










本文接着上一篇博客,如果您未阅读上篇博客,请点击【数据分析与挖掘实战】金融风控之贷款违约预测详解1(有代码和数据集)
七.建模和调参
7.1模型相关原理介绍
由于相关算法原理篇幅较长,本文推荐了一些博客供初学者们进行学习。
7.1.1 逻辑回归模型
7.1.2 决策树模型
7.1.3GBDT模型
7.1.4 XGBoost模型
7.1.5 LightGBM模型
7.1.6 Catboost模型
7.2 模型对比与性能评估
7.2.1逻辑回归
优点
- 训练速度较快,分类的时候,计算量仅仅只和特征的数目相关;
简单易理解,模型的可解释性非常好,从特征的权重可以看到不同的特征对最后结果的影响;
适合二分类问题,不需要缩放输入特征;
内存资源占用小,只需要存储各个维度的特征值;
缺点
- 逻辑回归需要预先处理缺失值和异常值【】;
不能用Logistic回归去解决非线性问题,因为Logistic的决策面是线性的;
对多重共线性数据较为敏感,且很难处理数据不平衡的问题;
准确率并不是很高,因为形式非常简单,很难去拟合数据的真实分布;
7.2.2 决策树模型
优点
简单直观,生成的决策树可以可视化展示
数据不需要预处理,不需要归一化,不需要处理缺失数据
既可以处理离散值,也可以处理连续值
缺点
决策树算法非常容易过拟合,导致泛化能力不强(可进行适当的剪枝)
采用的是贪心算法,容易得到局部最优解
7.2.3 集成模型集成方法(ensemble method)
通过组合多个学习器来完成学习任务,通过集成方法,可以将多个弱学习器组合成一个强分类器,因此集成学习的泛化能力一般比单一分类器要好。
集成方法主要包括Bagging和Boosting,Bagging和Boosting都是将已有的分类或回归算法通过一定方式组合起来,形成一个更加强大的分类。两种方法都是把若干个分类器整合为一个分类器的方法,只是整合的方式不一样,最终得到不一样的效果。常见的基于Baggin思想的集成模型有:随机森林、基于Boosting思想的集成模型有:Adaboost、GBDT、XgBoost、LightGBM等。
Baggin和Boosting的区别总结如下:
样本选择上: Bagging方法的训练集是从原始集中有放回的选取,所以从原始集中选出的各轮训练集之间是独立的;而Boosting方法需要每一轮的训练集不变,只是训练集中每个样本在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整
样例权重上: Bagging方法使用均匀取样,所以每个样本的权重相等;而Boosting方法根据错误率不断调整样本的权值,错误率越大则权重越大
预测函数上: Bagging方法中所有预测函数的权重相等;而Boosting方法中每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重
并行计算上: Bagging方法中各个预测函数可以并行生成;而Boosting方法各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
7.2.4 模型评估方法
对于数据集的划分有三种方法:留出法,交叉验证法和自助法
模型评价标准有auc,ks,fi-score,roc等等,上篇博客有介绍【数据分析与挖掘实战】金融风控之贷款违约预测详解1(有代码和数据集)
7.3代码示例
import pandas as pd
import numpy as np
import warnings
import os
import seaborn as sns
import matplotlib.pyplot as plt
"""
sns 相关设置
@return:
"""
# 声明使用 Seaborn 样式
sns.set()
# 有五种seaborn的绘图风格,它们分别是:darkgrid, whitegrid, dark, white, ticks。默认的主题是darkgrid。
sns.set_style("whitegrid")
# 有四个预置的环境,按大小从小到大排列分别为:paper, notebook, talk, poster。其中,notebook是默认的。
sns.set_context('talk')
# 中文字体设置-黑体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决保存图像是负号'-'显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
# 解决Seaborn中文显示问题并调整字体大小
sns.set(font='SimHei')
7.4简单建模
Tips1:金融风控的实际项目多涉及到信用评分,因此需要模型特征具有较好的可解释性,所以目前在实际项目中多还是以逻辑回归作为基础模型。但是在比赛中以得分高低为准,不需要严谨的可解释性,所以大多基于集成算法进行建模。
Tips2:因为逻辑回归的算法特性,需要提前对异常值、缺失值数据进行处理【参考task3部分】
Tips3:基于树模型的算法特性,异常值、缺失值处理可以跳过,但是对于业务较为了解的同学也可以自己对缺失异常值进行处理,效果可能会更优于模型处理的结果。
注:以下建模的源数据参考baseline进行了相应的特征工程,对于异常缺失值未进行相应的处理操作。
建模之前的预操作
