







@article{ma2021STDFusionNet,
title={STDFusionNet: An Infrared and Visible Image Fusion Network Based on Salient Target Detection},
author={Jiayi Ma, Linfeng Tang, Meilong Xu, Hao Zhang, and Guobao Xiao},
journal={IEEE Transactions on Instrumentation and Measurement},
year={2021},
volume={70},
number={},
pages={1-13},
doi={10.1109/TIM.2021.3075747},
publisher={IEEE}
}
论文所在期刊:IEEE Transactions on Instrumentation and Measurement
发布时间:2021.1.1
所在级别:中科院-工程技术2区
影响因子:5.6
论文笔记
关键词
Deep learning, image fusion, infrared image,mask, salient target detection.
深度学习,图像融合,红外图像,掩模,显著目标检测。
提出问题
- 以往基于深度学习的方法由于在图像融合问题中缺乏ground truth,无法定义所需的信息来指导融合框架的训练。
- 之前的方法在构造损失函数时对不同源图像的不同区域不加区分,在融合过程中引入了大量冗余甚至无效的信息。因此,融合后的图像中有用的信息不可避免地会被削弱。
- 在图1中提供了一个典型的例子来直观地说明这种不足,其中U2Fusion[13]是一种典型的基于cnn的方法,而fusongan[15]是一种典型的基于gan的方法。我们可以注意到U2Fusion弱化了突出的目标,而fusongan弱化了背景纹理。

- 在图1中提供了一个典型的例子来直观地说明这种不足,其中U2Fusion[13]是一种典型的基于cnn的方法,而fusongan[15]是一种典型的基于gan的方法。我们可以注意到U2Fusion弱化了突出的目标,而fusongan弱化了背景纹理。
核心思想
- 将红外图像的显著热目标和可见光图像的背景纹理结构定义为融合过程中最有意义的信息。基于这一定义,我们开发了一个特定的损失函数来指导融合模型学习,通过对红外图像中的显著目标进行标注,得到显著目标蒙版。
- 显著目标掩码仅用于指导网络的训练,不需要在测试阶段输入网络,因此,我们的网络是端到端模型。
- 采用伪暹网络从源图像中区分提取不同类型的信息,如显著目标强度和背景纹理结构。
- 在特定损失函数中引入显著目标掩模,引导网络检测红外图像中的热辐射目标,并将其与可见光图像的背景纹理细节融合。
网络结构
- 整体框架
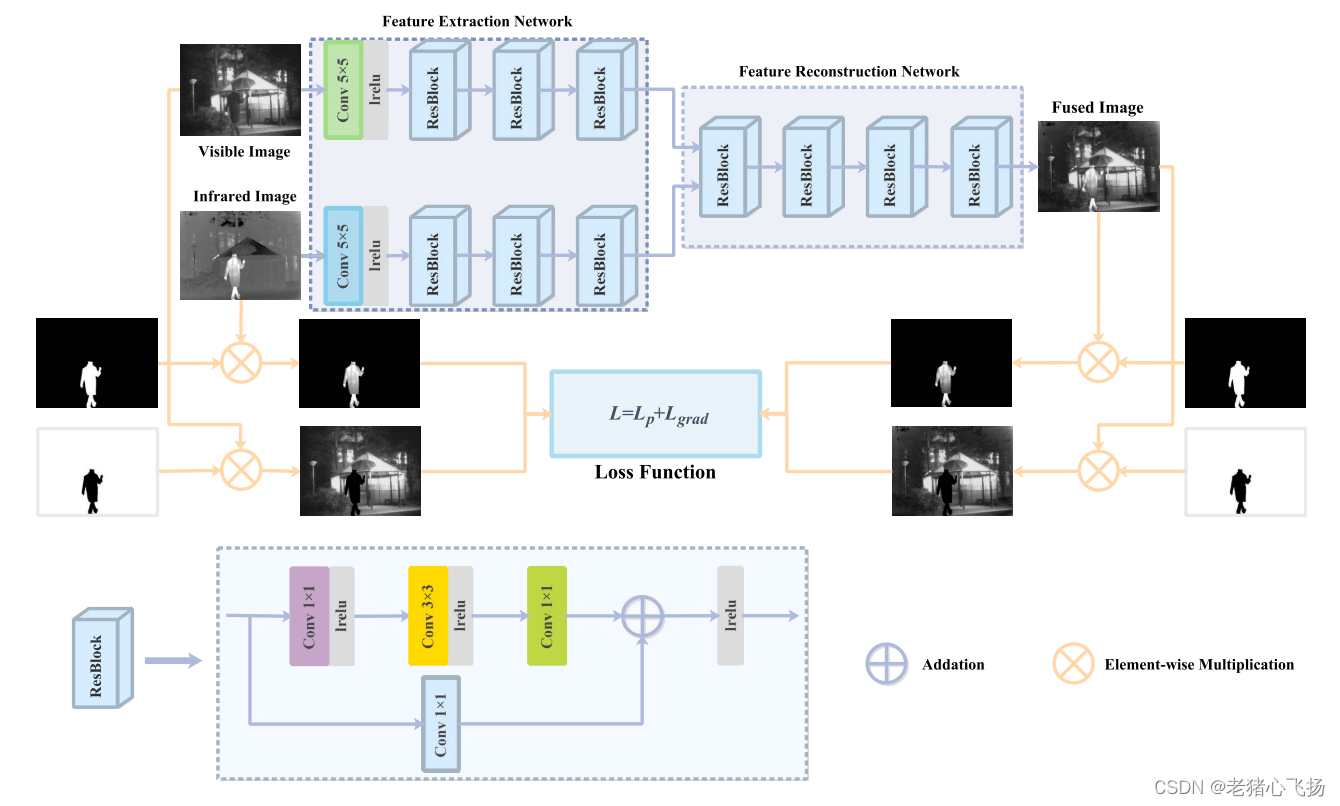
- 特征提取网络部分:由一个公共层和三个resblock组成
