







目录
MongoDB介绍
MongoDB是一个文档数据库(以JSON为数据模型),由C++语言编写。
MongoDB的数据是存储在硬盘上的,只不过需要操作的数据会被加载到内存中提高效率,所以MongoDB本身很吃内存。
(本文章使用4.x版本,自带分布式事务)
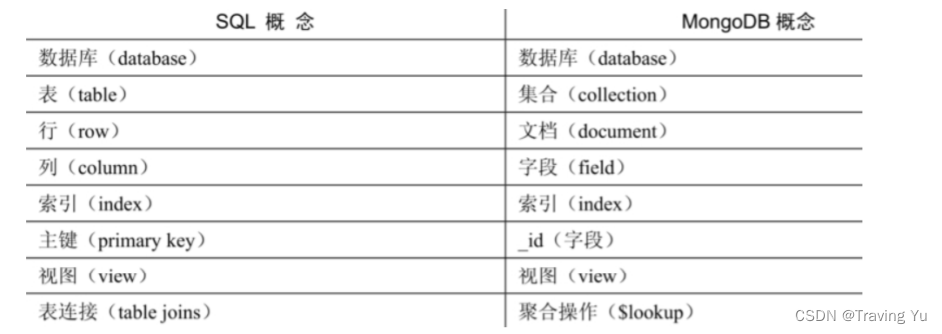
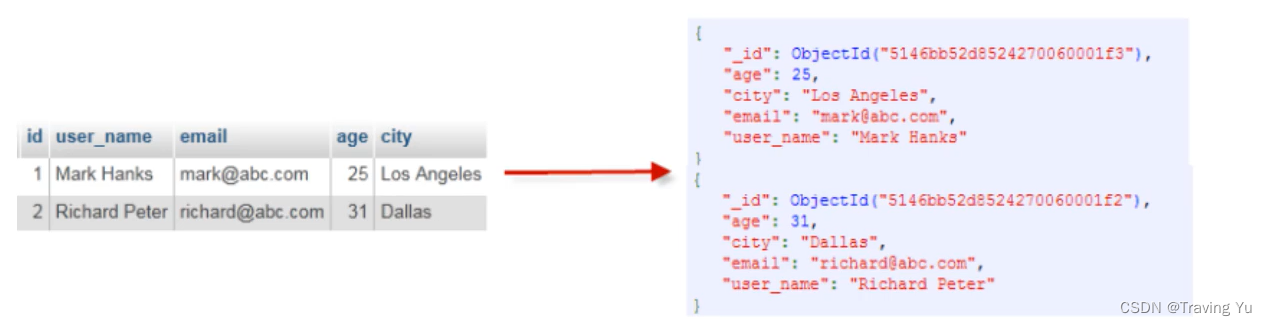
MongoDB技术优势
MongoDB基于灵活的JSON文档模型,非常适合敏捷式快速开发。与此同时,其与生俱来的高可用、高水平扩展能力使它在处理海量、高并发数据应用时颇具优势。
如何考虑是否选择MongoDB?
