区。
四、订单指标分析-总订单笔数分析
数据处理好后,进行分析
1)、编写HQL语句
-- 计算4月12日总订单笔数
select
count(orderid) as total_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12’
;
订单指标分析-总订单笔数分析
2)、app层建表
数据分析后,每次都要处理大规模数据,每次处理都需要占用较长时间,所以,我们可以将计算好的数据,直接保存下来。将来,可以快速查询数据结果,所以需要在app层创建表,保存的数据为某天的总订单数,保存一下几个字段:
1、时间(哪天的订单总数)
2、订单总数
-- 创建保存日期对应订单笔数的app表
create table if not exists app_didi.t_order_total(
date string comment '日期(年月日)',
count integer comment '订单笔数'
)
partitioned by (month string comment '年月,yyyy-MM')
row format delimited fields terminated by ','
;
3)、加载数据到app层,
此处因为结果的数据不会很多,所以只需要基于年月来分区
insert overwrite table app_didi.t_order_total partition(month='2020-04')
select
'2020-04-12',count(orderid) as total_cnt
From dw_didi.t_user_order_wide
Where dt = '2020-04-12';
查询的结果,后面就可以做为可视化使用。
订单指标分析-预约订单/非预约订单占比分析
数据处理好后,就可以进行分析了。
1、编写HQL语句
select
subscribe_name,
count(*) as order_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
group by
subscribe_name
;
2、app层建表
包含几个字段:
日期、是否预约、订单数量
create table if not exists app_didi.t_order_subscribe_total(
date string comment '日期',
subscribe_name string comment '是否预约',
count integer comment '订单数量'
)
partitioned by (month string comment '年月,yyyy-MM')
row format delimited fields terminated by ','
;
3、加载数据到app表
insert overwrite table app_didi.t_order_subscribe_total partition(month = '2020-04')
select
'2020-04-12',
subscribe_name,
count(*) as order_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
group by
subscribe_name
;
订单指标分析-不同时段订单占比分析
1)、编写HQL语句
select
order_time_range,
count(*) as order_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
group by
order_time_range
;
2)、app层建表
create table if not exists app_didi.t_order_timerange_total(
date string comment '日期',
timerange string comment '时间段',
