








1 INTRODUCTION
源代码注释在促进程序理解[56、57、60]和软件维护[14、59]方面起着至关重要的作用。然而,现有研究[30、31]表明,缺乏高质量的代码注释是软件行业中的一个常见问题。此外,在软件演进过程中,注释经常缺失、不匹配和过时[14]。这些实际问题推动了源代码摘要的研究。源代码摘要(简称代码摘要)是自动生成代码摘要(即注释)的任务。在过去的十年中,它一直是软件工程领域的研究热点之一.
最近,随着大型语言模型(LLMs)在自然语言处理(NLP)领域的成功[15, 50],越来越多的软件工程(SE)研究人员开始将它们整合到各种SE任务的解决过程中[11, 17, 26]。类似于用于NLP的LLMs(例如ChatGPT [45]和LLaMA [62])任务,有许多用于SE任务的代码LLMs,例如Codex [46]、StarCoder [37]、CodeGen [44]和PolyCoder [74]。在本文中,我们更加关注LLMs在代码摘要任务上的应用。现有研究表明,LLMs在大规模文本语料库上训练后,展现了特别令人兴奋的能力,可以从文字说明中执行新任务(即在零样本学习设置中)或从少量示例中学习(即在少样本学习设置中)[4, 10]。因此,近期有几项研究调查了在零样本和少样本学习中使用指导提示来使LLMs适应代码摘要任务的有效性。例如,
Sun等人[59]评估了ChatGPT在零样本代码摘要任务上的性能。 他们设计了几个启发式问题/指示,以收集ChatGPT的反馈,从而找到一个适当的提示来指导ChatGPT生成分布式代码摘要。然而,他们在大规模CSN-Python数据集上的实验结果表明,这个提示未能促使ChatGPT生成满意的摘要。我们也在CSN-Java数据集上尝试了这个提示,并得到了类似的结果,详见第3节。这些结果表明,手工制作有效的提示是一项具有挑战性的任务,要求用户不仅具备专业领域知识,还需要对所使用的LLMs有深入的了解[59, 67]。
Ahmed等人[4]研究了在使用少样本学习时采用指导提示的有效性,以使LLMs适应代码摘要任务。 为了发现少样本学习的适当示例数量,他们在一个小规模测试数据集上尝试了多组带有不同数量的样本(包括5、10和15)。然后,他们利用10个样本在商业LLMs Codex上进行了指导提示,并发现它可以胜过微调的基础模型(例如CodeT5 [68])。我们利用相同的10个样本在开源LLMs(例如StarCoderBase-3B)上进行指导提示,并发现它们的性能仍然远远不及微调后的LLMs,详见第3节和第5.2.1节。这种现象表明,对于少样本学习,选择哪些样本和选择多少样本都需要用户根据专业知识和持续的试验做出决策。
另一种将LLMs适应以更好地完成下游任务的直接方案是通过面向任务的微调[34, 75]。面向任务的微调通过在数千个与所需任务特定的监督标签上训练来更新LLMs的权重。微调的主要优势是在任务基准测试上表现出强大的性能[10, 51, 70]。例如,Jin等人[34]利用120亿个(B)的监督性bug修复数据对Codex进行微调。尽管微调显著增强了模型在bug修复方面的能力,但其训练成本较高。例如,为了进行全模型微调(更新Codex的所有权重),Jin等人构建了一个由64个32GB的V100 GPU组成的训练环境,这超出了许多研究团队的能力范围。在本文中,我们还在代码摘要任务上尝试了面向任务的微调方案,这同样带来了较高的训练成本,详见第5.2.1节。随着LLMs的规模不断增长,微调的成本可能会相当可观。
在本文中,我们提出了一种新颖的用于代码摘要的提示学习框架,称为PromptCS。PromptCS的关键特点是它能够使开发人员摆脱手工设计复杂提示的需要。具体来说,PromptCS设计了两个协作组件来实现这一特点,包括一个提示代理和一个LLM。提示代理负责生成连续提示,从而诱导LLM执行代码摘要任务的能力。提示代理的核心是一个基于深度学习(DL)的提示编码器,它以由𝑛个可学习标记组成的伪提示作为输入,并生成一个提示嵌入(即连续提示)。提示代理在LLM的指导下进行训练。因此,训练有素的提示代理可以产生比人工编写的离散提示更适合LLM的连续提示。更重要的是,与改变LLM参数的面向任务的微调方案不同,PromptCS对LLMs是非侵入式的。在训练过程中,PromptCS冻结LLMs的参数,只更新提示代理的参数,这可以极大地降低训练资源的需求。
