






最近在打通飞书多维表格所记录的任务单到工时系统的自动同步,一开始以为很简单,所需要的字段毕竟都是现成的,夸下海口一天绝对没问题,实际上手才发现由于对飞书和Golang的不熟悉,踩了很多坑。
飞书多维表格支持直接创建自动化流程,步骤如下:
- 设置一个定时任务(或手动触发)
- 筛选出日期为前一天的所有记录的姓名,工作内容,工时等字段
- 上述字段提取出来发送 Http 请求至公网接口(否则我都想直接写一个python服务端了)进行同步
这个过程恰如把大象放进冰箱一样简单,但事实上,有个尬住的点在于飞书多维表格的人员类型字段发送的Http请求默认是中文名,但工时系统所能接受的姓名是英文id,也就是企业里取的用于登录和标识的英文花名。点开该人员类型的值是一个名片,中英文名都能直接显示,按道理应该十分简单

但询问了飞书官方人员,甚至升级到了专家协助解决,过了大半天专家竟建议我维护一张中英文名的映射表,然后在我的多维表格中创建一个引用,一时语塞,互联网的人员流动性下,维护这张表的成本太高了。

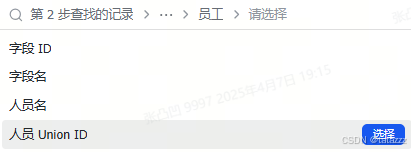
求人不如求己,我相信这个名片类型的数据结构一定是有意义的,最终还是找到了下面的解决方案:第2步中筛选出前一天的记录的人员类型字段,将这个字段向下继续选择就找到了一个 UnionId,这应该就是名片的引用来源,所以将这个值打包成一个 http 请求体,发送到下面的接口,即可获取英文名。
https://open.feishu.cn/document/server-docs/contact-v3/user/get
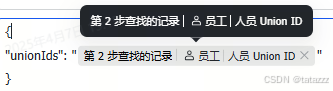
以为只要解决了这个问题就能顺风顺水,毕竟所有需要发送的字段值都已经就绪,下面只要把上一步获取的英文名和第2步中获取的其他值拼接在一起构造一个 Http 请求体发送到工时系统接口即可。
事实上真正的折磨才刚刚开始,早早就听说过序列化和反序列化的威名,小实习生只能说百闻不如一见。
如上面提到的,构造了下面的请求体:

事实上服务端中获取到的请求体却是
{
"total" : 5,
"data" : "{"status_code":200,"$startTime":1743682890447,"$endTime":1743682893744,"body":{"msg":"ok","traceId":"","code":2000,"data":{"ads":"xxx,xxx,xxx,xxx,xxx"}},"headers":{"Access-Control-Expose-Headers":"Content-Length, Access-Control-Allow-Origin, Access-Control-Allow-Headers, Cache-Control, Content-Language, Content-Type","Content-Length":"109","Content-Type":"application/json; charset=utf-8","Date":"Thu, 03 Apr 2025 12:21:33 GMT","Access-Control-Allow-Credentials":"true","Access-Control-Allow-Headers":"Origin, X-Requested-With, Content-Type, Accept, Authorization","Access-Control-Allow-Methods":"POST, GET, OPTIONS, PUT, DELETE, UPDATE","Access-Control-Allow-Origin":"*"}}",
"dates": "2025/04/01, 2025/04/01, 2025/04/01, 2025/04/01, 2025/04/01",
"projects" : "xxx,xxx,xxx,xxx,xxx",
"contents" : "xxx, xxx, xxx, xxx, xxx",
"hours" : "0.1, 0.1, 0.1, 0.1, 0.1"
}
我想要解析到下面这个类中,类型都是字符串,Data 本身同样是一个 Json,再用 NestedAdData 类再次解析一次就能获取到我想要的 Body 中的 Data 中的 ads 英文名字段了。
type FeishuTssPayloads struct {
Total int `json:"total"`
Data string `json:"data"`
Dates string `json:"dates"`
Projects string `json:"projects"`
Contents string `json:"contents"`
Hours string `json:"hours"`
}
type NestedAdData struct {
Body Body `json:"body"`
Headers map[string]string `json:"headers"`
StatusCode int `json:"status_code"`
StartTime int64 `json:"$startTime"`
EndTime int64 `json:"$endTime"`
}
type Body struct {
TraceId string `json:"traceId"`
Code int `json:"code"`
Data struct {
Ads string `json:"ads"`
} `json:"data"`
Msg string `json:"msg"`
}
这三个数据结构也花了一些时间,一开始想直接将Data的类型设置为下面的 NestedAdData,但事实上看请求体就能知道其实嵌套再多层,本质上也只是一个字符串。
但 Body 就不同了,大括号前面是没有双引号的,这才是区分的标准,也要感谢下面这篇博客,让 go 和 json 双重小白很快理解了这一点
https://xiaorui.cc/archives/2858
到了这里,长征走了99%,只要两行 json.Unmarshal() 就能解决问题了。最后一个坑跳了出来,嵌套 json 的解析,这也正是写这个流水账的初衷,网上关于 Golang 的嵌套 json 解析的内容似乎不太充实
json 在解析的时候,是根据相关字符来判断json的开始和结束的,这种嵌套的json,事实上会在下面这个位置就识别为json已经结束,会报错 json : invalid character ‘}’ after object key,解决方案非常好想,转义字符就能解决,因此需要在解析之前先提取出字符串然后用正则表达式将 data 下的内容中的引号进行转义,
{
"total" : 5,
"data" : "{" //start...
直接上代码,供参考
body, _ := ioutil.ReadAll(c.Request.Body)
rawJSON := string(body)
// 1. 获取【"data":】和【"dates":】之间的字符串内容dataStr
startIndex := strings.Index(rawJSON, `"data"`)
startIndex += len(`"data": "`)
endIndex := strings.Index(rawJSON[startIndex:], `"dates"`)
endIndex += startIndex
dataStr := rawJSON[startIndex:endIndex]
// 2. dataStr中,除了第一个和最后一个引号 其余的引号均转义为\"
var escapedDataStr string
if len(dataStr) > 0 {
innerStr := dataStr[1 : len(dataStr)-1]
escapedInnerStr := strings.ReplaceAll(innerStr, `"`, `\"`)
escapedDataStr = "\"" + escapedInnerStr[:len(escapedInnerStr)-3] + escapedInnerStr[len(escapedInnerStr)-2:] + "\n"
}
// 3. 将escapedDataStr 替换到原来的rawJSON中对应的位置
newJSON := rawJSON[:startIndex] + escapedDataStr + rawJSON[endIndex:]
var req entity.FeishuTssPayloads
err := json.Unmarshal([]byte(newJSON), &req)
var nestedAdData entity.NestedAdData
err = json.Unmarshal([]byte(req.Data), &nestedAdData)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