from sklearn.model_selection import KFold
# 分离数据集,方便进行交叉验证
X_train = data.loc[data['sample']=='train', :].drop(['id','issueDate','isDefault', 'sample'], axis=1)
X_test = data.loc[data['sample']=='test', :].drop(['id','issueDate','isDefault', 'sample'], axis=1)
y_train = data.loc[data['sample']=='train', 'isDefault']
# 5折交叉验证
folds = 5
seed = 2020
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
使用Lightgbm进行建模
"""对训练集数据进行划分,分成训练集和验证集,并进行相应的操作"""
from sklearn.model_selection import train_test_split
import lightgbm as lgb
# 数据集划分
X_train_split, X_val, y_train_split, y_val = train_test_split(X_train, y_train, test_size=0.2)
train_matrix = lgb.Dataset(X_train_split, label=y_train_split)
valid_matrix = lgb.Dataset(X_val, label=y_val)
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'learning_rate': 0.1,
'metric': 'auc',
'min_child_weight': 1e-3,
'num_leaves': 31,
'max_depth': -1,
'reg_lambda': 0,
'reg_alpha': 0,
'feature_fraction': 1,
'bagging_fraction': 1,
'bagging_freq': 0,
'seed': 2020,
'nthread': 8,
'silent': True,
'verbose': -1,
}
"""使用训练集数据进行模型训练"""
model = lgb.train(params, train_set=train_matrix, valid_sets=valid_matrix, num_boost_round=20000, verbose_eval=1000, early_stopping_rounds=200)

对验证集进行预测
from sklearn import metrics
from sklearn.metrics import roc_auc_score
"""预测并计算roc的相关指标"""
val_pre_lgb = model.predict(X_val, num_iteration=model.best_iteration)
fpr, tpr, threshold = metrics.roc_curve(y_val, val_pre_lgb)
roc_auc = metrics.auc(fpr, tpr)
print('未调参前lightgbm单模型在验证集上的AUC:{}'.format(roc_auc))
"""画出roc曲线图"""
plt.figure(figsize=(8, 8))
plt.title('Validation ROC')
plt.plot(fpr, tpr, 'b', label = 'Val AUC = %0.4f' % roc_auc)
plt.ylim(0,1)
plt.xlim(0,1)
plt.legend(loc='best')
plt.title('ROC')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
# 画出对角线
plt.plot([0,1],[0,1],'r--')
plt.show()

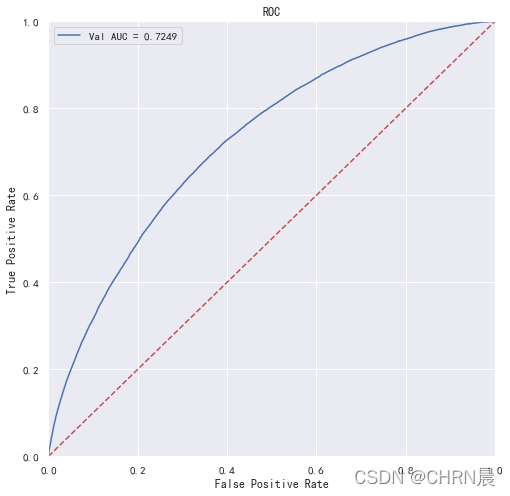
更进一步的,使用5折交叉验证进行模型性能评估
import lightgbm as lgb
"""使用lightgbm 5折交叉验证进行建模预测"""
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(X_train, y_train)):
print('************************************ {} ************************************'.format(str(i+1)))
X_train_split, y_train_split, X_val, y_val = X_train.iloc[train_index], y_train[train_index], X_train.iloc[valid_index], y_train[valid_index]
train_matrix = lgb.Dataset(X_train_split, label=y_train_split)