count integer comment '订单数量'
)
partitioned by (month string comment '年月,yyyy-MM')
row format delimited fields terminated by ','
;
3)、加载数据到app表
insert overwrite table app_didi.t_order_timerange_total partition(month = '2020-04')
select
'2020-04-12',
order_time_range,
count(*) as order_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
group by
order_time_range
;
订单指标分析-不同地域订单对比
1)、编写HQL语句
select
province,
count(*) as order_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
group by
province
;
2)、app层建表
create table if not exists app_didi.t_order_province_total(
date string comment '日期',
province string comment '省份',
count integer comment '订单数量'
)
partitioned by (month string comment '年月,yyyy-MM')
row format delimited fields terminated by ','
;
3)、加载数据到app表
insert overwrite table app_didi.t_order_province_total partition(month = '2020-04')
select
'2020-04-12',
province,
count(*) as order_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
group by
province
;
订单指标分析-不同年龄段/时段订单占比
1)、编写HQL语句
select
age_range,
order_time_range,
count(*) as order_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12’
group by
age_range,
order_time_range
;
2)、app层建表
create table if not exists app_didi. t_order_age_and_time_range_total (
date string comment '日期’,
age_range string comment '年龄段’,
order_time_range string comment '时段’,
count integer comment '订单数量’
)
partitioned by (month string comment '年月,yyyy-MM’)
row format delimited fields terminated by ',' ;
3)、加载数据到app表
insert overwrite table app_didi.t_order_age_and_time_range_total partition(month = '2020-04’)
select
‘2020-04-12’,
age_range,
order_time_range,
count(*) as order_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12’
group by age_range, order_time_range ;