总之,我们的工作有以下贡献:
- 我们提出了一种新颖的代码摘要的提示学习框架,称为PromptCS。PromptCS能够为输入的代码片段生成高质量的摘要。此外,PromptCS是一个通用框架,可以与多个LLMs结合使用(请参见第5.2.3节的实验结果)。我们开放了PromptCS的代码[58],以促进未来的研究和应用。
- 我们在广泛使用的基准数据集上进行了大量实验来评估PromptCS 。实验结果表明,在所有四个指标(即BLEU、METEOR、ROUGE-L和SentenceBERT)方面,PromptCS显著优于采用零样本和少样本学习的指导提示方案,并且与面向任务的微调方案相媲美。在某些LLMs上,例如StarCoderBase-1B和StarCoderBase-3B,PromptCS甚至优于面向任务的微调方案。在训练成本方面,PromptCS显著低于面向任务的微调方案。例如,当使用StarCoderBase-7B模型作为基础LLM时,PromptCS大约需要67小时来训练提示代理,而面向任务的微调方案则需要大约211小时进行一次epoch的训练,详见第5.2.1节。
- 我们进行了定性的人工评估,评估了PromptCS和基线(包括采用零样本和少样本学习的指导提示方案以及面向任务的微调方案)生成的摘要。人工评分的统计结果显示,与基线相比,PromptCS生成的摘要更接近于基准摘要(详见第5.2.6节)。
3 MOTIVATION
在本节中,我们详细阐述了最新方案在将LLMs适应代码摘要任务方面的不足之处,这也是我们提出新方案的动机。为了便于理解每种方案的效果,我们在名为StarCoderBase-3B的LLM上执行了面向任务的微调方案,使用CSN-Java数据集的结果作为参考。现有研究[51、70、71]表明,当LLMs经过微调时,它们往往能够达到最佳效果,展现出其全部潜力。详细结果见表1的第3行。
正如在第1节中提到的,目前有几种方案可供研究人员将LLMs适应于代码摘要任务。其中,最突出的方法是采用零样本/少样本学习进行指导提示[4、8、59]。例如,Sun等人[59]采用零样本学习的指导提示来诱导ChatGPT完成代码摘要任务。为了获得一个合适的提示,他们通过调整语言选择和语法结构等细节尝试了各种提示。经过许多复杂的尝试,他们最终找到了一个适当的提示,可以用来指导ChatGPT生成分布式的注释,即“请为以下函数生成一个简短的一句话摘要: < c o d e > <code> <code>"
我们利用这个提示来引导ChatGPT生成CSN-Java数据集中代码片段的摘要,结果见表1的第4行。从表1可以看出,ChatGPT的结果与他们在其论文中显示的CSN-Python数据集上的结果相似(BLEU为10.28,METEOR为14.40,ROUGE-L为20.81),与面向任务的微调结果相比,都令人不满意。这表明,即使是在代码摘要领域的专业研究人员也很难设计出好的提示。

除了工作[59]外,Ahmed等人[4]还研究了采用少样本学习进行指导提示的有效性,用于代码摘要任务。他们在名为Codex的商业LLM上进行了少样本学习,并发现它可以在仅有十个样本的情况下显著优于使用数千个样本进行微调训练的模型。我们在多个开源代码LLM上使用相同的少样本学习样本进行实验。表1的第4行显示了在StarCoderBase-3B上的实验结果。观察到,虽然与采用零样本学习的指导提示相比,采用少样本学习的指导提示可以在BLEU和ROUGE-L等方面提高LLM在代码摘要上的性能,但仍远远不及面向任务的微调结果。这意味着对于采用少样本学习的指导提示方案,选择适当的代码摘要样本进行少样本学习也是一项复杂的任务。决定选择哪些样本以及选择多少样本需要在该领域具有专业知识和不断试验。
