







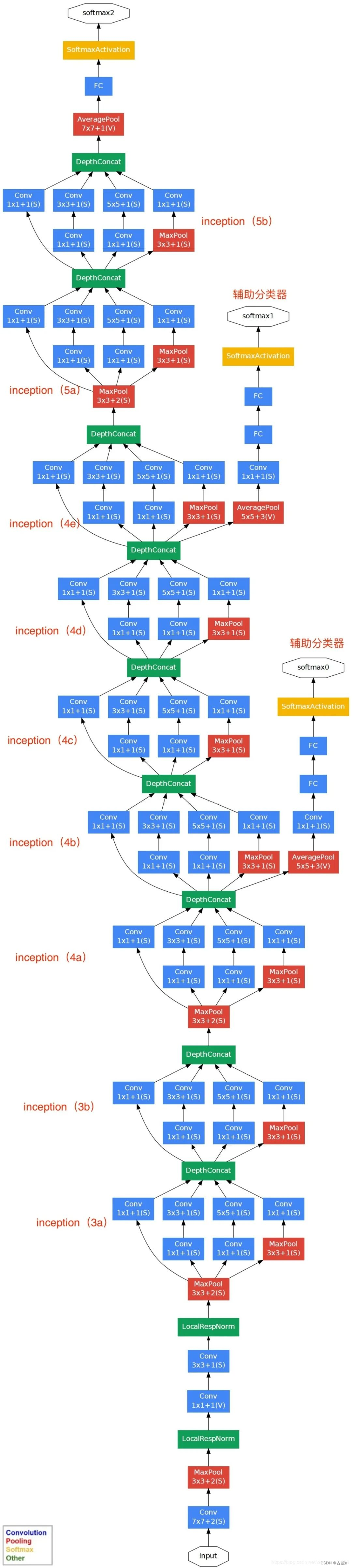
GoogLeNet
GoogLeNet的设计主要特点是引入了Inception模块,这是一种多尺度卷积结构,可以在不同尺度下进行特征提取。Inception模块使用了不同大小的卷积核和池化操作,并将它们的输出在通道维度上连接在一起,以获得更丰富的特征表示。
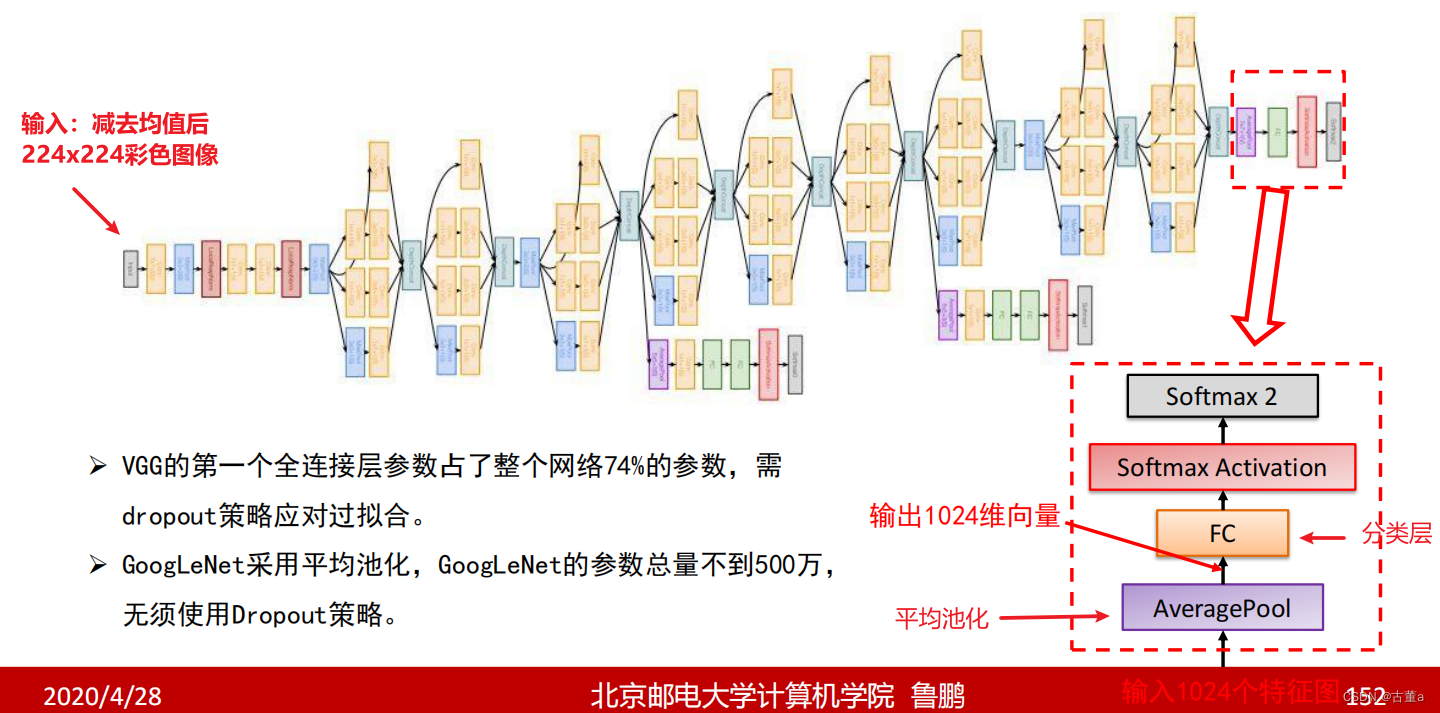
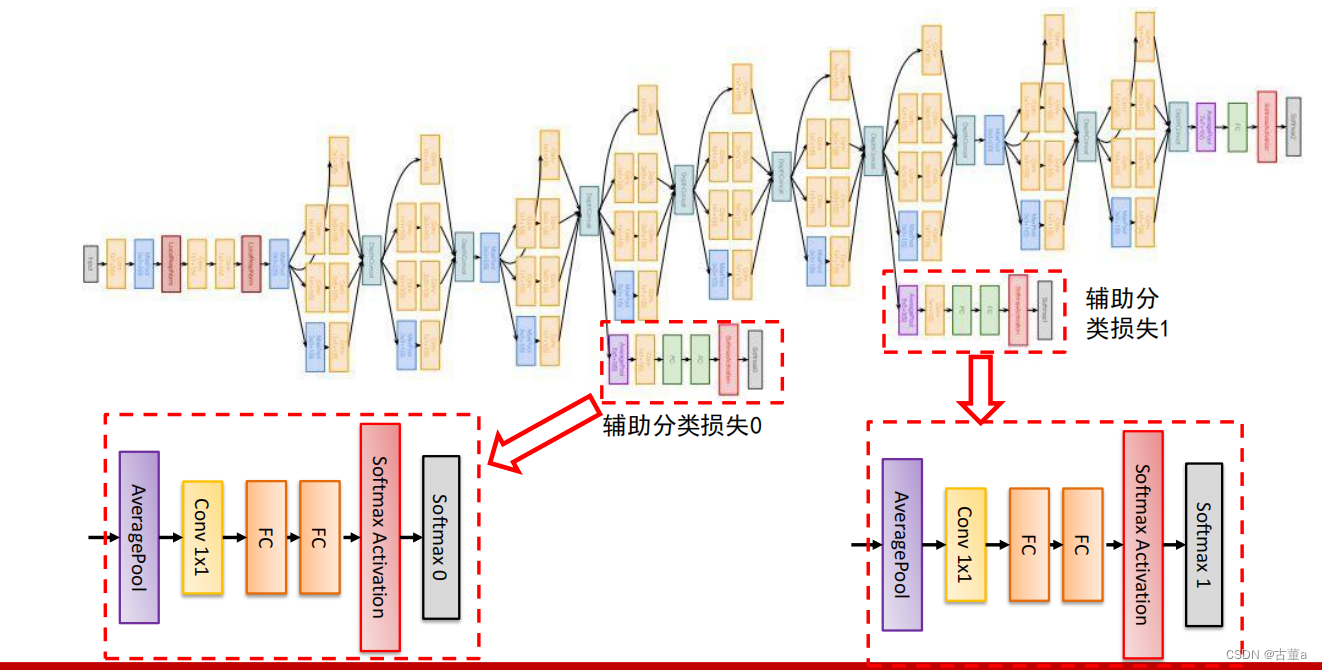
GoogLeNet还采用了一种称为"平均池化"(average pooling)的特殊池化方式来代替全连接层,以减少参数数量和计算量。