







一、YOLOV5源码准备
1.1 源码下载
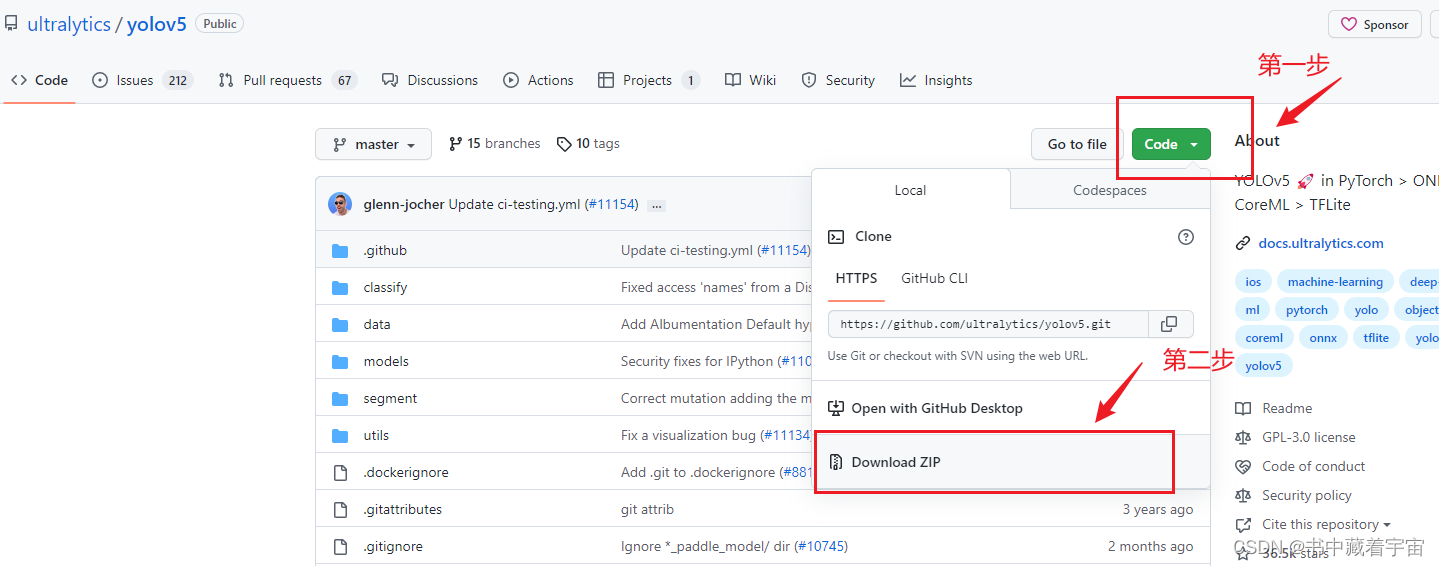
(1)在github或者gitee搜索关键字YOLOv5即可,我使用的是github
链接: link
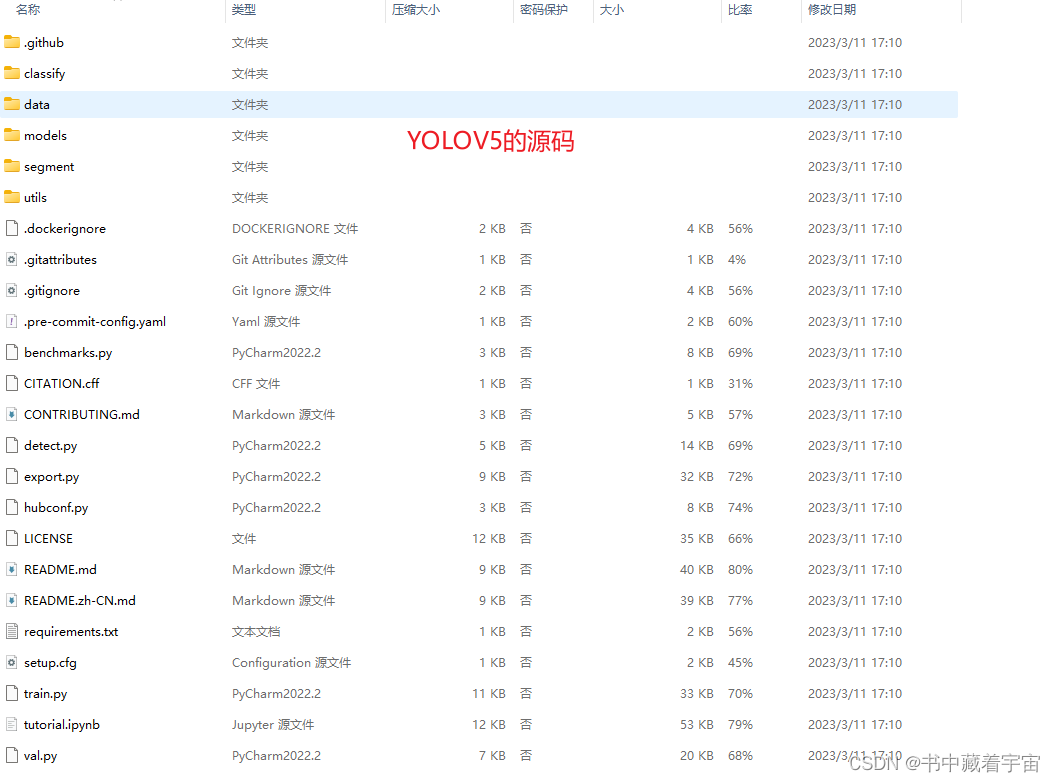
YOLOV5的源码下载好解压之后就如下所示
备注:下载好源码之后,需要下载预训练的权重模型,这里可以参考这个博客链接: link
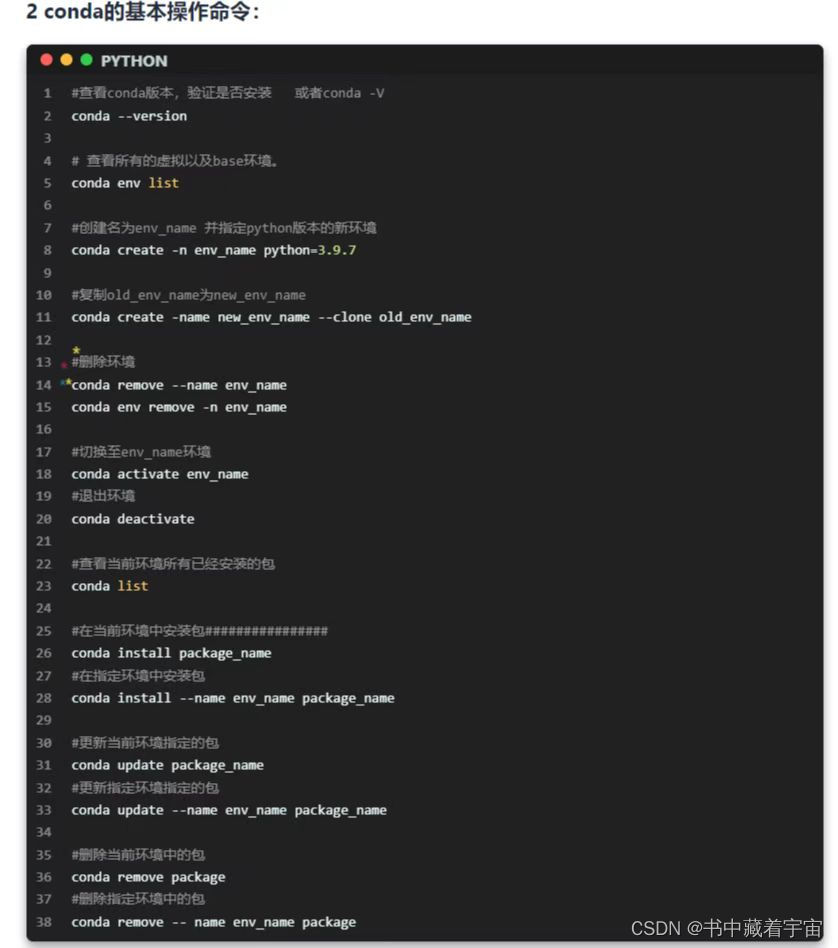
1.2 虚拟环境配置
做好1.1步骤之后,我们需要对虚拟环境进行配置。不想使用虚拟环境的这步可以跳过。
虚拟环境的配置需要使用conda虚拟环境配置。
one step下载Anoconda
two step: conda create -n env_name python=“python version”
three step: conda activate
1.3 YOLO所需环境和支持包安装
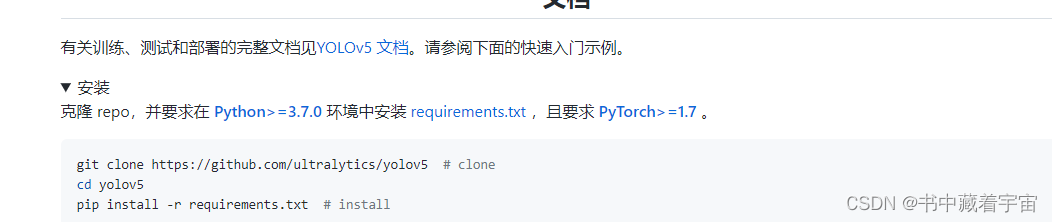
(1)环境配置好后,打开我们刚刚下载的yolov5源码(提前解压好),打开requirements.txt
文件,里面有YOLOV5运行所需要的支持库以及相应的版本要求。
# YOLOv5 requirements
# Usage: pip install -r requirements.txt
# Base ------------------------------------------------------------------------
gitpython>=3.1.30
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.1
Pillow>=7.1.2
psutil # system resources
PyYAML>=5.3.1
requests>=2.23.0
scipy>=1.4.1
thop>=0.1.1 # FLOPs computation
torch>=1.7.0 # see https://pytorch.org/get-started/locally (recommended)
torchvision>=0.8.1
tqdm>=4.64.0
# protobuf<=3.20.1 # https://github.com/ultralytics/yolov5/issues/8012
# Logging ---------------------------------------------------------------------
tensorboard>=2.4.1