面向任务的微调也是一种将LLMs适应于下游任务的简单想法。然而,与对LLMs非侵入性的指导提示方案不同,微调过程涉及更新和存储LLMs的参数。在实际应用中,研究人员和实践者可能需要投入大量资源来完成微调过程,以确保微调后的LLMs在特定领域或下游任务中表现良好。面向任务的微调非常耗时,特别是在可用的训练资源有限的情况下。例如,我们的实验表明,仅在一个1卡的A800GPU设备上,微调StarCoder-7B模型仅仅需要一个epoch就需要超过200个小时,详见第5.2.1节。随着LLMs规模的不断增长,与面向任务的微调相关的训练时间和计算成本变得越来越难以承受。此外,值得注意的是,微调LLMs的参数变化可能会影响它们在其他下游任务上的性能。
我们的解决方案是提出一种新颖的提示学习框架PromptCS,用于将LLMs适应于代码摘要任务。与需要复杂提示设计或精心选择的少样本学习样本的指导提示技术不同,PromptCS训练了一个提示代理,可以生成连续提示,诱导LLMs为给定的代码片段生成高质量的摘要。与改变LLMs参数的微调技术不同,PromptCS也对LLMs非侵入式,冻结LLMs的参数,并仅更新提示代理的参数,大大降低了对训练资源的需求。表1的最后一行显示了PromptCS在CSN-Java数据集上的结果。观察到,PromptCS在所有三个指标上都显著优于指导提示方案(包括零样本学习和少样本学习),甚至在BLEU和ROUGE-L上超过了面向任务的微调。在第5.2.1节,我们通过实证方法证明了PromptCS在提高度量分数方面优于三个最新基线的效果。
4、Methodology
4.1 overview
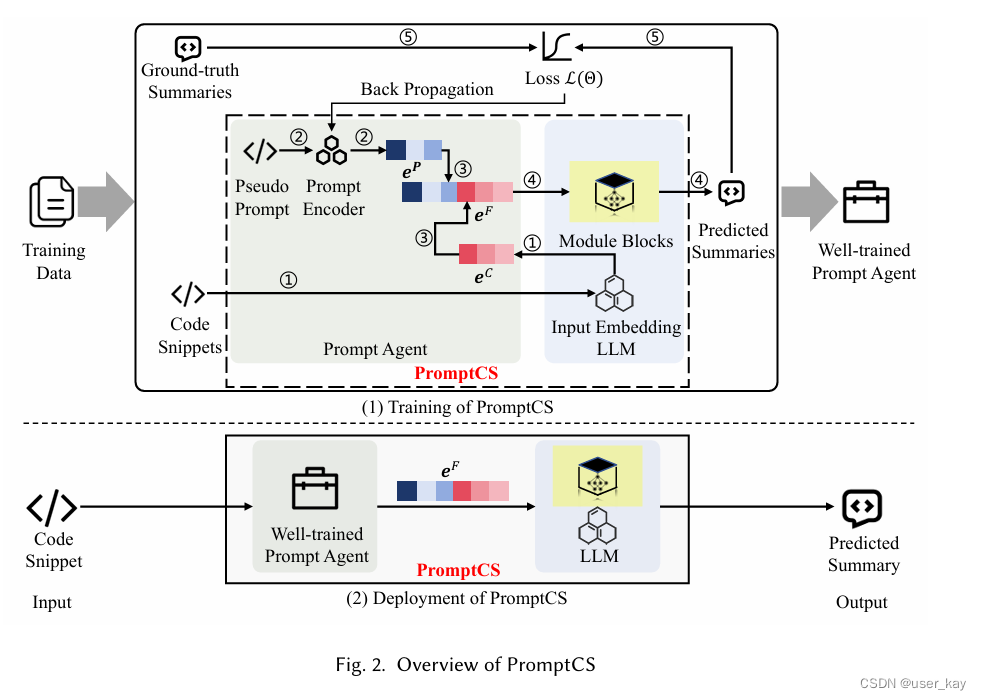
图2展示了PromptCS的概述。顶部显示了PromptCS的训练过程,底部显示了PromptCS的部署/使用来支持代码摘要服务。PromptCS包括两个核心组件:提示代理和LLMs。
提示代理负责生成提示,诱导LLMs为代码片段生成自然语言摘要。PromptCS对LLMs非侵入式,即LLMs的参数始终被冻结,在训练过程中保持不变。 因此,在PromptCS的训练过程中,我们的目标是获得一个训练有素的提示代理。PromptCS利用由⟨代码片段,地面真实摘要⟩对组成的训练数据来训练提示代理。具体来说,PromptCS将提示代理的训练分解为五个步骤。
1、PromptCS将代码片段馈送给LLMs,利用其输入嵌入层生成相应的代码嵌入,表示为
e
C
e^C
eC,详见第4.2节。
2、PromptCS将伪提示馈送到提示编码器中,生成提示嵌入,表示为
e
P
e^P
eP。伪提示由𝑛个可学习的标记组成,没有实际意义。提示编码器是一个DL模型,并与提示代理一起训练。该步骤的详细内容在第4.3节中解释。
3、PromptCS将
e
C
e^C
eC和
e
P
e^P
eP连接在一起,产生融合嵌入,表示为
e
F
e^F
eF。与人工编写的离散提示类似,我们的PromptCS对输入代码片段也是非侵入式的,即提示嵌入不会破坏代码嵌入的完整性。因此,
e
P
e^P
eP仅会连接到
e
C
e^C
eC的前部/后部,详见第4.4节。
4、将
e
F
e^F
eF馈送到LLMs的模块块中生成预测摘要
5、基于预测摘要和地面真实摘要,PromptCS计算损失并迭代更新提示代理的模型参数,详见第4.5节。一旦训练阶段完成,就获得了训练有素的提示代理。当PromptCS部署以供使用时,提示代理将自动为用户提供的代码片段生成提示嵌入,以指导LLMs生成预测摘要。对于用户来说,所有这些都是无缝的,不可感知的。
4.2 Code Embedding Generation
正如在第2.2节中提到的,每个LLMs都有三个核心组件,即分词器、输入嵌入层和模块区域(module block)。PromptCS直接利用LLMs的前两个组件来完成代码嵌入生成的任务。具体来说,给定一个代码片段,我们的提示代理首先利用对应LLMs提供的分词器将代码片段中的各种元素,例如标识符和符号,转换为索引表示。每个索引表示对应于LLMs词汇表中的一个标记。然后,提示代理将这些索引表示馈送给LLMs的输入嵌入层。输入嵌入层可以将索引表示编码为嵌入(即,𝒆𝐶),以便模块块更好地理解它们的内部信息。
