







 本文探讨了大模型finetuning的各种策略,如LORA的低秩假设、Adapter和AdapterFusion,以及Prefix-Tuning、P-Tuning和Prompt-Tuning在自然语言处理任务中的应用。同时关注了大模型训练中的内存优化,包括量化技术(如FP16、BF16)和DeepspeedZero的分片策略,以减少显存占用。
本文探讨了大模型finetuning的各种策略,如LORA的低秩假设、Adapter和AdapterFusion,以及Prefix-Tuning、P-Tuning和Prompt-Tuning在自然语言处理任务中的应用。同时关注了大模型训练中的内存优化,包括量化技术(如FP16、BF16)和DeepspeedZero的分片策略,以减少显存占用。
关于finetune,模型训练等
为什么要finetune?finetune一般是在base模型或者别人训练好的模型上,为了让模型更适应特定任务或领域某种应用场景,让模型学习输入到输出的映射关系。
finetune大模型,成本越来越高,不可能重新训练所有参数。
finetune的方法及优缺点:
1.lora 假设模型在微调过程中权重的改变是低秩的,lora是改变权重密集层变化的秩分解矩阵来间接训练神经网络里的密集层,同时保持预训练的权重不变。
在非 token embedding 的每一层 linear 增加一些低秩矩阵,来作为训练参数。
例如一个 token embedding 的维度是 [input_feature, output_feature],那么增加如下两个 lora 参数:
- lora_right_weight: [input_feature, k]
- lora_left_weight: [k, output_feature],
在 forward 过程中,将输入作用到 lora 的参数上,将输出作用到 linear 层原本的输出上。
正常的 Linear forward 中执行如下计算:
output = F.linear(input, weight, bias)LoRA Linear 执行如下计算:
output = F.linear(input, weight, bias)
lora_output = dropout(input) @ lora_right_weight @ lora_left_weight
output += lora_output * lora_scalinglora就是在原来的预训练权重上开了一个支路,认为这个支路的权重应该是低秩的,所以可以用BA来表示这个权重(其中A使用高斯分布初始化,B使用0初始化,当然也可以反过来)。疑问:如果这样,可以不只是把lora作用在attention权重上,而是放在任意层。attention层的含义是什么?哪些层是更接近下游任务,哪些层又接近知识表示?不同层的优化可能可以设置不同的秩。
qlora相比于lora,就是采取了量化的手段,用更低的精度存储权重,在训练时使用更高的精度?。
2.adapter:在预训练的某一层添加adapter模块,训练时冻结预训练参数,由adapter层学习新知识和任务。adapterfusion。。。
3.prefix-tuning: 前缀微调将一个连续的特定于任务的向量序列添加到输入,和prompt不同的是,没有token对应前缀序列,是完全自由的参数。
来自知乎评论:要是仔细看prefix tuning的源码,实际上是把前缀当成past key values传到llm里,llm内selfattention对past key value的逻辑是要么直接当成key和value,要么和原有的key和value拼接。所以实际上prefix只是讲故事,核心是扩大已知query的kv搜索空间
来自知乎2:
Prefix tuning 是为自然语言生成任务设计的,和 prompt tuning 十分的像,也是将 pretrain 好了的模型 freeze 住,在输入前面增加 prompt embedding 用于训练。
区别在于,prompt tuning 只把 prompt embedding 增加到 input embedding 上,而 prefix tuning 将 prefix activation 增加到每一层的中间变量上,等效于加宽了每一层的网络参数。
prefix tuning 的作者发现这样 finetune 的性能可以与全量 finetune 媲美,而且只需要 1/1000 的训练参数量,如果训练数据比较少的情况下,prefix tuning 甚至可以取得更好的效果。
下图上半子图表示的是正常的 finetune 流程,下半子图在输入输出的最开头,每个任务增加了两个 prefix embedding,该 embedding 会参与训练,不断更新。
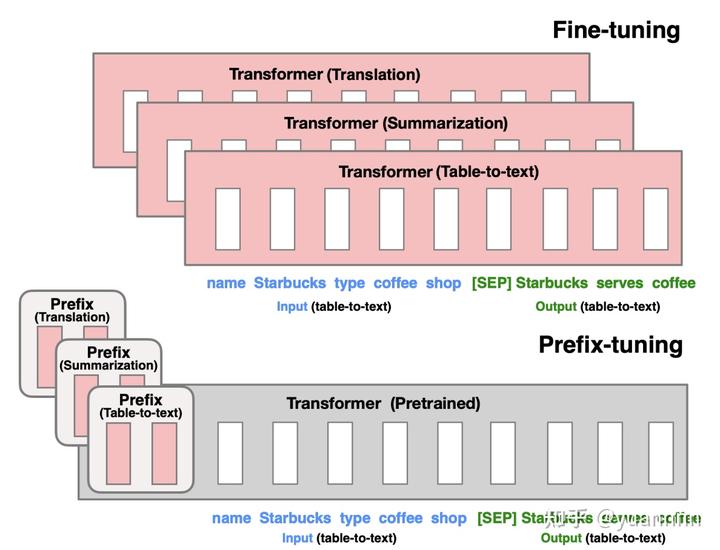
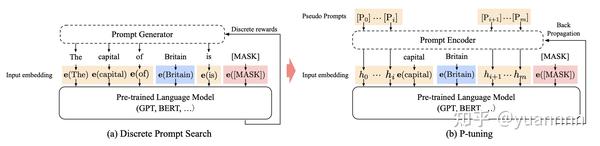
4.p-tuning:
P tuning 也是为自然语言生成任务设计的,和 prompt tuning 也很像,区别在于:
- prompt embedding 可以放在 input embedding 的任意位置,而非一定要在句首
- prompt encoder 增加了 LSTM 到 prompt encoder,增加了深度和复杂度
- 增加了 anchor token 的概念
下图中可以看到,橙色部分是 prompt embedding,它可以被添加到文本的任意位置,并且通过 prompt encoder 变为了 hidden state。
5.prompt-tuning:Prompt-tuning给每个任务定义了自己的Prompt,拼接到数据上作为输入,同时freeze预训练模型进行训练,在没有加额外层的情况下,可以看到随着模型体积增大效果越来越好,最终追上了精调的效果。 也就是指令微调了。?
是针对 T5 模型在文本分类任务上做的,它把所有任务都做成生成任务,比如说文本分类任务,把需要分类的文本当作输入的 context,而分类的标签结果通过模型生成任务生成。
Prompt tuning 是在 fintune 时,freeze pretrain 的参数,在 input embedding 前面加上一些 prompt embedding,成为 [prompt embedding, input embedding],而这些 prompt embedding 通过可训练 prompt encoder 映射得到,等价于增加了 input embedding 参数。

