







Y. Zhu, X. Sun, M. Wang and H. Huang, “Multi-Modal Feature Pyramid Transformer for RGB-Infrared Object Detection,” in IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 9, pp. 9984-9995, Sept. 2023, doi: 10.1109/TITS.2023.3266487.
keywords: {Transformers;Feature extraction;Object detection;Fuses;Semantics;Visualization;Standards;RGB-infrared object detection;feature pyramid;transformer;multi-modal fusion},
论文所在期刊:
发布时间:Sept. 2023
所在级别:
影响因子:
论文笔记
关键词
RGB-infrared object detection, feature pyra-mid, transformer, multi-modal fusion
rgb -红外目标检测,特征金字塔,transformer,多模态融合
提出问题
- 在一些实际应用中,RGB图像与红外图像存在错位。不对齐的rgb,红外图像增加了融合的难度
- 夜间RGB图像与红外图像之间的视觉差异较大,增加了对齐的难度。
- 在标准的特征金字塔中,相邻尺度之间的特征交互通常遵循自上而下或自下而上的顺序。最高层的特征需要通过多个中间尺度传播。在到达底部的特征之前,它们与这些尺度上的特征相互作用。在这种传播和交互过程中,可能会丢失或削弱基本特征信息。
核心思想
- 基于目标检测中常用的特征金字塔,作者提出了多模态特征金字塔transformer(multimodal feature pyramid Transformer, MFPT)来融合两种模式
- 算法通过模态内特征金字塔变压器和模态间特征金字塔变压器学习语义和模态互补信息,增强各模态特征。