- 在CNN的基础上构建特征提取网络,引入ResBlock增强网络提取,缓解梯度消失/爆炸的问题
- 特征重建网络部分:由四个resblock组成,分别起到Feature fusion和image Reconstruction的作用。
- 最后一层的激活函数使用Tanh来保证融合图像的变化范围与输入图像的变化范围一致。
- 掩膜的生成
- 突出目标掩模的目的是突出红外图像中辐射大量热量的物体(例如行人、车辆和掩体)。
- 使用LabelMe工具箱对红外图像中的显著目标进行标注,并将其转换为二进制显著目标掩模。
损失函数
- 完整图像:由掩膜部分提取红外光,反掩膜部分提取可见光
- 其中Im为显著目标掩码
- 操作符◦表示元素乘法
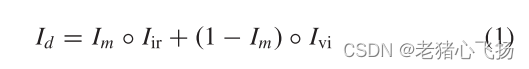
- 显著图像像素损失以及背景像素损失
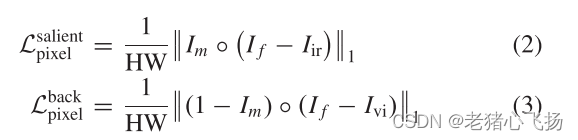
- 梯度损失:增强对网络的约束,使融合图像具有更清晰的纹理,使显著目标具有更锐利的边缘。
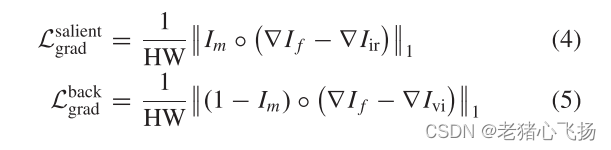
- 总损失:作者将同一区域的像素损失和梯度损失等同对待
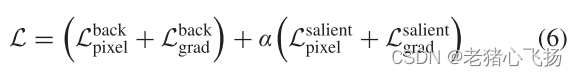
数据集
- TNO数据集
- RoadScene数据集
训练设置
- 在TNO数据集上训练我们的模型,用于训练的图像对的数量是20。为了获得更多的训练数据,我们将每个图像的步长设置为24,每个patch的大小相同,为128 × 128。因此,生成的用于训练的图像补丁对的数量为6921。
