






正确的判断来自于经验,而经验来自于错误的判断。
---- 弗雷德里克·布鲁克斯(Frederick P. Brooks)
前言
本节内容为邱锡鹏教授的《神经网络与深度学习》的第三章,线性模型。
一、分类问题示例
图像分类,目标检测,实例分割,垃圾邮件过滤,文档归类,情感分类,文本分类
二、线性分类模型
线性回归模型,它所对应的y值,属于实数
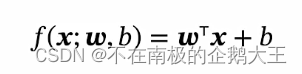
线性分类模型,y是一个个离散的标签。f(x;w)的值域是实数,因此,我们需要引入一个非线性的决策函数,来预测输出目标。f(x;w)又被叫做判别函数。

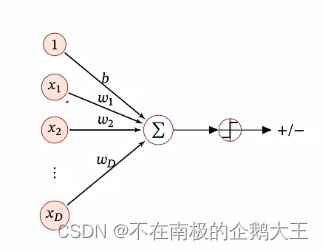
线性分类模型的本质是,定义一个f(x;w)=0的分界线或者分界面,将整个空间一分为二,一边为1,一边为0。
线性分类模型=线性判别函数+线性决策边界
1.二分类
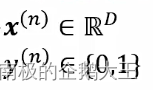
模型:
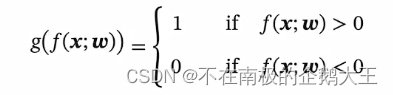
损失函数可以采用0-1损失函数,但它是不能求导的,不能把它转化为一个优化问题,所以要去找更合适它的学习准则。

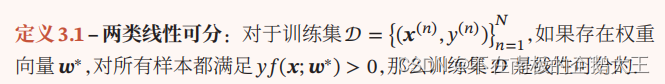
2.多分类
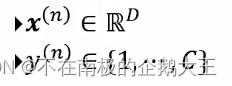
C>2。至少要把空间分成三个区域,一个分界线或者分界面是不能实现的,需要由多个线性分类模型来实现。
常用的方式:
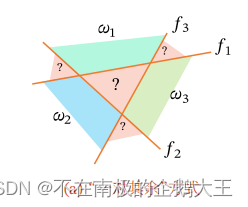
1).“一对其余“方式,把多分类问题转换成C个一对其余问题。即每个类别对应一个判别函数,将类别c的样本和不属于类别c的样本分开。
但是会出现,难以确定类别的区域,比如中间的不属于三类的区域和分别属于两类的区域。
2).“一对一“方式,把多分类问题转换成C(C-1)/2个一对一问题。即每两个类别对应一个判别函数,将类别c1的样本和类别c2的样本分开。
也会出现,难以确定类别的区域,比如中间的区域,每一类的票数是一样多的。
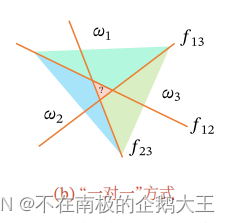
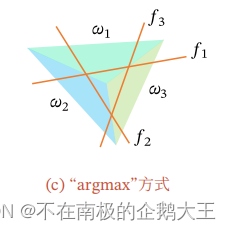
3).“argmax“方式,目前用的最多的方式,是一种改进的一对其余方式,也是需要C个判别函数,它在哪个判别函数的值最高,它就属于哪个类。
空间中不会存在模糊的区域,也就是,除了边界上的点,一定能找到最大的类别。
三、交叉熵和对数似然
交叉熵是一种信息论的概念。”信息“是一组消息的集合。信息论将消息的传递看作一种统计现象,包括信息传输和信息压缩。
熵,在信息论中,用来衡量一个随机事件的不确定性。
熵越高,则随机变量的信息越多;熵越低,则随机变量的信息越少。
自信息,一个随机事件所包含的信息量。
对于一个随机变量X,当X=x的自信息I(x)定义为,I(x)=-log p(x)。
可加性,i和j的自信息量等于它们自信息量的和。