# clearml>=1.2.0
# comet
# Plotting --------------------------------------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export ----------------------------------------------------------------------
# coremltools>=6.0 # CoreML export
# onnx>=1.12.0 # ONNX export
# onnx-simplifier>=0.4.1 # ONNX simplifier
# nvidia-pyindex # TensorRT export
# nvidia-tensorrt # TensorRT export
# scikit-learn<=1.1.2 # CoreML quantization
# tensorflow>=2.4.1 # TF exports (-cpu, -aarch64, -macos)
# tensorflowjs>=3.9.0 # TF.js export
# openvino-dev # OpenVINO export
# Deploy ----------------------------------------------------------------------
setuptools>=65.5.1 # Snyk vulnerability fix
# tritonclient[all]~=2.24.0
# Extras ----------------------------------------------------------------------
# ipython # interactive notebook
# mss # screenshots
# albumentations>=1.0.3
# pycocotools>=2.0.6 # COCO mAP
# roboflow
# ultralytics # HUB https://hub.ultralytics.com
由于不同的Ubuntu的版本所带的python版本不一样,而yolov5对python的版本需求也是不一样的,所以我们需要自己在创建的conda虚拟环境里面安装自己合适的python的版本【要求python大于3.7】
(2)安装python的对应版本
conda activate 你的虚拟环境,不切换表示在base环境.
在开始安装Python之前,请在系统上安装一些必需的软件包。登录到您的Ubuntu系统并执行以下命令:
sudo apt update
sudo apt install software-properties-common
使用Apt-Get安装Python 3.9
Apt软件包管理器提供了在Ubuntu系统上安装Python 3.9的简单方法。请按照以下步骤操作:
打开系统上的终端,然后为系统配置Deadsnakes PPA。
