



一、基本认知
流程:数据获取、特征工程(最为重要)、建立模型、评估与应用
数据特征决定了模型的上限,预处理和特征提取是最核心的,算法和参数决定逼近这个上限
计算机视觉有面临的问题:物体遮蔽、背景混入等
传统机器算法ML,深度学习算法DL
深度学习专门用到计算机视觉上面的:主要有图像分类任务⬇
算法:k近邻--要检测数据和训练数据之间距离越近(检测数据变为矩阵,矩阵中的值为0-255,训练数据也一样,计算距离就是两个矩阵相减),那么检测数据就与训练数据相同,但是不能用于图像分类,因为k近邻不能分析出图片的主题是什么,所以有的时候把背景相同的数据归为一类,其实检测数据和训练数据根本就不同。
图片里面不同地方有着不同的重要性,这个就叫做权重参数。现在有一个线性函数(输入是图片和类别的权重参数,输出是给图片类别的估值),因为图片的每个地方都是不同的像素点,所以全都对应着不同的权重参数。
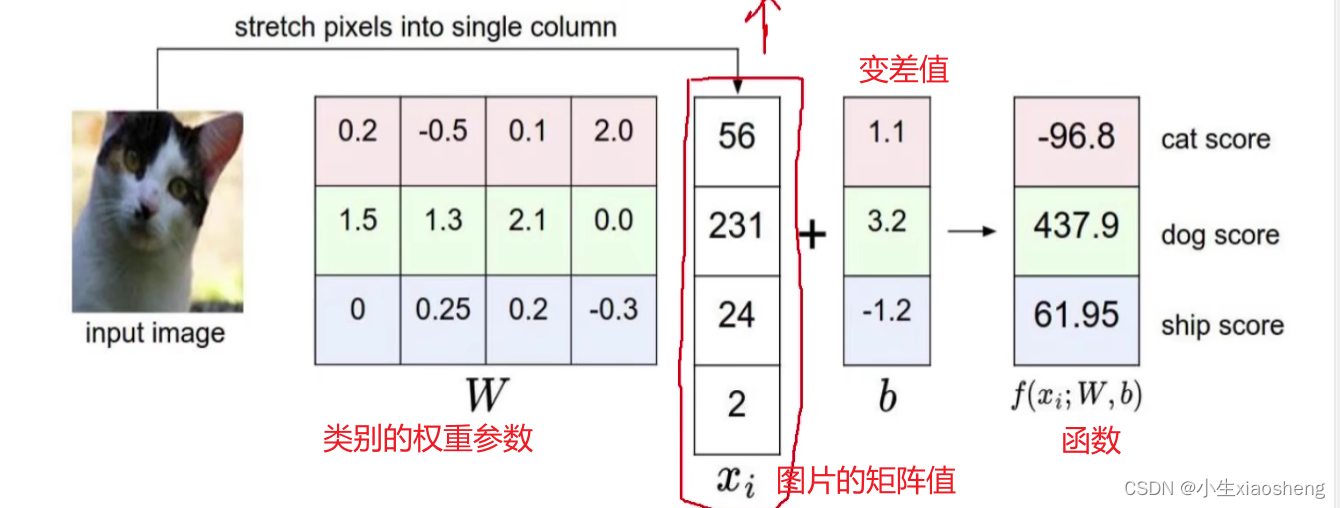
初始W是随机参数的,但是对于函数的影响是巨大的,所有要经过训练来改变W的值,而如何来判断因为W所产生的结果是好还是坏,所以要运用到损失函数,损失函数越大表示越可能出现错误判断,在进行损失函数计算的时候还要加上 λR(W),表示正则化惩罚项(存在W权重带来的损失),防止过拟合(在训练上loss很小,但是到了预测上loss就变大了)。
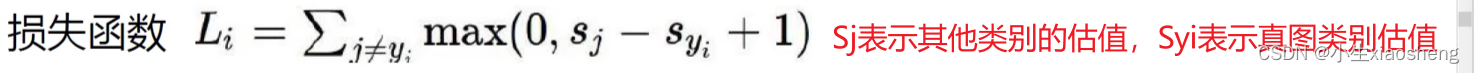
通过以上得到的输出是一个估值,在一定程度上是很难看出来区别的,所以这个时候引入softmax分类器,可以将估值转化为概率值,公式就是,当x往正无穷或者负无穷走的时候,这个公式的值都是在0-1之间。
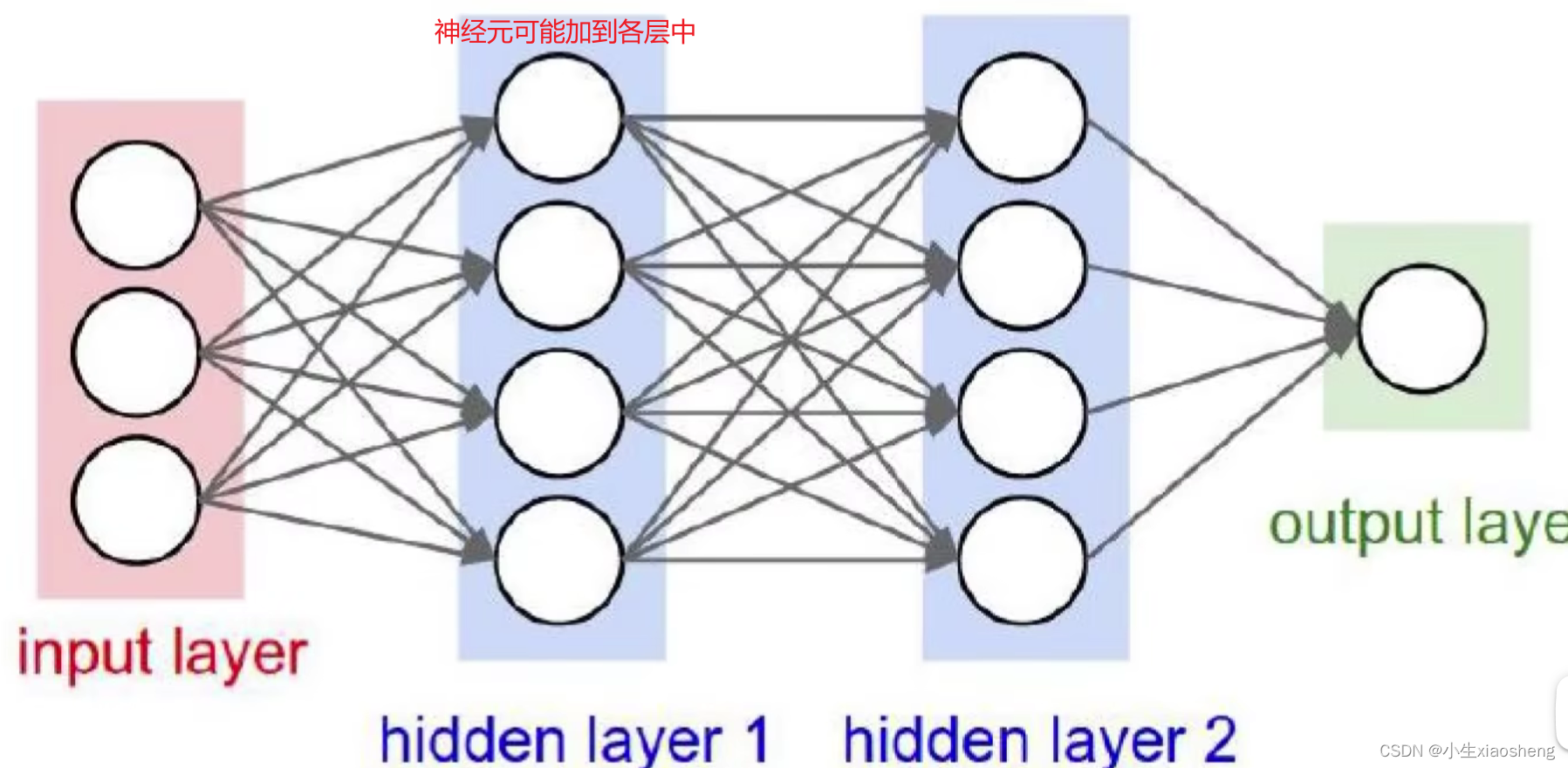
在网络整体框架里面,每层之间的矩阵维度之所以发生变化,是因为W权重产生发生了改变,X和W进行计算之后还是一个矩阵,这个时候就要进行非线性计算把矩阵变成一维向量。经过很多层之后W权重参数对于网络来说数量是巨大的。
神经元在理论上个数是越多越好,但是当个数过多的时候会出现过拟合的问题,因为是做全连接,看起来神经元是增加了一个,其实在增加了一组的输入和输出。
