







RAG和Agent部分
RAG的定义:Retrieval Augmented Generation检索增强生成
RAG的过程:
RAG即 Retrieval Augmented Generation 的简称,是现阶段增强使用 LLM 的常见方式之一,其一般步骤为:
1. 文档划分(Document Split)
2. 向量嵌入(Embedding)
3. 文档获取(Retrieve)
4. Prompt 工程(Prompt Engineering)
5. 大模型问答(LLM)
通常来说,可将RAG划分为召回(Retrieve)阶段和答案生成(Answer Generate)阶段
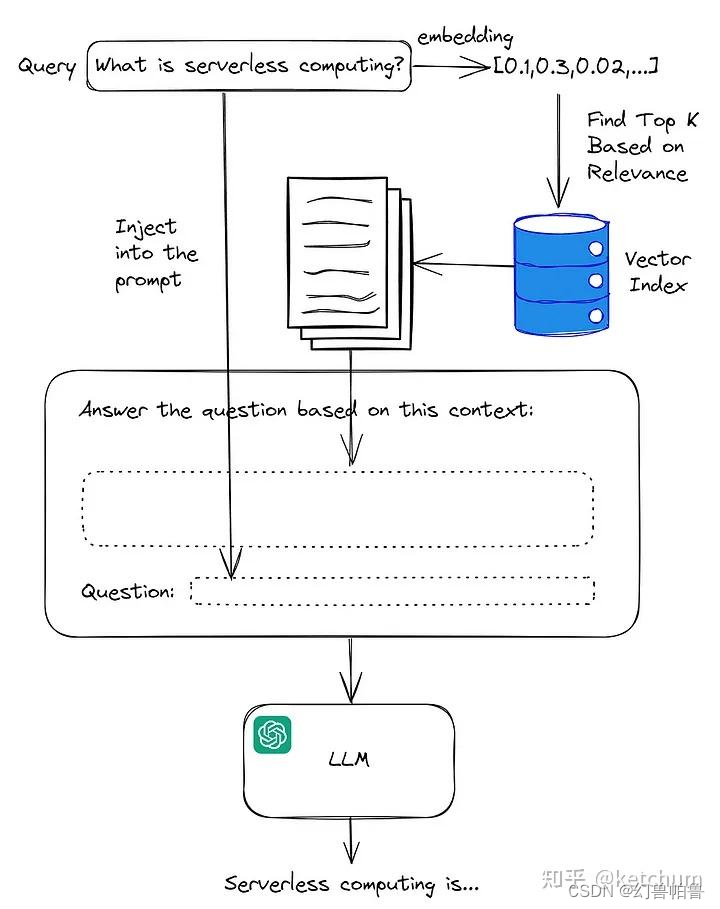
通过在外部知识库里检索匹配的知识并将信息融入prompt里。
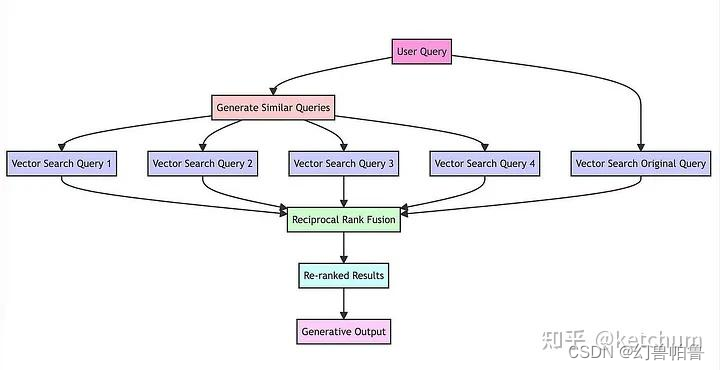
index: 我们这里用了faiss index (原来是chromadb)因为faiss index可以支持更大规模的数据集。
加载向量数据库用的embedding:我们用了bce embedding,网易的开源项目QAnything.