- 在测试阶段,我们从TNO数据集中选择20对图像进行对比实验,从RoadScene数据集中选择20对图像进行泛化实验。值得注意的是,每个源图像都归一化为[−1,1]。
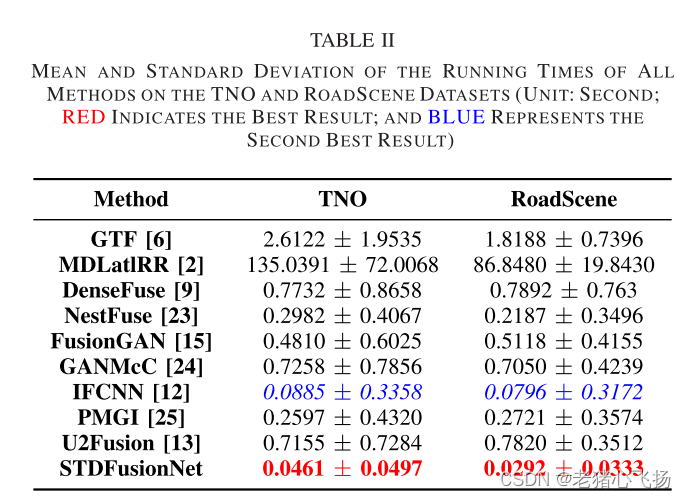
- 采用Adam作为优化求解器来训练模型
- 批大小设置为32
- 迭代次数设置为30
- 学习率设置为10−3。
- 显著区域只占红外图像的一小部分。为了平衡显著区域和背景区域的损失,在本工作中,α设置为7。
- 源图像直接输入融合网络,在测试过程中没有进行任何裁剪。
实验
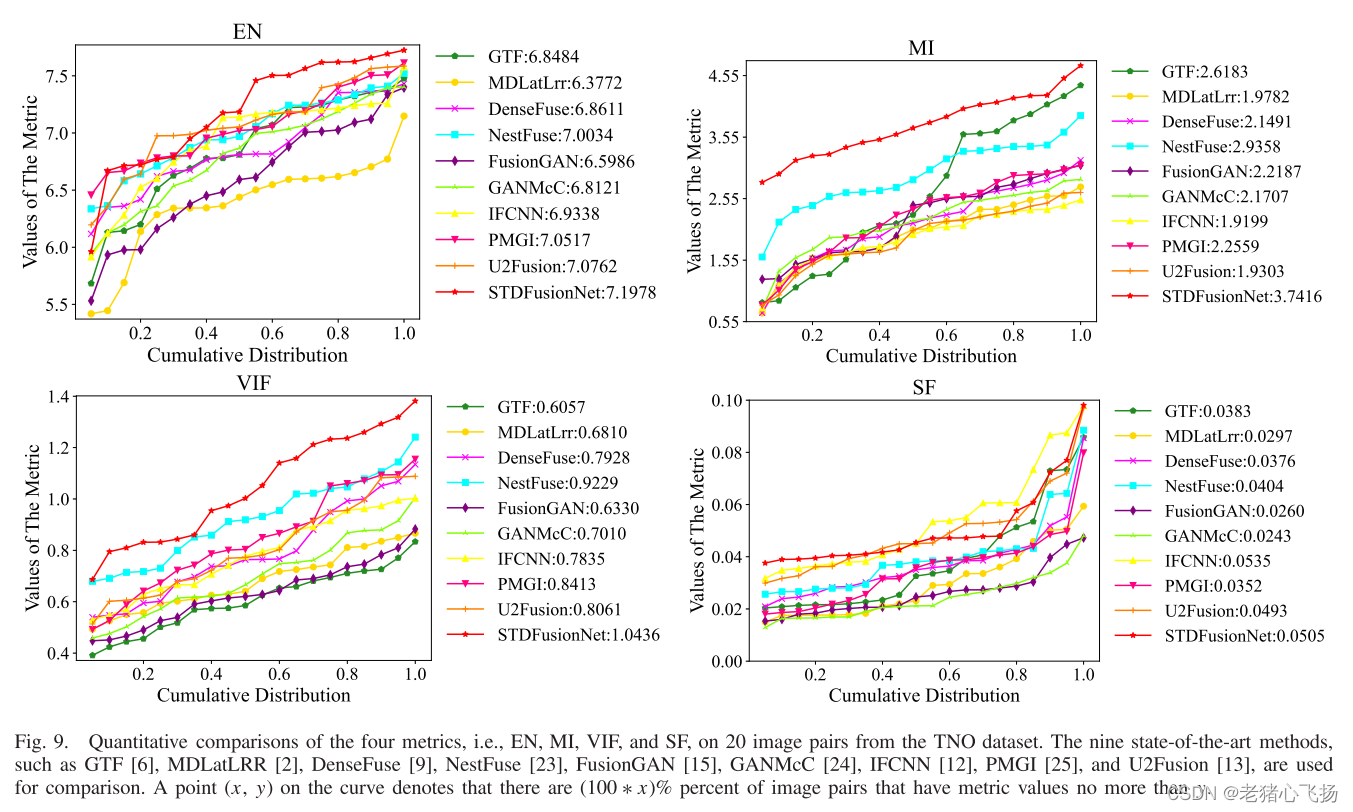
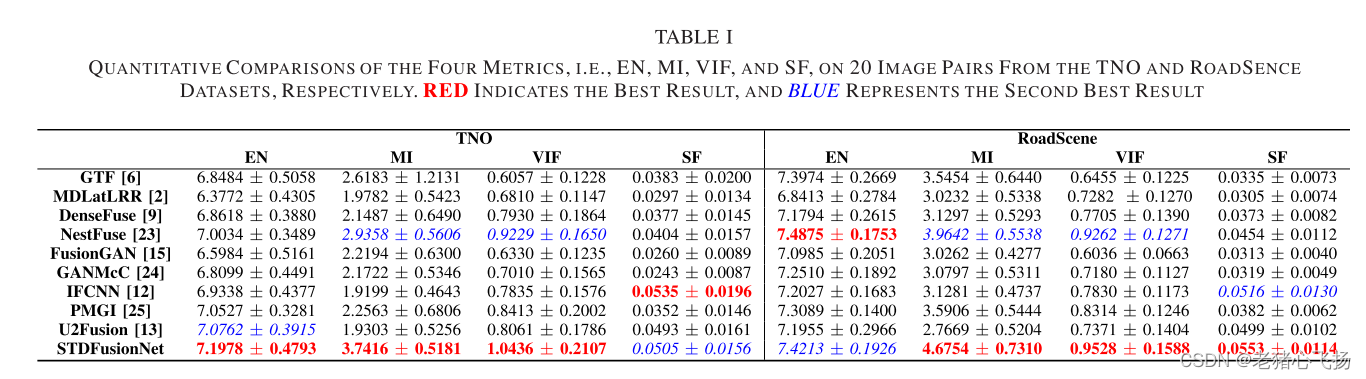
评价指标
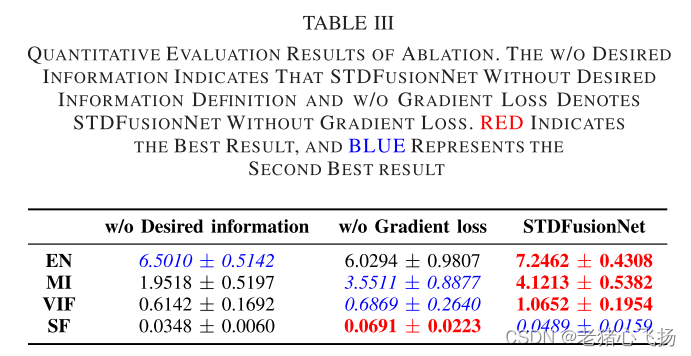
- 包括EN, MI, VIF, SF。
不懂的可以看看这个:图像融合网络的通用评估指标
Baseline
- 传统方法:GTF和MDLatLRR
- 七种深度学习方法:DenseFuse, NestFuse, fusongan, GANMcC, IFCNN,PMGI和U2Fusion。
实验结果
- 定性比较




- 定量比较















 623
623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