valid_matrix = lgb.Dataset(X_val, label=y_val)
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'learning_rate': 0.1,
'metric': 'auc',
'min_child_weight': 1e-3,
'num_leaves': 31,
'max_depth': -1,
'reg_lambda': 0,
'reg_alpha': 0,
'feature_fraction': 1,
'bagging_fraction': 1,
'bagging_freq': 0,
'seed': 2020,
'nthread': 8,
'silent': True,
'verbose': -1,
}
model = lgb.train(params, train_set=train_matrix, num_boost_round=20000, valid_sets=valid_matrix, verbose_eval=1000, early_stopping_rounds=200)
val_pred = model.predict(X_val, num_iteration=model.best_iteration)
cv_scores.append(roc_auc_score(y_val, val_pred))
print(cv_scores)
print("lgb_scotrainre_list:{}".format(cv_scores))
print("lgb_score_mean:{}".format(np.mean(cv_scores)))
print("lgb_score_std:{}".format(np.std(cv_scores)))

7.5模型调参
贪心调参
先使用当前对模型影响最大的参数进行调优,达到当前参数下的模型最优化,再使用对模型影响次之的参数进行调优,如此下去,直到所有的参数调整完毕。
这个方法的缺点就是可能会调到局部最优而不是全局最优,但是只需要一步一步的进行参数最优化调试即可,容易理解。
需要注意的是在树模型中参数调整的顺序,也就是各个参数对模型的影响程度,这里列举一下日常调参过程中常用的参数和调参顺序:
①:max_depth、num_leaves
②:min_data_in_leaf、min_child_weight
③:bagging_fraction、 feature_fraction、bagging_freq
④:reg_lambda、reg_alpha
⑤:min_split_gain
from sklearn.model_selection import cross_val_score
# 调objective
best_obj = dict()
for obj in objective:
model = LGBMRegressor(objective=obj)
"""预测并计算roc的相关指标"""
score = cross_val_score(model, X_train, y_train, cv=5, scoring='roc_auc').mean()
best_obj[obj] = score
# num_leaves
best_leaves = dict()
for leaves in num_leaves:
model = LGBMRegressor(objective=min(best_obj.items(), key=lambda x:x[1])[0], num_leaves=leaves)
"""预测并计算roc的相关指标"""
score = cross_val_score(model, X_train, y_train, cv=5, scoring='roc_auc').mean()
best_leaves[leaves] = score
# max_depth
best_depth = dict()
for depth in max_depth:
model = LGBMRegressor(objective=min(best_obj.items(), key=lambda x:x[1])[0],
num_leaves=min(best_leaves.items(), key=lambda x:x[1])[0],
max_depth=depth)
"""预测并计算roc的相关指标"""
score = cross_val_score(model, X_train, y_train, cv=5, scoring='roc_auc').mean()
best_depth[depth] = score
"""
可依次将模型的参数通过上面的方式进行调整优化,并且通过可视化观察在每一个最优参数下模型的得分情况
"""
网格搜索
sklearn 提供GridSearchCV用于进行网格搜索,只需要把模型的参数输进去,就能给出最优化的结果和参数。相比起贪心调参,网格搜索的结果会更优,但是网格搜索只适合于小数据集,一旦数据的量级上去了,很难得出结果。
同样以Lightgbm算法为例,进行网格搜索调参:
"""通过网格搜索确定最优参数"""
from sklearn.model_selection import GridSearchCV