- 模态间特征金字塔转换器还可以学习模态之间的距离无关依赖关系,而模态之间的距离依赖关系对不对齐图像不敏感。
- 本文提出的方法在训练阶段没有明确考虑不对准问题,但它可以隐式地实现不同模态的特征对准,显示了在不同位置移动下的鲁棒性。
网络结构
-
总体网络
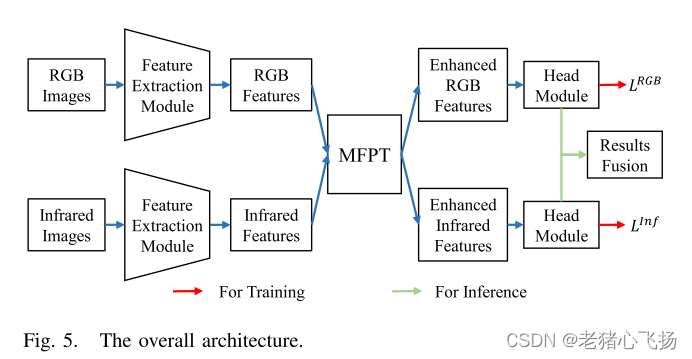
-
MFPT的架构,它包括两个关键组件:模态内特征金字塔变压器和模态间特征金字塔变压器。不同的颜色代表不同的形态。
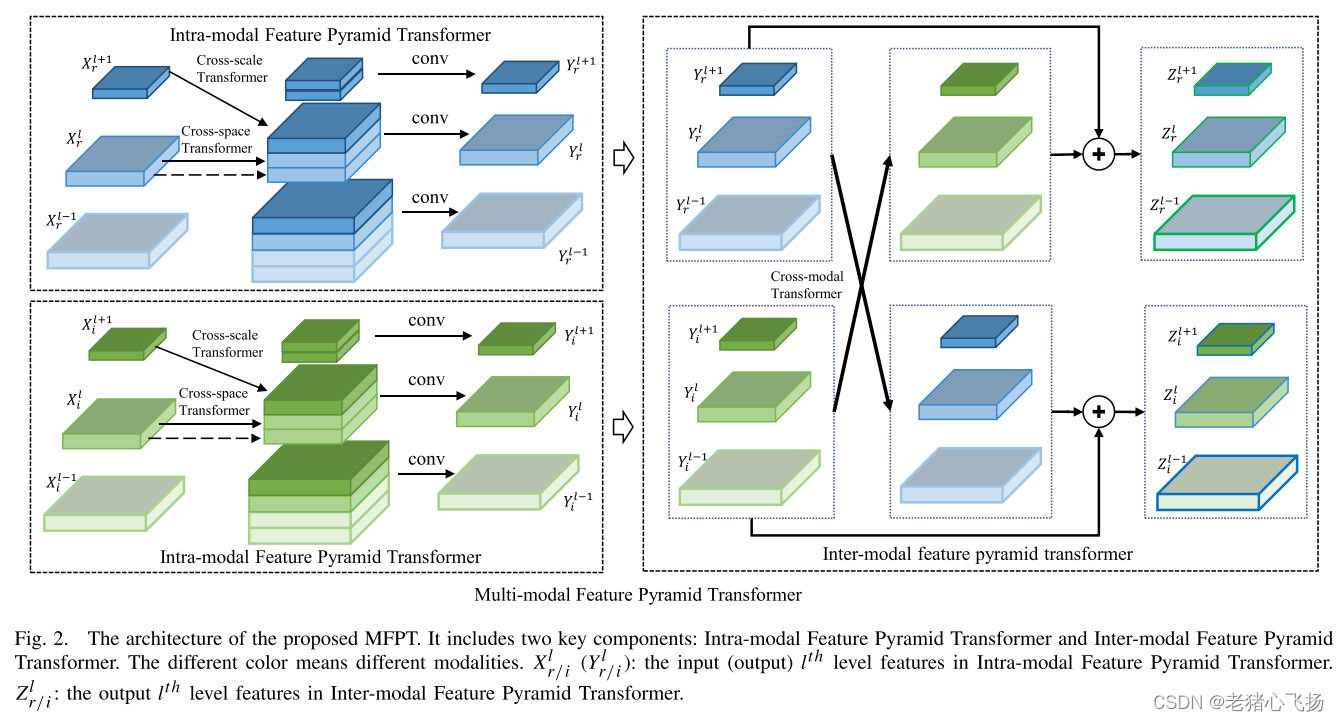
-
Local Transformer
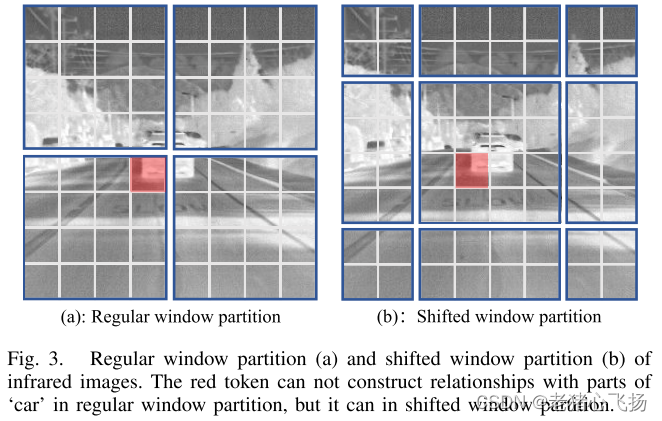
红色标记包含“car”的一部分,但它不能与其他窗口中“car”的部分构建关系。为了解决这个问题,作者使用了一个移位的窗口分区,如图3(b)所示。在这个窗口分区中,红色标记可以构建与“car”部件的关系。最后的注意力权重是两个分区的平均值
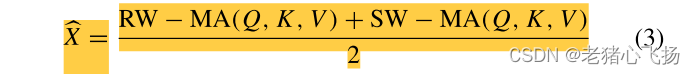
-
模态内特征金字塔transformer:模态内特征金字塔转换器同时支持所有尺度上的特征交互,可以更容易地捕获基本特征信息。
实现了特征跨空间和尺度的交互,提高了特征在各模态中的语义表示。具体包括跨空间变压器、跨尺度transformer两种- 跨空间转换器旨在捕获每个模态的同一级别特征中共同出现的对象特征,Q、K、V皆由同一层的特征计算而来
- 跨尺度transformer中,Q是从低级特征派生出来的,K、V是从相同的高级特征派生出来的。
- 由于Xl+的尺度小于Xl,所以fc k()或fc v()需要输出比输入更大的尺度特征。采用反卷积运算实现fc k()和fc v()。反褶积运算中,输入输出尺度变化关系计算如下:m(hap)= s(m − 1) + 2p − k + 2,其中m为输入特征的宽度或高度大小,k为核大小,s为步长,p为填充大小,bm为输出特征的宽度或高度大小。设k = s, p = s−1,可得:m(hap)= sm, s = 2, 4, . . .
