







目录
参考
暖焱:【深度学习】05-01-Transformer-李宏毅老师21&22深度学习课程笔记
B站:强烈推荐!台大李宏毅自注意力机制和Transformer详解!
Seq2seq
列举Seq2seq的适用任务。
encoder:输入向量序列,处理,输出向量序列。
Transformer’s Encoder 原始论文设计的结构。
Transformer’s Encoder 原始论文设计的结构并不是最优。
Sequence-to-sequence(Seq2seq)适用任务
输入一个序列,输出一个序列,但是输出序列的长度由模型自己来决定。
下面是Seq2seq的例子。
语音识别
语音辨识。输入一段声音讯号,经过语音识别,输出N个字符,但是无法得知具体输出的字符个数,所以只能由机器来自主决定输出多少字符。
机器翻译

机器翻译,输入某一种语言的一句话,经过翻译输出另一种语言的句子,但是输出的字符数是认为确定不了的,这种情况下只能通过机器自主决定。
语音翻译

台语是不普及的。很多人并不清楚。
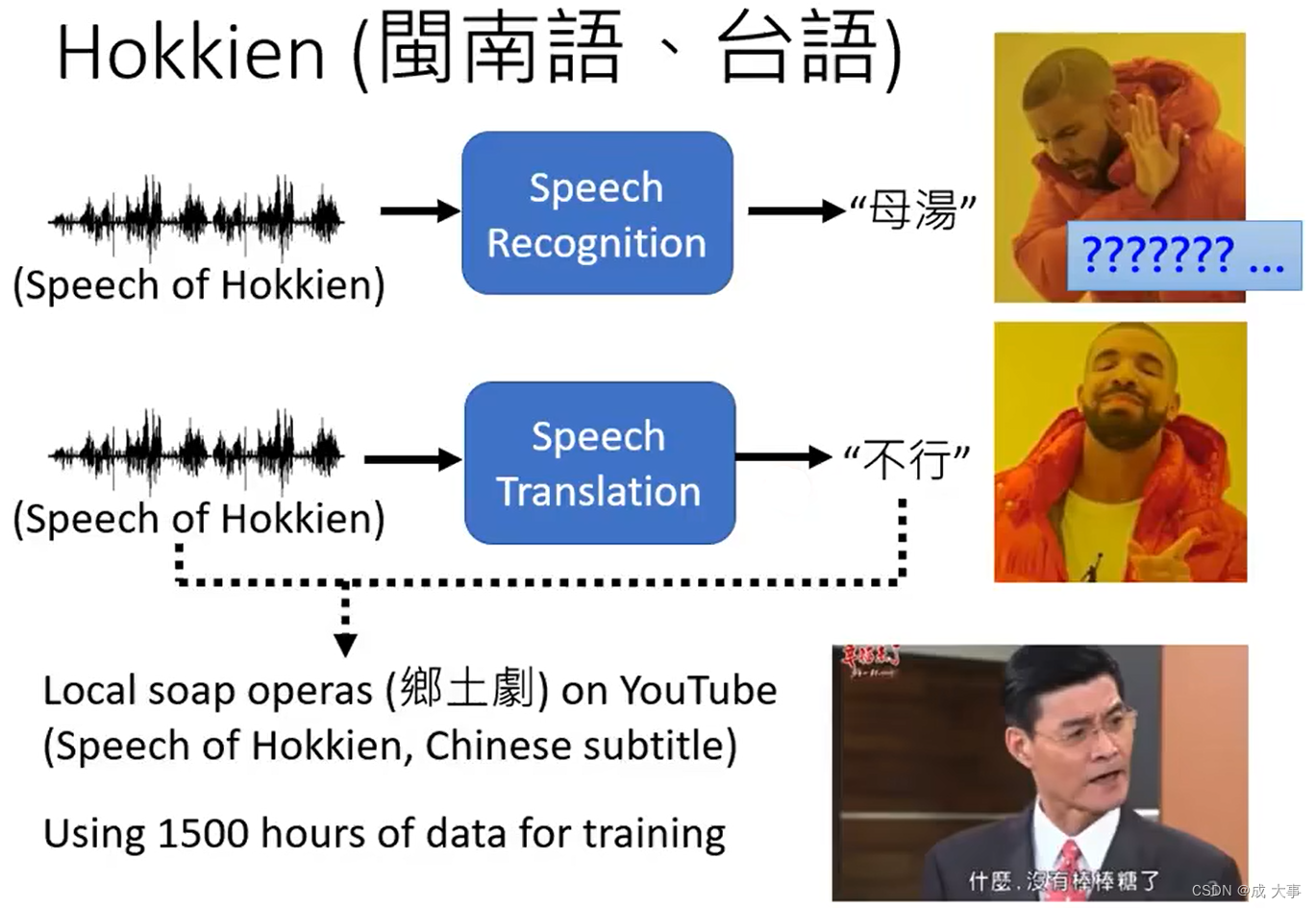
语音翻译。 语音翻译与语音识别不同,考虑一种没有文字的语言(如:台语),输入该语言的语音到机器中,通过机器处理,得到一种人类可以理解的文字。
