






最近看了一下百度paddlespeech的一些公开课,把课程里的视频内容大体听了一下,现在整理一下笔记。教程链接见:飞桨AI Studio星河社区-人工智能学习与实训社区
语音识别的过程可以这样简单概括:
将声音信号经过预加重、加窗、fft等转化成频谱图,横轴是频率,纵轴是能量大小。然后经过mel滤波器变成mel频谱图。
然后的处理方法,有的是直接经过取对数操作变成logfbank特征;有的去除了相邻频段的重叠相关部分,就是mfcc特征。现在深度学习有用到重叠相关性,用logfbank的比较多。
声音特征经过声学模型,输出每一帧的识别文字和对应的概率。声学模型框架课程里介绍了两种,一种是deepspeech,一种是基于transformer的conformer。
deepspeech2采用了两层降采样的cnn和多层rnn组成。
deepspeech2是使用cnn提取局部特征,减少模型输入帧数,降低计算量,易于模型收敛;这也就是为什么有了cnn以后,不再需要mfcc等人工特征提取相对独立的信号了(或者说是能量的本征值?)。
rnn的作用是获取语音的上下文信息,获得更加准确的信息,进行一定程度的语义消歧。
softmax将特征向量映射到一个字表长度的向量。
decoder是将encoder的概率解码成最终的文字结果。
ctc的解码有3种方式:
CTC greedy search
CTC beam search
CTC Prefix beam search
prefix beam search合并了生成重复项的概率(因为ctc的对齐方式就是允许有重复项,但是最后会把相邻的重复项或空格合并成一个token。)
ctc的对齐是很有用的,利用了单调有序性(就是说语音里文字的前后关系也对应识别文字的前后关系。)但是语音转译就没这么好的条件利用了,例如good morning应该翻译成“早上好”。
还说回语音识别,另一种方式是conformer,前身是espnet。conformer的encoder部分是一个“汉堡包”类型的模型结构,而且他是layernorm在前面,然后接mha,然后接一个残差连接:
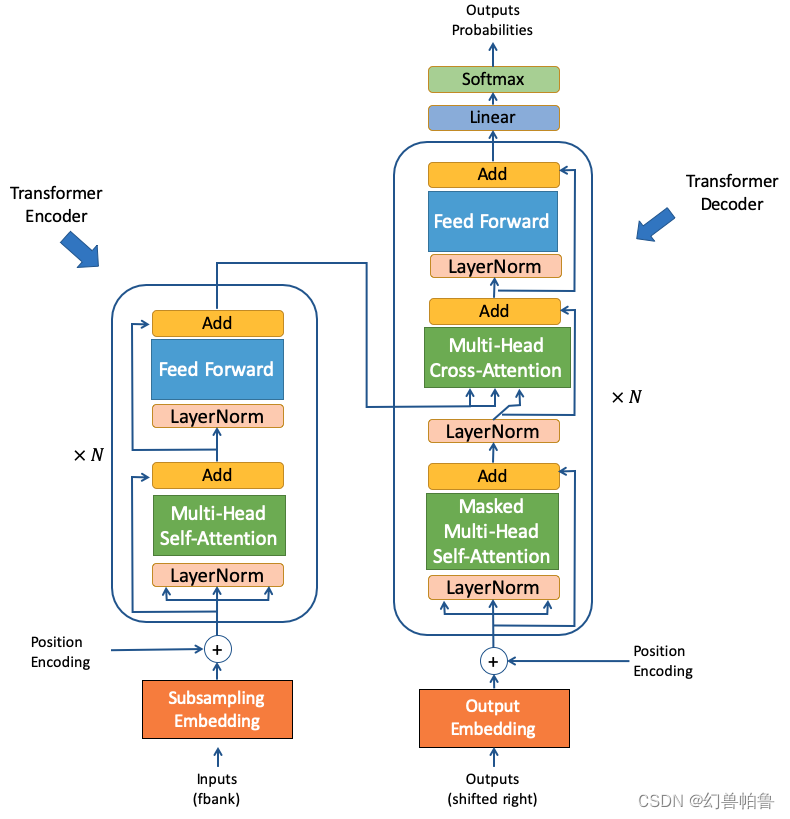
transformer相比rnn,可以更有效的捕捉到长距离的依赖关系。采用自回归的方法生成数据,也就是说用识别到的文字作为key,encode编码作为q和v,来生成下一个文字。
模型训练同时使用了 CTC 损失和 cross entropy 交叉熵损失进行损失函数的计算。
其中 Encoder 输出的特征直接进入 CTC Decoder 得到 CTC 损失。
而 Decoder 的输出使用 cross entropy 损失。
声纹识别有两种模式:1:1(声纹密码,安全)和1:N(从声纹库里提取,说话人分离)
现在利用x-vector来识别。
工业场景应用痛点:
1.没有标注数据,只有无监督数据
2.跨域场景性能下降严重
3.超大规模说话人训练
4.难分样本
痛点1:无监督比对学习,用已有的标注数据生成无监督样本,然后训练模型把不同说话人能有效分隔开。
痛点2:领域对抗学习,只需新增1条支路,建立特征对抗
痛点3:将多分类转换成二分类任务(语音/noise)
痛点4:解决长尾问题:focal loss,提升难分样本权重;ghm,不应特别关注困难样本,而应在一定范围内关注















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