熵:随机变量X的自信息的数学期望。熵的分布越均衡,熵越大。
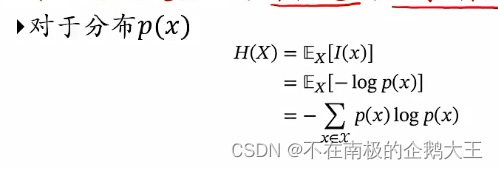
熵编码,对分布p(y)的符号进行编码时,熵H§是理论上最优的平均编码长度,这种编码方式被称为熵编码。对出现概率大的符号赋予一个短码字,出现概率小的符号赋予一个长码字,使得最终的平均码长很小。
交叉熵是按照概率分布为q的最优编码,对真实分布为p的信息进行编码的长度。p和q越接近,交叉熵越小。
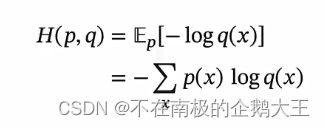
KL散度是用概率分布q来近似p时所造成的信息损失量,就是交叉熵和熵的差异。

在机器学习中可以中用KL散度衡量两个分布的差异。

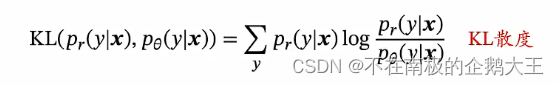
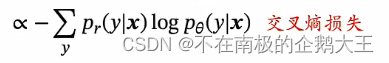

四、Logistic回归
Logistic回归,是一种常用的处理二分类问题的线性模型。
我们把分类问题看成条件概率估计问题,为了解决连续的线性函数不适合进行分类的问题,引入一个非线性函数g(又被叫做激活函数),将线性函数的值域从实数区间”挤压“到(0,1)之间,预测类别标签的条件概率p(y=c|x)
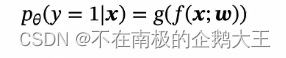
Logistic 函数是一种常用的S(sigmod)型函数,二分类问题中用到的是标准Logistic 函数。
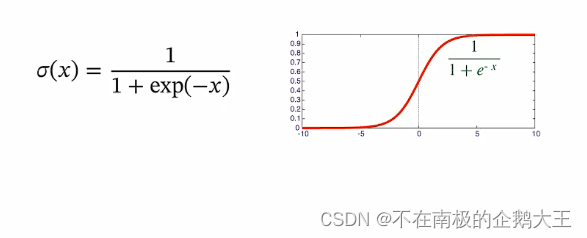
将Logistic函数作为激活函数,则标签y=1的后验概率为
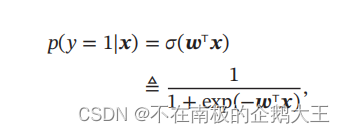
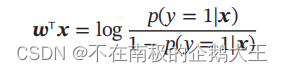
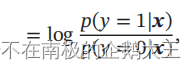
样本𝒙为正反例后验概率的比值,称为几率,几率的对数称为对数几率。这样 Logistic 回归可以看作预测值为“标签的对数几率”的线性回归模型,Logistic回归也称为对数几率回归。
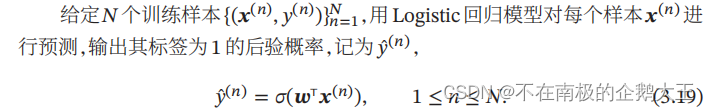

比较真实分布和预测分布,我们可以用上一小节的交叉熵损失函数,来计算风险损失。

下图为梯度的求导过程。

采用梯度下降法来训练Logistic回归,它的训练过程为:初始化 𝒘0 ← 0,然后按照梯度的反方向来迭代更新参数
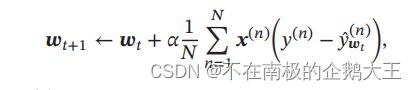
五、Softmax回归
Softmax函数可以将多个标量映射为一个概率分布.对于𝐾 个标量𝑥1, ⋯ , 𝑥𝐾,Softmax函数定义为
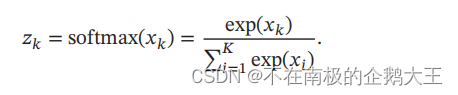
对于这个例子,我们才用argmax方式进行拆分,也就是分成C个判别函数,它在哪个判别函数的值最高,它就属于哪个类。给定一个样本𝒙,Softmax回归预测的属于类别𝑐的条件概率为