语音合成
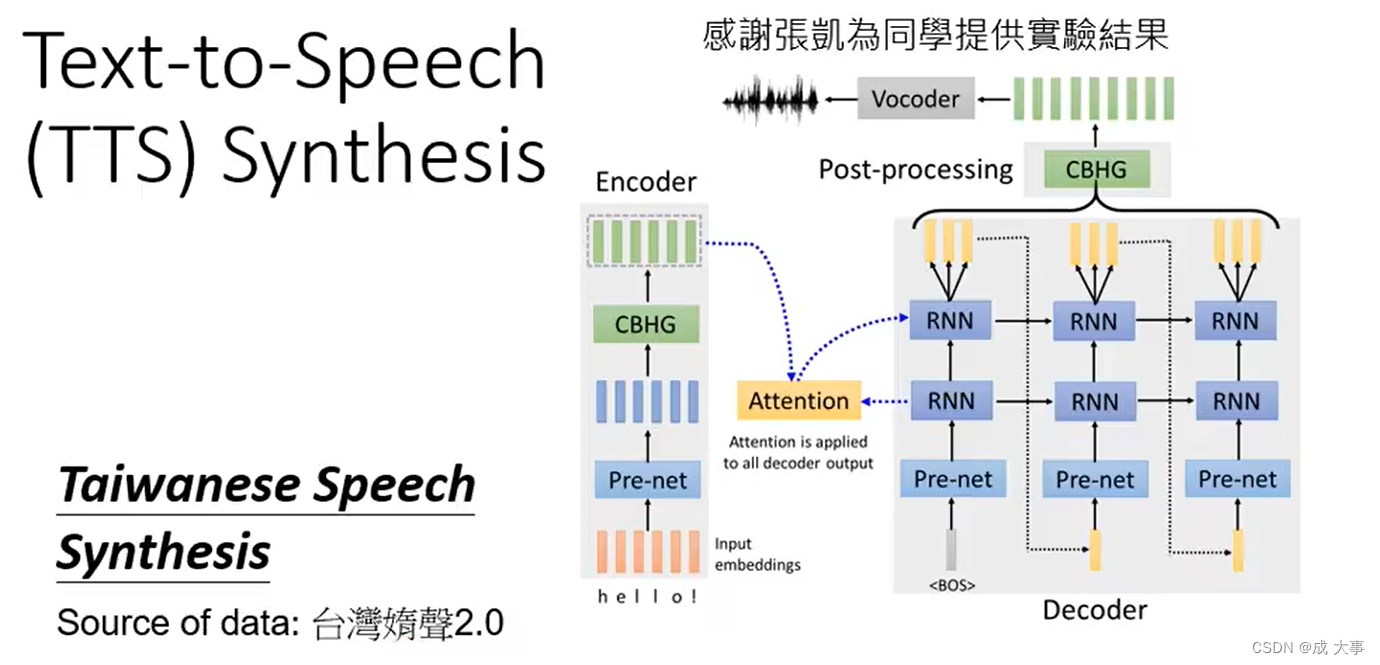
语音合成:输入一串文字,输出一段语音。
聊天机器人
聊天机器人:收集对话来进行训练。但是对机器说出“Hi”的时候,机器会回复“Hello!How are you today?”。
自然语言处理
问答系统(Question Answering)
任何自然语言处理的问题都可以看做是QA问题。
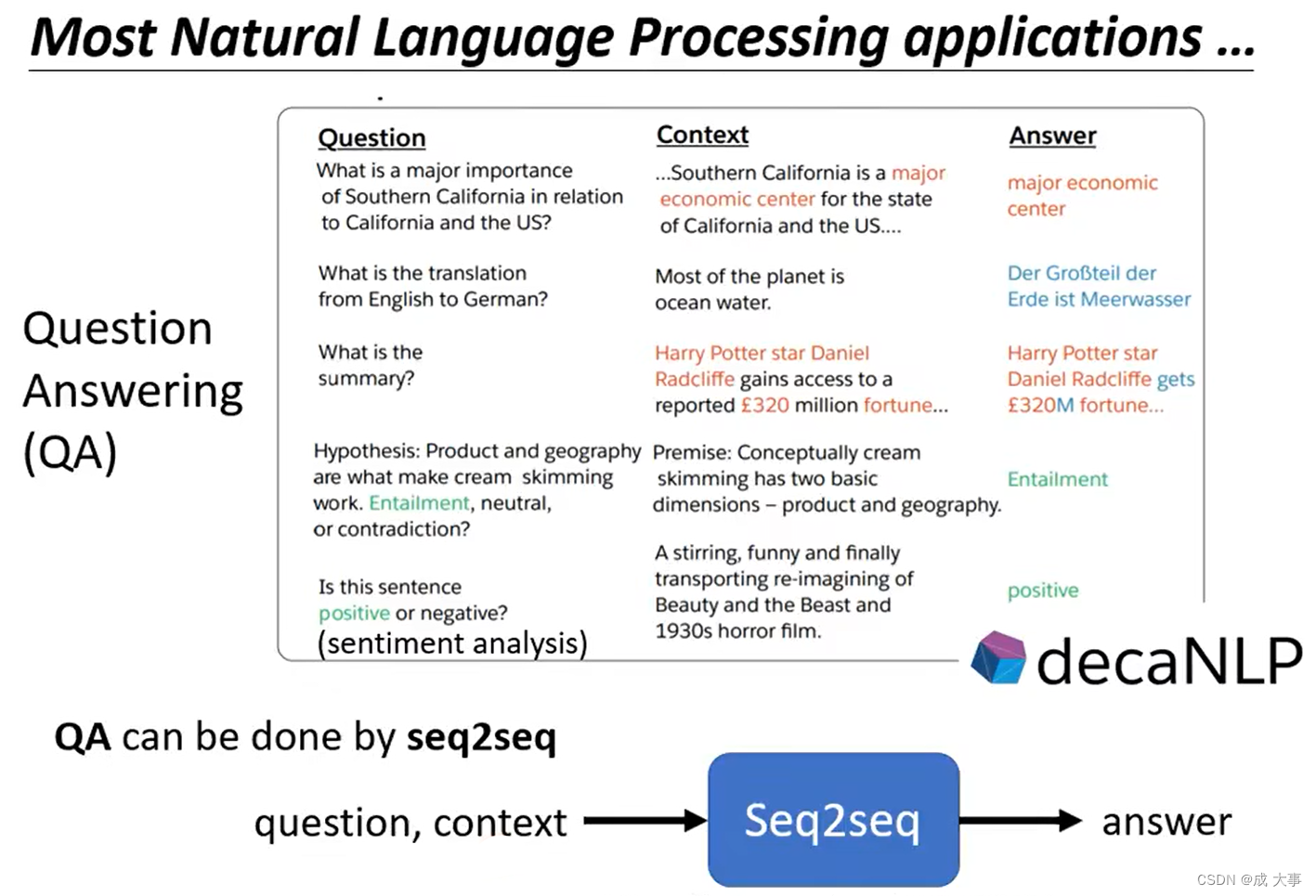
学习更多:
The Natural Language Decathlon: Multitask Learning as Question Answering
LAMOL: LAnguage MOdeling for Lifelong Language Learning
自然语言处理。
上述应用,使用客制化模型比使用通用Seq2seq可以得到更好的结果。
有些应用,即使不是Seq2seq模型的问题,仍用Seq2seq的模型处理。例如下面的例子。
硬解任务:文法分析
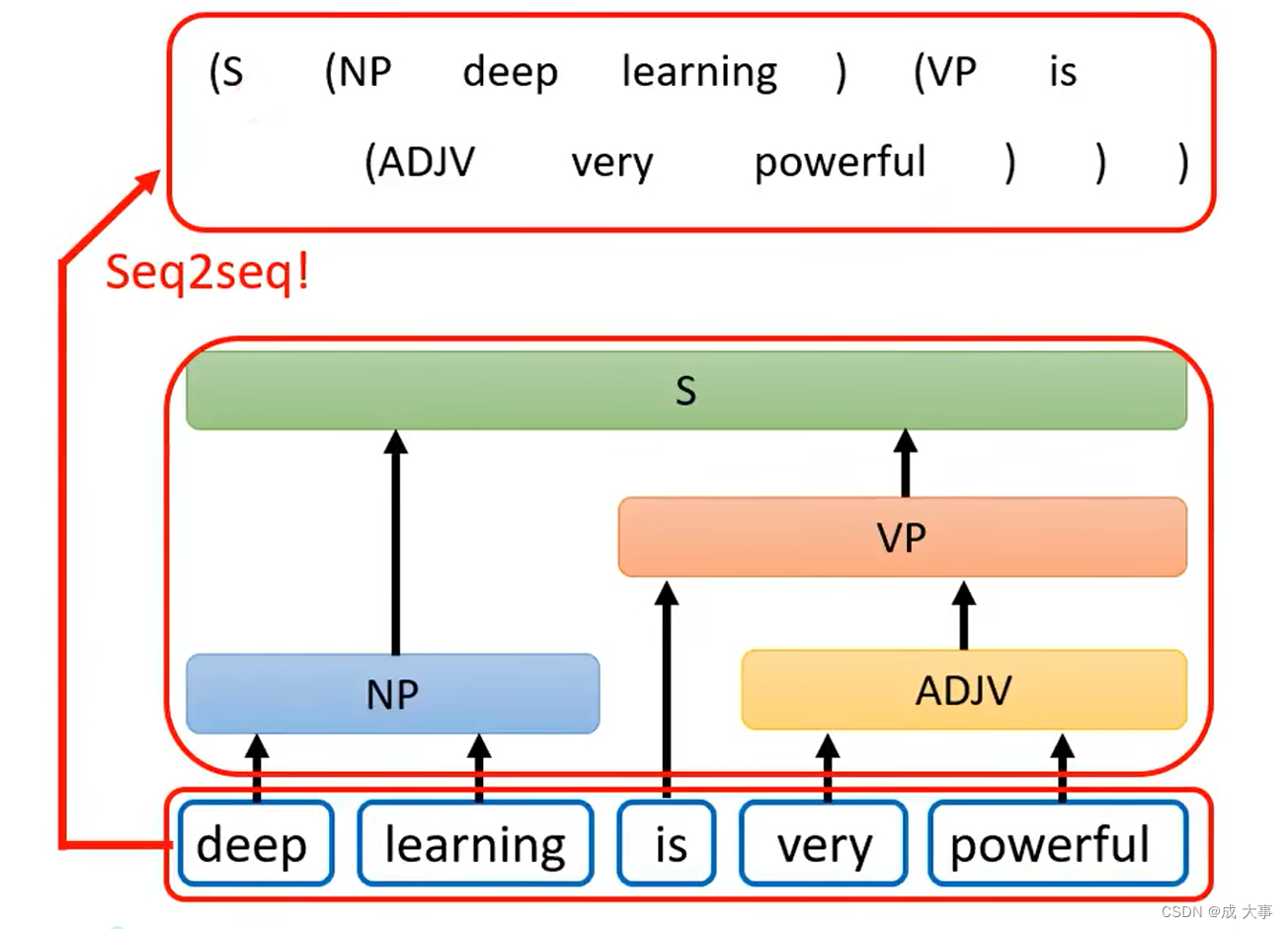
文法剖析。
论文Grammar as a Foreign Language中,将文法剖析任务看做翻译任务,并且得到了很好的效果。