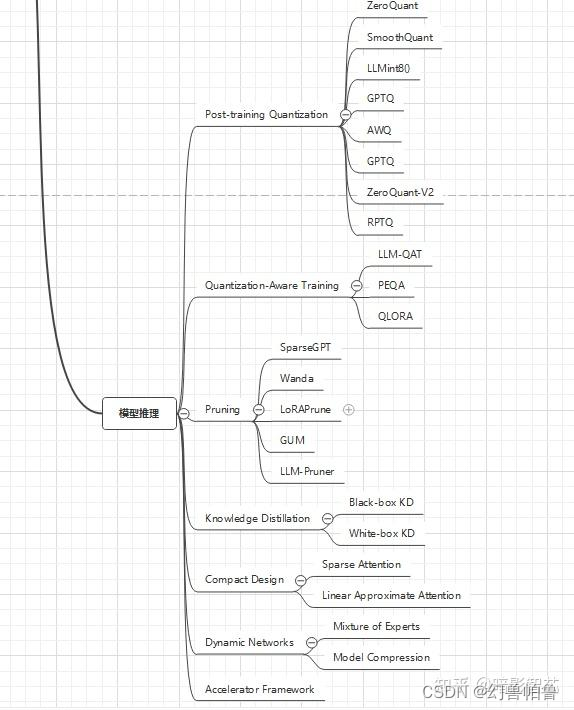
大模型训练的内存大小问题:
假设一个6B大小的模型,推理过程需要多少显存?
如果不量化,fp32精度一个数是4个字节,一个6B模型占用字节数为6B*4 = 24GB。int8量化是6GB。半精度bf16是12GB。
fp16是5整数位+10精度位
bf16是8整数位+7精度位
量化就是按scale放缩,然后转化成相应的精度类型存储。
训练:如果使用半精度训练,全量训练一共需要大概是6B*4.(这个结论记得,但是推导过程忘了)
模型参数:如果用fp32,就是6*4GB
梯度:全量训练,和模型参数一样数量,也是6*4
优化器状态:对于AdamW来说,要一阶和二阶momentum,这里需要两倍模型参数量的大小。
AdamW的公式?
Adam:

其实AdamW和Adam唯一的区别,就是weight decay的加入方式。
在Adam当中,weight decay是直接加入到梯度当中:
![]()
其中是当前step的梯度,是上一个step中的模型权重,是正则化系数。
而在AdamW中,正则化变成了:
![]()
其中是学习率。
所以AdamW的思路特别简单:反正正则化系数加进梯度之后最终也要在权重上进行更新,那为什么还需要加进梯度去呢?因此,AdamW直接在权重上进行衰减,在收敛速度上也能领先于Adam。

此外还有cuda kernel的占用。
lora是6B*2 +一点点 大概14GB的现存。
deepspeed zero 加上cpu offload减少显存占用。原理?
数据并行+模型并行
数据并行:每个gpu上有一个完整的副本
模型并行:分为流水线并行或张量并行
流水线并行:前后部分分开,可能有等待时间
张量并行:网络分块,不同gpu计算不同节点,可能有通信开销
zero的优化思想为:针对模型状态部分,Zero 使用的方法是分片,即每张卡只存 1𝑁 的模型状态量,N是GPU个数 。但是本质上 ZERO 仍然属于一种数据并行方案。
一个常用的结论如下:
- 速度: Zero 1 > Zero 2 > Zero 2 + offload > zero 3 > zero 3 + offload
- 显存:阶段 0 (DDP) < 阶段 1 < 阶段 2 < 阶段 2 + 卸载 < 阶段 3 < 阶段 3 + 卸
Deepspeed 的优化细节
- Deepspeed Zero Stage 1
针对 Adam 状态进行分片,此时每张卡模型状态所需显存变成了 2𝐴+2𝐴+12𝐴𝑁 。我们以单机8卡,7B模型为例,此时模型状态部分所需显存 降低到 4 * 7 + (12*7)/8 = 38.5GB。
- Deepspeed Zero Stage 2
在Zero-1 的基础上,针对模型梯度再次分片,此时每张卡模型状态所需显存变成了 2𝐴+2𝐴+12𝐴𝑁
同样以单机8卡,7B模型为例,此时模型状态部分所需显存降低到 2*7+(14*7)/8=26.25GB。
- Deepspeed Zero Stage 3
在Zero-2的基础上,对模型参数也进行分片,此时每张卡模型状态所需显存变成了 2𝐴+2𝐴+(4𝐴+4𝐴+4𝐴)𝑁=16𝐴𝑁 。
同样以单机8卡,7B模型为例,此时模型状态部分所需显存降低到 16*7/8=14GB















 880
880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