没有某个业务场景必须要使用MongoDB才能解决,但使用MongoDB通常能让你以更低的成本解决问题。如果你不清楚当前业务是否适合使用MongoDB,可以通过做几道选择题来辅助决策。
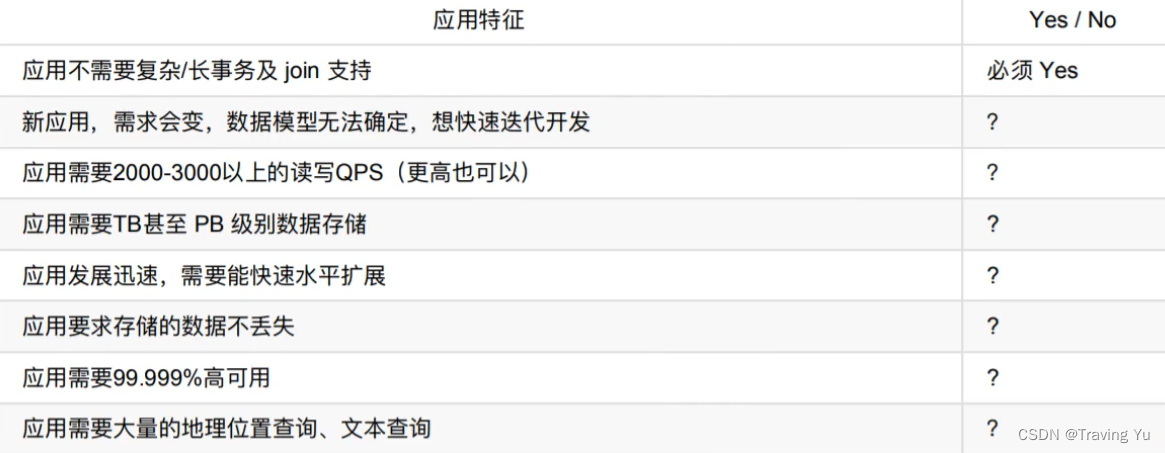
只要有一项需求满足就可以考虑使用MongoDB,匹配越多,选择MongoDB越合适
MongoDB安装
使用命令参数启动服务
#下载MongoDB
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.4.9.tgz
tar -zxvf mongodb-linux-x86_64-rhel70-4.4.9.tgz
启动:
#创建dbpath和logpath
mkdir -p /mongodb/data /mongodb/log /mongodb/conf
#进入mongodb目录,启动mongodb服务
bin/mongod --port=27017 --dbpath=/mongodb/data --
logpath=/mongodb/log/mongodb.log \
--bind_ip=0.0.0.0 --fork
–dbpath :指定数据文件存放目录
–logpath :指定日志文件,注意是指定文件不是目录
–logappend :使用追加的方式记录日志
–port:指定端口,默认为27017
–bind_ip:默认只监听localhost网卡
–fork: 后台启动
–auth: 开启认证模式
使用配置文件启动服务
编辑/mongodb/conf/mongo.conf文件,内容如下:
systemLog:
destination: file
path: /mongodb/log/mongod.log # log path
logAppend: true
storage:
dbPath: /mongodb/data # data directory
engine: wiredTiger #存储引擎
journal: #是否启用journal日志
enabled: true
net:
bindIp: 0.0.0.0
port: 27017 # port
processManagement:
fork: true
启动:
mongod -f /mongodb/conf/mongo.conf
关闭MongoDB服务
方式1:
mongod --port=27017 --dbpath=/mongodb/data --shutdown
方式2:
进入mongo shell
use admin
db.shutdownServer()
Mongo shell使用
mongo是MongoDB的交互式JavaScript Shell界面,mongo shell是基于JavaScript语法的,它为系统管理员提供了强大的界面,并为开发人员提供了直接测试数据库查询和操作的方法。
mongo --port=27017
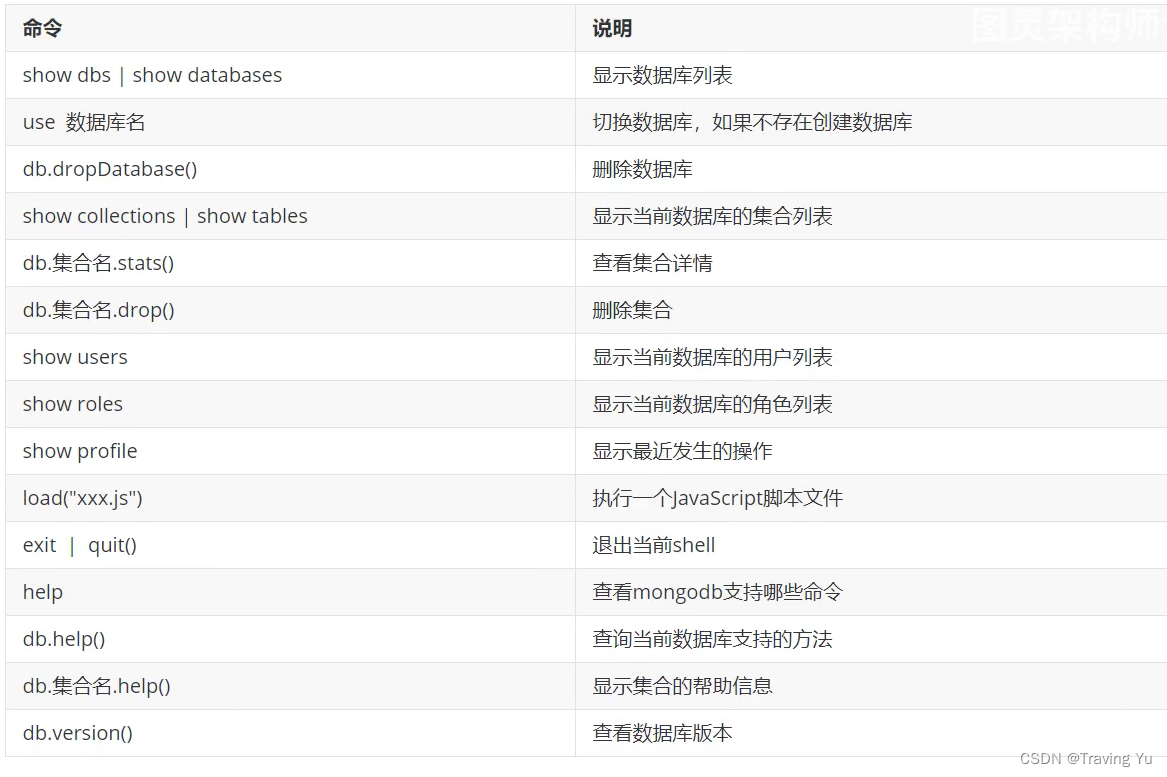
创建集合语法
db.createCollection(name, options)
options参数
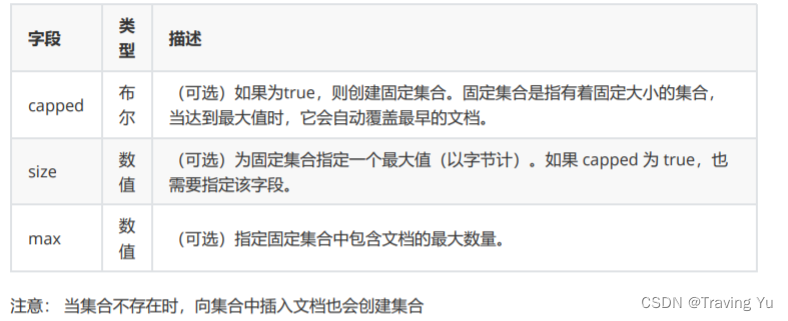
安全认证模式启动
常用权限
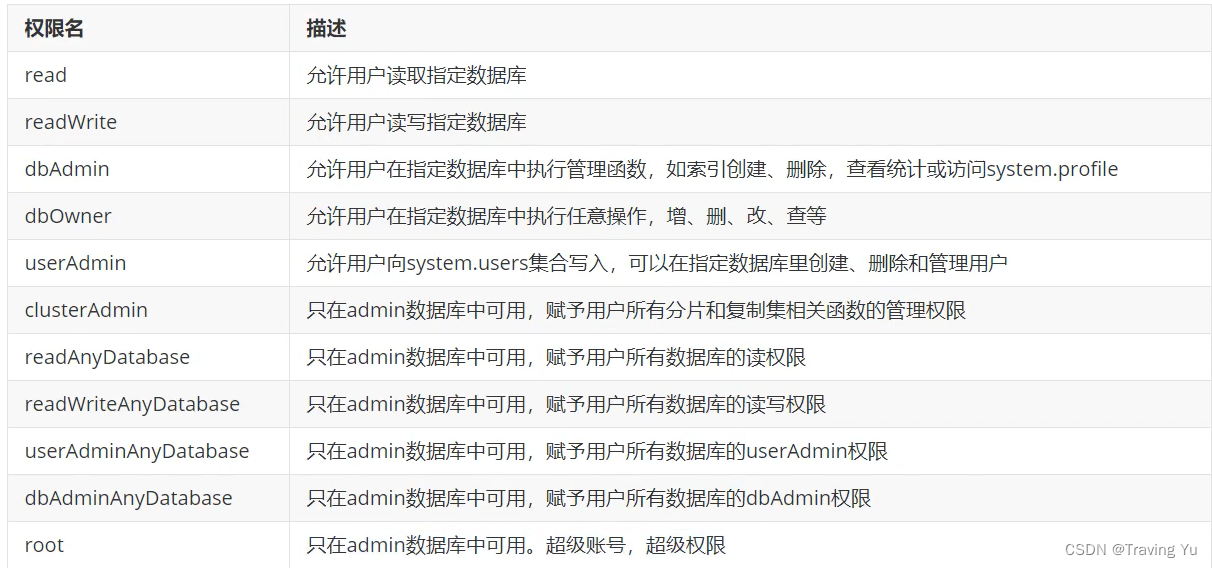
创建管理员账号
# 设置管理员用户名密码需要切换到admin库
use admin
#创建管理员
db.createUser({user:"fox",pwd:"fox",roles:["root"]})
# 查看所有用户信息
show users
#删除用户
db.dropUser("fox")
创建应用数据库用户
use appdb
db.createUser({user:"appdb",pwd:"fox",roles:["dbOwner"]})
默认情况下,MongoDB不会启用鉴权,以鉴权模式启动MongoDB