硬解任务:多标签分类
多标签分类任务(multi-label classification):一个输入对应多个类别。
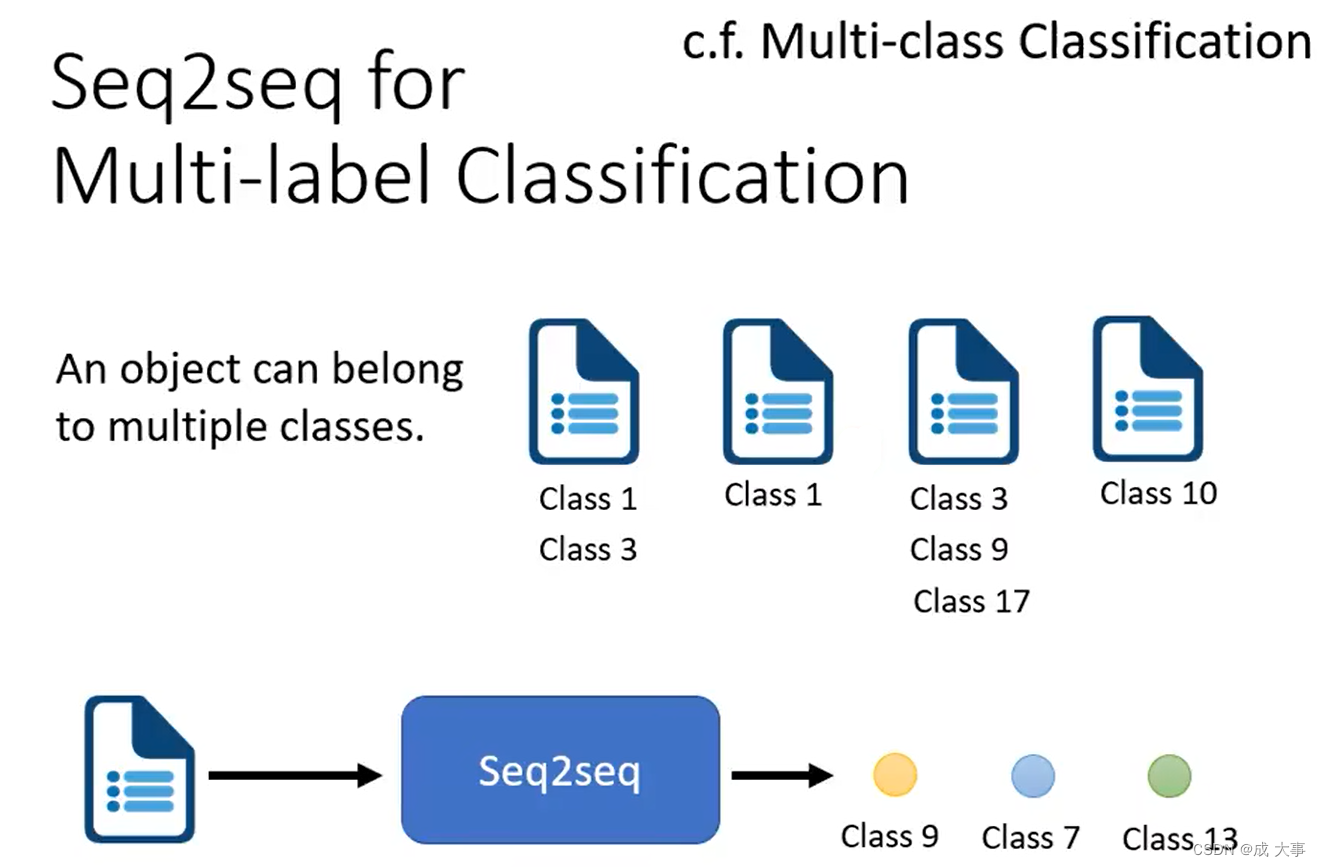
多标签分类的处理方法:输入经过Seq2seq模型处理,机器自己决定输出多少个类别。
注意:
- 多标签分类任务不能使用多分类任务的方法处理,因为输入对应的类别数不同,不能事先规定固定的输出类别数。
多类分类任务(multi-class classification) :是将输入样本分到多个互斥的类别中的一个。换句话说,每个样本只能被分配到一个类别。
处理方法:输入经过处理后输出多个类别的分数,取最高的1个类别为结果输出。
了解更多:
Order-free Learning Alleviating Exposure Bias in Multi-label Classification
Order-Free RNN with Visual Attention for Multi-Label Classification
硬解任务:目标检测
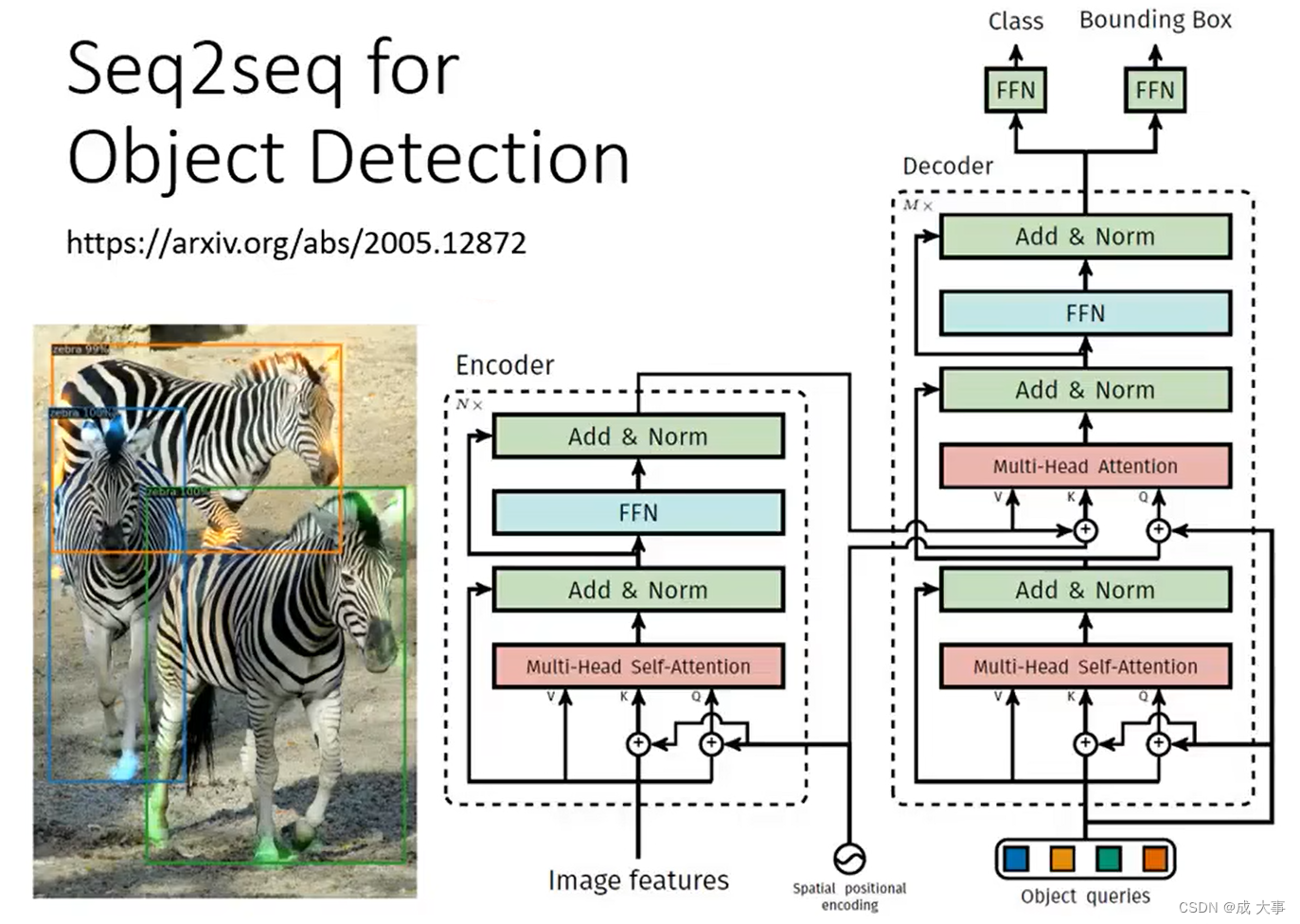
详细了解:End-to-End Object Detection with Transformers