此外,GoogLeNet还使用了辅助分类器(auxiliary classifier)来帮助训练深层网络,并通过附加的损失函数促进梯度的传播。
参考
GoogLeNet模型结构
创新点
串联结构(如VGG)存在的问题
后面的卷积层只能处理前层输出的特征图;前层因某些原因(比如感受野限制)丢失重要信息,后层无法找回。
解决方案:每一层尽量多的保留输入信号中的信息。
Inception结构,它能保留输入信号中的更多特征信息
Inception 结构的主要思路是怎样用密集成分来近似最优的局部稀疏结构。
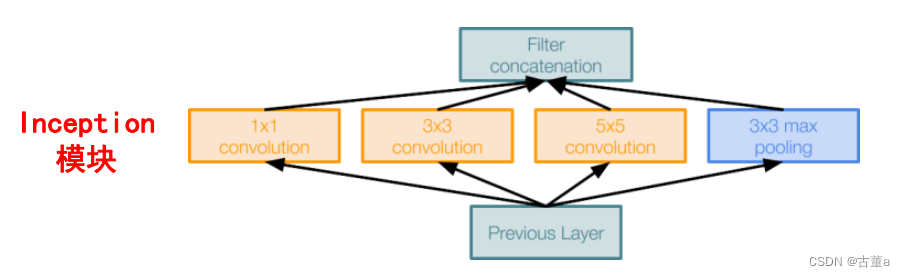