mongod -f /mongodb/conf/mongo.conf --auth
启用鉴权之后,连接MongoDB的相关操作都需要提供身份认证。
mongo 192.168.65.174:27017 -u fox -p fox --authenticationDatabase=admin
MongoDB文档操作
插入文档
- insert: 若插入的数据主键已经存在,则会抛 DuplicateKeyException 异常,提示主键重复,不保存当前数据。
- save: 如果 _id 主键存在则更新数据,如果不存在就插入数据
db.collection.insertOne({x:1})
使用JS脚本插入:
编辑脚本book.js
进入mongo shell,执行load("books.js")
查询文档
db.collection.find(query, projection)
- query :可选,使用查询操作符指定查询条件
- projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。投影时,id为1的时候,其他字段必须是1;id是0的时候,其他字段可以是0;如果没有_id字段约束,多个其他字段必须同为0或同为1。
如果查询返回的条目数量较多,mongo shell则会自动实现分批显示。默认情况下每次只显示20条,可以输入it命令读取下一批。
条件查询:
#查询带有nosql标签的book文档:
db.books.find({tag:"nosql"})
#按照id查询单个book文档:
db.books.find({_id:ObjectId("61caa09ee0782536660494d9")})
#查询分类为“travel”、收藏数超过60个的book文档:
db.books.find({type:"travel",favCount:{$gt:60}})
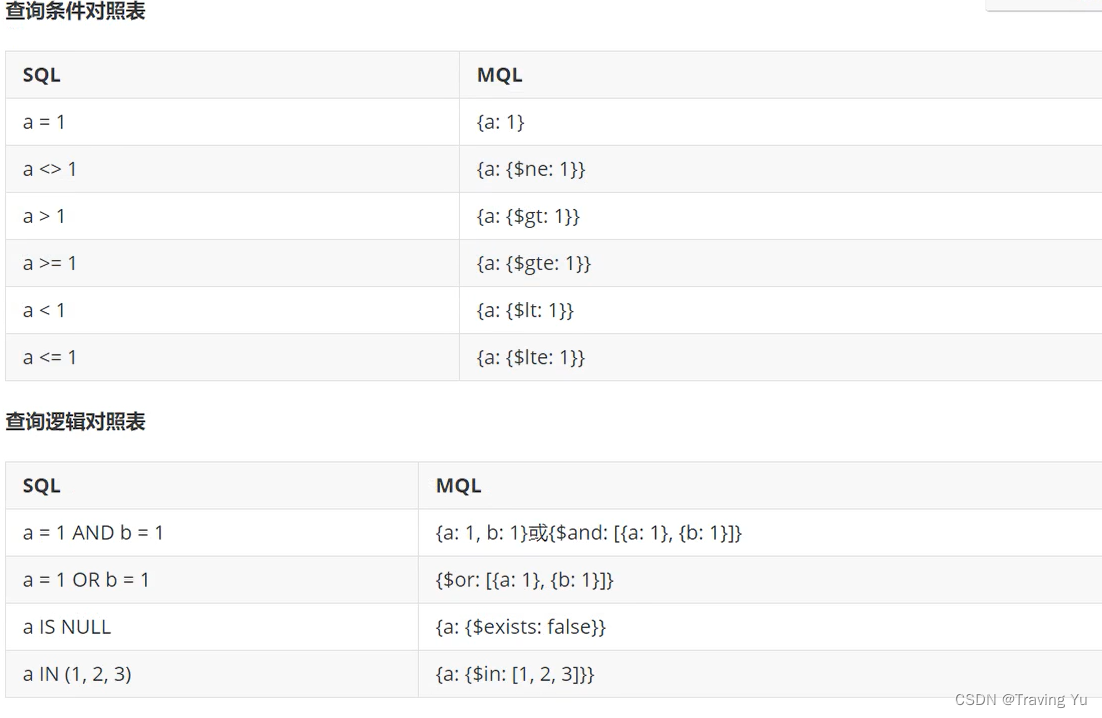

指定排序:
#指定按收藏数(favCount)降序返回
db.books.find({type:"travel"}).sort({favCount:-1})
分页查询:
db.books.find().skip(8).limit(4)
正则表达式匹配查询:
//使用正则表达式查找type包含 so 字符串的book
db.books.find({type:{$regex:"so"}})
//或者
db.books.find({type:/so/})
更新文档
db.collection.update(query,update,options)
- query:描述更新的查询条件;
- update:描述更新的动作及新的内容;
- options:描述更新的选项
– upsert: 可选,如果不存在update的记录,是否插入新的记录。默认false,不插入
– multi: 可选,是否按条件查询出的多条记录全部更新。 默认false,只更新找到的第一条记录
– writeConcern :可选,决定一个写操作落到多少个节点上才算成功。
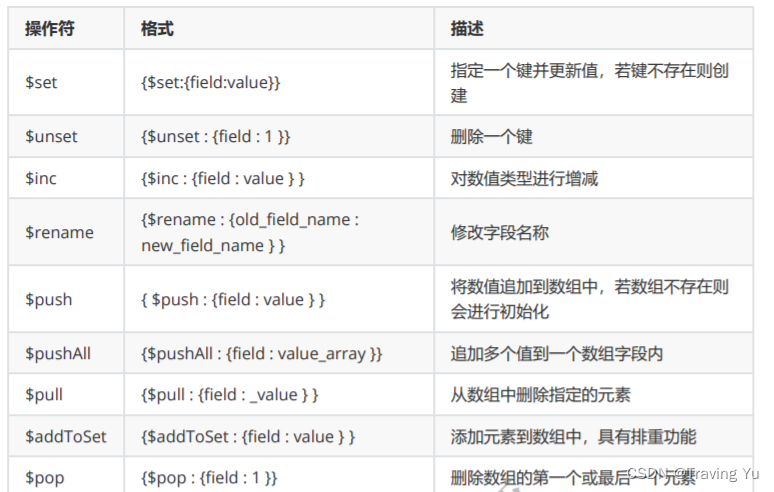
删除文档
db.user.remove({age:28})// 删除age 等于28的记录
db.user.remove({age:{$lt:25}}) // 删除age 小于25的记录
db.user.remove( { } ) // 删除所有记录
db.user.remove() //报错
db.books.deleteMany ({}) //删除集合下全部文档
db.books.deleteMany ({ type:"novel" }) //删除 type等于 novel 的全部文档
db.books.deleteOne ({ type:"novel" }) //删除 type等于novel 的一个文档
SpringBoot整合MongoDB
-
引入依赖