Sequence-to-sequence(Seq2seq)
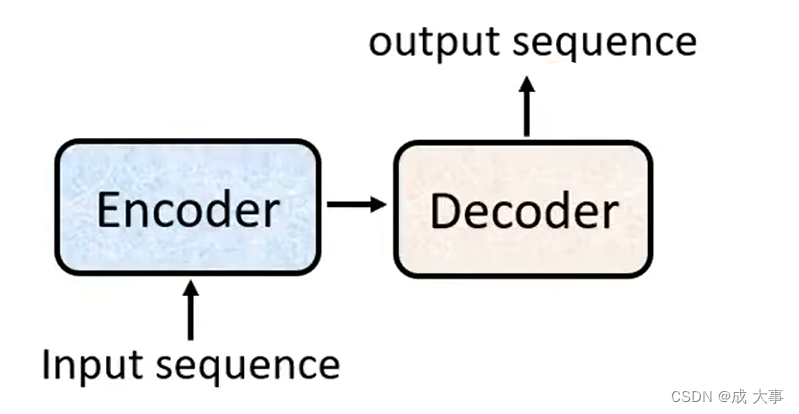
内部结构分为两个部分,一个是encoder另一个是decoder。
一个是编码器,一个是解码器。输入一个seq给Encoder, 处理的结果丢给decoder,然后decoder来决定输出一个什么样的seq。
Seq2Seq最开始是被用在翻译上面,下面是其结构。
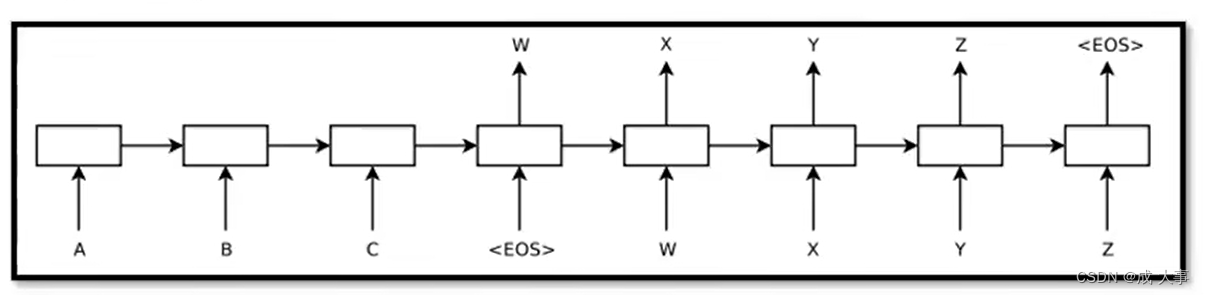
详情了解:Sequence to Sequence Learning with Neural Networks
随着人们对seq2seq的研究越发深入,现在主要应用在transformer上面,结构如下图:
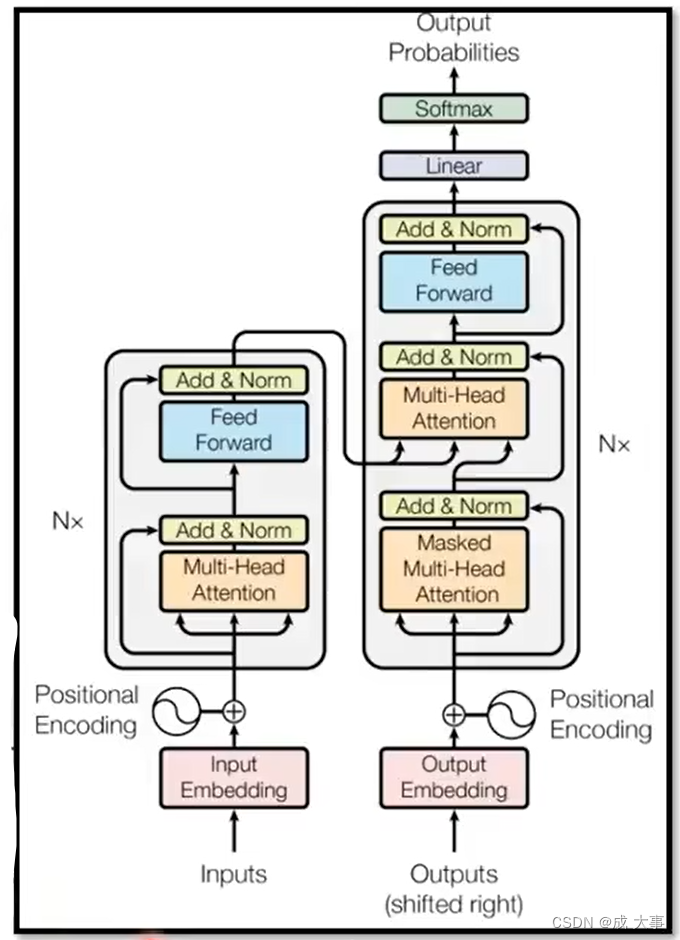
Transformer的经典论文:Attention Is All You Need
Encoder
Encoder主要工作就是输入一排向量,输出另外一排向量。但是这样子的工作很多模型都可以做到,比如self-attention(自注意力),RNN,CNN。Transform里面用的就是self-attention(自注意力)。
