






有信息搜索策略
有信息搜索策略由于拥有启发式函数这一线索,使得其搜索路径不再漫无目的,从而可以更有效地找到解。
启发式函数可以表现为:h(n) = 从节点 n 的状态到目标状态的最小代价路径的代价估计值
(1)贪心最佳优先搜索Greedy Best-First Search
贪心最佳优先图搜索在有限状态空间中是完备的,但在无限状态空间中是不完备的。
所谓贪婪,即只扩展当前代价最小的节点(或者说离当前节点最近的点)。这样做的缺点就是,目前代价小,之后的代价不一定小,如果解在代价最大的点,那么按照贪婪最佳优先算法,可能就找不到这个解,然后就会陷入死循环。
其评价函数就是其代价函数本身。
(2)A*搜索
其评价函数为f(n) = g(n) + h(n)
其中f(n)是节点n的综合优先级。当我们选择下一个要遍历的节点时,我们总会选取综合优先级最高(值最小)的节点。g(n) 是节点n距离起点的代价。h(n)是节点n距离终点的预计代价,这也就是A*算法的启发函数。
即综合评价历史代价和下一步所需代价之和,该算法是完备的,但不一定是最优的,这取决于启发式函数的性质,如可容许性和一致性。(证明 反证法)
* 初始化open_set和close_set;
* 将起点加入open_set中,并设置优先级为0(优先级最高);
* 如果open_set不为空,则从open_set中选取优先级最高的节点n:
* 如果节点n为终点,则:
* 从终点开始逐步追踪parent节点,一直达到起点;
* 返回找到的结果路径,算法结束;
* 如果节点n不是终点,则:
* 将节点n从open_set中删除,并加入close_set中;
* 遍历节点n所有的邻近节点:
* 如果邻近节点m在close_set中,则:
* 跳过,选取下一个邻近节点
* 如果邻近节点m也不在open_set中,则:
* 设置节点m的parent为节点n
* 计算节点m的优先级
* 将节点m加入open_set中(3)搜索等值线
等值线方法可以可视化搜索策略的扩展过程,可以从图中看到,对于具有好的启发式函数的A*搜索,这个等值线会向着目标延申,同时,当启发式函数具有一致性时,路径的代价是单调递增的。
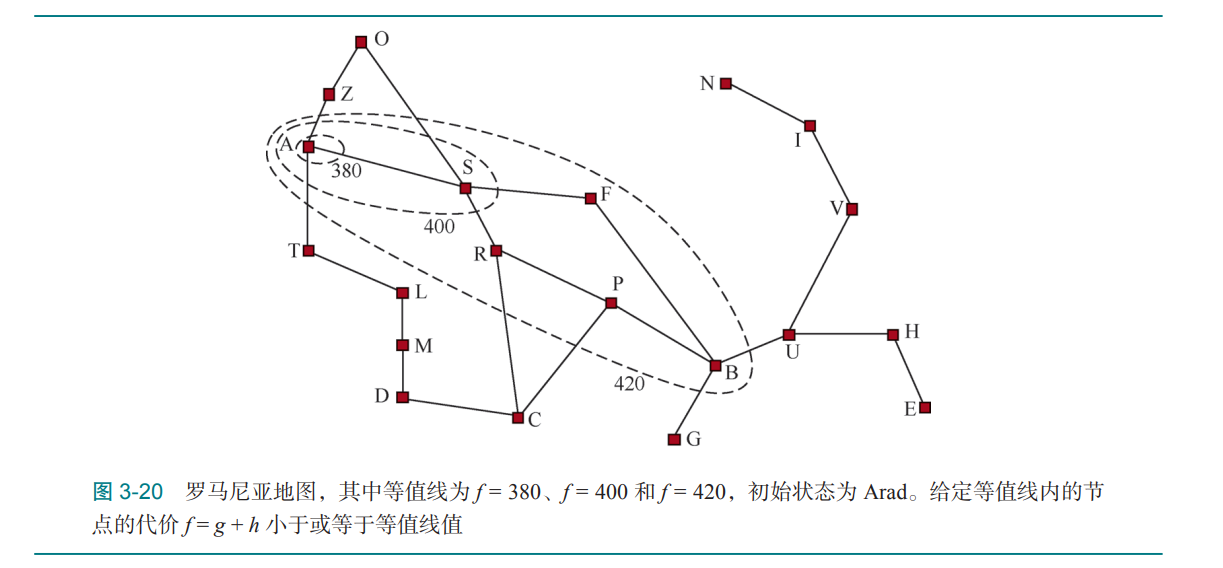
这样就可以保证其搜索策略不会扩展f(n)>C*的节点。
(但其在特殊情况下,搜索复杂度是极高的)
(4)满意搜索
如果我们允许 A* 搜索使用不可容许的启发式函数(inadmissible heuristic)(它可能会高估到达 某个目标的代价),那么我们就有可能错过最优解,但是该启发式函数可能更准确,从而减少 了需要扩展的节点数。
此时,这些解称为满意解。
加权A*搜索:对启发式函数的值增加更高的权重,f(n) = g(n) + W × h(n),其中 W>1。
但是“足够好”这个 标准根据问题而定,如有界次优搜索、有界代价搜索或无界代价搜索。
(5)内存受限搜索
常用措施包括只记录必要状态或删除无用状态。
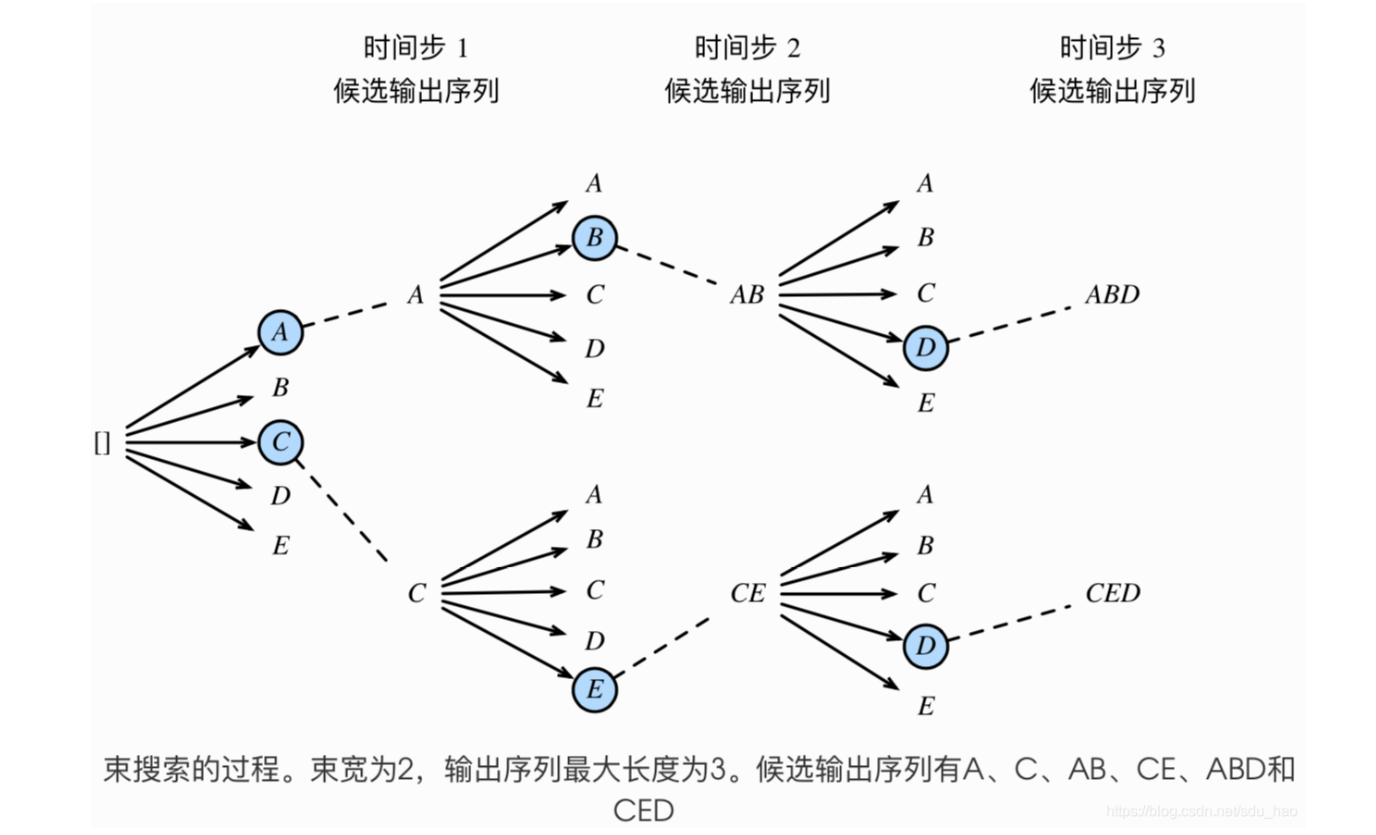
比较著名的策略是束搜索(如用在预训练模型的自然语言生成任务中)
束搜索(beam search)是对贪婪搜索的一个改进算法。它有一个束宽(beam size)超参数。我们将它设为k。在时间步1时,选取当前时间步条件概率最大的k个词,分别组成 k个候选输出序列的⾸词。