<!--spring data mongodb--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-mongodb</artifactId> </dependency> -
配置springboot配置文件
spring: data: mongodb: uri: mongodb://fox:fox@192.168.65.174:27017/test?authSource=admin #uri等同于下面的配置 #database: test #host: 192.168.65.174 #port: 27017 #username: fox #password: fox #authentication-database: admin -
使用时注入mongoTemplate
@Autowired MongoTemplate mongoTemplate;
创建实体类

@Document("emp") //对应emp集合中的一个文档
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Employee {
@Id //映射文档中的_id
private Integer id;
@Field("username")
private String name;
@Field
private int age;
@Field
private Double salary;
@Field
private Date birthday;
}
添加文档
insert方法返回值是新增的Document对象,里面包含了新增后id的值。如果集合不存在会自动创建集合。通过Spring Data MongoDB还会给集合中多加一个class的属性,存储新增时Document对应Java中类的全限定路径。这么做为了查询时能把Document转换为Java类型
@Test
public void testInsert(){
Employee employee = new Employee(1, "小明", 30,10000.00, new Date());
//添加文档
// sava: _id存在时更新数据
//mongoTemplate.save(employee);
// insert: _id存在抛出异常 支持批量操作
mongoTemplate.insert(employee);
List<Employee> list = Arrays.asList(
new Employee(2, "张三", 21,5000.00, new Date()),
new Employee(3, "李四", 26,8000.00, new Date()),
new Employee(4, "王五",22, 8000.00, new Date()),
new Employee(5, "张龙",28, 6000.00, new Date()),
new Employee(6, "赵虎",24, 7000.00, new Date()),
new Employee(7, "赵六",28, 12000.00, new Date()));
//插入多条数据
mongoTemplate.insert(list,Employee.class);
}
查询文档
Criteria是标准查询的接口,可以引用静态的Criteria.where的把多个条件组合在一起,就可以轻松地将多个方法标准和查询连接起来,方便我们操作查询语句
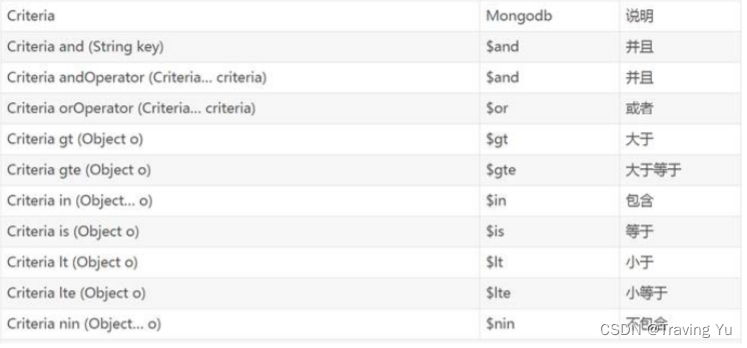
@Test
public void testFind(){
System.out.println("==========查询所有文档===========");
//查询所有文档
List<Employee> list = mongoTemplate.findAll(Employee.class);
list.forEach(System.out::println);