在计算loss的时候还考虑的 λR(W)正则表达式,如果 λ的值越小,那么对网络来说可能越精细,但是过小了就出现了过拟合,λ越大线段越平滑,而之越奇怪。
在网络中进行非线性变化就叫激活函数,激活函数主要有relu、sigmoid,激活函数就是找梯度(求导),但是sigmoid可能出现导师为0从而导致W不再更新,所以用relu用的多。
数据预处理是当我们拿到数据的时候不是直接放到网络中,而是线进行一些操作。
二、卷积神经网络CNN
卷积神经网络主要就是运用到计算机视觉上的,卷积神经网络的别称就叫CNN,神经网络是用于特征提取的,所以卷积神经网络也是来进行特征提取的。
可以用到检测任务、图像分类、检索相同数据、超分辨率重构、医学任务、标志识别等。
传统神经网络就是存在添加神经元的时候导致整个网络变的庞大,同时也可能存在过拟合的风险,所以出现了卷积神经网络。卷积层是提取特征,池化层是压缩特征,做卷积的时候也是权重乘以输入矩阵再加上偏差,一般卷积有几个通道,那么卷积完之后把几个通道里面的数值相加为最终结果。如果权重矩阵不同,那么得到的特征也就不同,这就是为什么特征图有多个的原因。卷积参数共享表示的就是权重参数是一样的,如果一个矩阵值对应一个权重参数,那么参数太多了。在整个神经网络中,经过一次卷积之后要加上relu非线性变化,两次卷积之后再池化,最后再来一个全连接。只有带未知参数的计算才算一层。经典网络架构VGG——conv-xxx、残差网络resnet。感受野的意思是下一个卷积层矩阵对应的一个值是上一层权重大小的矩阵数值整合得到的,权重的数量就是感受野,我们发现感受野大的比感受野小(但是数量多)的使用的参数数量要多,并且使用的relu数量也会变少。
三、递归神经网络RNN
递归神经网络主要就是运用到自然语言处理上,Word2Vec--把文字转换为向量,并且按照时间顺序进行依次排列。
传统神经网络不适合处理时序的输入,认为第一个输入的结果和第二个输入的结果是没有关系的,不会考虑各个序列之间的关系,每一步都是独立执行的,但是只是因为时间顺序不同,它们之前其实是有关系的,所以我们不能因为时序相关性对结果产生的影响,这个就是RNN网络在处理时序问题的体现。递归神经网络是在基础神经网络上的hidden layer层进行回归,这样前一个时间产生的特征矩阵也会影响后一个时刻产生的特征矩阵,但是这样也会出现一个问题就是后面的一个结果受前面所有的结果影响,当量变大的时候,这个是很没必要的。