下式为Softmax函数的向量表示, 分母是对所有的判别函数的求和,1C是一个C维的全一向量,起到一个求和的作用。W是所有判别函数中权重向量w组成的矩阵。
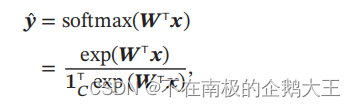
Softmax回归,我们采用交叉熵损失函数来学习最优的参数矩阵,也就是让交叉熵最小,y的真实分布用one-hot向量来表示,因此只需要让为1的y对应的自信息-logp最小即可,也就是所预测的概率最大,也就是最大似然估计。

因此,Softmax回归模型的风险函数为,
风险函数R(w)关于w的梯度为,具体证明过程如下。




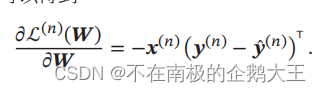
采用梯度下降法,Softmax回归的训练过程为:初始化𝑾0 ← 0,然后通过下式进行迭代更新

课后问题:Softmax回归解决二分类问题时和Logistic回归的区别。
使用 SoftMax 回归或者是多个 Logistic回归二分类解决多分类问题,取决于类别之间是否互斥,例如,如果有四个类别的音乐,分别为:古典音乐、乡村音乐、摇滚乐和爵士乐,那么可以假设每个训练样本只会被打上一个标签(即:一首歌只能属于这四种音乐类型的其中一种),此时你应该使用类别数k = 4 的 SoftMax 回归。(如果在你的数据集中,有的歌曲不属于以上四类的其中任何一类,那么你可以添加一个“其他类”,并将类别数k 设为5)。如果四个类别如下:人声音乐、舞曲、影视原声、流行歌曲,那么这些类别之间并不是互斥的。例如:一首歌曲可以来源于影视原声,同时也包含人声。这种情况下,使用 4 个二分类的 Logistic 回归分类器更为合适。这样,对于每个新的音乐作品,我们的算法可以分别判断它是否属于各个类别。
————————————————
版权声明:本文为CSDN博主「打工人小飞」的原创文章,遵循CC4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接: https://blog.csdn.net/huangfei711/article/details/79801968
主要区别就是使用 SoftMax 回归或者是多个 Logistic 回归二分类解决多分类问题,取决于类别之间是否互斥。如果分类的类别是互斥的,使用Softmax 回归;若不是互斥的,是相互混杂的,则使用Logistic回归。
六、感知器
感知器(Perceptron)由 Frank Roseblatt 于 1957 年提出,是一种广泛使用的线性分类器。
感知器可谓是最简单的人工神经网络,只有一个神经元。
感知器是对生物神经元的简单数学模拟,有与生物神经元相对应的部件,如权重(突触)、偏置(阈值)及激活函数(细胞体),输出为+1或−1。
感知器是一种简单的两类线性分类模型,分类准则和Logistic相同,但输出为+1/-1
它的学习目标如下所示,也就是使得感知器对每个样本的结果是正确的。

感知器的学习算法是一种错误驱动的在线学习算法。
在线学习也就是样本是逐个输入的,先是(x1,y1),逐渐到(xn,yn)。
错误驱动是指当分类错误时更新模型权重,正确时不变,直到所有样本都对。
学习方法类似于随机梯度下降的方式,因此可以反推出感知器的损失函数。
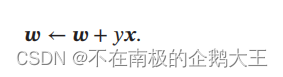