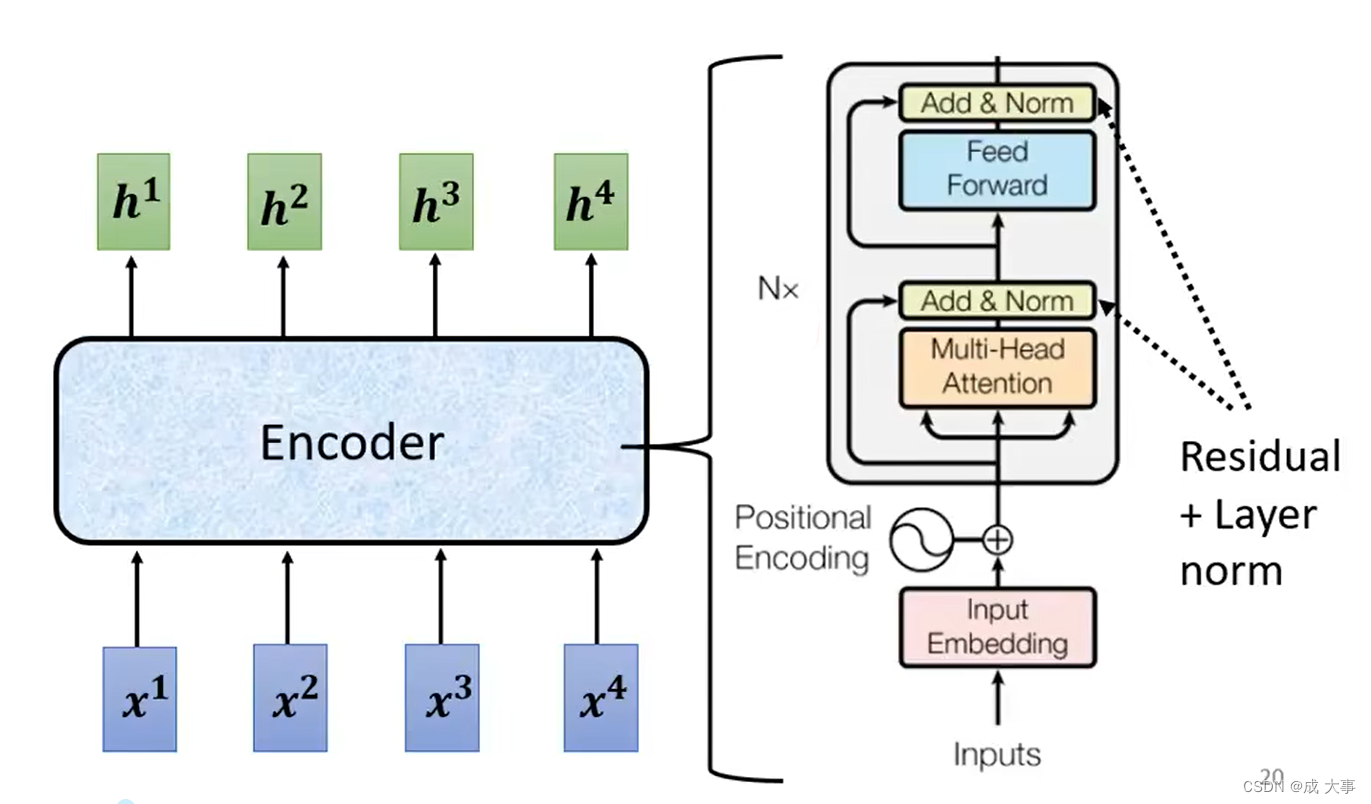
- 输入。
- Positional Encoding 位置编码,Self-attention 本身没有位置信息。
- 输入block。
- 多头注意力。
- add & norm。即 residual + layer norm
- fully connected network feed forward。
- add & norm。即 residual + layer norm。
- 输出block。
- 可重复多次block。
Transformer’s Encoder 结构如下:
- 在inputs的地方加上了positional encoding,之前有讲过如果只用self-attention,没有位置信息,所以需要加上positional的information。
- Multi-Head Attention:这里就是self-attention的block,然后专门强调说它是Multi-Head的self-attention。
- Add&Norm:residual加上layer normalization。
- Feed Forward: 是FC的feed forward network。
- N×:block会重复N次。
