







CIFAR10模型搭建
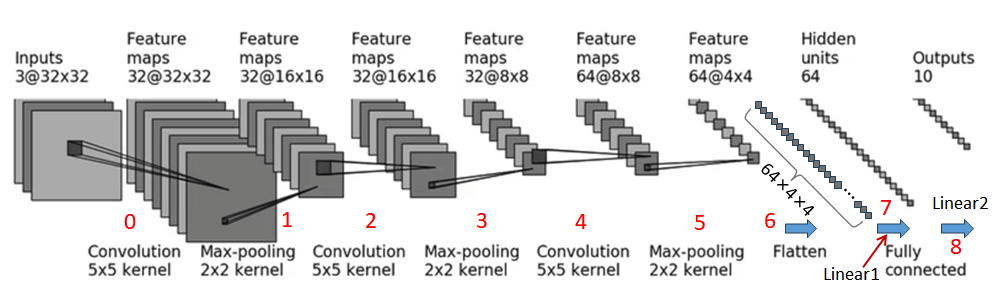
0. input : 3@32x32,3通道32x32的图片 --> 特征图(Feature maps) : 32@32x32
即经过32个3@5x5的卷积层,输出尺寸没有变化(有x个特征图即有x个卷积核。卷积核的通道数与输入的通道数相等,即3@5x5)。
两种方法推导出padding = 2、stride = 1的值:
•公式法:

𝐻𝑜𝑢𝑡=32,𝐻𝑖𝑛=32,dilation = 1(默认值,此时没有空洞),kernel_size = 5
•理论法:为保持输出尺寸不变,padding都是卷积核大小的一半,则有padding=kernel_size/2;奇数卷积核把中心格子对准图片第一个格子,卷积核在格子外有两层那么padding=2。
1.input : 32@32x32 --> output : 32@16x16
即经过2x2的最大池化层,stride = 2(池化层的步长为池化核的尺寸),padding = 0,特征图尺寸减小一半。
2.input : 32@16x16 --> output : 32@16x16
即即经过32个3@5x5的卷积层,输出尺寸没有变化。padding = 2、stride = 1。
3.input : 32@16x16 --> output : 32@8x8
即经过2x2的最大池化层,stride = 2,padding = 0,通道数不变,特征图尺寸减小一半。
4.input : 32@8x8 --> output : 64@8x8
即即经过64个3@5x5的卷积层,输出尺寸没有变化。padding = 2、stride = 1。
5.input : 64@8x8 --> output : 64@4x4
即经过2x2的最大池化层,stride = 2,padding = 0,通道数不变,特征图尺寸减小一半。
6.input:64@4x4-->output :1×1024
即经过展平层 Flatten 作用,将64@4x4的特征图依次排开。
7.input:1×1024-->output :1×64
即经过线性层Linear1的作用。
8.input:1×64-->output:1×10
即经过线性层Linear2的作用。
代码验证:
按照网络结构一层一层搭建网络结构。
示例1:
# 导入需要用到的库
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