def get_best_cv_params(learning_rate=0.1, n_estimators=581, num_leaves=31, max_depth=-1, bagging_fraction=1.0,
feature_fraction=1.0, bagging_freq=0, min_data_in_leaf=20, min_child_weight=0.001,
min_split_gain=0, reg_lambda=0, reg_alpha=0, param_grid=None):
# 设置5折交叉验证
cv_fold = StratifiedKFold(n_splits=5, random_state=0, shuffle=True, )
model_lgb = lgb.LGBMClassifier(learning_rate=learning_rate,
n_estimators=n_estimators,
num_leaves=num_leaves,
max_depth=max_depth,
bagging_fraction=bagging_fraction,
feature_fraction=feature_fraction,
bagging_freq=bagging_freq,
min_data_in_leaf=min_data_in_leaf,
min_child_weight=min_child_weight,
min_split_gain=min_split_gain,
reg_lambda=reg_lambda,
reg_alpha=reg_alpha,
n_jobs= 8
)
grid_search = GridSearchCV(estimator=model_lgb,
cv=cv_fold,
param_grid=param_grid,
scoring='roc_auc'
)
grid_search.fit(X_train, y_train)
print('模型当前最优参数为:{}'.format(grid_search.best_params_))
print('模型当前最优得分为:{}'.format(grid_search.best_score_))
贝叶斯调参
7.6总结
在本节中,我们主要完成了建模与调参的工作,首先在建模的过程中通过划分数据集、交叉验证等方式对模型的性能进行评估验证,并通过可视化方式绘制模型ROC曲线。
最后我们对模型进行调参,这部分介绍了贪心调参、网格搜索调参、贝叶斯调参共三种调参手段,重点使用贝叶斯调参对本次项目进行简单优化,大家在实际操作的过程中可以参考调参思路进行优化,不必拘泥于以上教程所写的具体实例。
八.模型融合
将之前建模调参的结果进行模型融合。 尝试多种融合方案,提交融合结果并打卡。
模型融合是比赛后期上分的重要手段,特别是多人组队学习的比赛中,将不同队友的模型进行融合,可能会收获意想不到的效果哦,往往模型相差越大且模型表现都不错的前提下,模型融合后结果会有大幅提升,以下是模型融合的方式。

stacking:
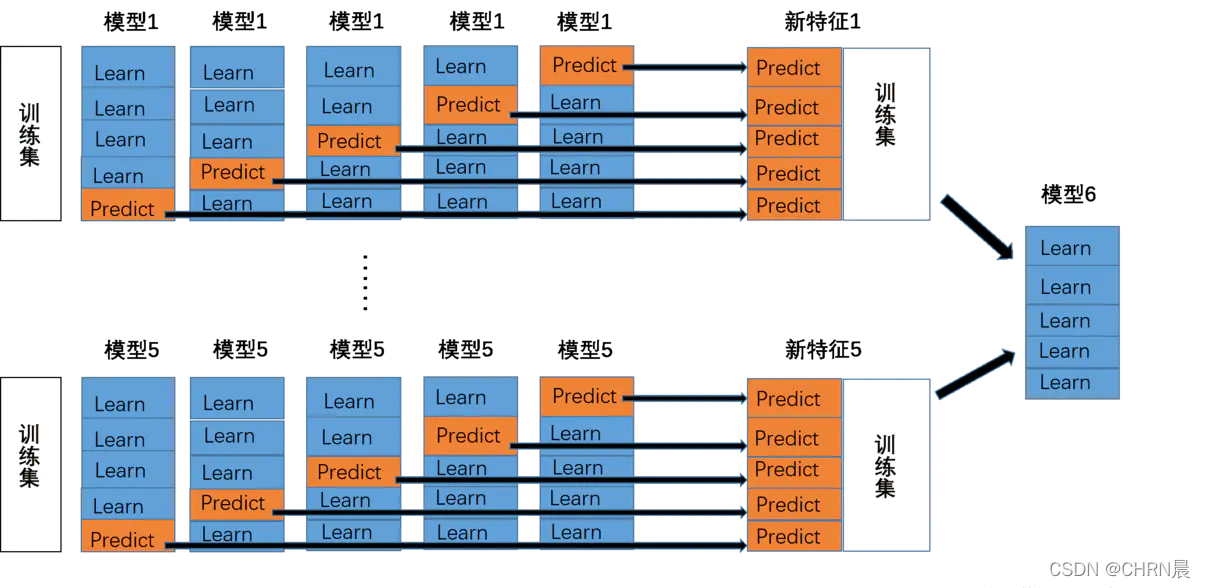
blending:
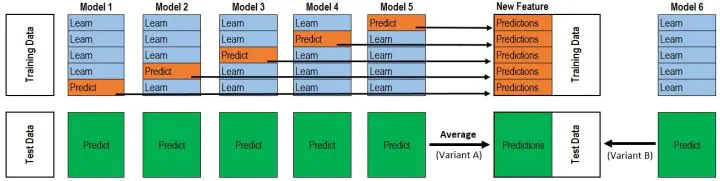
8.1 简单加权平均和加权平均

8.2 投票
简单投票:多三种模型进行简单投票
from xgboost import XGBClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = XGBClassifier(learning_rate=0.1, n_estimators=150, max_depth=4, min_child_weight=2, subsample=0.7,objective='binary:logistic')
vclf = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('xgb', clf3)])
vclf = vclf .fit(x_train,y_train)
print(vclf .predict(x_test))
加权投票
在VotingClassifier中加入参数 voting=‘soft’, weights=[2, 1, 1],weights用于调节基模型的权重
from xgboost import XGBClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = XGBClassifier(learning_rate=0.1, n_estimators=150, max_depth=4, min_child_weight=2, subsample=0.7,objective='binary:logistic')
vclf = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('xgb', clf3)], voting='soft', weights=[2, 1, 1])
vclf = vclf .fit(x_train,y_train)
print(vclf .predict(x_test))
8.3Stacking:鸢尾花数据集为例
import warnings
warnings.filterwarnings('ignore')