- 在得到Xp,l和Xc,l后,计算模态内特征金字塔变压器Yl的融合特征如下:[·]表示特征拼接操作,Fintra()表示卷积操作。

-
模态间特征金字塔Transformer
- Q由本模态的同一层的特征,K、V由不同模态的同一层特征计算而来
- 利用式(3)(公式在上面)可以计算出跨模态transformer的注意权值
- 得到Ym,l r后,计算RGB模态Zl r的增强特征如下:其中σ()表示激活函数。Ym,l, r可以认为是红外模态的互补特征。同样,也可以得到红外模态Zl i的增强特征。
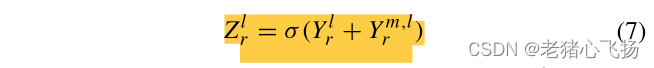
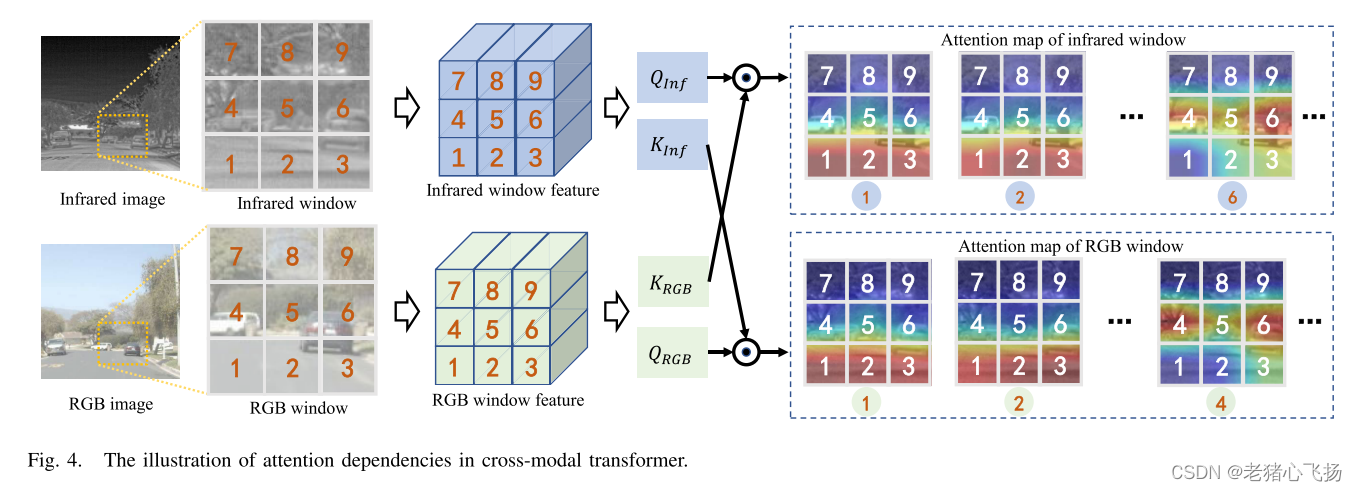
-
红外窗口的“6”令牌与RGB窗口的“3/5/6”令牌构建有效的近程依赖关系,与“4”令牌构建有效的远程依赖关系。类似地,RGB窗口中的“4”标记与红外窗口中的“4/5”标记构建有效的短程依赖关系,与“3/6”标记构建有效的远程依赖关系。这些有效的短程和远程依赖关系可以从另一模态中学习互补信息。