传统以前都是使用RNN,不过现在使用的是LSTM,而LSTM就是在RNN上能够忘记一些前面的元素:C参数全局维护表示什么信息会被遗忘什么信息保留、门单元是让信息通过的方式由sigmoid(0-1之间的,0表示不能通过,1表示允许通过,中间小数值则就是概率通过)和乘法运算来控制、函数和时间
用于控制这个信息是否被丢弃。
Word2Vec词向量模型-算法是用来干什么的--语言的位置是关键的?如果一个词语在意思上和语句上表达的是一个意思那么在向量空间上是否的一样的?
一个词向量(理解为一个一维向量,向量的长度就是维度,向量里面的值通常在-1~1之间,具体的含义只有计算机自己能看懂了)通常的维度是较高的,而只要有了向量就可以计算两个向量的相似度,这样就能判断那些词语的意思可能是相近的,但是得先把所有的词向量构建好。当我们训练完得到一个词向量之后,就和其他词向量进行对比,发现较为接近那么可能该词向量就和接近词向量的意思一样。
网络模型:CBOW--输入是一段话的上下文,要输出上下文中间少的那个词语;skipgram--输入是中间词语,输出为这个词语的上下文。
那么该如何训练一个词向量呢?输入输出数据是一段话,比如先输入“我”再输入“吃”,那么输出得是“饭”,这个结果是我们想要的,输入的是词但是在计算机中词对应的是大向量,所以要有一个词向量表,输出是向量要转换成对应的词。向量表怎么来的?初始时就是一些随机向量,但是每次进行训练的时候会把这些向量进行更新。构建训练数据就是把一段话选择两个词输入得到一个词输出,然后往下走。在网络训练的时候不仅要更新权重参数,而且也要更新输入向量(词向量表)。

预测:如果一个词向量库稍微大一些,那么训练的结果到词向量里面找,最后一层就相当于softmax,这样计算起来太耗费时间了。所以如果输入两个词向量,输出为两个词连接的可能性,但是一个词后面有多种词所以可能造成全是1的结果,此时要设置负采样,如果一个词后面没有这个词那么就设置结果为0。怎么知道这个词后面该不该接这个词,这个是在模型训练的时候就已经设计好的,一个词后面可能接什么词语。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