select * from app_didi.t_order_age_and_time_range_total
五、Sqoop数据导出
在分析完核心指标后,需要将指标数据导出到mysql数据库中,便于后续的应用,例如指标的可视化。
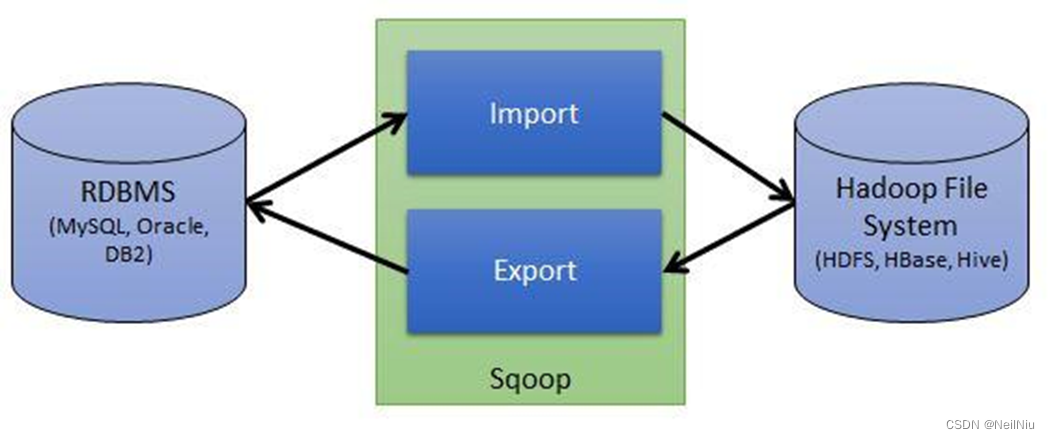
Apache Sqoop是在Hadoop生态体系和RDBMS体系之间传送数据的一个工具,来自于Apache
Hadoop生态系统包含:HDFS、Hive、Hbase等等
RDBMS体系包含:Mysql、Oracle、DB2等
Sqoop可以理解:“SQL到Hadoop 和Hadoop 到SQL”
安装Sqoop 1.4.7启动
#进入Sqoop安装目录
cd /export/server/sqoop-1.4.7
#验证sqoop是否工作
bin/sqoop list-databases \
--connect jdbc:mysql://192.168.88.100:3306/ \
--username root \
--password 123456
显示Mysql中所有的数据库
information_schema
hive
mysql
performance_schema
sysMysql创建目标表
1)、将数据从Hadoop生态体系导出到RDBMS数据库导出前,目标表必须存在于目标数据库中,所以我们必须先在Mysql中创建对应的目标数据库app_test
#创建目标数据库
create database if not exists app_didi;
#创建订单总笔数目标表
create table if not exists app_didi.t_order_total(
order_date date,
count int
);
#创建预约订单/非预约订单统计目标表
create table if not exists app_didi.t_order_subscribe_total(
order_date date ,
subscribe_name varchar(20) ,
count int
);
2)、在mysql中创建数据库和目标表
#创建不同时段订单统计目标表
create table if not exists app_didi.t_order_timerange_total(
order_date date ,
timerange varchar(20) ,
count int
);
#创建不同地域订单统计目标表
create table if not exists app_didi.t_order_province_total(
order_date date ,
province varchar(20) ,
count int
);
#创建不同年龄段,不同时段订单目标表
create table if not exists app_didi.t_order_age_and_time_range_total(
order_date date ,
age_range varchar(20) ,
order_time_range varchar(20) ,
count int
);
Sqoop数据导出
1)、将Hive中的结果表导出到mysql中
#导出订单总笔数表数据
bin/sqoop export \
--connect jdbc:mysql://192.168.88.100:3306/app_didi \
--username root \
--password 123456 \
# 导入到这个mysql中的表
--table t_order_total \
# 将HDFS中的表
--export-dir /user/hive/warehouse/app_didi.db/t_order_total/month=2020-04
#导出预约和非预约订单统计数据
bin/sqoop export \