sudo add-apt-repository ppa:deadsnakes/ppa
在Ubuntu系统上添加ppa后,更新apt缓存并在Ubuntu上安装Python 3.9。
sudo apt update
sudo apt install python3.9
等待安装完成。通过执行以下命令检查Python版本:
python3.9 -V
至此,Python 3.9已安装在Ubuntu系统上并可以使用

(3)安装支持包,所需版本在上述的requirement.txt
# s一起安装的命令
pip3 install -r requirements.txt
#s 上述如果出现问题可以单独安装
# s先安装下面三个,免得安装库时报错
sudo apt-get install cmake
sudo pip3 install scikit-build
sudo pip3 install --upgrade setuptools && python3 -m pip install --upgrade pip3
sudo pip3 install matplotlib==3.2.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
sudo pip3 install numpy==1.19.5 -i https://pypi.tuna.tsinghua.edu.cn/simple
sudo pip3 install opencv-python==4.2.0.32 -i https://pypi.tuna.tsinghua.edu.cn/simple
sudo pip3 install Pillow==8.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
sudo pip3 install PyYAML==5.3.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install scipy==1.4.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
sudo pip3 install torchvision==0.8.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
(先torchvision,很有可能会自动下载torch 1.7.1哈)
sudo pip3 install torch==1.7.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
sudo pip3 install tqdm -i https://pypi.tuna.tsinghua.edu.cn/simple