encoder里面会分成很多的block,每个block都是输入一排向量输出一排向量。
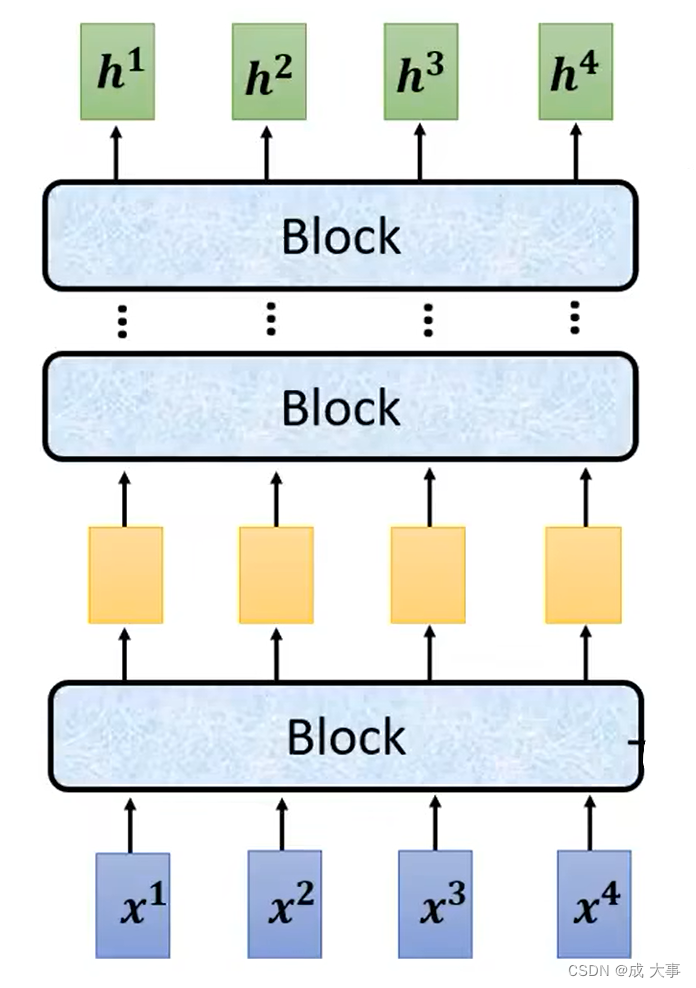
但是每个block并不是neural network的一层(layer),是因为一个block里面是好几个layer在做事情。
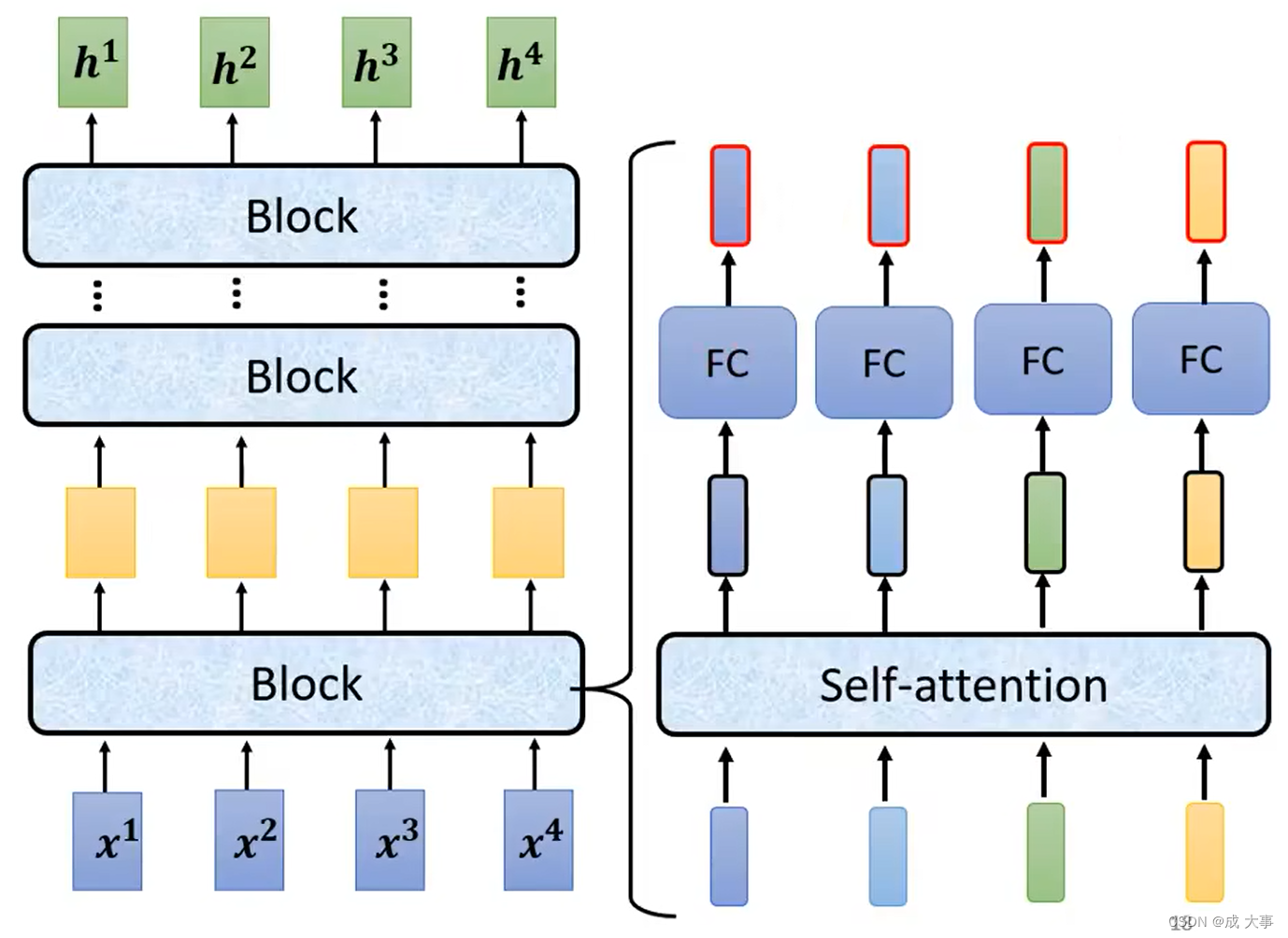
每个block里面的工作:
- 输入一排向量
- 经过self-attention处理
- 输出一排向量
- 再将输出的每个向量丢到fully connected的feed forward network里面
- output一排新的vector
Transformer’s Encoder 原始论文设计
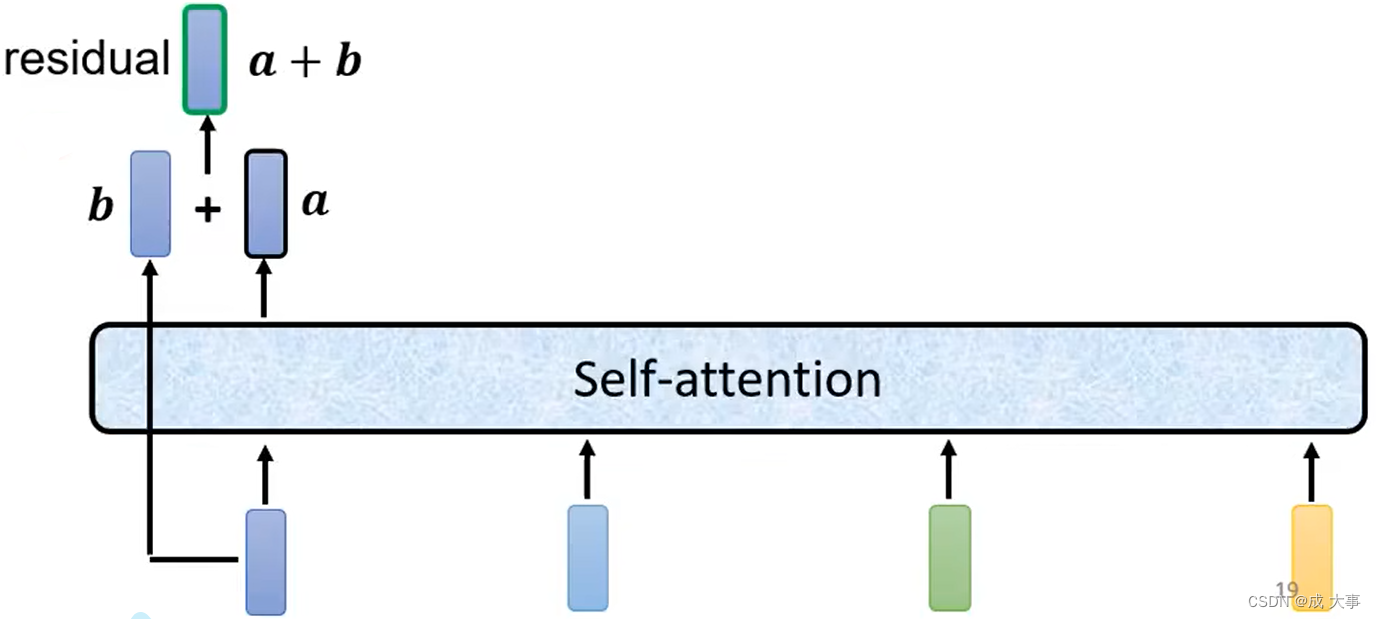
原来的Transformer里面的block的结构较复杂。
原先的设计不只是输出一个vector,还要把输出的vector加上它的input得到新的output。这样的network架构叫做residual connection。
这种架构在deep learning的领域应用非常的广泛。
[补充:为什么Encoder中要使用residual connection?]