1、采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2、 之所以卷积核大小采用1、3和5,主要是为了方便对齐。
设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征。
3、3×3 max pooling 可理解为非最大化抑制。
文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。保留且加强了原图中比较重要的信息。
4、网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
5、1×1 3×3 5×5卷积,及3×3max pooling,通过设定合适的padding都会得到相同维度的特征,然后将这些特征直接拼接在一起。
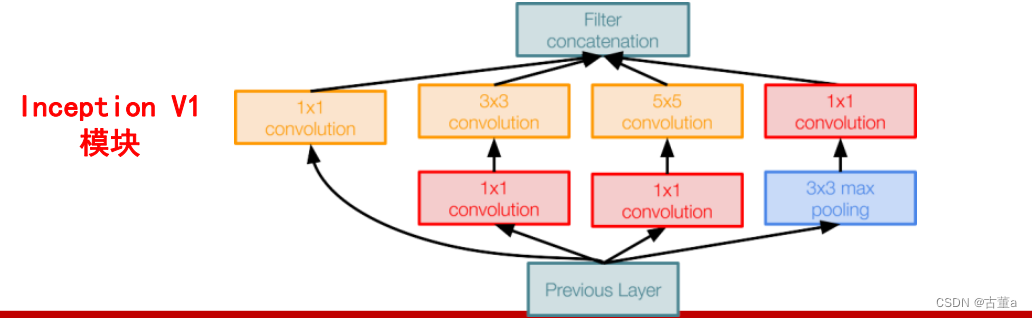
但是,使用5x5的卷积核仍然会带来巨大的计算量。
为此,文章借鉴NIN2,采用1x1卷积核来进行降维。
具体改进后的Inception Module如下图:
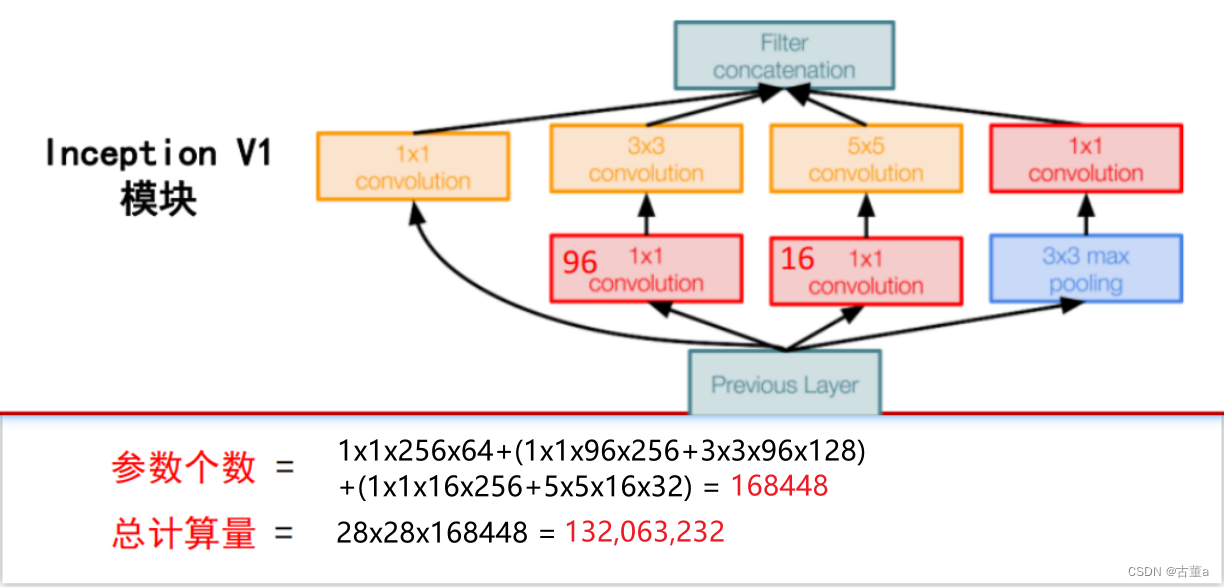
例如:上一层的输出为100x100x128,经过具有256个输出的5x5卷积层之(stride=1,pad=2),输出数据为100x100x256。其中,卷积层的参数为128x5x5x256。
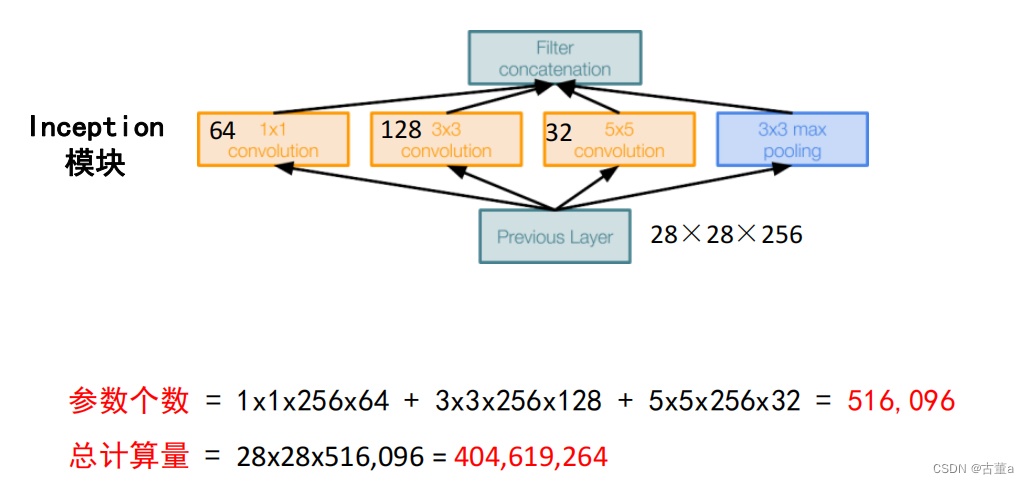
