






前言
本篇为邱锡鹏《神经网络与深度学习》的第二章课后习题,
如有问题,欢迎大家批评指正。
===========================
2-1
为什么平方损失函数不适用于分类问题?
答:
平方损失函数实际上是计算的预测值和实际值之间的距离,距离越小,损失越小,优化也就越好。
但对于分类问题来说,如果模型输出的是一个标签,计算两个标签之间的距离是没有意义的,比如分类问题的类别为1,2,3,真实结果为1,模型的分类结果为2或者3,距离为1或者2,它们的距离不同,但并没有代表着预测出3的模型就比预测出2的模型差,缩短它们的距离,并不一定会起到优化模型的作用。
即使输出的是一个概率分布,假设一个问题的真实分布为[0,0,1],有两次模型预测的结果分别为[0.2,0.3,0.5]和[0.1,0.4,0.5],结果都是预测正确。对于交叉熵损失函数来说,计算的结果相同,但对平方损失函数来说,第一次的结果比第二次好。
显然平方损失函数过于严格,它的减小在某种情况下并不一定起到了优化作用。它适合对一个准确的实数值的预测,而分类问题仅需要分为正确类别。
===========================
2-2

答:

右边为具体的推导公式,左边为用到的知识。
权重r的作用:对每一个样本都给予一个权重,使得每个样本对结果的影响不同,权重大的样本对最后的结果影响更大。在具体问题上,对我们所感兴趣的样本,或者更为重要的样本,分配更大的权重,使得到的模型更贴合这些样本,使模型更加符合我们的期望。
===========================
2-3
证明在线性回归中,如果样本数量𝑁 小于特征数量𝐷 + 1,则𝑿𝑿 T 的秩
最大为𝑁.
答:

===========================
2-4
在线性回归中,验证岭回归的解为结构风险最小化准则下的最小二乘
法估计
答: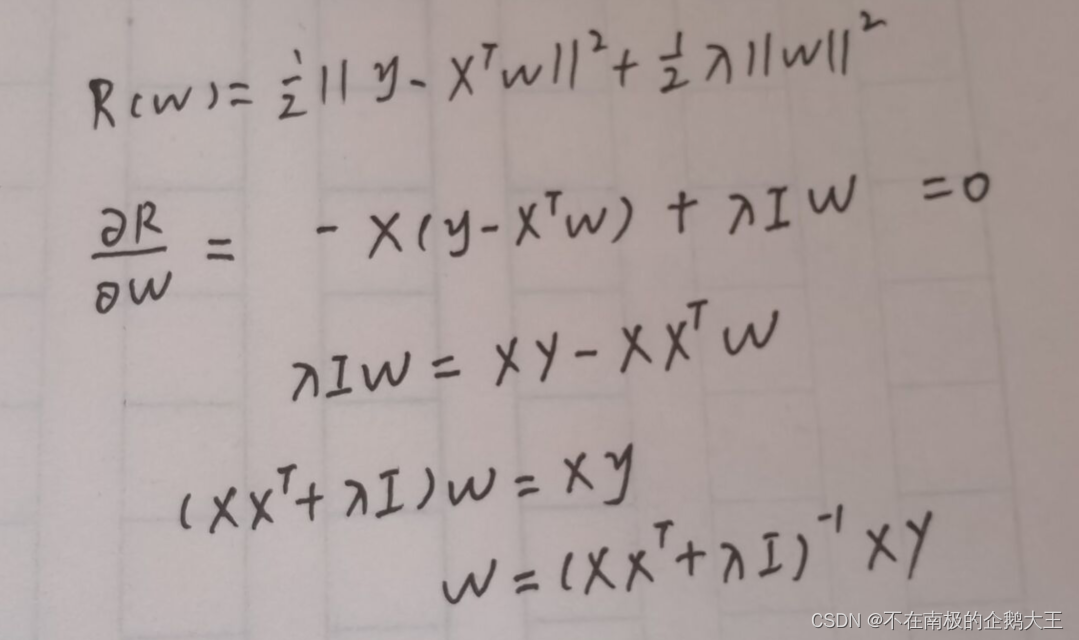
===========================
2-5
在线性回归中,若假设标签 𝑦 ∼ 𝒩(𝒘T𝒙, 𝛽),并用最大似然估计来优化
参数,验证最优参数为公式的解
答:
 ===========================
===========================
2-6