在之后的每个时间步,基于上个时间步的k个候选输出序列,从k|Y|个可能的输出序列中选取条件概率最大的k个,作为该时间步的候选输出序列。最终,我们从各个时间步的候选输出序列中筛选出包含特殊符号“<eos>”的序列,并将它们中所有特殊符号“<eos>”后面的⼦序列舍弃,得到最终候选输出序列的集合。
迭代加深A*搜索:
IDA* 既拥有 A* 的优点,又不要求在内存中保留所有已达状态,这 样做的代价是需要多次访问某些状态。从而减少对内存的消耗
该算法在确定一个等值线后,只会找到一个刚好超过该等值线的节点,继而停止搜索。
递归最佳优先搜索:
RBFS:它的结构和递归深度优先搜索类似,但是它不会不确定地沿着当前路径继续,它用变量fimi跟踪记录从当前结点的祖先可得到的最佳可选路径的∫值。如果当前结点超过了这个限制,递归将回到可选路径上。
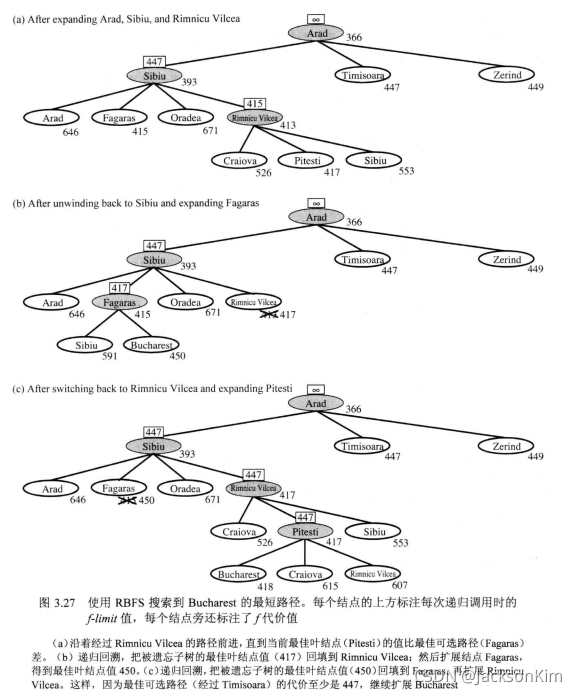
由于其过于节省内存,有可能会多次忘记必要节点的状态从而加大算法的重复率。
(6)双向启发式搜索
对于正向搜索(以初始状态作为根节点)中的节点,我们用 fF(n) = gF(n) + hF(n) 作为评价函数;对于反向搜索(以某个目标状态作为根节点)中的节点, 我们用 fB(n) = gB(n) + hB(n) 作为评价函数。
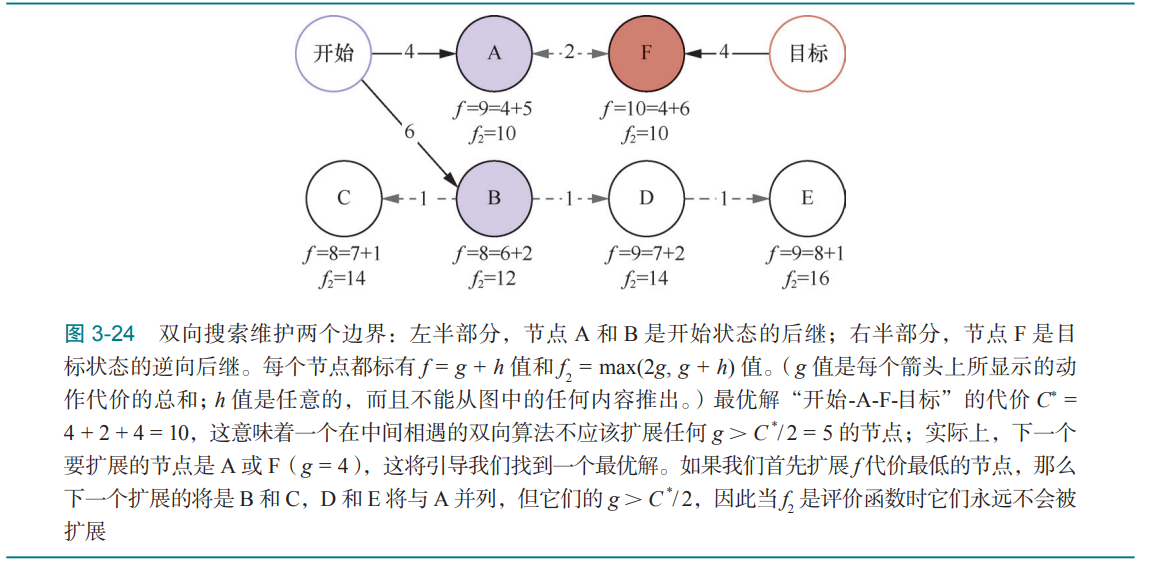
如果使用双向最佳优先算法,则选择节点的原则是不能扩展超过最优代价二分之一代价值得节点。
当启发函数较优但不是最佳时,这往往是一个有效的搜索策略。















 695
695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