损失函数
- 总损失
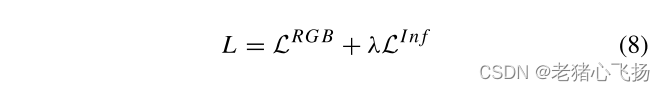
- 在retanet架构下,LRGB或LInf包含位置损失和分类损失。位置损耗为平滑L1损耗,分类损耗为焦点损耗。
- 焦点损失
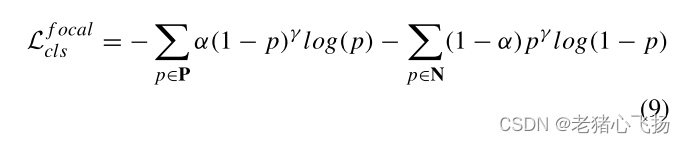
- 在测试阶段,将RGB图像和红外图像馈送到MFPT中,获得增强的特征用于预测。RGB与IR预测结果通过NMS方式融合
数据集
- KAIST:包含95,328对rgb -红外图像,其中1,182个独特的行人被103,128个边界框标注。
- 采用[L. Zhang, X. Zhu, X. Chen, X. Yang, Z. Lei, and Z. Liu, “Weakly aligned cross-modal learning for multispectral pedestrian detection,” in Proc.IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct.2019, pp. 5127–5137.]