sudo pip3 install tensorboard==2.4.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
sudo pip3 install seaborn==0.11.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
会检测pandas>=0.23,scipy>=1.0 下载最新版pandas-1.1.5 python-dateutil-2.8.2 scipy-1.5.4
sudo pip3 install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
# tips 如果pip或者pip3指令无法使用的话,我们需要安装pip 和pip3
sudo apt install python-pip pip 下载
sudo apt install python3-pip pip3 下载
验证:
pip --version
pip3 --version
小tips
**
1、pip是python的包管理工具,pip和pip3版本不同,都位于Scripts\目录下:
2、如果系统中只安装了Python2,那么就只能使用pip。
3、如果系统中只安装了Python3,那么既可以使用pip也可以使用pip3,二者是等价的。
4、如果系统中同时安装了Python2和Python3,则pip默认给Python2用,pip3指定给Python3用。
重要:虚拟环境中,若只存在一个python版本,可以认为在用系统中pip和pip3命令都是相同的
因此用如下命令行来配置:
sudo pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
也可以根据requirements.txt内容一个一个库分开下载安装:
sudo pip3 install matplotlib==3.2.2 -i https://pypi.tuna.tsinghua.edu.cn/simple**
二、YOLOV5的运行
2.1 yolov5自带的数据运行
在做好前面的步骤之后,我们就可以运行YOLOv5的模型效果了。
为了便于展示,这里我们使用的是基础环境(base环境)
(base) mawei@ubuntu:~/Downloads/yolov50-6.0$ python3 detect.py --weights ./yolov5s.pt
# 输出结果在run文件夹的exp里面

2.2训练我们自己的数据
(1)制作自己的数据集
从网上下载一些你需要的数据集图片,比如这里我下载的是口罩检测的数据集,因为我要做口罩检测的模型。

备注:口罩数据集越大越好,标签越准确越好,训练轮数越多越好。
(2)打标签
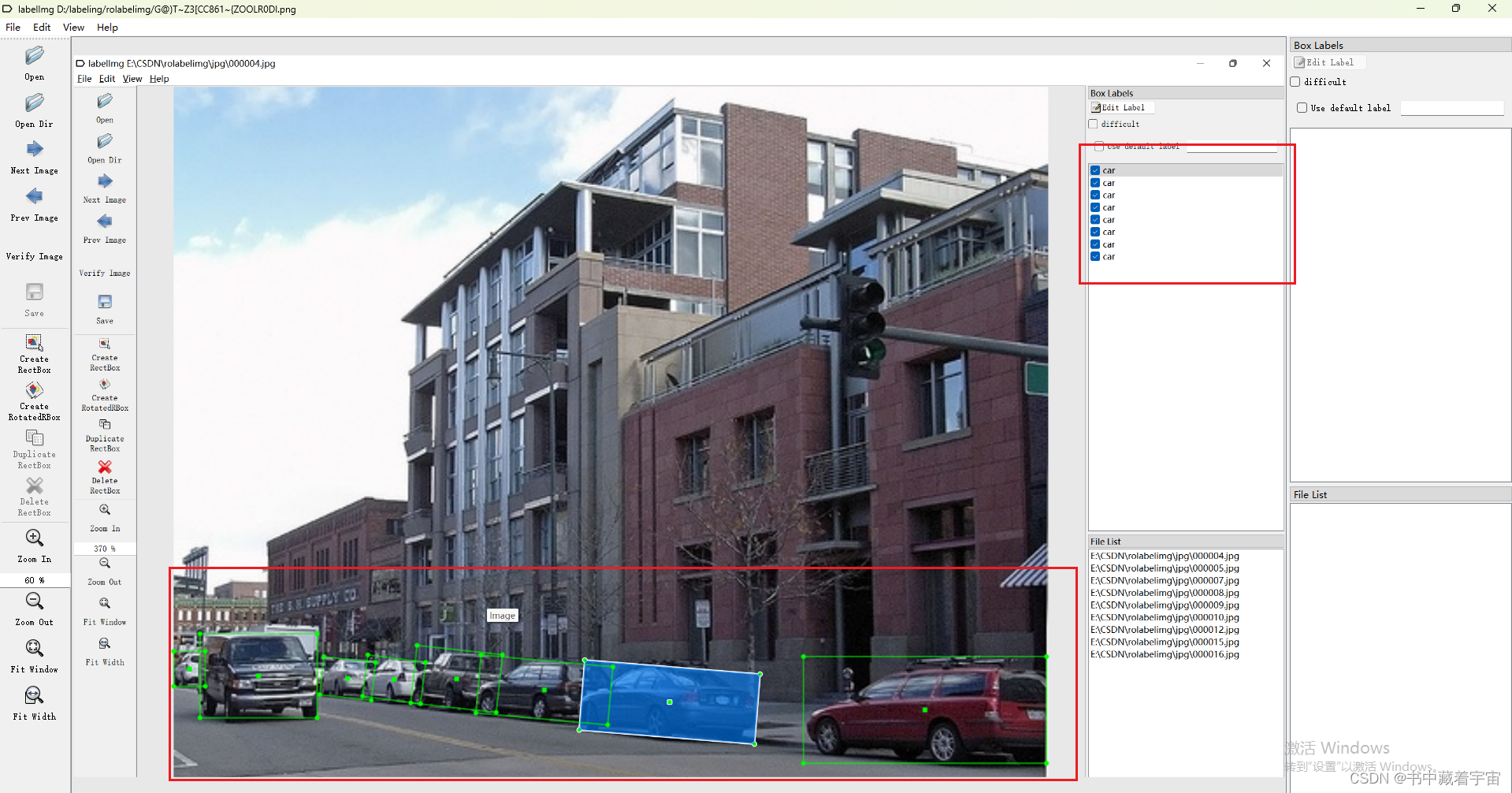
标签打好之后保存的xml的格式