# 搭建CIFAR10模型网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(3, 32, 5, padding=2) # 第一个卷积层
self.maxpool1 = MaxPool2d(2) # 第一个最大池化层
self.conv2 = Conv2d(32, 32, 5, padding=2) # 第二个卷积层
self.maxpool2 = MaxPool2d(2) # 第二个最大池化层
self.conv3 = Conv2d(32, 64, 5, padding=2) # 第三个卷积层
self.maxpool3 = MaxPool2d(2) # 第三个最大池化层
self.flatten = Flatten() # 展平层
# 两个线性层
self.linear1 = Linear(1024, 64) # 第一个线性层
self.linear2 = Linear(64, 10) # 第二个线性层
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
tudui = Tudui() # 实例化
print(tudui) # 观察网络信息
input = torch.ones((64, 3, 32, 32)) # 为网络创建假想输入,目的是检查网络是否正确
output = tudui(input) # 输出
print(output.shape) # torch.Size([64, 10]),结果与图片结果一致
运行结果:
# 两个print出的内容分别为:
Tudui(
(conv1): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear1): Linear(in_features=1024, out_features=64, bias=True)
(linear2): Linear(in_features=64, out_features=10, bias=True)
)
torch.Size([64, 10])
Sequential的使用
当模型中只是简单的前馈网络时,即上一层的输出直接作为下一层的输入,这时可以采用torch.nn.Sequential()模块来快速搭建模型,而不必手动在forward()函数中一层一层地前向传播。因此,如果想快速搭建模型而不考虑中间过程的话,推荐使用torch.nn.Sequential()模块。
