







(引用)
论文所在期刊:IEEE Transactions on Instrumentation and Measurement
发布时间:02 February 2023
所在级别:中科院-工程技术2区
影响因子:5.6
论文笔记
关键词
Automatic patrol inspections, multiscale object detection, real-time detection, transformer, unmanned aerial vehicle (UAV)-vision.
自动巡逻巡检、多尺度目标检测、实时检测、transformer、无人机视觉。
提出问题
- 在无人机检验过程中,可能会出现问题。例如,无人机图像中存在大量难以检测的小目标,无人机图像中物体遮挡严重,对实时性提出了要求
核心思想
- 针对小物体缺乏视觉特征的问题,设计了特征融合模块(FFM),实现了不同层次特征的交互融合,提高了小物体的特征表达能力。
- 为了实现实时检测,我们设计了一个轻量级的特征提取模块(LEM)来构建骨干网来控制计算量和参数。
- 为了解决被遮挡物体特征不连续的问题,设计了一种高效的基于卷积变压器块(ECTB)的卷积多头自注意(CMHSA)算法,通过提取物体的上下文信息来提高被遮挡物体的识别能力。
网络结构
- 整体框架
Conv_1和Conv_2:对图像进行四倍下采样,以减少网络的参数和计算量。LEM模块和卷积层:组成的轻量级CNN进行特征提取和图像下采样。ECTB模块:对卷积捕获的特征映射中的信息进行处理和聚合,以获取图像的全局信息。