







机器学习是什么?
通俗地讲,
机器学习
(
Machine Learning
,
ML
)
就是
让计算机从数据中进行自动学习,
得到某种知识
(
或规律
)
。
作为一门学科
,
机器学习通常指一类问题以及解决这类问题的方法,
即如何从观测数据
(
样本
)
中寻找规律
,
并利用学习到的规律(
模型
)对未知或无法观测的数据进行预测。
机器学习是从有限的观测数据中学习(
或
“
猜测
”)
出具有一般性的规律
,
并
可以将总结出来的规律推广应用到未观测样本上。
基本概念(样本、特征、标签、模型、学习算法等)
首先我们以一个生活中的例子来介绍机器学习中的一些基本概念:
样本
、
特征、
标签
、
模型
、
学习算法等
.
假设我们要到市场上购买芒果
,
但是之前毫无挑选芒果的经验,
那么如何通过学习来获取这些知识
?
首先,
我们从市场上随机选取一些芒果
,
列出每个芒果的
特征
(
Feature
)(
特征也可以称为
属性
(Attribute
)), 包括颜色、
大小
、
形状
、
产地
、
品牌
,
以及我们需要预测的
标签
(
Label
).
标签可以是连续值(
比如关于芒果的甜度
、
水分以及成熟度的综合打分
),
也可以是离散值(
比如
“
好
”“
坏
”
两类标签
)。
这里
,
每个芒果的标签可以通过直接品尝来获得
,也可以通过请一些经验丰富的专家来进行标记。
我们可以将一个标记好
特征
以及
标签
的芒果看作一个
样本
(
Sample
),
也经常称为
示例
(
Instance
)。 一组样本构成的集合称为
数据集
(
Data Set)。一般将数据集分为两部分: 训练集和测试集.
训练集
(
Training Set
)
中的样本是用来训练模型的
,
也叫
训练样本
(
Training Sample
),
而
测试集
(
Test Set
)
中的样本是用来检验模型好坏的,
也叫
测试样本
(
Test Sample
)。
我们通常用一个𝐷
维向量
𝒙 = [𝑥
1
, 𝑥
2
, ⋯ , 𝑥
𝐷
]
T
表示一个芒果的所有特征构成的向量,
称为
特征向量
(
Feature Vector
),
其中每一维表示一个特征。
并不是所有的样本特征都是数值型,需要通过转换表示为特征向量,而芒果的标签通常用标量𝑦
来表示。
假设训练集 𝒟
由
𝑁
个样本组成
,
其中每个样本都是
独立同分布的
(
Identically and Independently Distributed,
IID
),
即独立地从相同的数据分布中抽取的,
记为:
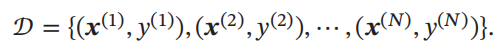
给定训练集𝒟
,
我们希望让计算机从一个函数集合
ℱ = {𝑓
1
(𝒙), 𝑓
2
(𝒙), ⋯}
中自动寻找一个“
最优
”
的
函数
𝑓
∗
(𝒙)
来近似每个样本的特征向量
𝒙
和标签
𝑦
之间的真实映射关系。
对于一个样本
𝒙
,
我们可以通过函数
𝑓
∗
(𝒙)
来预测其标签的值
或标签的条件概率
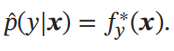
如何寻找这个“
最优
”
的函数
𝑓
∗
(𝒙)
是机器学习的关键
,
一般需要通过
学习算法
(
Learning Algorithm
)
𝒜
来完成
. 在 有 些 文 献 中,
学习算法也叫作
学习器
(Learner)。这个寻找过程通常称为
学习
(
Learning
) 或
训练
(
Training
)
过程。
这样,
下次从市场上买芒果
(
测试样本
)
时
,
可以根据芒果的特征
,
使用学习到的函数 𝑓
∗
(𝒙)
来预测芒果的好坏
.
为了评价的公正性
,
我们还是独立同分布地抽取一组芒果作为测试集 𝒟
′
,
并在测试集中所有芒果上进行测试
,
计算预测结果的准确率

其中𝐼(⋅)为指示函数,|𝒟′ |为测试集大小.
图1给出了机器学习的基本流程。对一个预测任务,输入特征向量为 𝒙,输出标签为𝑦,我们选择一个函数集合ℱ,通过学习算法𝒜和一组训练样本𝒟,从ℱ中学习到函数𝑓 ∗ (𝒙).这样对新的输入𝒙,就可以用函数𝑓 ∗ (𝒙)进行预测.