compressor: bcereranker:二阶段精排,把更符合用户提问的文档排在前面,过滤不相干的文档。
retriever: db_retriever 和 bm25_retriever
使用了distance_strategy=DistanceStrategy.MAX_INNER_PRODUCT
因为这里的查找是按照内积排序寻找最近似样本,所以要使得不同样本之间的距离也就是内积最大。(? 为什么不用cosine距离)
retriever的技巧:使用HyQE技术,也就是将问题——文档检索变成问题——问题检索。因为文档字数太长,问题检索的相似度较低,召回结果的准确性不够。
其他retriever:bm25retriever? 似乎和tf-idf有相似之处,体现在词的重要性和词在所有文档里的出现频率。
chain:RAG chain
chain也就是一个prompt template,将用户提问和检索到的上下文内容一起填入模版内,然后送给大模型。
You are a helpful assistant that generates multiple search queries based on a single input query.
Generate multiple search queries related to: {USER_INPUT}
OUTPUT (4 queries):
关于RAG,还有什么其他要说的?
RAG的评测:
这里采用f1指标进行评测,计算TP,FP,FN得到P和R,然后F1=2PR/(P+R)
这里采用单字重合的频率来计算P和R。是不够准确的。
在测试集为向量数据库子集的情况下,F1指标为90%以上。
可以将菜谱名提纯,将菜谱名嵌入不同的提问模板里,例如**怎么做?我想做**怎么办?检查模型对于提问的鲁棒性。
前面是测试集为向量数据库的子集时的检测指标,如果测试集非向量数据库的子集,也就是说会出现检索没有命中的情况,这时的F1指标约为45%。
我们在测试后分析发现,仅仅使用F1-score进行测试评估模型和检索器效果的局限性在于,在本项目的设计中F1-score仅关注单个字符的匹配,忽略了词汇和句子的语义相似性,从而导致较好的答案得到较低的F1-score。一个可行的替代解决方案是采用第三方LLM服务(如ChatGPT)采用其他评估标准(如faithfulness, answer relevance, context precision, context recall等)进行评估。
重复数据问题:需要做数据清洗。
使用达摩院的开源数据清洗工具data-juicer,测试多种算子:window size,tokenization,是否在sub-sentence level去重。
清洗后的150w条菜谱剩余54w条左右。
因为langchain里的检索使用暴力检索的方式,性能下降较大,每次响应时长达1分钟。使用llama-index+faiss里的HNSW64方法检索:
八、HNSWx (最重要的放在最后说)
优点:该方法为基于图检索的改进方法,检索速度极快,10亿级别秒出检索结果,而且召回率几乎可以媲美Flat,最高能达到惊人的97%。检索的时间复杂度为loglogn,几乎可以无视候选向量的量级了。并且支持分批导入,极其适合线上任务,毫秒级别体验。
缺点:构建索引极慢,占用内存极大(是Faiss中最大的,大于原向量占用的内存大小)
参数:HNSWx中的x为构建图时每个点最多连接多少个节点,x越大,构图越复杂,查询越精确,当然构建index时间也就越慢,x取4~64中的任何一个整数。
使用情况:不在乎内存,并且有充裕的时间来构建index
如下有更详细介绍
大规模向量检索库Faiss学习总结记录_faiss数据库教程-CSDN博客
Agent部分:
Agent能力也是大模型涌现能力的一种?基础模型经过指令微调以后,即可配合插件具有agent能力。
先列出几个概念:
系统提示词:internlm2里是这样的:“当开启工具以及代码时,根据需求选择合适的工具进行调用”
插件提示词:你可以使用以下插件(****)(目前看到的agent似乎只能支持1个插件在使用,可以同时支持多个插件吗?或者多个agent?)