空间金字塔池-fast (SPPF)与空间金字塔池(SPP):具有相似的结构和相同的功能,都是通过多分支池化层构建不同尺度的特征图并进行融合,增强特征的表现力。FFM模块:对骨干网中不同层次的特征进行融合。为低级特征提供了更多的高级语义信息,为高级特征提供了更丰富的细节信息,从而提高了检测器的多尺度目标检测性能,特别是对小目标的检测性能。APH模块:从不同分辨率的特征图中检测不同比例尺的目标。
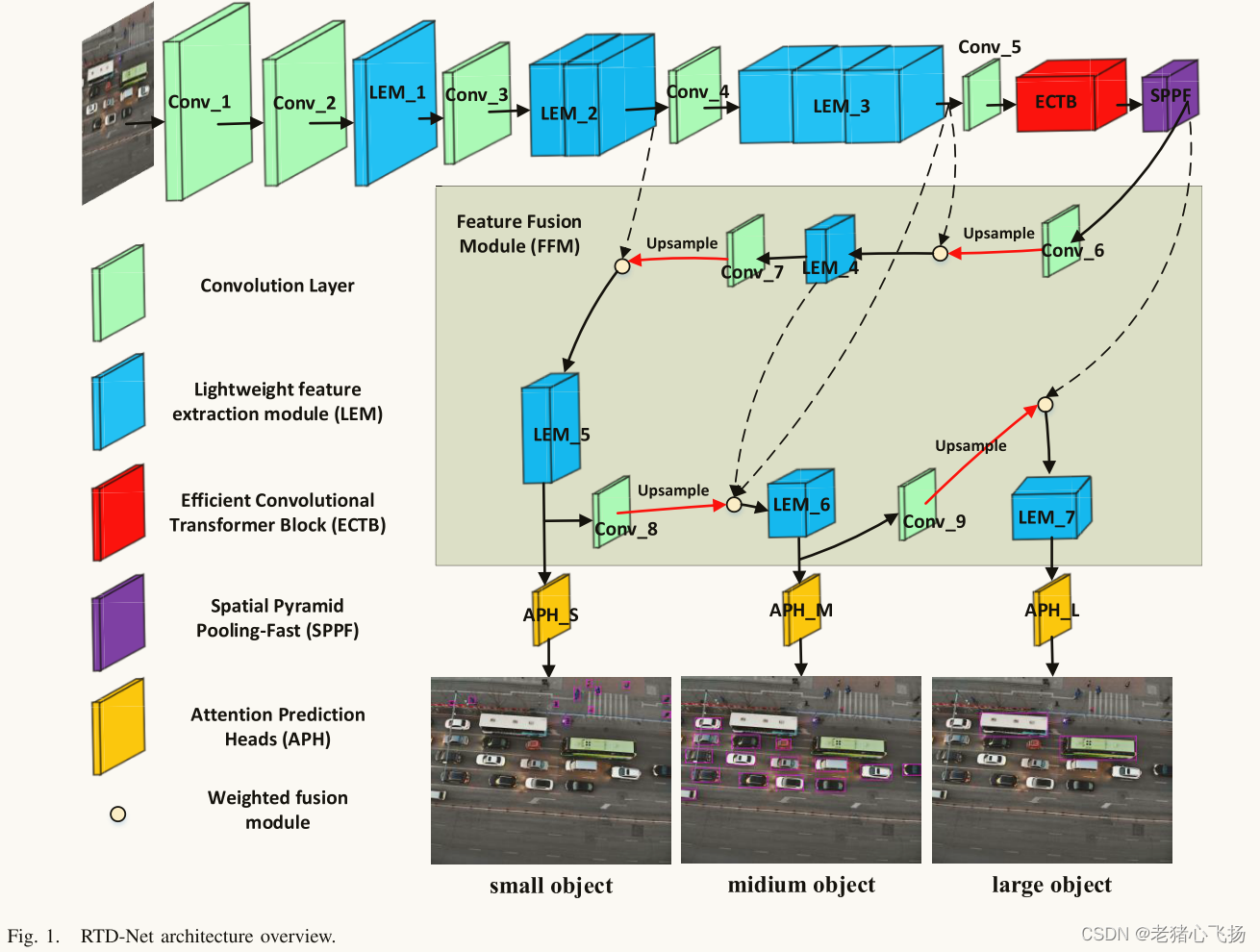
- 轻量级特征提取模块(LEM)
- 通过同构的多分支结构提取不同通道尺寸的特征信息。
- 与C3模块相比,LEM的参数个数和计算量减少了52%,不仅节省了大量的计算资源,而且有效地避免了过拟合的发生,提高了特征提取的鲁棒性。
- 使用1 × 1的卷积核对输入特征的通道信息进行积分,将输入特征映射到以通道数为输入特征的低维特征。
- 采用多分支3 × 3卷积核对这些低维特征图进行特征提取,通道数为输入特征图的1/32。
- 将每个分支进行合并,并使用1 × 1卷积核对特征进行组合。
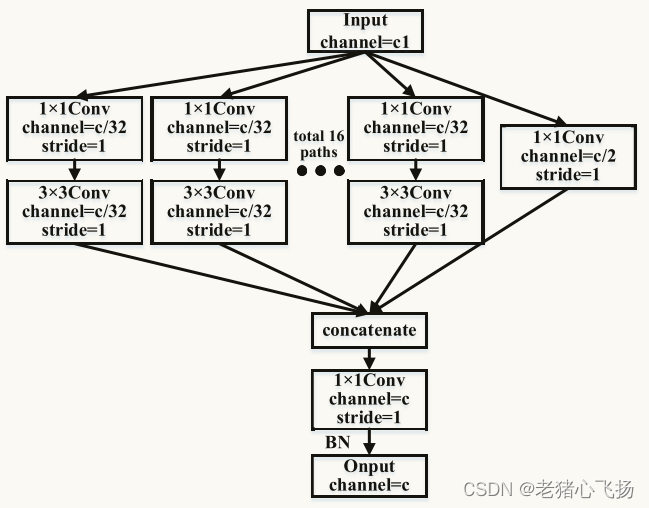
- 使用批归一化(BN)来防止梯度损失
- 式中x表示输入特征图,y表示输出特征图,conv1表示1 × 1标准卷积,其通道数为输入特征图的1/2。0i (x)表示输入特征在低维嵌入和变换中的投影。
- C是要聚合的转换集的大小,它用于控制同质多分支体系结构的数量,本文中的C = 16。
- conv2表示组合特征的1 × 1标准卷积,BN为BN层。
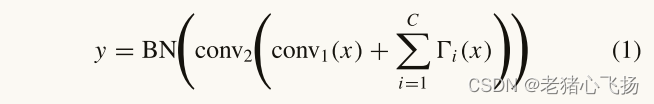