机器学习的三个基本要素(模型、学习准测、优化算法)
模型
对于一个机器学习任务,
首先要确定其输入空间
𝒳
和输出空间
𝒴
.
不同机器学习任务的主要区别在于输出空间不同.
在二分类问题中
𝒴 = {+1, −1}
,
在
𝐶
分类问题中𝒴 = {1, 2, ⋯ , 𝐶}
,
而在回归问题中
𝒴 = ℝ
.
输入空间 𝒳
和输出空间
𝒴
构成了一个样本空间。
对于样本空间中的样本(𝒙, 𝑦) ∈ 𝒳 × 𝒴,
假定
𝒙
和
𝑦
之间的关系可以通过一个未知的
真实映射函数
𝑦 = 𝑔(𝒙) 或
真实条件概率分布
𝑝
𝑟
(𝑦|𝒙)
来描述
.机器学习的目标是找到一个模型来近似真实映射函数
𝑔(𝒙)
或真实条件概率分布
𝑝
𝑟
(𝑦|𝒙)。
由于我们不知道真实的映射函数𝑔(𝒙)
或条件概率分布
𝑝
𝑟
(𝑦|𝒙)
的具体形式
, 因而只能根据经验来假设一个函数集合ℱ
,
称为
假设空间
(
Hypothesis Space
), 然后通过观测其在训练集 𝒟
上的特性
,
从中选择一个理想的
假设
(
Hypothesis
) 𝑓 ∗
∈ ℱ
.
假设空间ℱ
通常为一个参数化的函数族 ℱ = {𝑓(𝒙; 𝜃)|𝜃 ∈ ℝ^𝐷},
其中𝑓(𝒙; 𝜃)
是参数为
𝜃
的函数
,
也称为
模型
(
Model
),𝐷 为参数的数量
.
常见的假设空间可以分为线性和非线性两种,对应的模型
𝑓
也分别称为线性模型和非线性模型。
学习准则
损失函数
损失函数是一个非负实数函数,
用来量化模型预测和真实标签之间的差异。
下面介绍几种常用的损失函数。
0-1 损失函数
最直观的损失函数是模型在训练集上的错误率
,
即
0-1
损失函数
(0-1 Loss Function
):
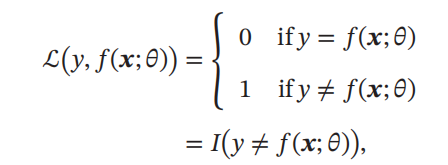
其中
𝐼(⋅)
是指示函数。
虽然0-1损失函数能够客观地评价模型的好坏,但其缺点是数学性质不是很好:不连续且导数为
0
,
难以优化
.
因此经常用连续可微的损失函数替代。
平方损失函数 平方损失函数
(
Quadratic Loss Function
)
经常用在预测标签𝑦 为实数值的任务中,
定义为
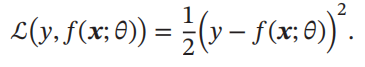
平方损失函数一般不适用于分类问题.
交叉熵损失函数 交叉熵损失函数
(Cross-Entropy Loss Function)一般用于分类问题.
假设样本的标签
𝑦 ∈ {1, ⋯ , 𝐶 } 为离散的类别,
模型
𝑓(𝒙; 𝜃) ∈ [0, 1]^𝐶 的输出为类别标签的条件概率分布,即
并满足
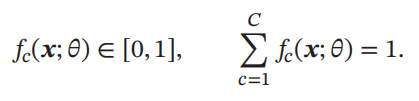

对于两个概率分布,
一般可以用交叉熵来衡量它们的差异.标签的真实分布 𝒚和模型预测分布𝑓(𝒙; 𝜃)之间的交叉熵为
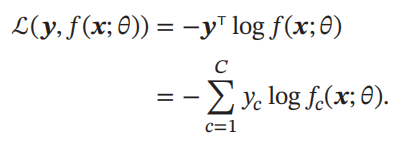
比如对于三分类问题,一个样本的标签向量为 𝒚 = [0, 0, 1]^T,模型预测的 标签分布为 𝑓(𝒙; 𝜃) = [0.3, 0.3, 0.4]^T,则它们的交叉熵为 −(0 × log(0.3) + 0 × log(0.3) + 1 × log(0.4)) = − log(0.4).
因为𝒚为one-hot向量,公式也可以写为
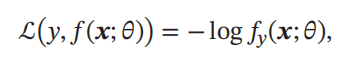
其中 𝑓𝑦
(𝒙; 𝜃)
可以看作真实类别 𝑦 的似然函数.因此,交叉熵损失函数也就是
负对数似然函数
(Negative Log-Likelihood)。
Hinge 损失函数
对于二分类问题
,
假设
𝑦
的取值为
{−1, +1}
,
𝑓(𝒙; 𝜃) ∈ ℝ
.
Hinge损失函数
(
Hinge Loss Function
)
为
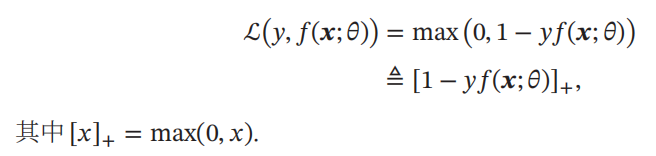
风险最小化准则

优化算法
在确定了训练集 𝒟、假设空间 ℱ 以及学习准则后,如何找到最优的模型 𝑓(𝒙, 𝜃∗ ) 就成了一个
最优化
(Optimization)问题
.
机器学习的训练过程其实就是最优化问题的求解过程。而最优化问题的求解过程就需要用优化算法来处理。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