假如上一层输出先经过具有32个输出的1x1卷积层,再经过具有256个输出的5x5卷积层,那么最终的输出数据仍为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256,大约减少了4倍。
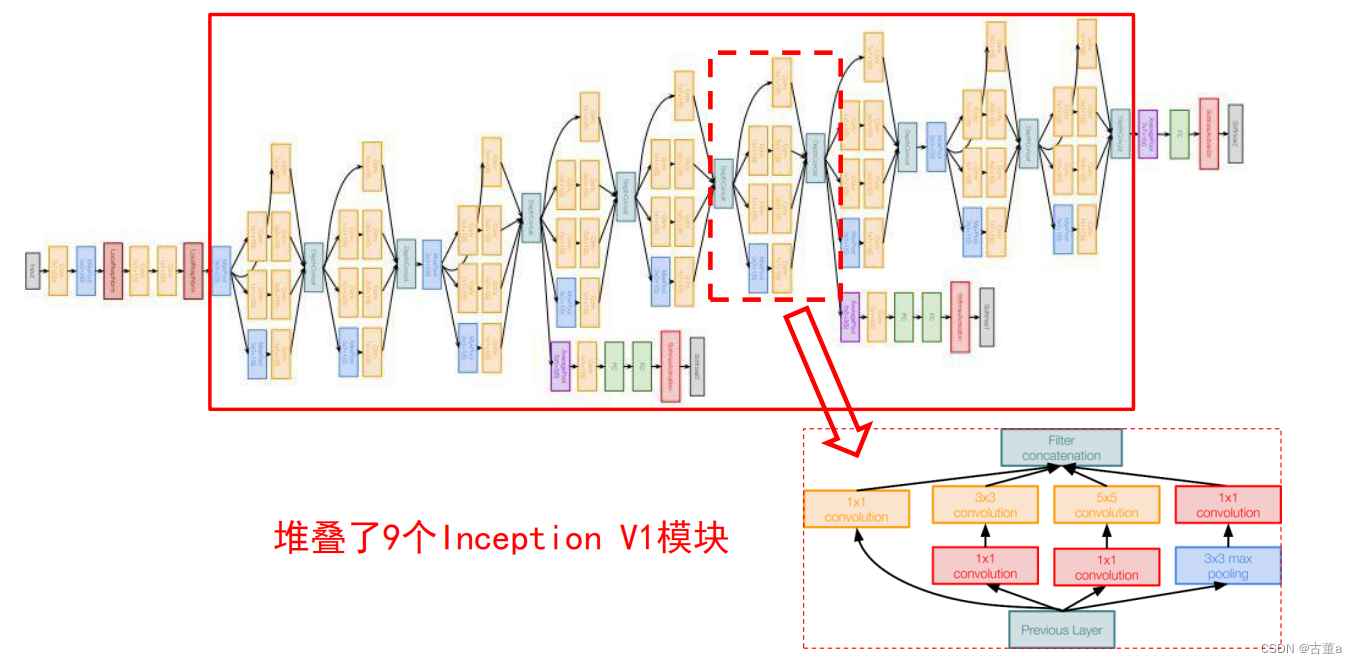
层数更深、参数更少、计算效率更高、非线性表达能力也更强
去掉了AlexNet的前两个全连接层,并采用了平均池化
这一设计使得GoogLeNet只有500万参数,比AlexNet少了12倍
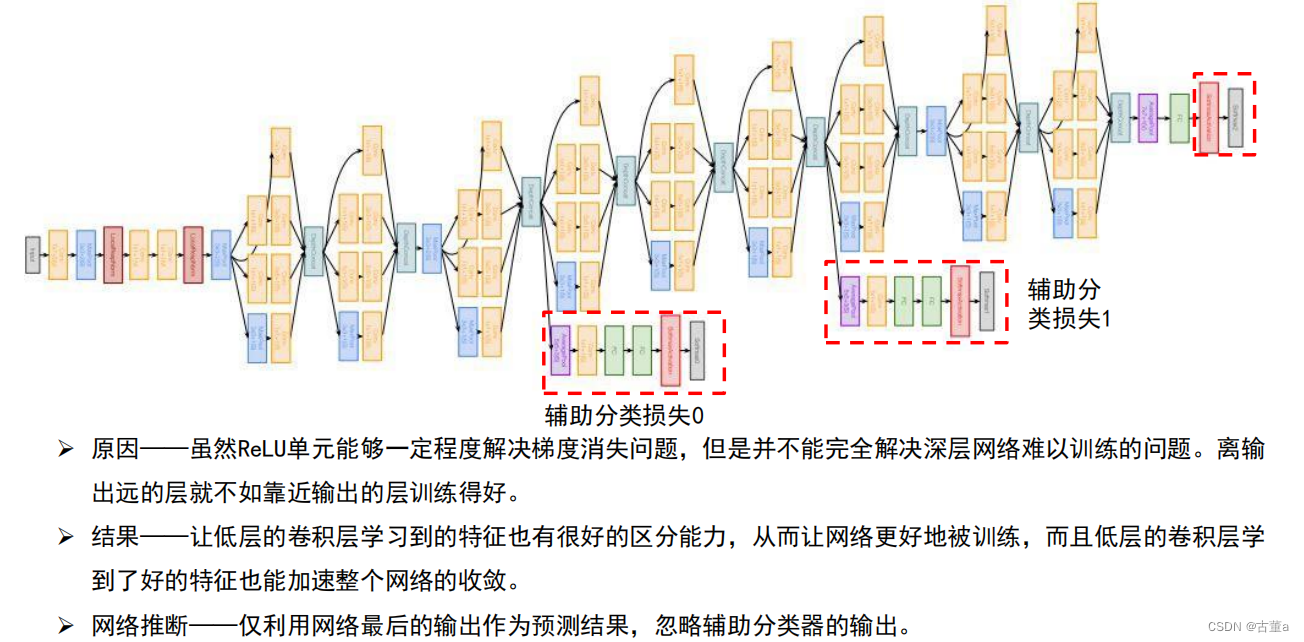
引入了辅助分类器
克服了训练过程中的梯度消失问题
问题1:平均池化向量化与直接展开向量化有什么区别?