System.out.println("==========根据_id查询===========");
//根据_id查询
Employee e = mongoTemplate.findById(1, Employee.class);
System.out.println(e);
System.out.println("==========findOne返回第一个文档===========");
//如果查询结果是多个,返回其中第一个文档对象
Employee one = mongoTemplate.findOne(new Query(), Employee.class);
System.out.println(one);
System.out.println("==========条件查询===========");
//new Query() 表示没有条件
//查询薪资大于等于8000的员工
//Query query = new Query(Criteria.where("salary").gte(8000));
//查询薪资大于4000小于10000的员工
//Query query = new Query(Criteria.where("salary").gt(4000).lt(10000));
//正则查询(模糊查询) java中正则不需要有//
//Query query = new Query(Criteria.where("name").regex("张"));
//and or 多条件查询
Criteria criteria = new Criteria();
//and 查询年龄大于25&薪资大于8000的员工
//criteria.andOperator(Criteria.where("age").gt(25),Criteria.where("salary").gt(8000));
//or 查询姓名是张三或者薪资大于8000的员工
criteria.orOperator(Criteria.where("name").is("张三"),Criteria.where("salary").gt(5000));
Query query = new Query(criteria);
//sort排序
//query.with(Sort.by(Sort.Order.desc("salary")));
//skip limit 分页 skip用于指定跳过记录数,limit则用于限定返回结果数量。
query.with(Sort.by(Sort.Order.desc("salary")))
.skip(0) //指定跳过记录数
.limit(4); //每页显示记录数
//查询结果
List<Employee> employees = mongoTemplate.find(
query, Employee.class);
employees.forEach(System.out::println);
}
使用MQL语句查询:
@Test
public void testFindByJson() {
//使用json字符串方式查询
//等值查询
//String json = "{name:'张三'}";
//多条件查询
String json = "{$or:[{age:{$gt:25}},{salary:{$gte:8000}}]}";
Query query = new BasicQuery(json);
//查询结果
List<Employee> employees = mongoTemplate.find(
query, Employee.class);
employees.forEach(System.out::println);
}
更新文档
在Mongodb中无论是使用客户端API还是使用Spring Data,更新返回结果一定是受行数影响。如果更新后的结果和更新前的结果是相同返回0
- updateFirst() 只更新满足条件的第一条记录