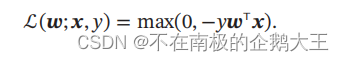
下图为具体的学习过程,分割线或者决策面是WTX=0。w为一个向量,X也为一个向量,只有它们的夹角小于90°,WTX才大于0,因此和w同方向的为+。选取的点不正确的话,w+yx,若点为正例,w向量加上x向量;点为负例,则w向量减去x向量,直到全部正确。
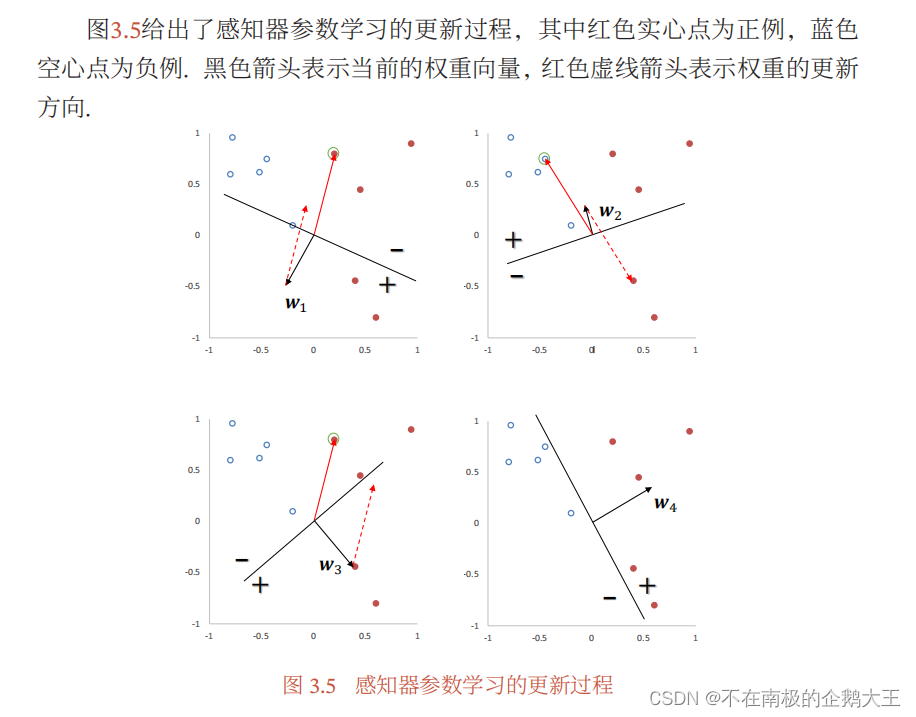
对于两类问题,如果训练集是线性可分的,那么感知器算法可以在有限次迭代后收敛.然而,如果训练集不是线性可分的,那么这个算法则不能确保会收敛。


拓展
参数平均感知器
感知器学习到的权重向量和训练样本的顺序相关.在迭代次序上排在后面的错误样本比前面的错误样本,对最终的权重向量影响更大。比如有 1000 个训练样本,在迭代100个样本后,感知器已经学习到一个很好的权重向量。在接下来的899个样本上都预测正确,也没有更新权重向量。但是,在最后第1000个样本时预测错误,并更新了权重.这次更新可能反而使得权重向量变差。
为了提高感知器的鲁棒性和泛化能力,我们可以将在感知器学习过程中的所有 𝐾 个权重向量保存起来,𝐾 为感知器在训练中权重向量的总更新次数,并赋予每个权重向量 一个置信系数𝑐𝑘(1≤𝑘≤𝐾)。最终的分类结果通过这 𝐾 个不同权重的感知器投票决定,这个模型也称为投票感知器。

投票感知器虽然提高了感知器的泛化能力,但是需要保存𝐾个权重向量,在实际操作中会带来额外的开销。因此,人们经常会使用一个简化的版本,通过使用“参数平均”的策略来减少投票感知器的参数数量,也叫做平均感知器。
T为迭代的总回合数,W为T次迭代的平均权重向量。方法非常简单,只需要再每次迭代的时候都更新W。


扩展到多分类
原始的感知器是一种二分类模型,但也可以很容易地扩展到多分类问题。

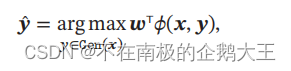
在𝐶分类问题中,一种常用的特征函数𝜙(𝒙, 𝒚)是𝒙和𝒚的外积
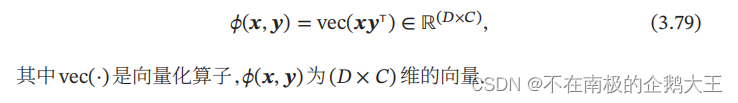