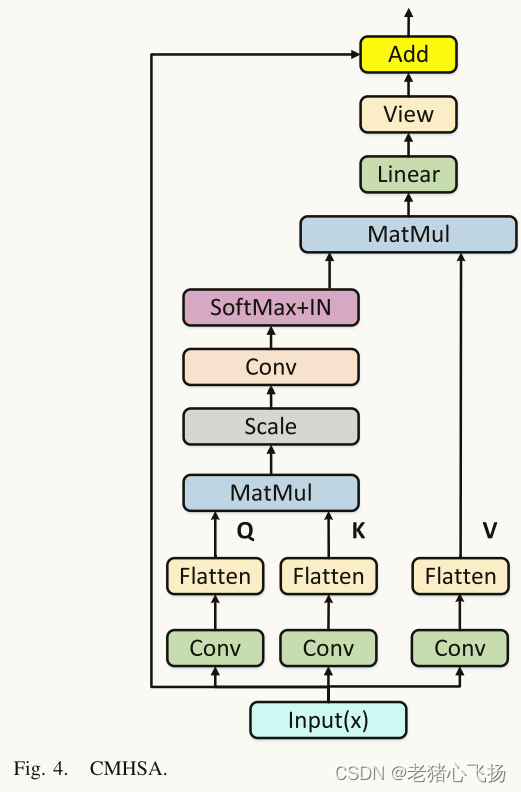
- 高效卷积变压器块(ECTB)
- (a)MHSA通过query-key-value计算序列标记之间的全局关系,并通过线性网络进一步学习这些全局特征。
但是计算负担大,每次名随空间维数的增长呈二次增长,导致显著的训练和推理开销 - (b)利用CNN从图像中提取详细的特征信息,并利用MSHA对CNN捕获的特征映射中包含的信息进行处理和聚合。
BoTNet中的MSHA仍然存在内存和计算量大的问题,不适合操作无人机等计算资源有限、检测速度要求高的场景。 - (c)ECTB具有与LEM相同的拓扑结构,只是用自关注机制取代了LEF的同构多分支体系结构。这个简单的规则可以减少超参数的自由选择,提高模型在不同场景下的稳定性。为了解决传统MSHA的上述问题,ECTB采用卷积投影代替原MHSA中的位置线性投影,得到了CMHSA的机制。使用卷积投影层对输入的二维令牌映射进行投影,并将投影后的令牌平展为一维以供后续处理。此程序可表述如公式(2)
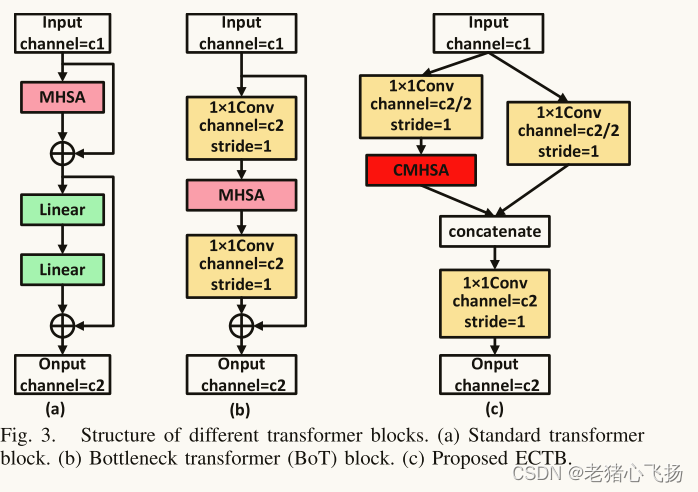
- 其中xq/k/v i是第i层Q/ k/v矩阵的令牌输入,xi是卷积投影之前的未扰动令牌,Conv是标准卷积,s是卷积核大小,这里设置为1
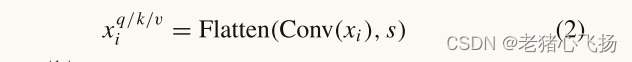
- 其中xq/k/v i是第i层Q/ k/v矩阵的令牌输入,xi是卷积投影之前的未扰动令牌,Conv是标准卷积,s是卷积核大小,这里设置为1
- Q、K、V之间的注意函数为:
- 其中c为输入令牌的通道数,T为处理令牌数,k为CMHSA的头数,本文中k = 4。Conv表示一个标准的1 × 1卷积操作。