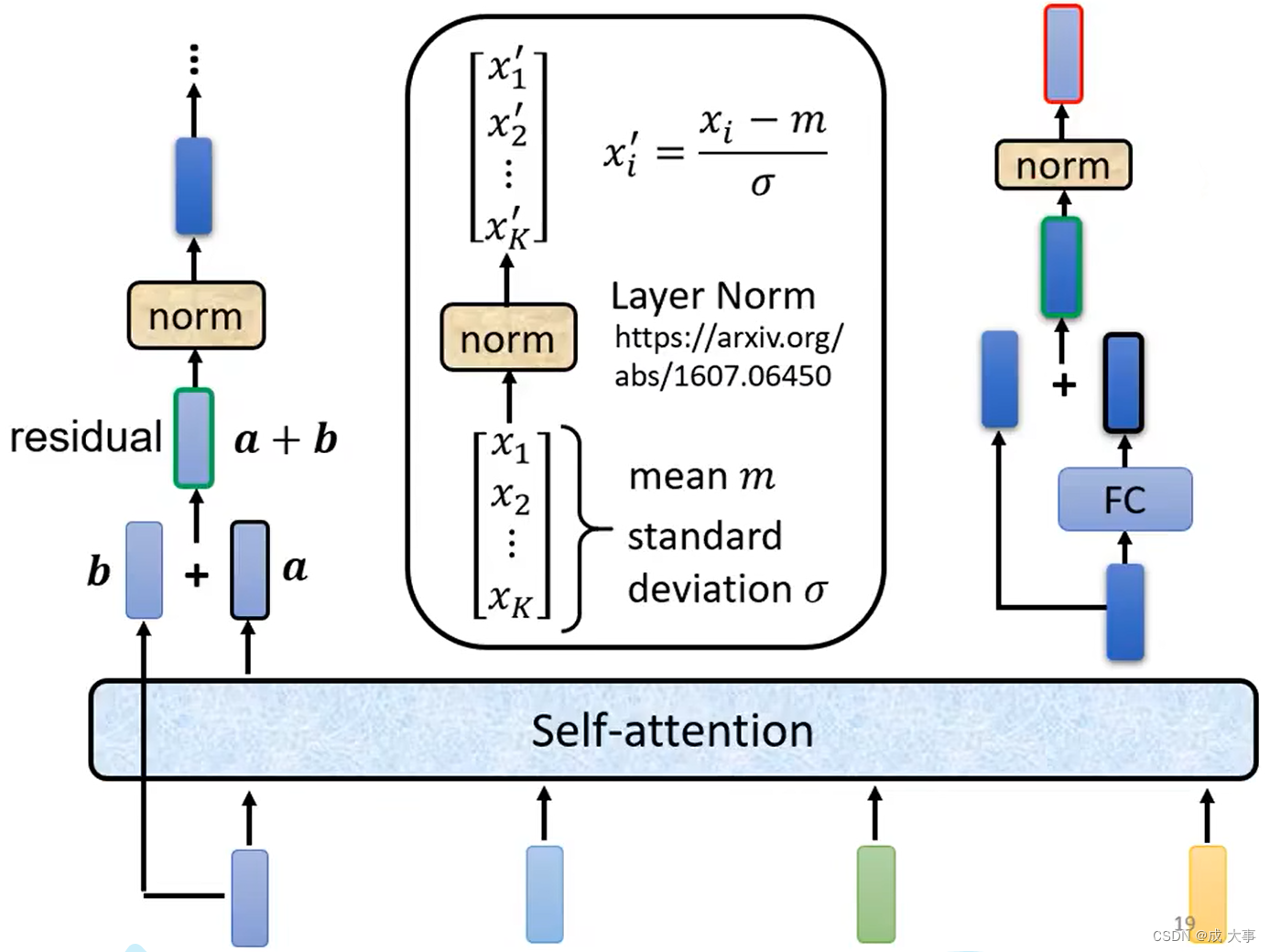
得到residual 的结果以后在经过norm,这里的norm不是batch normalization,用的是layer normalization。
它做的事情比batch normalization更简单一点,简而言之layer norm就是输入一个向量输出一个向量,不用考虑batch的资讯,过程就是对同一个feature同一个example里面不同的dimension去计算它的mean跟standard deviation(batch normalization 是对不同feature不同example的同一dimension计算mean跟standard deviation),然后在经过标准化就是layer normalization的输出。
这个输出后面是FC的输入,而FC里面也有residual的架构,我们会把FC network的input跟它的output加起来做一下residual得到新的输出,再把这个输出做一次layer normalization得到的才是真正的输出,这个输出才是transform encoder里面一个block的输出。
下图 self-attention 之上,展示了layer norm的过程。
Bert也使用了Transform的encoder。
Transform’s Encoder 原始论文的设计是否最优?- 不是
例如在On Layer Normalization in the Transformer Architecture这篇论文中,提出将layer norm放入block中。
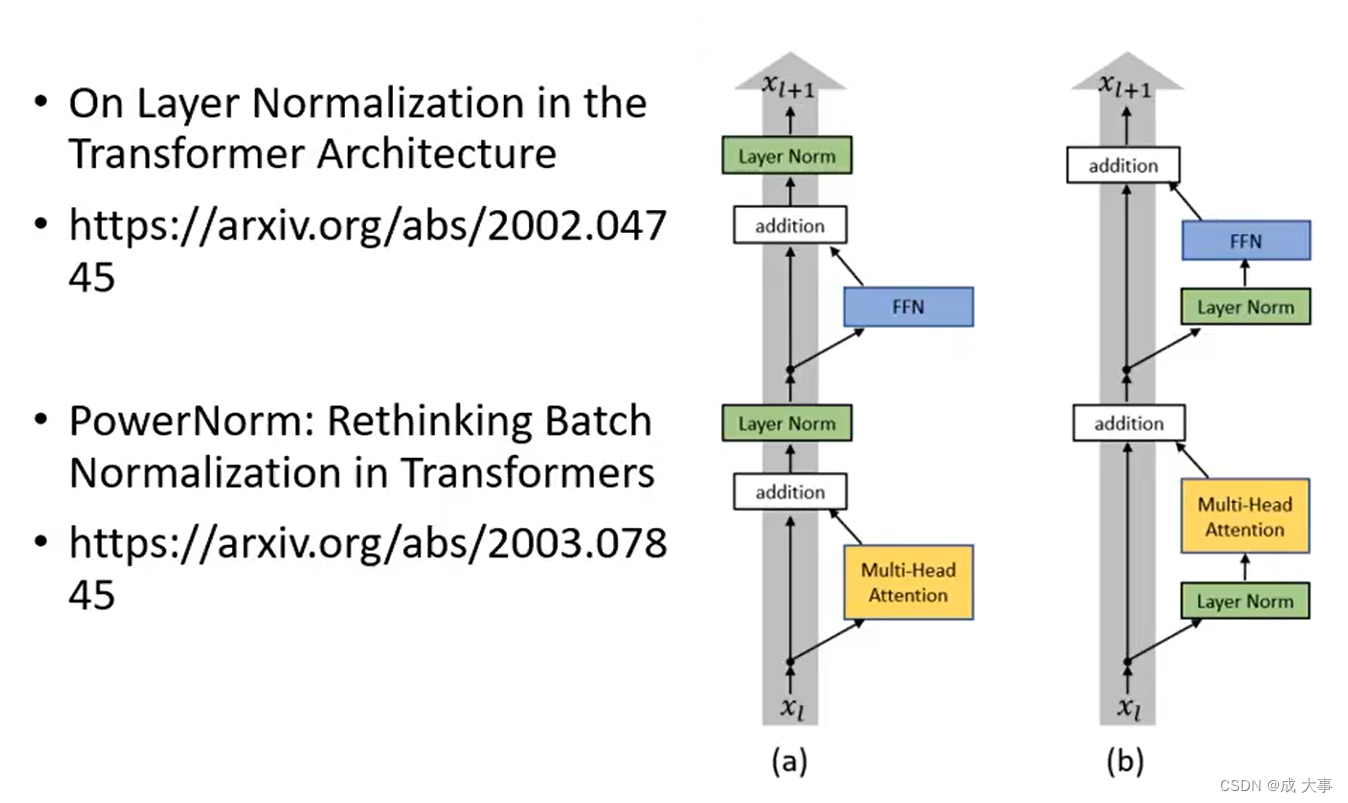