七、支持向量机
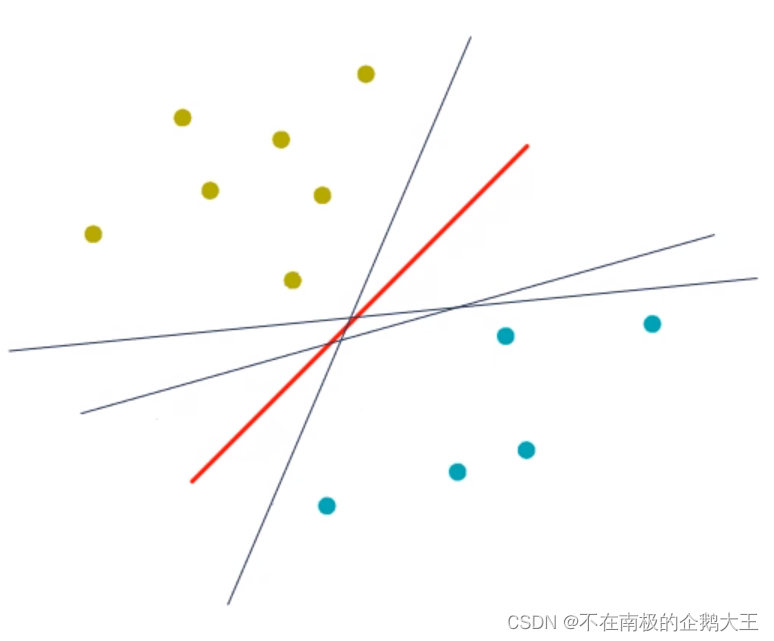
支持向量机(Support Vector Machine,SVM)是一个经典的二分类算法,其找到的分割超平面具有更好的鲁棒性,因此广泛使用在很多任务上,并表现出了很强优势。
以二分类为例,下图的几种分类器显然都是符合条件的,其中红色的分类器更好,因为它距离样本点都是比较远的,出现新点时分类成功的概率较高。
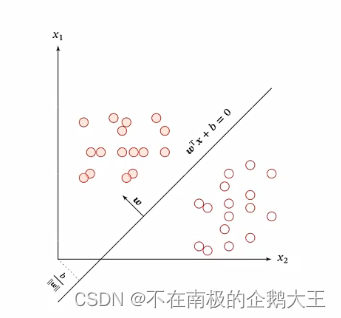
把分类器也就是决策边界到分类样本的最短距离称之为间隔。支持向量机就是选取间隔最大的决策边界。
样本点到超平面的距离如下所示。
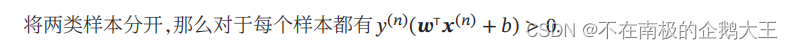
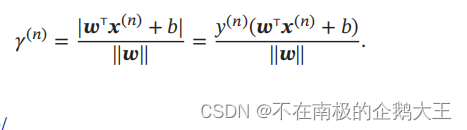

间隔即最小的距离。间隔越大,意味着超平面对两个数据集的划分越稳定,不容易受到噪声等因素影响。支持向量机的目标就是寻找一个间隔最大的超平面,如下所示。
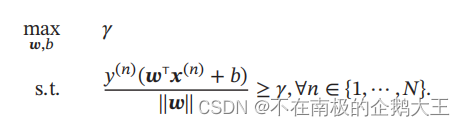
上图的w和b的值存在着多种满足条件的情况,因此不能进行优化,可以通过对w的值进行一个限制,使得解唯一便于进行优化。

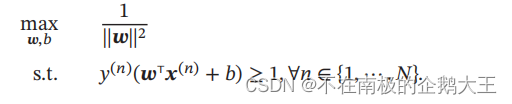
向量的模的平方可以免去开方运算,便于计算。数据集中所有满足 𝑦(𝑛)(𝒘T𝒙(𝑛) + 𝑏) = 1 的样本点,都称为支持向量。
在参数学习时,可以将上式改写成凸优化问题
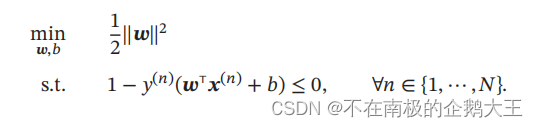
对于带有约束的优化问题,我们采用拉格朗日乘数法,得到相应的拉格朗日函数。
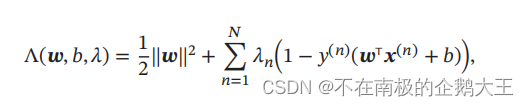
通过计算相应的函数的偏导数,得到相应的拉格朗日对偶函数