接下来用torch.nn.Sequential()改写示例 1,示例 2 如下。
示例2:
# 导入需要用到的库
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
# 搭建CIFAR10模型网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2), # 第一个卷积层
MaxPool2d(2), # 第一个最大池化层
Conv2d(32, 32, 5, padding=2), # 第二个卷积层
MaxPool2d(2), # 第二个最大池化层
Conv2d(32, 64, 5, padding=2), # 第三个卷积层
MaxPool2d(2), # 第三个最大池化层
Flatten(), # 展平层
# 两个线性层
Linear(1024, 64), # 第一个线性层
Linear(64, 10) # 第二个线性层
)
def forward(self, x):
x = self.model1(x)
return x
tudui = Tudui() # 实例化
print(tudui) # 观察网络信息
input = torch.ones((64, 3, 32, 32)) # 为网络创建假想输入,目的是检查网络是否正确
output = tudui(input) # 输出
print(output.shape) # torch.Size([64, 10]),结果与图片结果一致
运行结果:
# 两个print出来的结果分别为:
Tudui(
(model1): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
torch.Size([64, 10])我们发现,使用Sequential之后得到的结果(示例2)与按照前向传播一层一层搭建得到的结果(示例1)一致,使用Sequential之后可以使得forward函数中的内容得以简化。
使用tensorboard实现网络结构可视化
# 导入需要用到的库
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.tensorboard import SummaryWriter
# 搭建CIFAR10模型网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(3, 32, 5, padding=2) # 第一个卷积层
self.maxpool1 = MaxPool2d(2) # 第一个最大池化层