- 卷积层的使用可以实现不同头部之间的交互,并改善域特征之间的依赖关系。然而,它削弱了MHSA处理不同位置特征信息的能力。为了解决这个问题,我们在Softmax之后通过实例归一化(IN)计算点积矩阵。将每个头部的输出值通过线性投影拼接并调整成二维特征图作为最终输出。
- ECTB可以通过建立大域间的依赖关系来提高模型对无人机图像的检测精度,并且不会带来昂贵的存储和计算成本,便于模型在无人机和嵌入式设备中的部署。
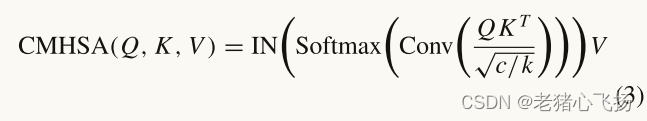
- (a)MHSA通过query-key-value计算序列标记之间的全局关系,并通过线性网络进一步学习这些全局特征。
- 融合模块(FFM)
- 多尺度目标的检测一直是一个挑战。深度特征映射具有更丰富的高级语义信息和更大的接收域,有利于大规模目标识别和目标分类。浅层特征图具有更高的分辨率和更丰富的位置信息,以及更详细的特征信息,可用于小目标识别和目标定位。
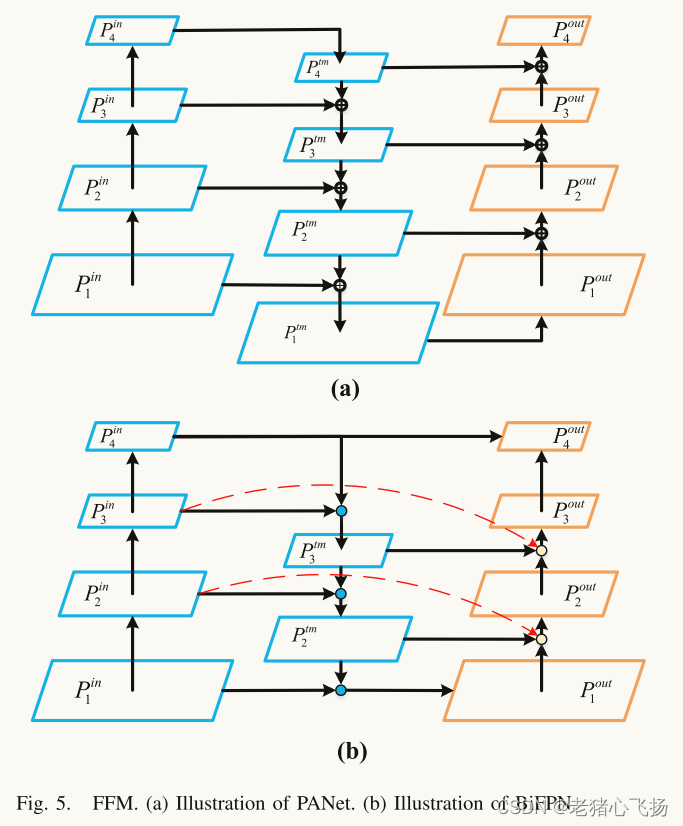
- 作者基于双向特征金字塔网络(BiFPN)[45]的思想设计了一个特征融合模块(FFM),如图5所示。通过融合不同层次的特征,可以提高特征的表现力。因此,可以提高新模型对多尺度目标(特别是小目标)的检测能力。
- 只有一条输入边的节点不能进行特征融合,对不同特征之间的融合贡献不大,因此,移除这些节点以简化网络结构。如图5所示,与PANet相比,BiFPN移除了Ptm 1和Ptm 4节点。