发表的精炼训练视频,每隔5帧从训练视频中抽取样本图像。被广泛评价的测试图像[10],[15],[16]每20帧从测试视频中采样。测试图像对数量为2252对,其中白天捕获1455对,夜间捕获797对。
- 对齐的FLIR:包含4129对用于训练的图像对和1013对用于测试的图像对。该数据集也在白天和夜间收集,并使用三个高频率类别:“自行车”,“汽车”和“人”进行评估。
训练设置
- focal loss中α = 0.25, γ = 2
- 学习率为0.01,动量为0.9,权值衰减为0.0005。利用了具有1000次线性预热迭代的余弦衰减学习率调度器。训练过程在12000次迭代后终止,采用提前停止。
实验
评价指标
不懂的可以看看这个:图像融合网络的通用评估指标
Baseline
实验结果
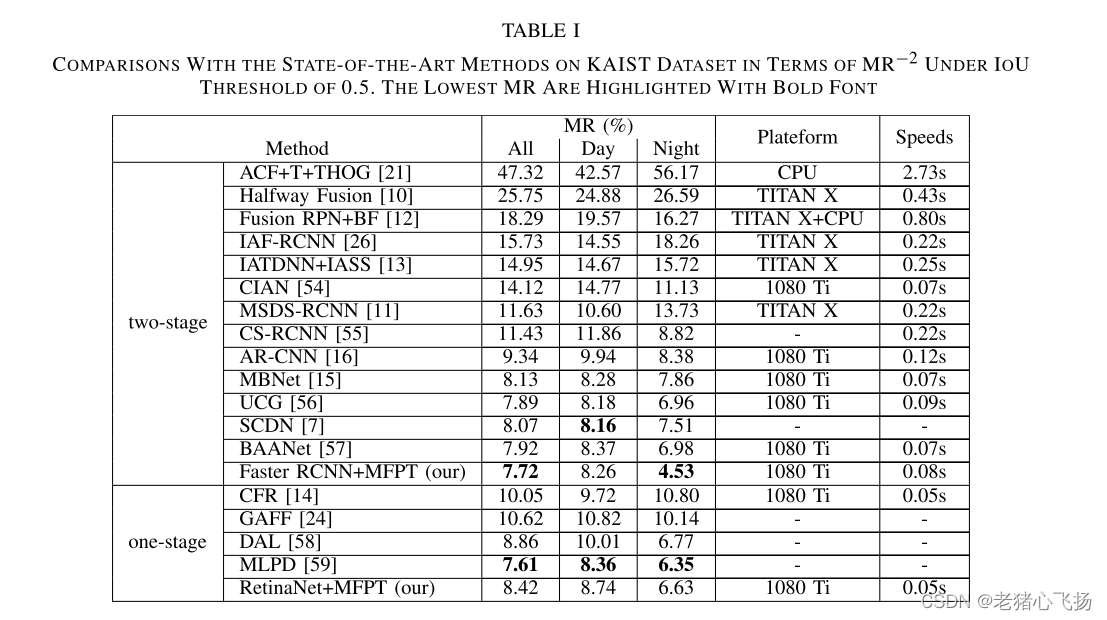