我们需要将xml格式转换为yolov5可以识别的txt文件格式,这里可以自行搜索xml转换为txt文件的程序。
import os
import xml.etree.ElementTree as ET
# xml文件存放目录(修改成自己的文件名)
input_dir = r'G:\XmlToTxt-master\VOC\Annotations'
# 输出txt文件目录(自己创建的文件夹)
out_dir = r'G:\\XmlToTxt-master\VOC\txt'
class_list = []
# 获取目录所有xml文件
def file_name(input_dir):
F = []
for root, dirs, files in os.walk(input_dir):
for file in files:
# print file.decode('gbk') #文件名中有中文字符时转码
if os.path.splitext(file)[1] == '.xml':
t = os.path.splitext(file)[0]
F.append(t) # 将所有的文件名添加到L列表中
return F # 返回L列表
# 获取所有分类
def get_class(filelist):
for i in filelist:
f_dir = input_dir + "\\" + i + ".xml"
in_file = open(f_dir, encoding='UTF-8')
filetree = ET.parse(in_file)
in_file.close()
root = filetree.getroot()
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in class_list:
class_list.append(cls)
def ConverCoordinate(imgshape, bbox):
# 将xml像素坐标转换为txt归一化后的坐标
xmin, xmax, ymin, ymax = bbox
width = imgshape[0]
height = imgshape[1]
dw = 1. / width
dh = 1. / height
x = (xmin + xmax) / 2.0
y = (ymin + ymax) / 2.0
w = xmax - xmin
h = ymax - ymin
# 归一化
x = x * dw
y = y * dh
w = w * dw
h = h * dh
return x, y, w, h
def readxml(i):
f_dir = input_dir + "\\" + i + ".xml"
txtresult = ''
outfile = open(f_dir, encoding='UTF-8')
filetree = ET.parse(outfile)