- 在同级的输入和输出节点之间添加跳跃连接,这样可以融合更多的特征,而不会显著增加计算成本,如图5(b)中的红线所示。
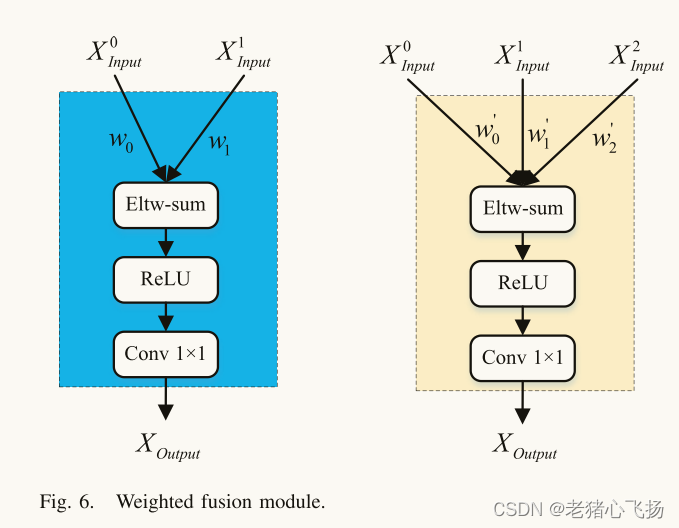
- 不同分辨率的输入特征的贡献是不同的,我们为每个输入增加额外的权重,提出了一个高效的加权融合模块,如图6所示。Xoutput的公式如下:
- 其中,Xi Input表示输入特征,wi为可学习权值,wi≥0。为了提高训练的稳定性,我们将权值归一化到[0,1]之间,并且ε是一个小值,目的是提高计算的稳定性。
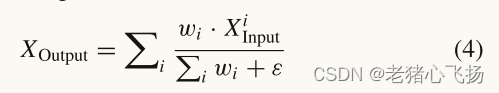
- 其中,Xi Input表示输入特征,wi为可学习权值,wi≥0。为了提高训练的稳定性,我们将权值归一化到[0,1]之间,并且ε是一个小值,目的是提高计算的稳定性。
- 以图5(b)中的Level 3为例,其两个特征融合可以描述为:
- 其中Resize为下采样或上采样操作,用于匹配不同融合特征的分辨率,Conv表示标准的1 × 1卷积,其他地点的特征也以类似的方式融合在一起。
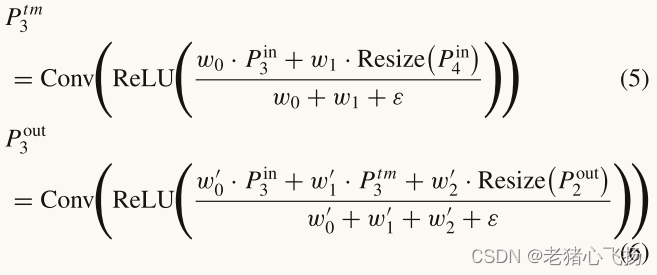
- 其中Resize为下采样或上采样操作,用于匹配不同融合特征的分辨率,Conv表示标准的1 × 1卷积,其他地点的特征也以类似的方式融合在一起。
- 注意力预测头(APH)
- 采用基于归一化的注意模块(NAM)注意机制,在检测头部前形成aph,提取注意区域,使模型能够聚焦于有用的对象。
- NAM是一种轻量级、高效的注意机制,它采用CBAM的模块集成方法,重新设计了通道和空间注意子模块。对于频道注意子模块,它使用BN的尺度因子来反映每个频道的重要性。比例因子是:
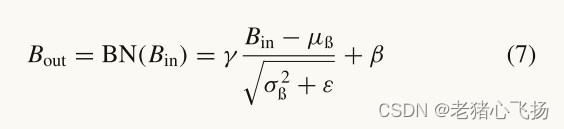
- 信道注意子模块如图7(a)所示,表示为
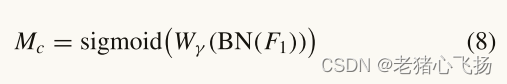
- 空间注意子模块如图7(b)所示,可表示为
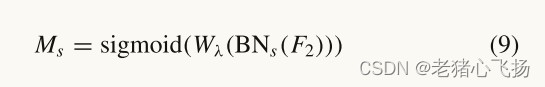
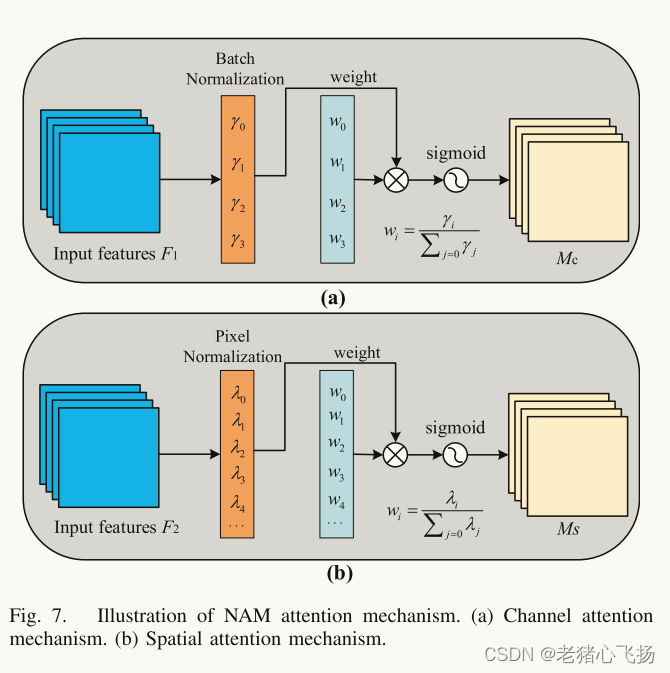
* APH首先在通道和空间两个独立的维度上推断输入图像的注意图,然后利用注意图对输入特征图进行乘法,自适应地获得图像的注意区域。
损失函数
数据集
- 无人机图像数据集(作者自己采集的,没有链接)
- MS COCO2017数据集
训练设置
- 采用随机动量梯度下降法(SGDM)对网络进行优化。
- 最大训练批为300 epoch,批大小设置为64。
- 权重强调和动量分别为0.0005和0.937。
- 初始学习率为0.01,每100次训练降低到0.1。
- 采用了马赛克和混合等多种数据增强方案进行图像增强。
实验
评价指标
不懂的可以看看这个:图像融合网络的通用评估指标
Baseline
- faster-RCNN
- swin-transformer.
实验结果
- 不同方法的视觉检测结果
- YOLOv3和v4都有较多的物体未被检测到,YOLOv5存在少量误检和漏检
- 在图10©中,Yolov4-tiny和Yolov4-tiny都不能正确识别道路上的车辆。虽然Yolov5s可以准确地检测道路上的车辆,但在图像的左上角可以观察到停车场物体的缺失检测现象。RTD-Net在大视场图像中显示出更强的准确识别感兴趣区域的能力。