- updateMulti() 更新所有满足条件的记录
- upsert() 没有符合条件的记录则插入数据
@Test
public void testUpdate(){
//query设置查询条件
Query query = new Query(Criteria.where("salary").gte(15000));
System.out.println("==========更新前===========");
List<Employee> employees = mongoTemplate.find(query, Employee.class);
employees.forEach(System.out::println);
Update update = new Update();
//设置更新属性
update.set("salary",13000);
//updateFirst() 只更新满足条件的第一条记录
//UpdateResult updateResult = mongoTemplate.updateFirst(query, update,Employee.class);
//updateMulti() 更新所有满足条件的记录
//UpdateResult updateResult = mongoTemplate.updateMulti(query, update,Employee.class);
//upsert() 没有符合条件的记录则插入数据
//update.setOnInsert("id",11); //指定_id
UpdateResult updateResult = mongoTemplate.upsert(query, update,Employee.class);
//返回修改的记录数
System.out.println(updateResult.getModifiedCount());
System.out.println("==========更新后===========");
employees = mongoTemplate.find(query, Employee.class);
employees.forEach(System.out::println);
删除文档
@Test
public void testDelete(){
//删除所有文档
//mongoTemplate.remove(new Query(),Employee.class);
//条件删除
Query query = new Query(Criteria.where("salary").gte(10000));
mongoTemplate.remove(query,Employee.class);
}
SpringBoot实现聚合操作
基于聚合管道mongodb提供的可操作的内容:
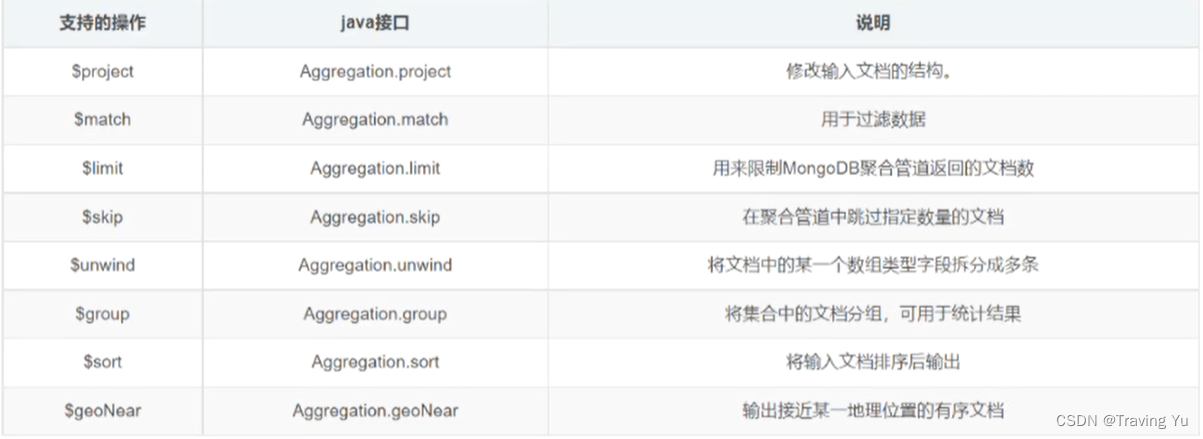
基于聚合操作Aggregation.group,mongodb提供可选的表达式:

示例:
实体结构
@Document("zips")
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Zips {
@Id //映射文档中的_id
private String id;
@Field
private String city;
@Field
private Double[] loc;
@Field
private Integer pop;
@Field
private String state;
}
返回人口超过1000万的州
db.zips.aggregate( [
{ $group: { _id: "$state", totalPop: { $sum: "$pop" } } },
{ $match: { totalPop: { $gt: 10*1000*1000 } } }
] )
Java实现:
@Test
public void test(){
//$group