4.3 Prompt Embedding Generation
提示嵌入的作用是指示LLMs生成代码摘要。如图2(1)所示,提示嵌入 𝒆𝑃 是通过提示编码器生成的。提示编码器的输入是一个由 𝑛 个可学习标记组成的伪提示,表示为 𝑝 = {𝑡0, 𝑡1, . . . , 𝑡𝑛},其中 𝑡𝑖 指代第 𝑖 个伪标记。伪标记的作用是仅作为占位符,没有承载任何实际含义,并指示提示编码器用于生成提示嵌入的长度。提示编码器是一个DL模型,能够将 𝑝 映射到一个连续的数字序列,然后输入到嵌入层生成 𝑻 = {𝒕0, 𝒕1, . . . , 𝒕𝑛},其中 𝒕𝑖 是一个可训练的嵌入张量。这使我们能够发现更有效的连续提示,超越了LLMs的原始词汇表。然后,提示编码器应用双向长短期记忆网络(BiLSTM)和带有ReLU激活的两层多层感知机(MLP)来生成实际的提示嵌入 𝒆𝑃 = {𝒆0, 𝒆1, . . . , 𝒆𝑛}。第 𝑖 个位置的值 𝒆𝑖 如下计算:


4.4 Fusion Embedding Generation
类似于人类如何将离散提示与代码片段连接起来,PromptCS也可以以各种方式将由提示代理生成的连续提示(即提示嵌入)与代码片段的嵌入连接起来。为了不破坏代码本身的完整性,常见的人类做法是在代码片段的前面或后面连接离散提示[59, 61]。图3的左侧显示了连接离散提示和代码片段(表示为
<
c
o
d
e
>
<code>
<code>)的示例,其中(a)和(b)分别代表两种模式:前端模式,将离散提示连接在代码片段前面;后端模式,将离散提示连接在代码片段后面。在本文中,除了遵循上述两种模式外,我们还尝试了一种新模式,称为双端模式。在双端模式中,提示嵌入被分为两部分,分别连接在代码嵌入的前部和后部。这种分割很容易实现。例如,我们可以将 𝒆𝑃 = {𝒆0, 𝒆1, . . . , 𝒆𝑛} 分成 𝒆𝑃1 = {𝒆0, 𝒆1, . . . , 𝒆𝑖 } 和 𝒆𝑃2 = {𝒆𝑖+1, . . . , 𝒆𝑛}。图3的右侧显示了连接提示嵌入和代码嵌入的示例,其中(e)、(f)和(g)分别展示了三种连接模式。

4.5 Model Training
Predicted Summary Generation.
在PromptCS中,预测的摘要由第二个组件即LLMs生成。如图2(1)所示,PromptCS直接将融合嵌入(即𝒆𝐹)馈送到能够生成自然语言摘要的LLMs的模块块中。如第2.2节所述,在本文中,我们更加关注将自回归型LLMs(Autoregressive LLMs)应用于代码摘要任务。对于自回归型LLMs,预测代码摘要可以看作是一个条件生成任务,其中输入是一个上下文,输出是一个标记序列。形式上,令 𝒛 = [𝒆𝐹, 𝒆𝑆],其中𝒆𝑆是通过将已生成的摘要馈送到LLMs的输入嵌入层中获得的摘要嵌入。𝒛𝑖表示𝒛中的第𝑖个值。LLMs在时间步𝑖生成的激活向量为𝑎𝑖 = [𝑎(1)𝑖, . . . , 𝑎(𝑛)𝑖],这是该时间步的所有激活层的输出的串联。𝑎(𝑗)𝑖是时间步𝑖处第𝑗层的激活向量。自回归型LLMs根据𝑧𝑖和其左侧上下文中的过去激活𝑎<𝑖来计算𝑎𝑖,即:𝑎𝑖 = 𝐿𝐿𝑀(𝒛𝑖, 𝑎<𝑖)。然后,它利用矩阵𝑊将𝑎𝑖的最后一层映射到对数𝑙𝑖,这是与下一个词相关联的概率向量,即𝑙𝑖 = 𝑊 · 𝑎(𝑛)𝑖。最后,基于𝑙𝑖,它进一步使用函数𝑃(·)来选择LLMs词汇表中概率最高的标记作为已生成摘要的下一个标记𝑠𝑖+1,即𝑠𝑖+1 = 𝑃(𝑙𝑖)。
Train Process
在PromptCS的训练过程中,LLMs的参数被冻结,只有提示编码器的参数被更新。设𝑦ˆ为对应于预测摘要的概率向量,𝑦为地面真实摘要。损失函数可以建模为以下的分类交叉熵损失函数:

在这里,Θ代表模型的可训练参数;𝐶是词汇表中的标记数。ˆ 𝑦𝑖 和 𝑦𝑖 分别表示每个 𝑖 ∈ 𝐶 的预测标记和地面实况标记的概率。
5 EVALUATION AND ANALYSIS
我们进行了一系列实验来回答以下研究问题(RQs):
- RQ1. PromptCS在将LLMs适应到代码摘要任务中的有效性如何?