- 在图10(d)中,Yolov3-tiny、Yolov4tiny和Yolov5s无法识别被树枝遮挡的目标,而RTD-Net能够完整准确地检测被遮挡的目标。

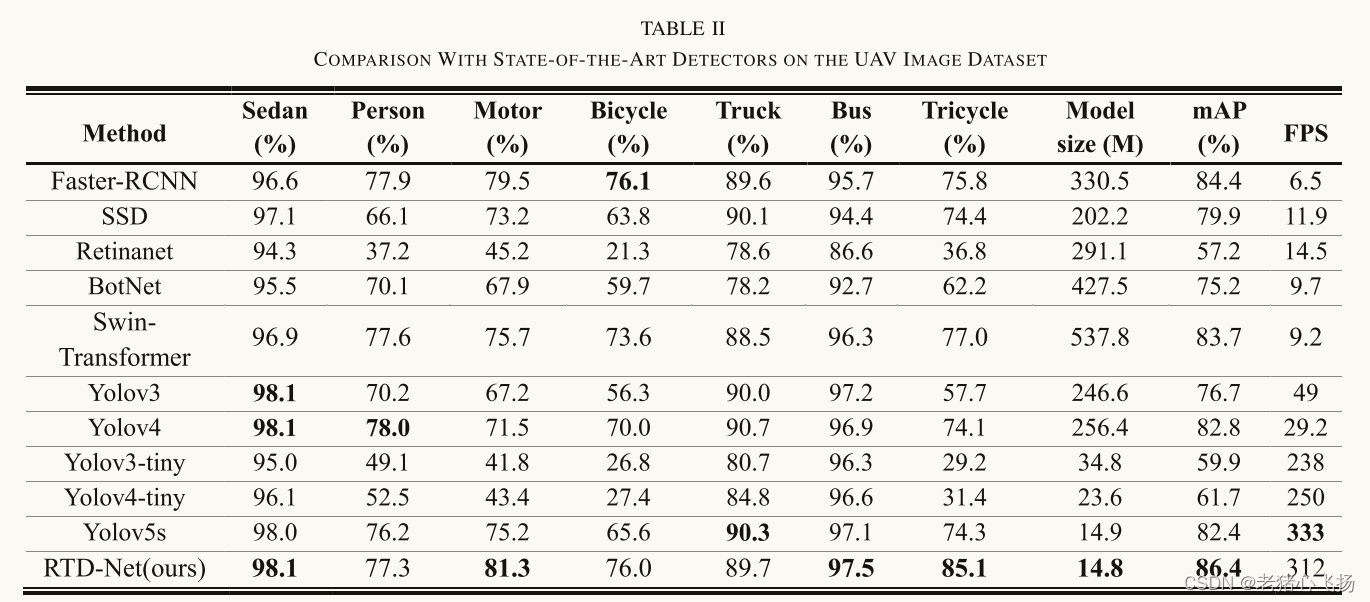
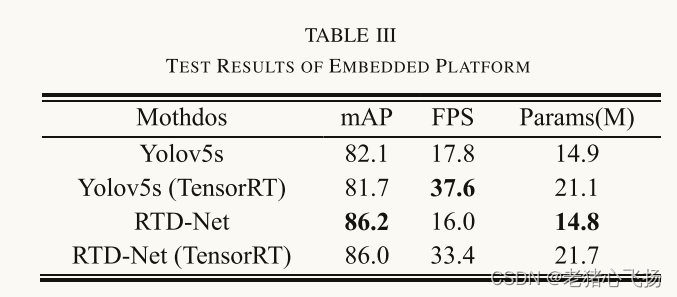
- 在单台NVIDIA GeForce GTX1080Ti上,RTD-Net的推理速度达到312帧/秒,比faster- rcnn快48倍,比swing -transformer快33倍以上。它比最快的检测器Yolov5s慢21帧/s,但检测精度比Yolov5s高4% mAP。同时,RTD-Net的模型尺寸仅为14.8 M,是所有方法中最小的。
- RTD-Net在大多数类别中产生了良好的检测准确性。对于包括人、汽车和自行车在内的小对象,RTD-Net的AP分别达到77.3%、81.3%和76.0%。与Yolov3-tiny、Yolov4-tiny和Yolov5s等相同复杂度的检测器相比,准确率最高,分别比Yolov5s高出1.1%、6.1%和10.4% AP。
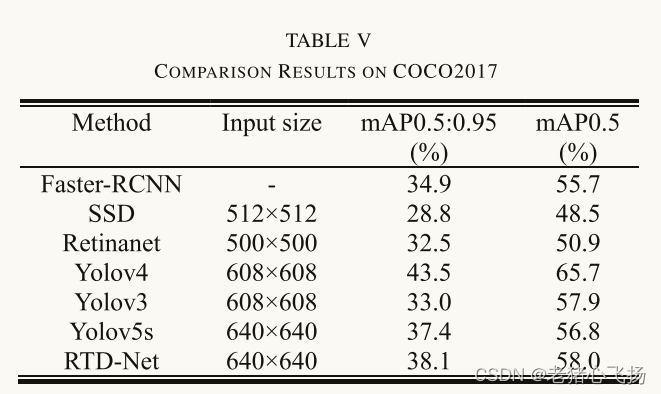
- 与无人机图像数据集上最先进探测器的比较
- 嵌入式平台测试结果
- 多环境下鲁棒性对比

- 消融实验

- COCO2017中的可视化结果。
















 7997
7997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