GroupOperation groupOperation =
Aggregation.group("state").sum("pop").as("totalPop");
//$match
MatchOperation matchOperation = Aggregation.match(
Criteria.where("totalPop").gte(10*1000*1000));
// 按顺序组合每一个聚合步骤
TypedAggregation<Zips> typedAggregation =
Aggregation.newAggregation(Zips.class,
groupOperation, matchOperation);
//执行聚合操作,如果不使用 Map,也可以使用自定义的实体类来接收数据
AggregationResults<Map> aggregationResults =
mongoTemplate.aggregate(typedAggregation, Map.class);
// 取出最终结果
List<Map> mappedResults = aggregationResults.getMappedResults();
for(Map map:mappedResults){
System.out.println(map);
}
}
返回各州平均城市人口
db.zips.aggregate( [
{ $group: { _id: { state: "$state", city: "$city" }, cityPop: { $sum: "$pop" }} },
{ $group: { _id: "$_id.state", avgCityPop: { $avg: "$cityPop" } } },
{ $sort:{avgCityPop:-1}}
] )
Java实现:
@Test
public void test2(){
//$group
GroupOperation groupOperation =
Aggregation.group("state","city").sum("pop").as("cityPop");
//$group
GroupOperation groupOperation2 =
Aggregation.group("_id.state").avg("cityPop").as("avgCityPop");
//$sort
SortOperation sortOperation =
Aggregation.sort(Sort.Direction.DESC,"avgCityPop");
// 按顺序组合每一个聚合步骤
TypedAggregation<Zips> typedAggregation =
Aggregation.newAggregation(Zips.class,
groupOperation, groupOperation2,sortOperation);
//执行聚合操作,如果不使用 Map,也可以使用自定义的实体类来接收数据
AggregationResults<Map> aggregationResults =
mongoTemplate.aggregate(typedAggregation, Map.class);
// 取出最终结果
List<Map> mappedResults = aggregationResults.getMappedResults();
for(Map map:mappedResults){
System.out.println(map);
}
}
按州返回最大和最小的城市
db.zips.aggregate( [
{ $group:
{
_id: { state: "$state", city: "$city" },
pop: { $sum: "$pop" }
}
},
{ $sort: { pop: 1 } },
{ $group:
{
_id : "$_id.state",