- RQ2. 关键配置,即提示长度和代码与提示嵌入的连接模式,如何影响PromptCS?
- RQ3. 提示编码器中网络架构的选择如何影响PromptCS?
- RQ4. 训练数据规模如何影响PromptCS?
- RQ5. PromptCS在其他编程语言的代码摘要任务中的表现如何?
- RQ6. PromptCS在人工评估中的表现如何?
5.1.1 dataset
我们在CodeSearchNet(CSN)语料库[32]上评估PromptCS,该语料库是一个庞大的代码片段集合,附带有六种编程语言的注释(包括Go、Java、JavaScript、PHP、Python和Ruby)。该语料库在研究代码摘要方面被广泛使用[4, 21, 57, 59, 77]。考虑到原始CSN语料库包含一些低质量数据[40],我们使用了来自CodeXGLUE[40]代码到文本文档生成任务的数据集,该任务是基于CSN语料库构建的,并排除了有缺陷的数据样本。
5.1.2 Metrics
我们在评估中使用了四个指标,包括BLEU[48]、METEOR[6]、ROUGE[38]和SentenceBERT[52]。这些指标在代码摘要中被广泛使用[30, 33, 57, 64, 66, 73, 76]。
BLEU,即双语评估协作[48],是一种精度度量的变体,通过计算生成摘要与地面真实摘要之间的n-gram精度来计算相似度,对过度短长度有惩罚。在本文中,我们遵循[57, 73]并展示标准的BLEU分数,提供了1-、2-、3-和4-gram的累积得分。
METEOR[6]是为了解决使用BLEU时的一些问题而引入的。METEOR结合了n-gram精度和n-gram召回率,通过取它们的调和平均来计算相似度度量。
ROUGE-L是ROUGE(用于测评摘要质量的召回为主)的一个变体[38]。ROUGE-L基于最长公共子序列(LCS)计算。
SentenceBERT[25]。与上述三个指标主要计算地面真实摘要和生成摘要之间的文本相似性不同,SentenceBERT测量语义相似性。SentenceBERT首先将两个比较的摘要转换为统一向量空间中的嵌入,然后使用余弦相似度来表示它们之间的语义相似性。
BLEU、ROUGE-L、METEOR和SentenceBERT的得分在[0, 1]范围内,并以百分比报告。得分越高,生成摘要越接近地面真实摘要,代码摘要性能越好。
5.1.3 Base LLMs
我们在四个流行的LLM上进行实验,包括三个开源LLM:PolyCoder [74]、CodeGen-Multi [44]、StarCoderBase [37],以及一个商用LLM:ChatGPT [45]。
PolyCoder [74] 由卡内基梅隆大学的研究人员发布。它使用GPT NeoX工具包在12种编程语言的249GB代码上进行训练,并提供三种规模:160M、0.4B和2.7B。
CodeGen-Multi [44] 由Salesforce发布,是一个用于程序合成的自回归语言模型系列的成员。在我们的实验中,我们使用了三种大小的CodeGen-Multi:350M、2B和6B。
StarCoderBase [37] 是Hugging Face和ServiceNow于2023年共同发布的。它在TheStack[36]中使用80多种编程语言进行训练。而著名的StarCoder是StarCoderBase的一个经过微调的版本,额外训练了350亿个Python令牌。考虑到StarCoder仅提供16B版本,可能不适合进行全面的比较实验。在我们的实验中,我们使用了三种规模的StarCoderBase:1B、3B和7B。
ChatGPT [45] 可能是最强大的LLM。为了在其协助下进行实验,我们使用了OpenAI API,该API由各种具有不同能力的模型提供支持,例如GPT-3.5、DALL·E和Whisper。在我们的实验中,我们使用了gpt-3.5-turbo模型,它在GPT-3.5系列中独具特色,是最具能力和成本效益的选择。
5.1.4 Experimental Settings
在训练阶段,我们将批量大小设置为16,学习速率设置为5e-5。我们采用AdamW优化器[39]以及线性学习率调度器,在HuggingFace推荐的默认设置下进行。为了确保全面的训练,我们采用了一个基于最佳验证BLEU的提前停止策略来控制模型的训练轮数。提前停止的耐心被设置为4。输入序列被填充到最大长度,使用特殊的令牌进行填充,这些令牌是根据LLM的词汇表选择的。为了在单个A800上对StarCoderBase-7B和CodeGen-Multi-6B进行微调,我们使用DeepSpeed0.12.2。我们将ZeroRedundancyOptimizer (ZeRO)设置为ZeRO-3,并启用将优化器计算卸载到CPU。所有模型均使用Python3.8中的PyTorch2.1.0框架实现。所有实验均在配有一块Nvidia A800 GPU和80GB内存的服务器上进行,运行Ubuntu20.04.4。
5.2 Experimental Results
为了回答这个研究问题,我们将我们的PromptCS与以下三种将LLM适应于代码摘要任务的方案进行比较。
5.2.1 RQ1: Effectiveness of PromptCS
1) Baselines:
- Instruct Prompting(zero-shot):该方案直接使用人工编写的指令来提示LLM为给定的代码片段生成摘要。 对于StarCoderBase、CodeGen-Multi和PolyCoder,我们使用文献[8]中提供的人工编写的提示。对于ChatGPT,我们使用文献[59]中提供的人工编写的提示。表3显示了上述两个人工编写的提示。
- Instruct Prompting(few-shot):在此方案中,除了在零次尝试设置中提供手写的提示之外,我们还提供了一些示例,展示了任务的性质,让LLM执行有限次的学习。我们遵循[4, 8],在有限次尝试的设置中提供了10个示例。 每个示例是从训练集中随机选择的一对⟨代码片段,摘要⟩。在实践中,我们直接利用Ahmed等人在他们的GitHub存储库中提供的10个示例,因为我们使用相同的实验数据集(即CSN语料库)。
- 任务导向的微调:在这个方案中,我们执行标准的微调过程,并利用训练集中的所有⟨代码片段,摘要⟩来微调LLM。 在微调过程中,LLM的所有模型参数可能会发生变化。
- PromptCS:这是本文提出的方案。PromptCS冻结LLM的参数,并且只训练提示代理(即提示编码器)。与任务导向的微调方案类似,我们利用训练集中的所有⟨代码片段,摘要⟩来训练提示代理。PromptCS的两个关键配置,即提示长度和代码嵌入和提示嵌入的连接模式被设置为100和后端模式,分别在第5.2.2节中讨论了这两个关键配置的更多实验
2) Results:
表2显示了我们的PromptCS和基线在四个评估指标(BLEU、METEOR、ROUGE-L和SentenceBERT)方面的性能。观察到,在所有四个度量标准的分数方面,任务导向的微调在LLM PolyCoder上表现最好,其次是PromptCS、指令提示(有限次尝试)和指令提示(零次尝试)。对于LLM CodeGen-Multi和StarCoderBase,PromptCS总体上与任务导向的微调相当,两者都明显优于两个指令提示方案。PromptCS甚至在某些LLM上表现优于任务导向的微调,例如CodeGen-Multi-2B(第7行)、StarCoderBase-1B(第9行)和-3B(第10行)。我们还在商业LLM ChatGPT上进行了指令提示方案的实验,并在表2的最后一行显示了其性能。观察到,指令提示方案在ChatGPT上的性能在所有四个度量标准上都优于其他三个LLM,但与任务导向的微调和PromptCS相比,也不令人满意。尽管这种比较是不合理的,但我们有理由相信,如果ChatGPT是开源的,任务导向的微调方案和PromptCS将显著提高其代码摘要的能力,而不是指令提示方案。

在适应LLM到代码摘要任务方面,PromptCS明显优于使用零射击和少射击学习的指令提示,并且在性能上与任务导向的微调相当。PromptCS甚至在某些LLMs上表现优于任务导向的微调,例如,CodeGen-Multi-2B、StarCoderBase-1B和-3B。
此外,我们还比较了基于任务导向方案和PromptCS之间的训练成本,以训练时间为指标。表4列出了在三个LLMs上进行训练时产生的时间成本。观察到,与任务导向方案相比,PromptCS在所有LLMs上显着需要更少的时间,这可以归因于PromptCS对LLMs的非侵入性,在训练过程中不更新LLMs的参数。需要注意的是,当LLM的模型大小非常大时(例如,StarCoderBase-7B),任务导向的微调将需要很长时间,并且如果可用的训练资源(例如性能和GPU设备数量)有限,则这种情况将变得不可接受。

5.2.2 RQ2.Influence of key configurations on PromptCS
如图2所示,PromptCS中的两个关键配置可能会影响其性能,即由伪提示确定的提示长度和代码嵌入和提示嵌入的连接模式。为了揭示它们的影响,我们进行了涉及五种不同提示长度(包括10、20、50、100和200)和三种连接模式(包括前端模式、后端模式和双端模式,详见第4.4节)的综合实验。我们统一选择StarCoderBase-1B作为基本LLM。
实验结果见表5。从表5中可以看出,如果使用前端模式,PromptCS在提示长度为50时取得最佳的BLEU分数(即20.41),而在提示长度为200时获得最佳的METEOR、ROUGE-L和SentenceBERT分数(分别为14.40、39.68和0.6206)。如果使用后端模式,PromptCS在提示长度为100时获得最佳的BLEU和SentenceBERT分数,分别在提示长度为20和200时获得最佳的METEOR和ROUGE-L分数。如果使用双端模式,PromptCS在提示长度为50时获得最佳的BLEU和ROUGE-L分数,分别在提示长度为100和20时获得最佳的METEOR和SentenceBERT分数。这些观察结果表明,不同的两个关键配置组合确实对PromptCS的有效性产生了不同的影响。值得注意的是,尽管不同的组合对PromptCS的影响有所不同,但从数值上来看,这些影响的差异是微不足道的。例如,就BLEU而言,最佳组合是后端模式和提示长度为100(获得得分为20.50),最差的组合是双端模式和提示长度为10(获得得分为20.03)。这两种组合之间的BLEU分数差异小于0.5。