import itertools
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
from sklearn.model_selection import cross_val_score, train_test_split
from mlxtend.plotting import plot_learning_curves
from mlxtend.plotting import plot_decision_regions
# 以python自带的鸢尾花数据集为例
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr)
label = ['KNN', 'Random Forest', 'Naive Bayes', 'Stacking Classifier']
clf_list = [clf1, clf2, clf3, sclf]
fig = plt.figure(figsize=(10,8))
gs = gridspec.GridSpec(2, 2)
grid = itertools.product([0,1],repeat=2)
clf_cv_mean = []
clf_cv_std = []
for clf, label, grd in zip(clf_list, label, grid):
scores = cross_val_score(clf, X, y, cv=5, scoring='accuracy')
print("Accuracy: %.2f (+/- %.2f) [%s]" %(scores.mean(), scores.std(), label))
clf_cv_mean.append(scores.mean())
clf_cv_std.append(scores.std())
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf)
plt.title(label)
plt.show()

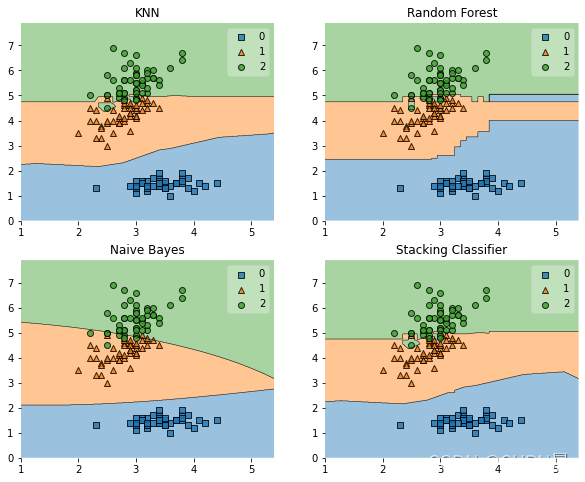
Accuracy: 0.91 (+/- 0.07) [KNN]
Accuracy: 0.94 (+/- 0.04) [Random Forest]
Accuracy: 0.91 (+/- 0.04) [Naive Bayes]
Accuracy: 0.94 (+/- 0.04) [Stacking Classifier]
8.4blending:鸢尾花数据集为例
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import roc_auc_score
# 以python自带的鸢尾花数据集为例
data_0 = iris.data
data = data_0[:100,:]
target_0 = iris.target
target = target_0[:100]
#模型融合中基学习器
clfs = [LogisticRegression(),
RandomForestClassifier(),
ExtraTreesClassifier(),
GradientBoostingClassifier()]
#切分一部分数据作为测试集
X, X_predict, y, y_predict = train_test_split(data, target, test_size=0.3, random_state=914)
#切分训练数据集为d1,d2两部分
X_d1, X_d2, y_d1, y_d2 = train_test_split(X, y, test_size=0.5, random_state=914)
dataset_d1 = np.zeros((X_d2.shape[0], len(clfs)))
dataset_d2 = np.zeros((X_predict.shape[0], len(clfs)))
for j, clf in enumerate(clfs):
#依次训练各个单模型
clf.fit(X_d1, y_d1)
y_submission = clf.predict_proba(X_d2)[:, 1]
dataset_d1[:, j] = y_submission
#对于测试集,直接用这k个模型的预测值作为新的特征。
dataset_d2[:, j] = clf.predict_proba(X_predict)[:, 1]
print("val auc Score: %f" % roc_auc_score(y_predict, dataset_d2[:, j]))
#融合使用的模型
clf = GradientBoostingClassifier()
clf.fit(dataset_d1, y_d2)
y_submission = clf.predict_proba(dataset_d2)[:, 1]
print("Val auc Score of Blending: %f" % (roc_auc_score(y_predict, y_submission)))


















 4201
4201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