--connect jdbc:mysql://192.168.88.100:3306/app_didi \
--username root \
--password 123456 \
# 导入到这个mysql中的表
--table t_order_subscribe_total \
# 将HDFS中的表
--export-dir /user/hive/warehouse/app_didi.db/t_order_subscribe_total/month=2020-04
Sqoop导出Hive结果表数据到Mysql
#导出不同时段订单统计表
bin/sqoop export \
--connect jdbc:mysql://192.168.88.100:3306/app_didi \
--username root \
--password 123456 \
--table t_order_timerange_total \
--export-dir /user/hive/warehouse/app_didi.db/t_order_timerange_total/month=2020-04
#导出不同地域订单统计表
bin/sqoop export \
--connect jdbc:mysql://192.168.88.100:3306/app_didi \
--username root \
--password 123456 \
# 导入到这个mysql中的表
--table t_order_province_total \
# 将HDFS中的表
--export-dir /user/hive/warehouse/app_didi.db/t_order_province_total/month=2020-04
#导出不同年龄段,不同时段订单目标表
bin/sqoop export \
--connect jdbc:mysql://192.168.88.100:3306/app_didi \
--username root \
--password 123456 \
# 导入到这个mysql中的表
--table t_order_age_and_time_range_total \
# 将HDFS中的表
--export-dir /user/hive/warehouse/app_didi.db/t_order_age_and_time_range_total/month=2020-04
六、Suerpset数据可视化
1)、Superset介绍
Superset是一个开源的企业级BI,它是目前开源的数据分析和可视化工具中比较好用的,功能简单,支持多种数据源、图标类型多、易维护、易二次开发。
2)、特点
1、丰富的数据可视化集
2、易于使用的界面,用于浏览和可视化数据
3、可提供身份验证。
Superset安装和启动
启动
superset run -h 192.168.88.100 -p 8099 --with-threads --reload --debugger
Superset建立数据源
1)、介绍
在启动完Superset之后,可以连接Mysql数据库
2)、连接
mysql的url地:mysql+pymysql://root:123456@192.168.88.100/app_didi?charset=utf8
分析指标可视化-订单总笔数可视化
1)、选择表数据源
2)、添加表连接

3)、设置表连接相关参数
4)、设置图标参数
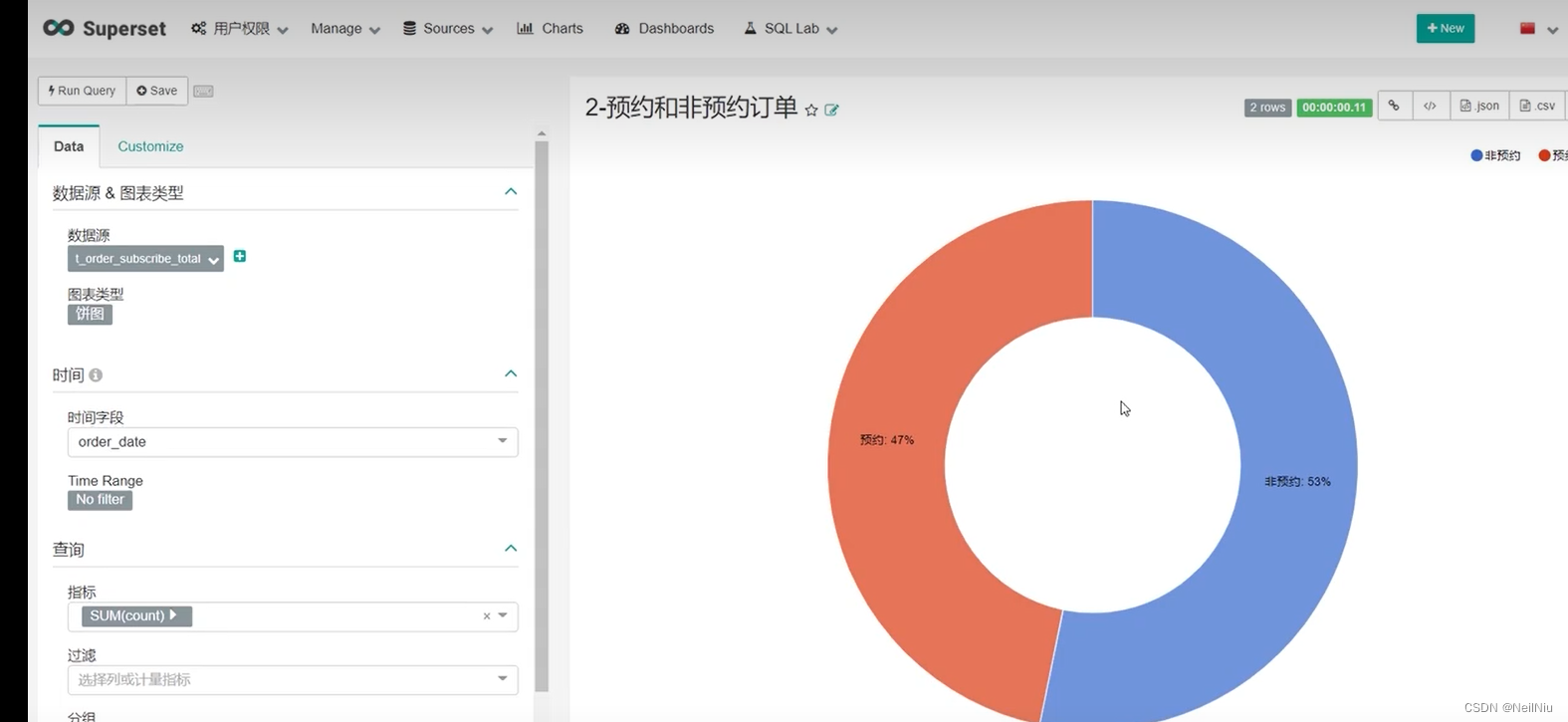
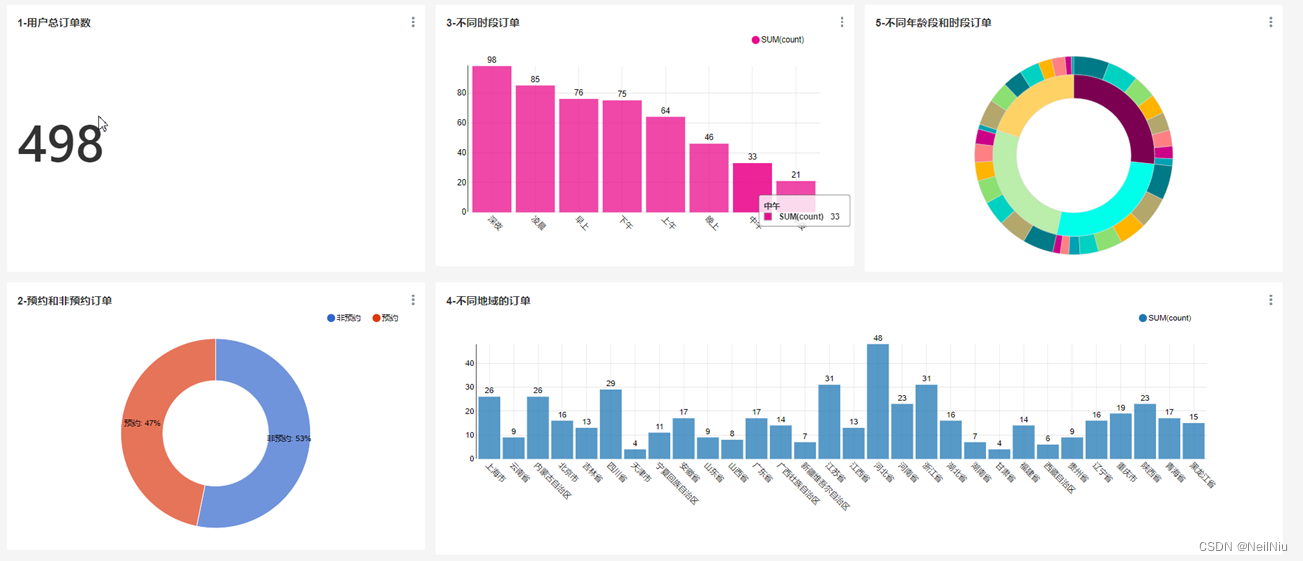
分析指标可视化-DashBoard看板开发
1)、实现步骤
1、创建看板
2、设置看板名字
3、进入看板
4、编辑看板
5、选择自定义看板
6、制作看板
7、调整看板
最终效果















 1279
1279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