outfile.close()
root = filetree.getroot()
# 获取图片大小
size = root.find('size')
width = int(size.find('width').text)
height = int(size.find('height').text)
imgshape = (width, height)
# 转化为yolov5的格式
for obj in root.findall('object'):
# 获取类别名
obj_name = obj.find('name').text
obj_id = class_list.index(obj_name)
# 获取每个obj的bbox框的左上和右下坐标
bbox = obj.find('bndbox')
xmin = float(bbox.find('xmin').text)
xmax = float(bbox.find('xmax').text)
ymin = float(bbox.find('ymin').text)
ymax = float(bbox.find('ymax').text)
bbox_coor = (xmin, xmax, ymin, ymax)
x, y, w, h = ConverCoordinate(imgshape, bbox_coor)
txt = '{} {} {} {} {}\n'.format(obj_id, x, y, w, h)
txtresult = txtresult + txt
# print(txtresult)
f = open(out_dir + "\\" + i + ".txt", 'a')
f.write(txtresult)
f.close()
# 获取文件夹下的所有文件
filelist = file_name(input_dir)
# 获取所有分类
get_class(filelist)
# 打印class
print(class_list)
# xml转txt
for i in filelist:
readxml(i)
# 在out_dir下生成一个class文件
f = open(out_dir + "\\classes.txt", 'a')
classresult = ''
for i in class_list:
classresult = classresult + i + "\n"
f.write(classresult)
f.close()
转换成功之后,我们需要把数据分为训练集和验证集。
训练集用于训练模型,生成合适的参数和权重文件。
验证集用于对训练好模型的性能进行验证和统计,给出AUC,ROC,查全率,查准率等。
(3)训练集和验证集的划分格式
data(你的数据集)
-------train
------images(图片文件)
------labels(标注文件)
--------val(验证集)