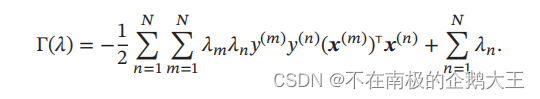
支持向量机的主优化问题为凸优化问题,满足强对偶性,即主优化问题可以通过最大化对偶函数来求解。对偶函数是一个凹函数,因此最大化对偶函数是一个凸优化问题,可以通过多种凸优化方法来进行求解,得到拉格朗日乘数的最优值𝜆∗。但由于其约束条件的数量为训练样本数量,一般的优化方法代价比较高,因此在实践中通常采用比较高效的优化方法,比如序列最小优化(Sequential Minimal Optimization,SMO)算法等。
同时根据KKT条件中的互补松弛条件,最优解满足
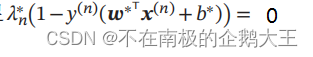
在计算出 𝜆∗ 后,根据公式可以计算最优权重 𝒘∗,而最优偏置 𝑏∗ 可以通过任选一个支持向量计算得到。

软间隔
在支持向量机的优化问题中,约束条件比较严格。如果训练集中的样本在特征空间中不是线性可分的,就无法找到最优解。因此,为了能够容忍部分不满足约束的样本,我们可以引入松弛变量(Slack Variable)𝜉。
其中参数 𝐶 > 0 用来控制间隔和松弛变量惩罚的平衡,C越小,松弛变量就可以越大,容忍程度也就越高。引入松弛变量的间隔称软间隔。


可以将目标函数进行一个重写,改成经验风险加上正则化的形式。其中的max可以看作损失函数,被称为Hinge损失函数,1/c是正则化系数
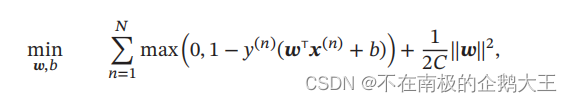


支持向量机还有一个重要的优点是可以使用核函数(Kernel Function)隐式地将样本从原始特征空间映射到更高维的空间,并解决原始特征空间中的线性不可分问题。比如在一个变换后的特征空间𝜙中,支持向量机的决策函数为

八、损失函数对比
本章节用了多种损失模型,为了比较它们,统一类别标签𝑦 ∈ {+1, −1},定义𝑓(𝒙; 𝒘) = 𝒘T𝒙 + b;这样对于样本 (𝒙, 𝑦),若 𝑦𝑓(𝒙; 𝒘) > 0,则分类正确,且越大表示越正确;若𝑦𝑓(𝒙; 𝒘) < 0,则分类错误。
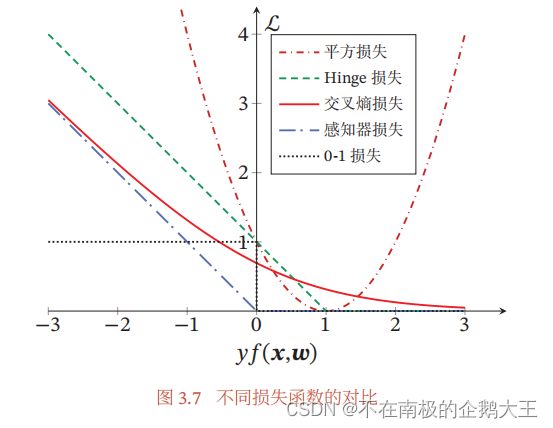
Logistic回归的损失函数为交叉熵损失函数,将它进行改写。它正如图像所示,它的值随着𝑦𝑓(𝒙; 𝒘) 的增大,逐渐减小趋近与0。
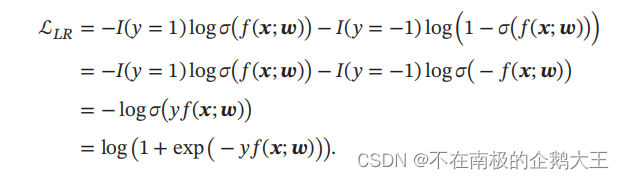
平方损失函数的改写为,它的值随着𝑦𝑓(𝒙; 𝒘) 的增大,先减小再增大,在𝑦𝑓(𝒙; 𝒘) =1时,损失最小,但是𝑦𝑓(𝒙; 𝒘) 再增大时,损失再次增加。不符合𝑦𝑓(𝒙; 𝒘) 越大,分类越正确。平放损失函数并不适用二分类问题。


总结
和回归问题不同,分类问题中的目标标签𝑦是离散的类别标签,因此分类问题中的决策函数需要输出离散值或是标签的后验概率。线性分类模型一般是一个广义线性函数,即一个或多个线性判别函数加上一个非线性激活函数。
















 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