self.conv2 = Conv2d(32, 32, 5, padding=2) # 第二个卷积层
self.maxpool2 = MaxPool2d(2) # 第二个最大池化层
self.conv3 = Conv2d(32, 64, 5, padding=2) # 第三个卷积层
self.maxpool3 = MaxPool2d(2) # 第三个最大池化层
self.flatten = Flatten() # 展平层
# 两个线性层
self.linear1 = Linear(1024, 64) # 第一个线性层
self.linear2 = Linear(64, 10) # 第二个线性层
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
tudui = Tudui() # 实例化
print(tudui) # 观察网络信息
input = torch.ones((64, 3, 32, 32)) # 为网络创建假想输入,目的是检查网络是否正确
output = tudui(input) # 输出
print(output.shape) # torch.Size([64, 10]),结果与图片结果一致
# 使用tensorboard实现网络可视化
writer = SummaryWriter("./log_sequential")
writer.add_graph(tudui, input)
writer.close()
运行上述代码,则会在项目文件夹CIFAR10model中出现对应的日志文件夹log_sequential。

随后打开Terminal,如下图所示。

输入tensorboard --logdir=log_sequential,如下图所示。

按下Enter键,得到一个网址,如下图所示。
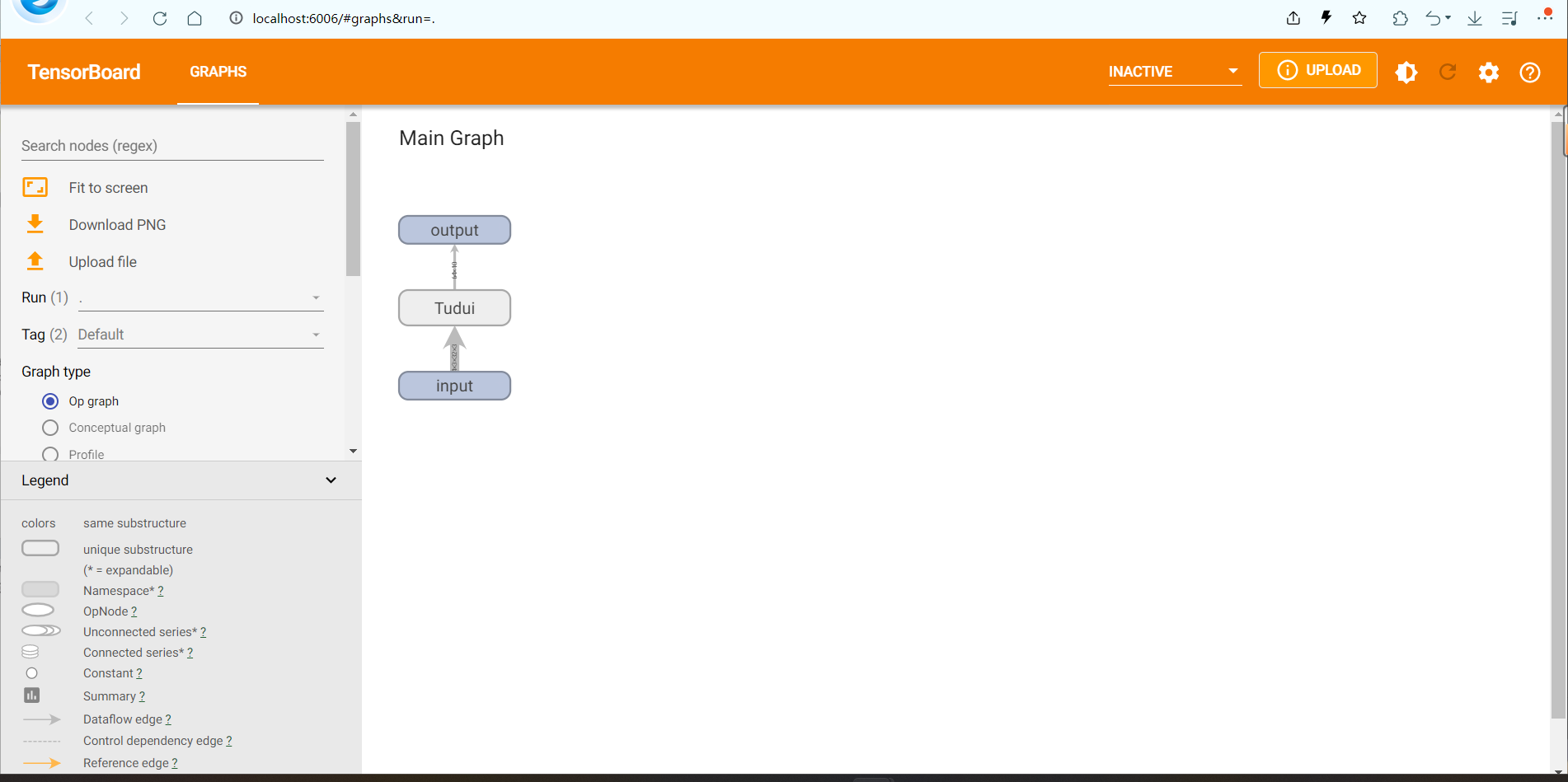
 打开这个网址,得到可视化界面。
打开这个网址,得到可视化界面。
我们点开搭建好的网络Tudui,可以得到更具体的网络每一层,如下图所示。
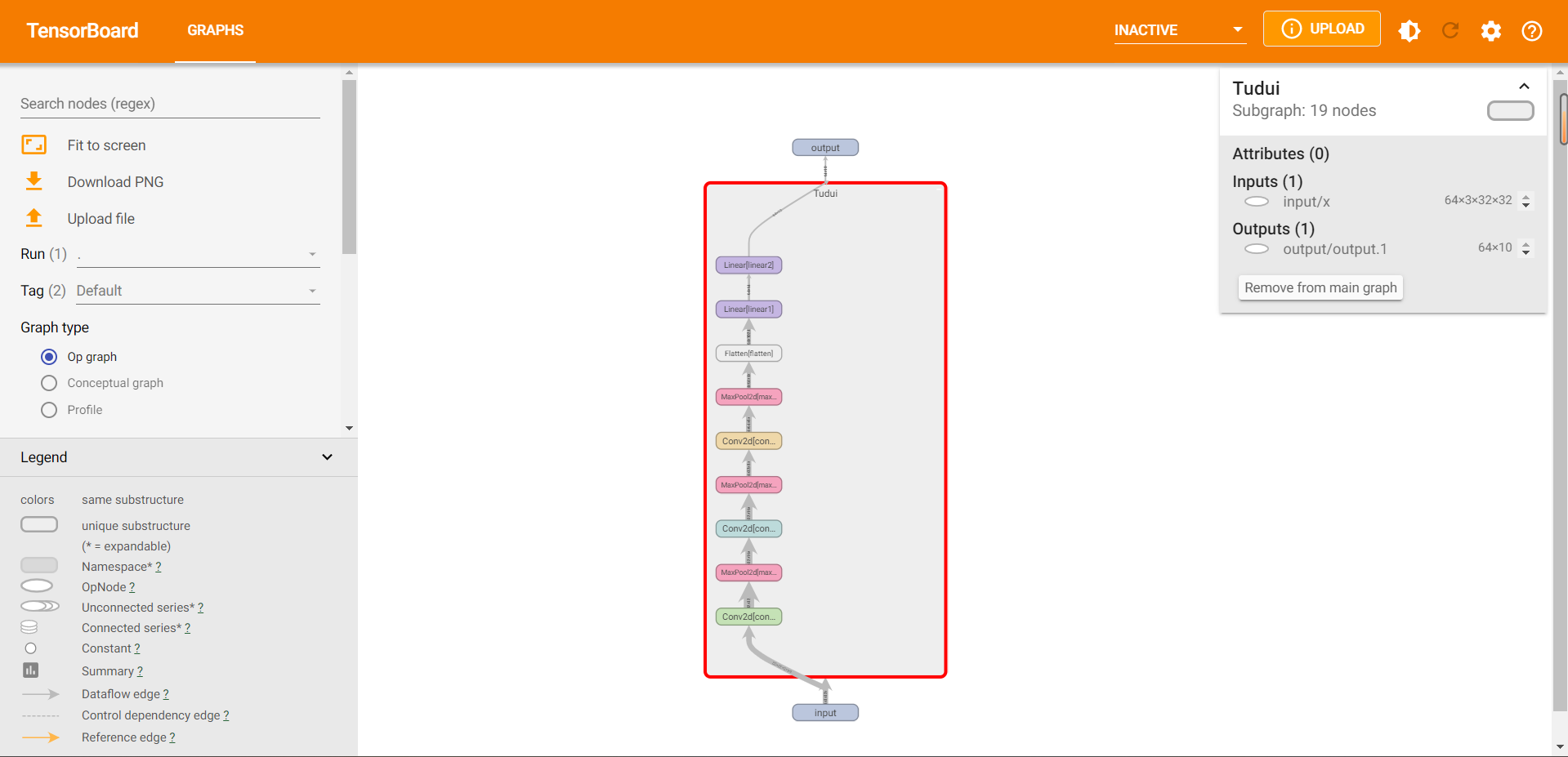
我们将其放大,如下图所示。















 5711
5711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