------images(图片文件)
------labels(标注文件)
说明:images里面是图片文件,labels里面是对应图片中标注物体的类别和坐标
如:0 0.4669354838709677 0.23925501432664756 0.18225806451612903 0.3123209169054441

(4)开始制作自己的yaml文件
这里我建立的mask.yaml文件,保存在data文件中

# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /home/mawei/Downloads/yolov5-6.0/data/kouzhao # dataset root dir,根文件的绝对路径
train: ./train/images # train images (relative to 'path'),训练集图片相对于根文件路径的相对路径
val: ./val/images # val images (relative to 'path'),验证集图片相对于根文件路径的相对路径
test: # test images (optional),测试集合路径,可以选或者不选
# Classes
nc: 2 # number of classes,你需要分的类,这里我是分2类,戴口罩和不带口罩
names: ['mask','unmask'] # class names,所分类的名字,mask 和unmask
说明:其中:
path:数据集的根目录
train:训练集与path的相对路径
val:验证集与path的相对路径
nc:类别数量,因为这个数据集只有一个类别(fire),nc即为1。
names:类别名字
(5)修改模型配置文件
因为我们使用的是原始的yaml文件作为我们预训练模型配置文件的,这样子我们可以减少我们的训练时间。我们在这里可以直接修改model里面自带的yolov5s.yaml文件。需要把其中的nc改成2即可。
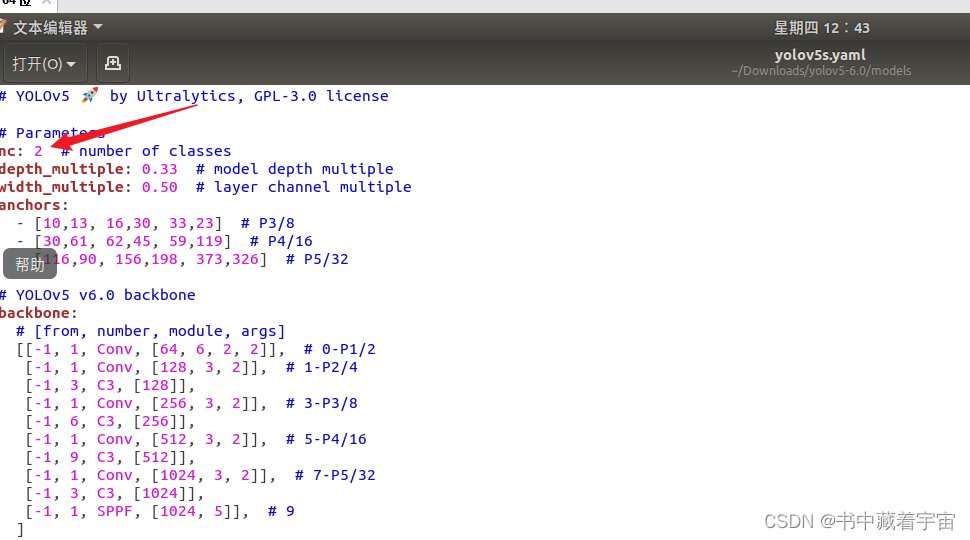
(6)开始训练
做好前面几步之后,我们就可以开始训练了。
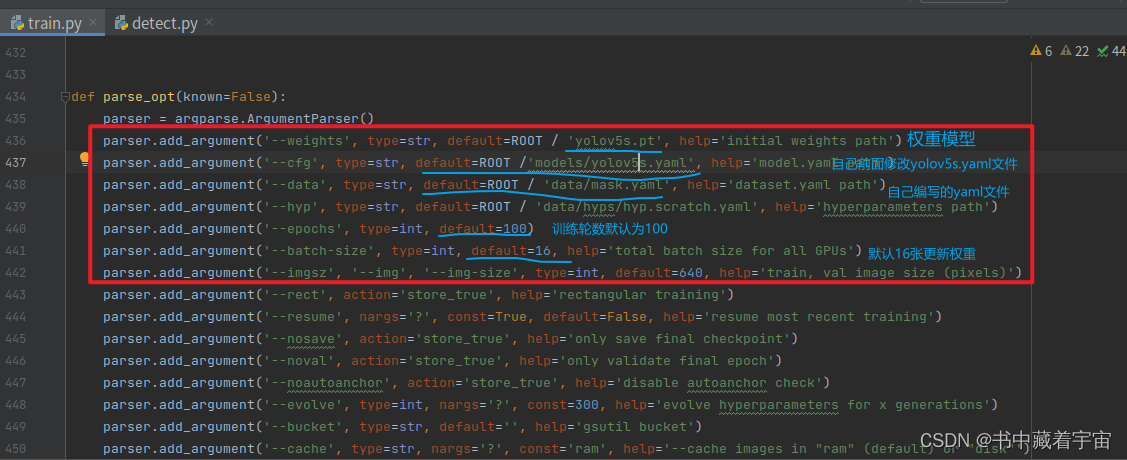
第一方法我们可以输入以下指令,开始训练。
python train.py --data mask.yaml --cfg yolov5s.yaml --weights yolov5s.pt --epoch 100 --batch-size 8 --device cpu
其中 --data:表示你自己写的配置文件
–cfg :需要迁移学习的配置文件
–weoghts:权重文件
–epoch:训练轮数
–device :cpu还是gpu
–batch:一次看完多少张图片才进行权重更新,梯度下降的mini-batch,显卡不行你就调小点
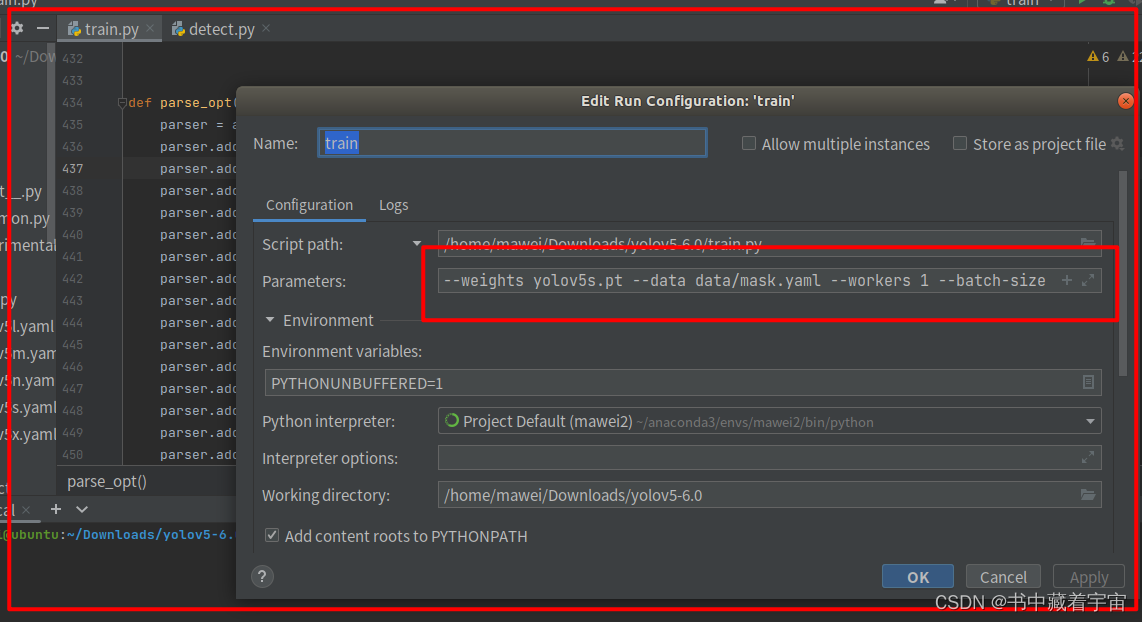