- 该方法具有以下优点:1)该方法更加灵活,可以在不同的目标检测架构中即插即用,而[59]是针对行人检测而设计的。ii)工作[59]利用了更复杂的训练策略,其中使用了完全配对的图像和半未配对的图像,而所提出的方法仅使用完全配对的图像。
- Faster RCNN+MFPT和RetinaNet+MFPT的每帧计算时间分别为0.08和0.05秒。该方法的计算时间比现有方法少或有竞争力。
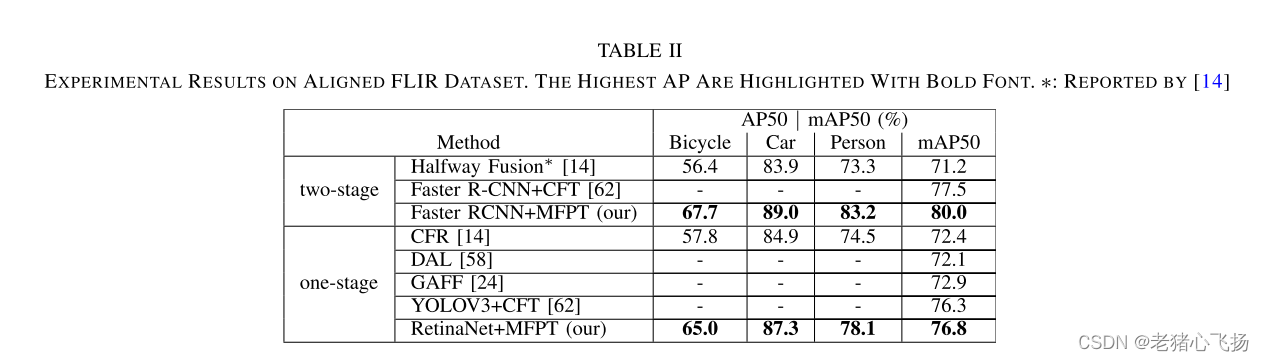
- 对齐后flir数据集的实验结果
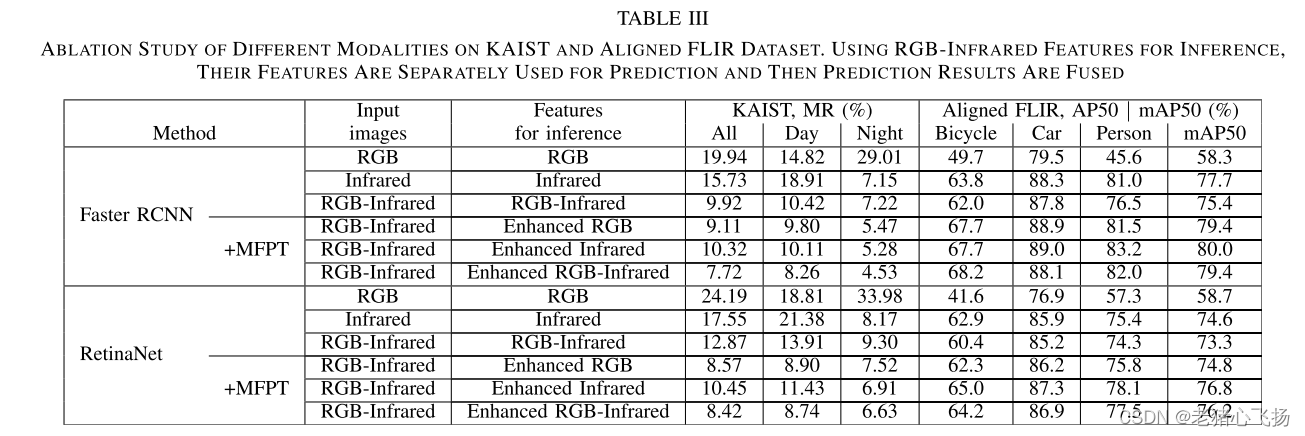
- 消融研究
- 不同模式在kaist和对准的flir数据集上的消融研究。利用rgb -红外特征进行推理,分别利用其特征进行预测,然后将预测结果进行融合
- 不同组成在kaist和对准flir数据集上的消融研究。
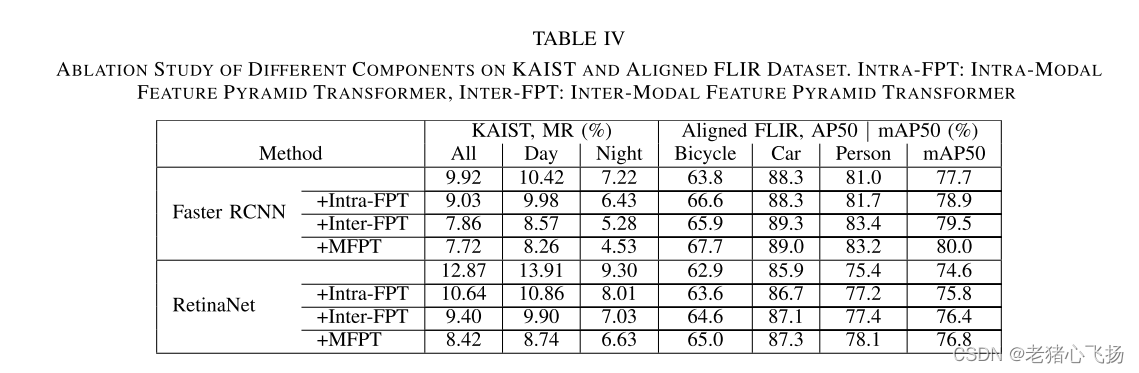