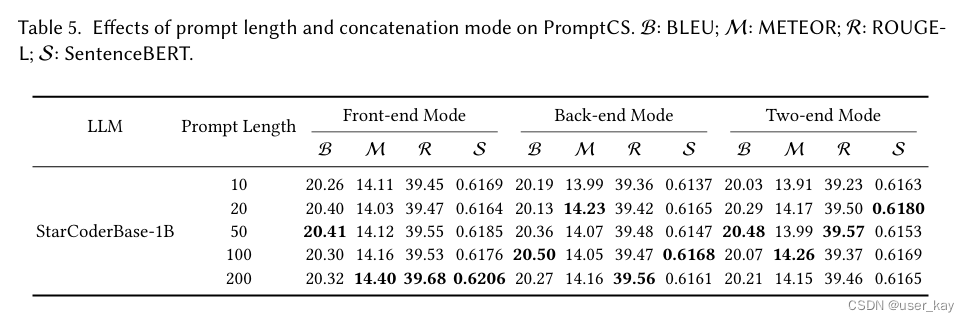
两个关键配置的不同组合对PromptCS的有效性产生不同的影响,然而,这些组合之间的差异并不显著。然而,值得注意的是,增加提示长度会提高模型的训练成本。
5.2.3 RQ3.InfluenceofthenetworkarchitectureusedinthepromptencoderonPromptCS.
如第4.3节所述,提示代理包含基于BiLSTM构建的DL型提示编码器。在实践中,我们还尝试将提示编码器建立在更先进的网络上,即Transformer,以验证不同选择对PromptCS的影响。与第5.2.1节相同,在这个实验中,我们将提示长度统一设置为100,连接模式设置为后端模式。表6呈现了实验结果。

观察到,与基于BiLSTM构建提示编码器相比,在以下情况下,基于Transformer构建提示编码器会为PromptCS带来性能改进:
1)在PolyCoder-160M上,在所有四个指标中,基于Transformer构建的提示编码器都提高了PromptCS的性能;
2)在CodeGen-Multi-350M上,在METEOR和SentenceBERT中,基于Transformer构建的提示编码器增强了PromptCS的性能改进,但在BLEU和ROUGE-L方面结果下降;
3)在StarCoderBase-1B上,在Transformer上构建的提示编码器不仅未能提高PromptCS的性能,还导致了所有四个指标的性能下降。
总的来说,随着LLM的模型大小增加,如果提示编码器建立在BiLSTM上,则PromptCS的性能往往会提高,而如果提示编码器建立在Transformer上,则PromptCS的性能呈相反的趋势。
尽管Transformer看起来比BiLSTM更先进,但在我们的应用场景中的实验结果并未显示出Transformer的显著优势。换句话说,BiLSTM足以满足我们对提示编码器设计的需求。
5.2.4 RQ4. Influence of the training data size on PromptCS.
本文还分析了训练数据规模对PromptCS有效性的影响。为了揭示这种影响,我们从一个小规模的训练集开始,并系统地增加训练样本的数量。较小的训练集是从完整的训练数据中随机抽取的。考虑的训练集大小包括100、1000、10000和164923(完整的训练数据)。在这个实验中,我们还统一地将StarCoderBase-1B作为基础LLM,并将提示长度和连接模式分别设置为100和back-end模式。
图5展示了实验结果,其中x轴表示训练集大小,y轴表示左侧的BLEU、METEOR和ROUGE-L以及右侧的SentenceBERT。可以观察到,随着训练集大小的增加,PromptCS在四个指标上的得分会提高,但增长并不明显。而使用100个样本训练的PromptCS与使用164,923个样本训练的PromptCS表现相当。这突显了PromptCS在小规模数据集上的优越适应性和泛化能力。对于减少训练成本、提高训练效率以及在数据有限的环境中获得满意的性能,这具有深远的实际意义

PromptCS即使在训练数据资源有限的情况下,例如只有100个可用样本,也能取得不错的性能。
5.2.5 RQ5. Effectiveness in other programming languages
为验证PromptCS的泛化能力,我们还在另外两种编程语言(包括JavaScript和Python)上进行了实验。在这些实验中,我们同样将提示长度和连接模式设置为100和后端模式。实验结果如表7所示。

**从表7的CSN-JavaScript列可以看出,任务导向的微调方案在大多数指标和LLM上优于PromptCS。**然而,值得注意的是,在三个LLM上,PromptCS的表现平均达到了任务导向的微调方案的98%,这是令人鼓舞的。从表7的CSN-Python列可以看出,在所有三个LLM上,PromptCS在所有四个指标上的表现都比任务导向的微调方案更好。