第二方法
打开PycharmIDE,打开train文件。
输入:
--weights yolov5s.pt --data data/mask.yaml --workers 1 --batch-size 8
然后点击运行train文件即可
以上两种方法都可以对自己的数据集进行训练。
(7)训练结果的检查
训练模型的指标结果在run/train/exp里面
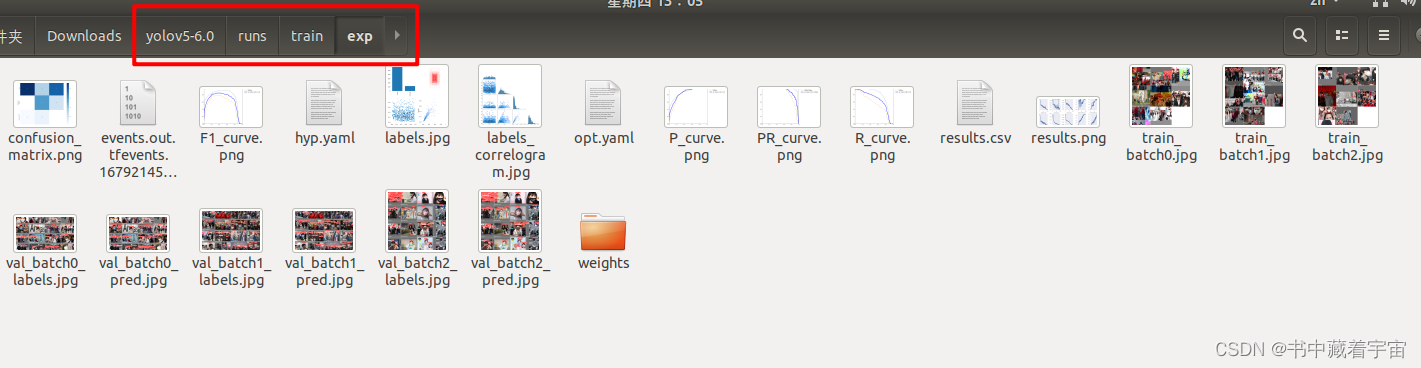
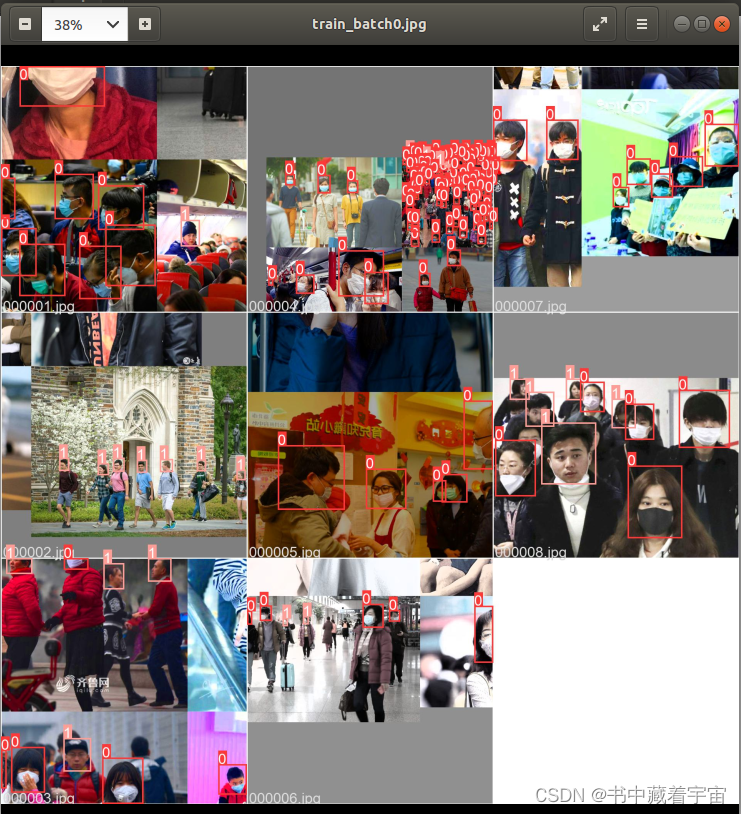
可以看到,我使用的第二种方法进行训练的,所以trainnatch0.jpg里面是8张图片一起的。而验证集没有指定,所以是16张图片一起的。

(8)模型使用
# 检测摄像头
python detect.py --weights runs/train/weights/best.pt --source 0 # webcam
# 检测图片文件
python detect.py --weights runs/train/weights/best.pt --source file.jpg # image
# 检测视频文件
python detect.py --weights runs/train/weights/best.pt --source file.mp4 # video
# 检测一个目录下的文件
python detect.py --weights runs/train/weights/best.pt path/ # directory
# 检测网络视频
python detect.py --weights runs/train/weights/best.pt 'https://youtu.be/NUsoVlDFqZg' # YouTube video
# 检测流媒体
python detect.py --weights runs/train/weights/best.pt 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
备注
不同的模型训练出来的权重文件是不一样的
Usage - formats:
$ python path/to/detect.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s.xml # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (macOS-only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU

















 2719
2719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