具体怎么组合这些提示词?在formatted里,把这些都作为system prompt前置传入大模型。
{“role": "system”, "content":"*****"}
在agent执行过程中,用户输入prompt,然后大模型解析prompt提取参数传入插件,插件嵌入参数后执行对应的action,返回结果(或错误代码)给大模型,大模型再加工结果返回给用户。
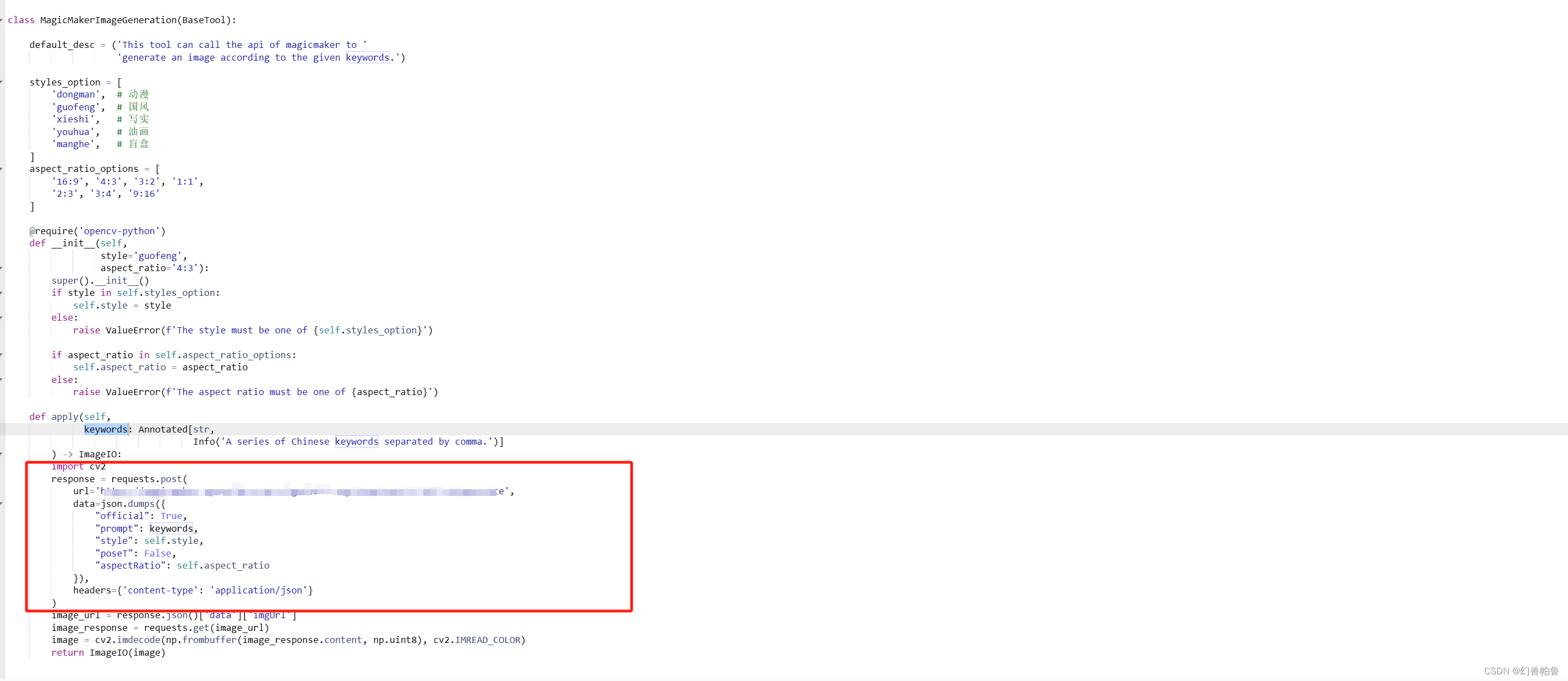
Agent本身并不神秘,像画图的Agent,也只需要在基础模型上增加一些画图指令到调用插件的微调数据集而已。大模型的能力是很强的,要相信这一点。因此食神项目的文生图功能 一样可以转交给agent模块来做。
例如教程里提供的例子,就是把prompt传入magicmaker,而后者是一个文生图的网站接口。
大模型评价:
目前用到的是OpenCompass。包含学科、语言、知识、理解、推理五大维度。
其他基本的评价指标:
MMLU:多语言理解能力。(中文的测试集是教育网上爬取的试卷,按acc方式计算指标)
GLUE:glue有9个指标,分别是CoLA、SST-2、MRPC、STS-B、QQP、MNLI、QNLI、RTE、WNLI。
C-Eval:
MT-bench:BLEU(机器翻译的指标,机器翻译和人工翻译比较n-gram相似度)
perplexity:给出上下文时,生成下一个词的概率的乘积。(N-gram模型)















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