答: 1).
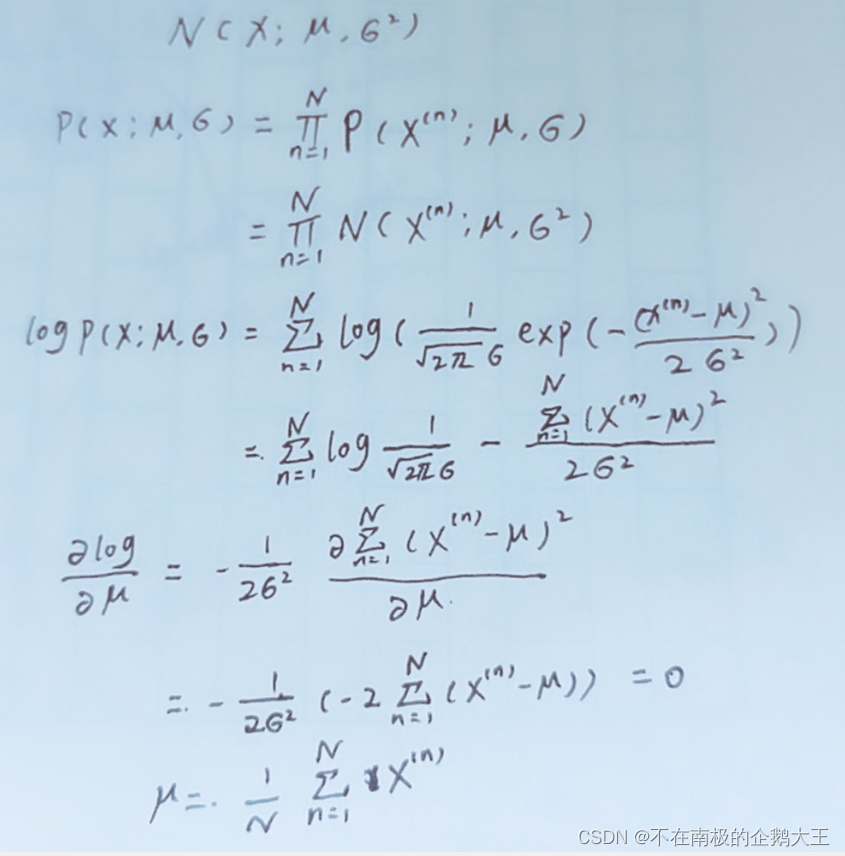
2).
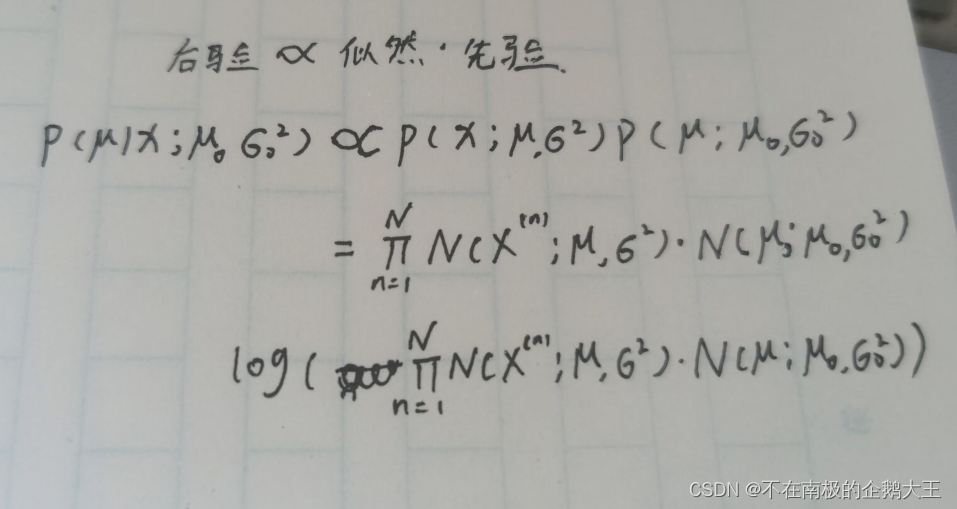

===========================
2-7
在习题2-6中,证明当𝑁 → ∞时,最大后验估计趋向于最大似然估计.
答:

===========================
2-8
验证模型2.61

答:

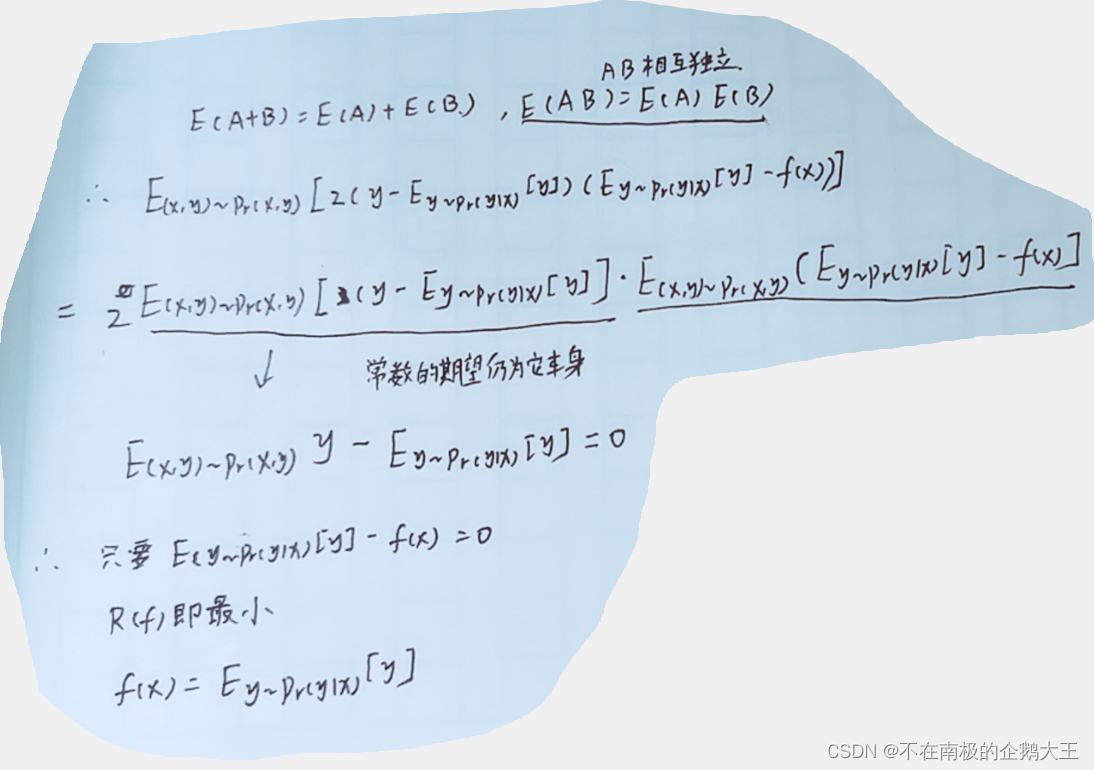
===========================
2-9
试分析什么因素会导致模型出现图2.6所示的高偏差和高方差情况
答:
高偏差是指:模型在训练集上的错误率较高,模型的拟合能力不够。
高方差是指:模型在验证集上的错误率较高,模型过度拟合,泛化能力差。
高偏差和高方差,也就是模型即欠拟合又过拟合,说明模型与数据完全不一致。
比如线性模型对非线性数据,它的偏差很大。对于不同的非线性数据,它的方差也可能很大,于是出现高方差,高偏差的情况。
===========================
2-10
验证公式(2.66)

答:

===========================
2-11
分别用一元、二元和三元特征的词袋模型表示文本“我打了张三”和 “张三打了我”,并分析不同模型的优缺点
答:
一元:
本题共有句”我“,”打了“,”张三“,三个词语
x1=[1,1,1]T
x2=[1,1,1]T
一元特征无法表示文本的语序,只要单词相同,向量便相同。
二元:
$我 我打了 打了张三 张三#
$张三 张三打了 打了我 我#
x1=[1,1,1,1,0,0,0,0]T
x2=[0,0,0,0,1,1,1,1]T
二元特征可以表示出每个单词相邻的顺序,语序不同,向量不同。
三元:
$我打了 我打了张三 打了张三#
$张三打了 张三打了我 打了我#
x1=[1,1,1,0,0,0]T
x2=[0,0,0,1,1,1]T
三元特征和二元一样可以表示出语序的不同,并且向量的长度比二元更短。
综上所述,若N元特征,N为1时,不能表现出语序,有失偏颇。N太大时,若这个例子为五元特征,会出现向量中只有一个分量就能表示整个句子,失去了词袋意义。
===========================
2-12
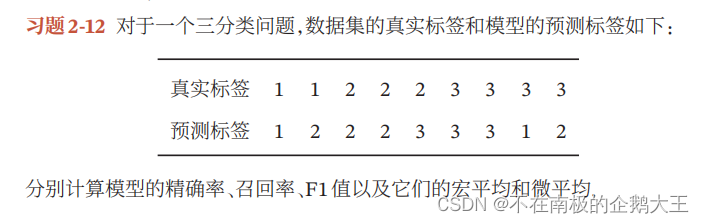
答:

总结
有兴趣的话,可以去邱锡鹏老师的教授的讨论中查看。
课后习题分享讨论















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