PromptCS在包括JavaScript和Python在内的其他不同编程语言的代码摘要任务上展现出良好的泛化能力。
5.2.6 RQ6. PromptCS’s performance in human evaluation.
除了自动化评估外,我们还进行了人工评估,按照之前的研究作品 [27, 29, 69, 73, 76] 的做法来评估三个基准模型和 PromptCS 生成的摘要。具体来说,我们邀请了五名具有四年以上软件开发经验和出色的英语能力的志愿者进行评估。我们随机从 CSN-Java 数据集中选择了 100 个代码片段、相应的基准摘要以及由基准模型和 PromptCS 生成的摘要。每个志愿者被要求根据生成的摘要与相应的基准摘要的相似程度,将得分从 1 到 5 分进行评分,其中 1 表示“完全不相似”,5 表示“高度相似/相同”。为了确保实验结果的公平性和客观性,每个摘要都由五名志愿者评估,最终得分是他们评分的中位数。

表 8 显示了生成摘要的得分分布。观察到 PromptCS 取得了最佳得分,并将平均得分(Avg.)从 2.31(使用零-shot学习的指导提示)、3.31(使用少量-shot学习的指导提示)和 3.60(面向任务的微调)提高到了 3.64。具体而言,在随机选择的 100 个代码片段中,PromptCS 能够生成 15 个与基准摘要高度相似甚至相同的摘要(得分 = 5),56 个良好的摘要(得分 ≥ 4)和 93 个不错的摘要(得分 ≥ 3)。PromptCS 还获得了较少数量的负面结果(得分 ≤ 2)。根据每个基准模型和 PromptCS 的 100 个最终得分,我们按照 [76] 进行 Wilcoxon 签名秩检验 [72] 并计算 Cliff’s delta 效应大小 [41]。将 PromptCS 与使用零-shot学习的指导提示、使用少量-shot学习的指导提示和面向任务的微调进行比较,Wilcoxon 签名秩检验的 p 值在 95% 置信水平下分别为 5.46E-16、0.016 和 0.722,这意味着 PromptCS 的改进在统计上显著超过了使用零-shot 和少量-shot学习的指导提示。此外,Cliff’s delta 效应大小分别为 0.5669(大)、0.1478(小)和 0.0314(可忽略的)。
人工评估显示,与基准模型生成的摘要相比,PromptCS生成的摘要平均得分更高。PromptCS还生成了最多的好摘要。
6 DISCUSSION
在本节中,我们提供了两个代码摘要案例,以了解与基线相比,PromptCS生成的摘要。两个案例都是来自CSN-Java测试集的真实示例。对于每个案例,我们将代码片段的注释视为地面真实摘要,并通过将基线和PromptCS应用于LLM StarCoderBase-3B来生成摘要。
图6显示了第一个代码摘要案例,在其中(b)呈现了地面真实摘要和由基线和PromptCS为代码片段𝑠2生成的摘要。从图中可以观察到,与地面真实摘要相比,由instruction prompting (few-shot)和task-oriented fine-tuning生成的摘要可以覆盖前两部分的语义,即“Fire”(蓝色字体)和“onThrowable”(红色字体),而由instruction prompting (zero-shot)和PromptCS生成的摘要可以覆盖所有三部分的语义(包括“to all registered listeners”(橙色字体))。然而,仔细检查图6(a)中第一行显示的𝑠2方法名,我们可以发现对于第二部分(即“onThrowable”),三个基线生成的摘要(即“an event”,“a ThrowableListener event”和“an exception event”)都是不准确的。只有PromptCS成功地诱导LLM正确生成了这一部分。

图7显示了第二个代码摘要案例,在其中地面真实摘要显示为(b),可以将其分为两个子句:“Verifies if the wrapped transaction is active”和“if dissociates it fromthethreadifneeded”。观察到与地面真实摘要相比,1)instruction prompting (zero-shot)和PromptCS生成的摘要覆盖了第一个子句;2)instruction prompting (few-shot)生成的摘要覆盖了第二个子句;3)task-oriented fine-tuning未覆盖任何一个子句。另一个值得注意的是,虽然PromptCS生成的摘要“if not throws an exception”不是地面真实摘要的一部分,但它确实为代码片段𝑠3中throw new IllegalStateException("There … in state: " + status);语句提供了一个很好的摘要。

从上述两个案例可以明显看出,与基线相比,PromptCS在为代码摘要任务调整LLM方面表现更好。PromptCS表现良好的原因归功于其提示代理,它在LLM的指导下进行训练,使其能够生成更适合LLM的提示。当然,第二个案例也表明,PromptCS仍有改进的空间。我们将在未来进一步优化它,以更好地诱导LLM生成高质量的代码摘要。
Conclusions
我们提出了一个用于源代码摘要的提示学习框架PromptCS。PromptCS配备有一个提示代理,可以诱导LLM完成代码摘要任务,生成连续的提示。PromptCS可以帮助模型用户节省大量时间,而无需花费时间制作提示指令。全面的自动化和人工评估表明,PromptCS在以低训练成本使LLM适应代码摘要方面是有效的。我们相信,我们的提示学习框架与LLM配对还可以使其他软件工程任务受益,我们将探索其他软件工程任务的可能性留给未来的工作。
















 1502
1502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









