






分布式训练
模型参数和数据集规模的扩大使得单机运行难以进行,“内存墙”的存在使得多节点集群进行分布式训练的方式逐渐进入主流。
常见的并行策略
在分布式系统中,分为数据并行和模型并行两部分。
数据并行
每个设备上的模型是一致的,将数据 x x x切分为多个slice,最后将各自的输出拼接起来作为最后的输出。但在机器学习中,这会导致多个设备返回的梯度更新不一致,因此,常见的策略是进行AllReduce, 以确保各个设备上的模型始终保持一致。
模型较小时适合采取此种策略
模型并行
当模型很大,同步梯度的代价很大,甚至模型参数大到无法单机内存读取时,就需要应用模型并行策略解决问题。
模型并行需要进行一致性确认(数据角度的
因此对于通信的安全性和速度有要求。
流水并行
流水并行指将网络切为多个阶段,并分发到不同的计算设备上,各个计算设备之间以“接力”的方式完成训练。
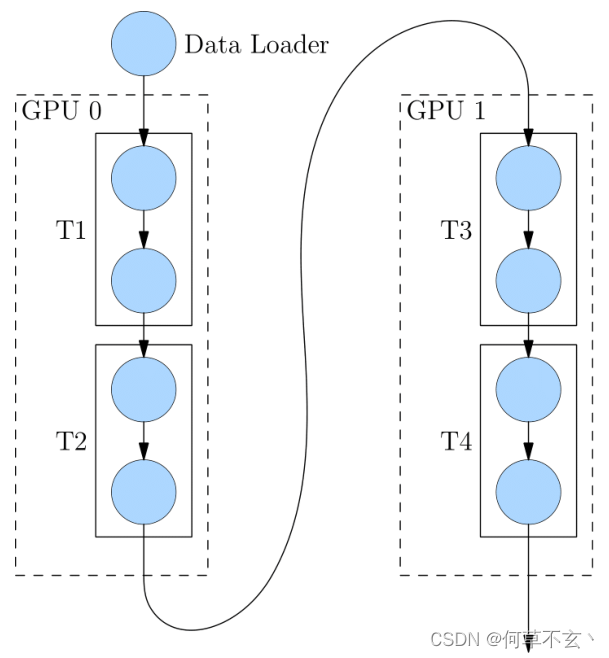
混合并行
GPT-3的并行方案是多种混用的。
它⾸先被分为 64 个阶段,进⾏流⽔并⾏。每个阶段都运⾏在 6 台DGX-A100 主机上。在6台主机之间,进⾏的是数据并⾏训练;每台主机有 8 张 GPU 显卡,同⼀台机器上的8张 GPU 显卡之间是进⾏模型并⾏训练。
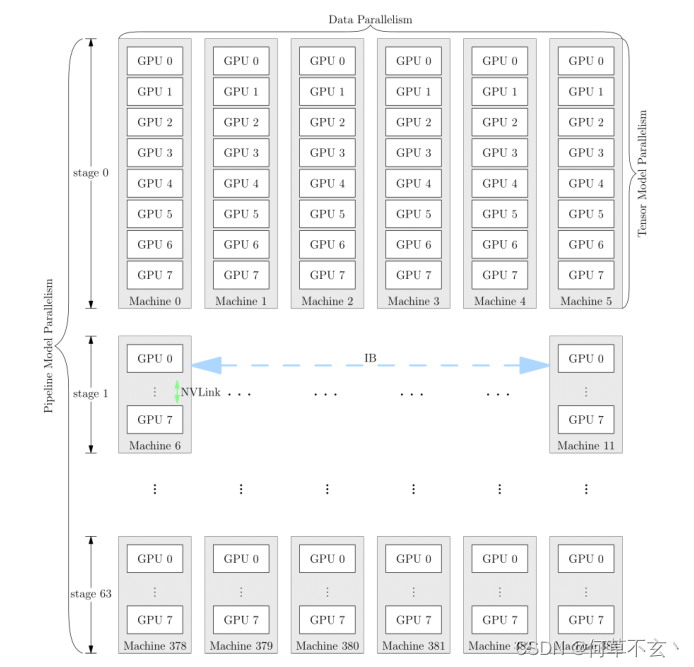















 1467
1467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









