







llm家族及其特点:
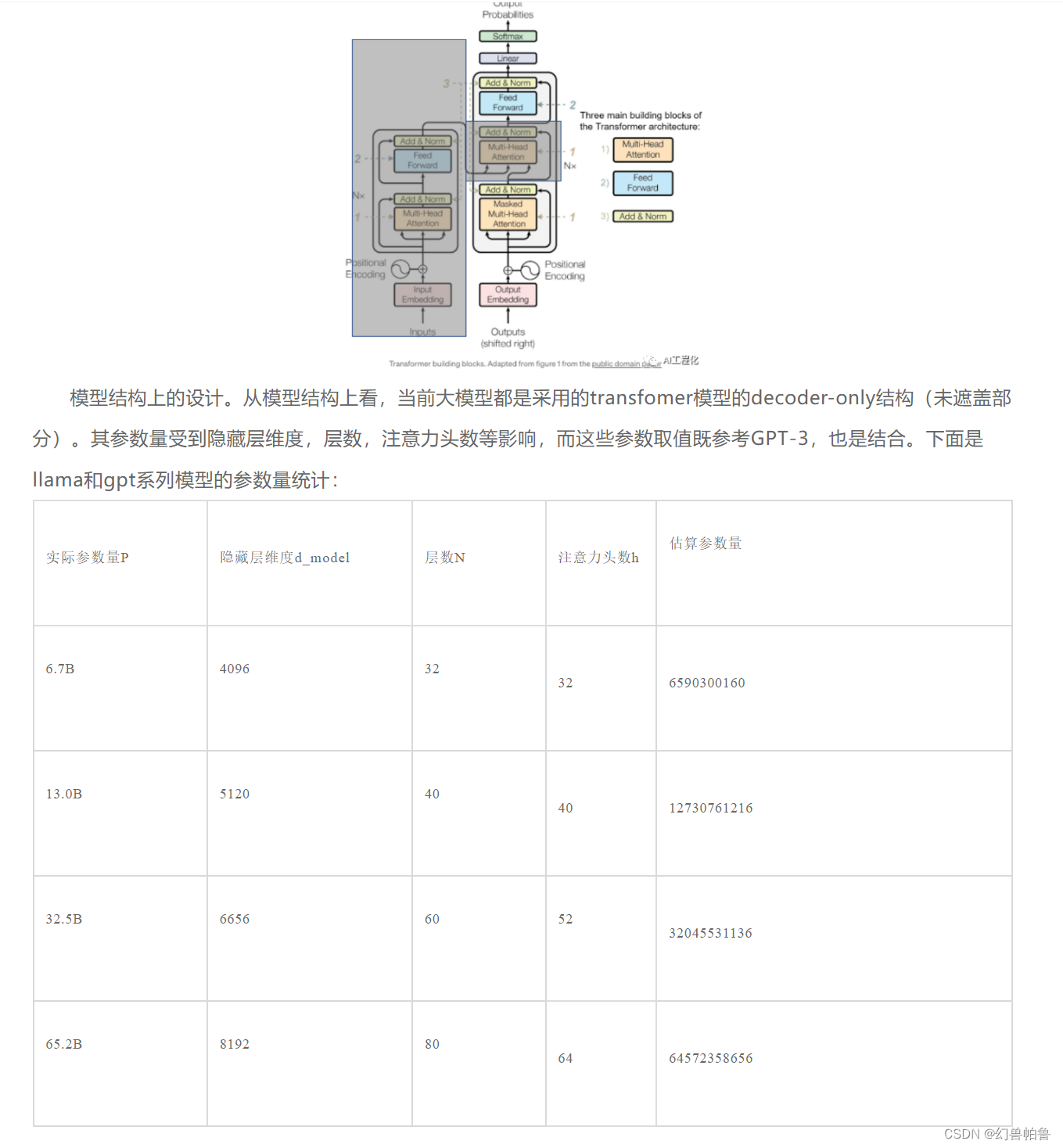
1.提出transformer:encoder+decoder架构,当时是解决lstm长序列模型遗忘,难以训练的问题。
transformer的自注意力机制可以注意到全部上下文内容,不存在远端的内容被遗忘的问题:transformer并行训练的架构也使得训练比lstm容易很多。
bert:在transformer后提出,重要的是提出了预训练这一范式,预训练=数据+训练题目,bert里用的是mask prediction和next sentence prediction。相当于是完形填空。(bert是encoder架构,侧重于全文理解。)
对于gpt这种decoder架构,它的预训练任务则是next token prediction。
其他架构?暂时还不清楚。
T5,XLnet,roberta?不知道了。
bert下游任务finetune。实际上和前面提到的大模型finetune是类似的。
GPT:最强的模型了,闭源的,参数量未知,猜测3.5是20B。
LLaMa:目前出到llama3了,有8B,70B两个版本,是稠密模型(没有MoE)