- 不同模式在kaist和对准的flir数据集上的消融研究。利用rgb -红外特征进行推理,分别利用其特征进行预测,然后将预测结果进行融合
- 对准前视红外测试数据中存在的一些不对准图像对。RGB和红外图像的地面真值标注(a)。Faster RCNN+MFPT方法增强的RGB、红外特征及其融合结果(b)。

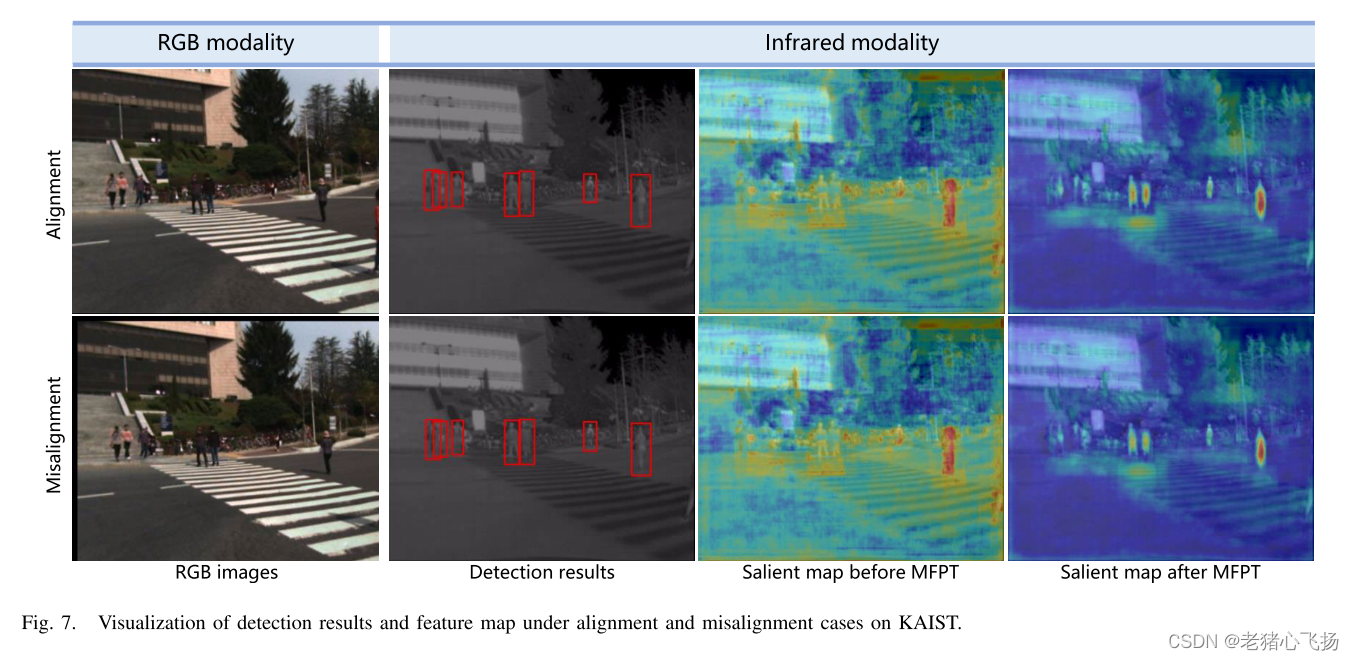
- 在韩国科学技术院(KAIST)的对齐和不对齐情况下的检测结果和特征图的可视化。
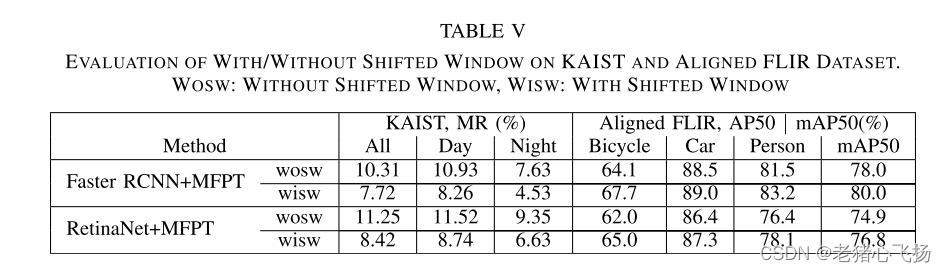
- 带/不带移位窗口在倾斜和对齐的flir数据集上的评价。wows:没有移位窗口,wisw:有移位窗口
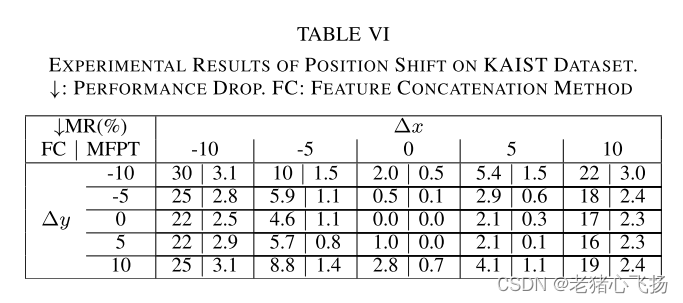
- kaist数据集上位置移位的实验结果。

















 565
565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