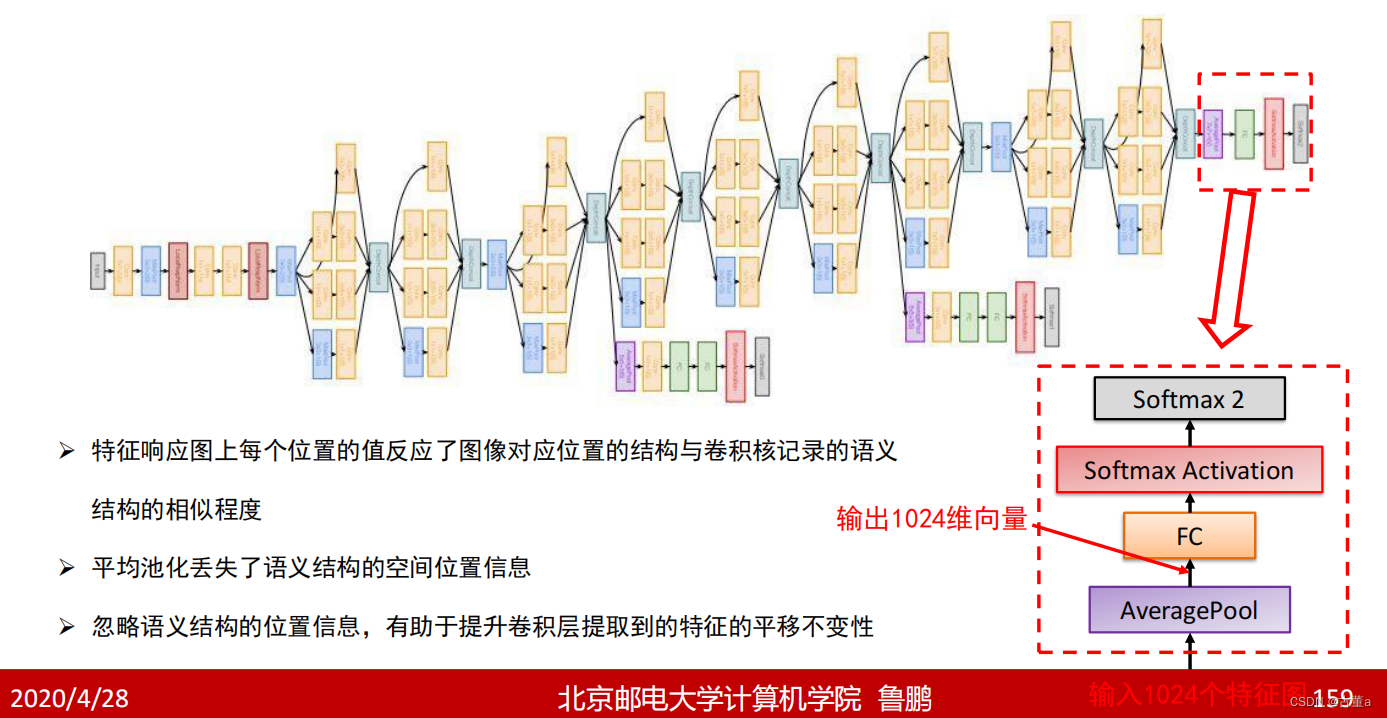
特征响应图中位置信息不太重要,平均池化,忽略位置信息,可以很大节省计算量。
问题2: 利用1 x1卷积进行压缩会损失信息吗?
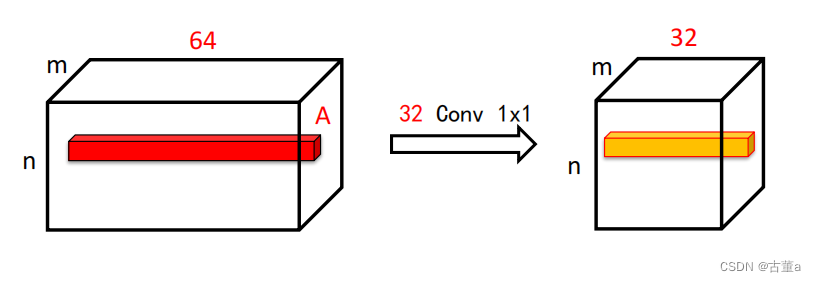
不会,假设图像或特征响应图深度通道为64,其中记录信息的只有少数,对应的向量非常稀疏,且其后的每个卷积核(深度通道也为64)都作用在这64个通道上。 经过压缩,并不会影响图像原始信息的记录。















 431
431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