词表大小128K,前两代都是32K。训练token数15T。
6B 隐藏层维度4096,层数40层。
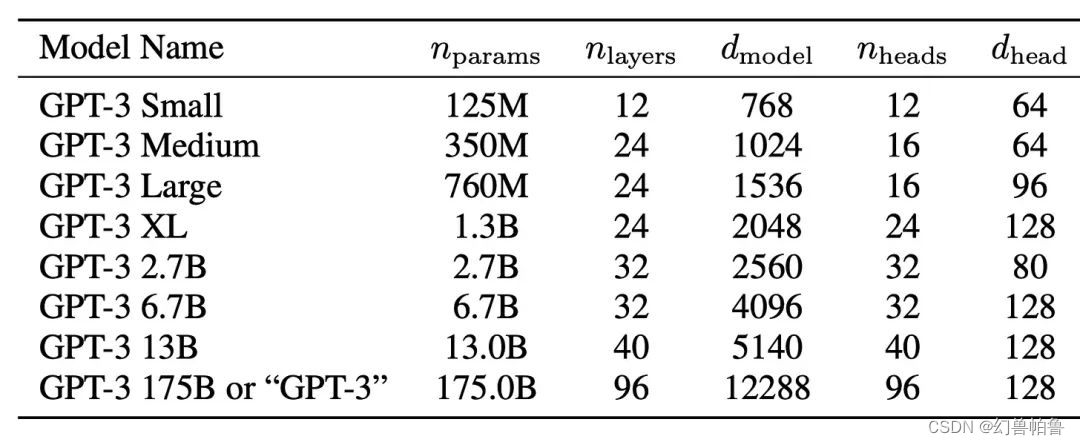
chinchilla law:训练量=6*训练token*参数量
GLM:Encoder-Decoder架构。感觉不太适合scaling law?
Internlm2:也是llama类型的架构吧,如何根据超参维度计算参数量?
MHA,MQA,GQA:MHA:一个query对应一个key。MQA:一个key对应所有query。但是这样训练难以达到最优性能。GQA:折中方案,将query和key进行分组,组内一个key对应多个query。类似于Group Convolution
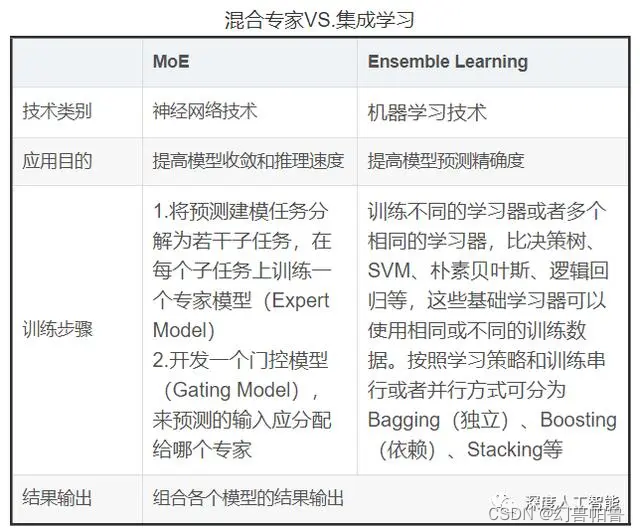
MoE架构:预测建模任务分解成若干子任务,并设计一个门控模型,预测输入应该分配给哪一个专家。如Mistral模型。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