biggestCity: { $last: "$_id.city" },
biggestPop: { $last: "$pop" },
smallestCity: { $first: "$_id.city" },
smallestPop: { $first: "$pop" }
}
},
{ $project:
{ _id: 0,
state: "$_id",
biggestCity: { name: "$biggestCity", pop: "$biggestPop" },
smallestCity: { name: "$smallestCity", pop: "$smallestPop" }
}
},
{ $sort: { state: 1 } }
] )
Java实现:
@Test
public void test3(){
//$group
GroupOperation groupOperation = Aggregation
.group("state","city").sum("pop").as("pop");
//$sort
SortOperation sortOperation = Aggregation
.sort(Sort.Direction.ASC,"pop");
//$group
GroupOperation groupOperation2 = Aggregation
.group("_id.state")
.last("_id.city").as("biggestCity")
.last("pop").as("biggestPop")
.first("_id.city").as("smallestCity")
.first("pop").as("smallestPop");
//$project
ProjectionOperation projectionOperation = Aggregation
.project("state","biggestCity","smallestCity")
.and("_id").as("state")
.andExpression(
"{ name: \"$biggestCity\", pop: \"$biggestPop\" }")
.as("biggestCity")
.andExpression(
"{ name: \"$smallestCity\", pop: \"$smallestPop\" }"
).as("smallestCity")
.andExclude("_id");
//$sort
SortOperation sortOperation2 = Aggregation
.sort(Sort.Direction.ASC,"state");
// 按顺序组合每一个聚合步骤
TypedAggregation<Zips> typedAggregation = Aggregation.newAggregation(
Zips.class, groupOperation, sortOperation, groupOperation2,
projectionOperation,sortOperation2);
//执行聚合操作,如果不使用 Map,也可以使用自定义的实体类来接收数据
AggregationResults<Map> aggregationResults = mongoTemplate
.aggregate(typedAggregation, Map.class);
// 取出最终结果
List<Map> mappedResults = aggregationResults.getMappedResults();
for(Map map:mappedResults){
System.out.println(map);
}
}















 2866
2866











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