PowerNorm: Rethinking Batch Normalization in Transformers这篇论文中,分析回答了为什么transformer encoder中不是batch normalization而是layer nomalization,进而提出transformer encoder中使用power normalization,效果更好。
Decoder
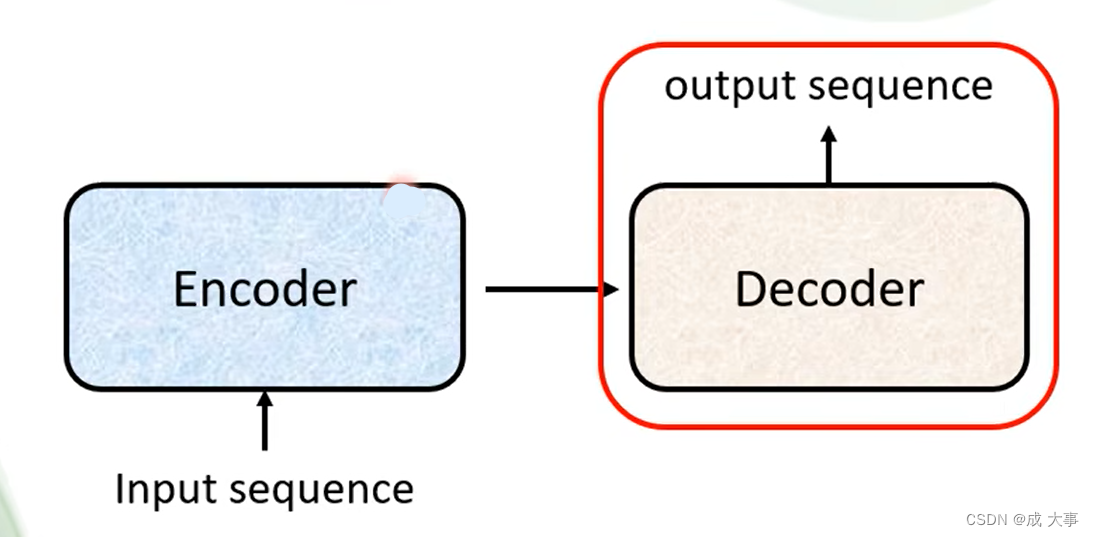
Autoregressive(AT)
decoder其实有两种,下面介绍Autoregressive de decoder(AT),是通过语音辨识来详细了解它的运作过程。
首先,输入一个声音讯号,经过encoder输出一组vector,然后将这个输出当decoder的输入,最后产生语音辨识的结果。
Autoregressive Decoder 如何开始?- “begin”
Decoder 将 Encoder 的输出读进去。如何开始呢?给一个特殊的符号“BEGIN”。
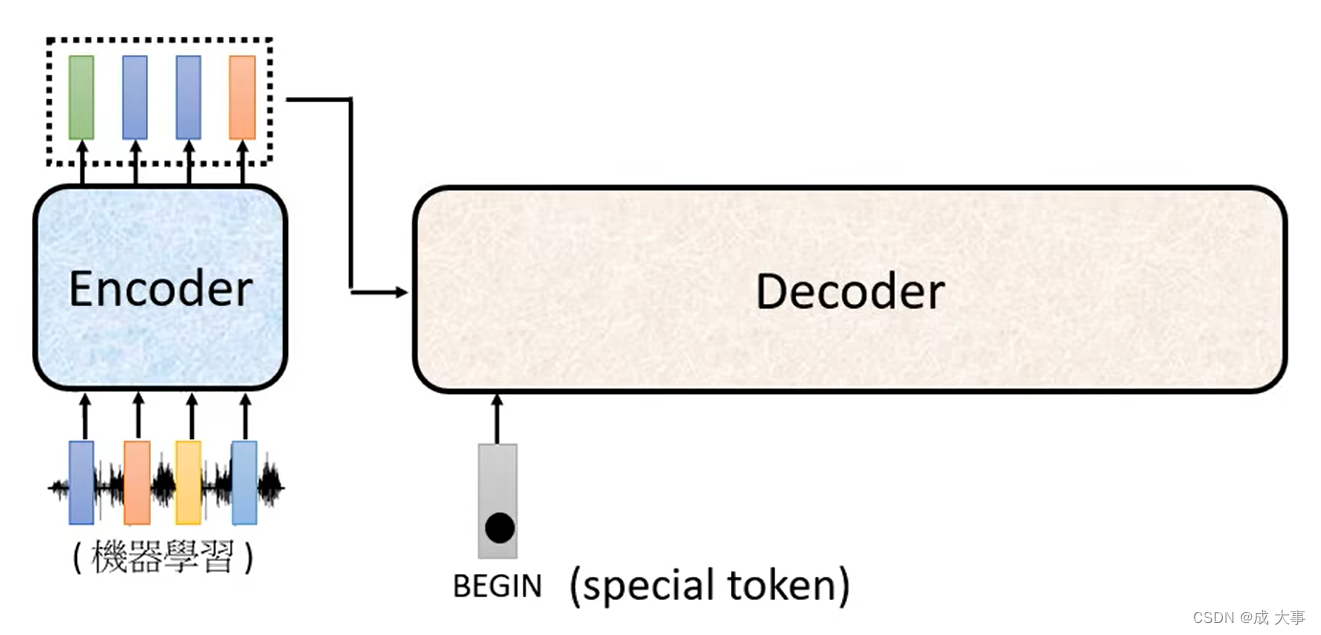
如果要处理NLP的问题,每一个token都可以把他用一个One-Hot的Vector(其中一维是1,其他都是0)来表示,所以begin也是用One-Hot Vector来表示。然后decoder吐出一个向量,这个vector的长度非常长,跟vocabulary的size是一样的。
Vocabulary:首先知道decoder输出的单位是什么?
假设是中文的语音辨识,那这里vocabulary的size可能就是中文的方块字的数目。
要是英文的话,用字母数量太少,用单词数量又太多,所以可以用Subword当作英文的单位,即单词的字首字根的组合,数量适中。

因为在产生输出向量之前,通常会跑出一个Softmax,就跟做分类一样,做分类得到最终的输出前通常会跑一个Softmax, 所以这一个向量里面的分数,它是一个Distrubution,也就是向量对应的值总和为1。
然后输出的向量中的每一个中文的字都会对应一个数值,数值最高的那一个中文字就是最终的输出。
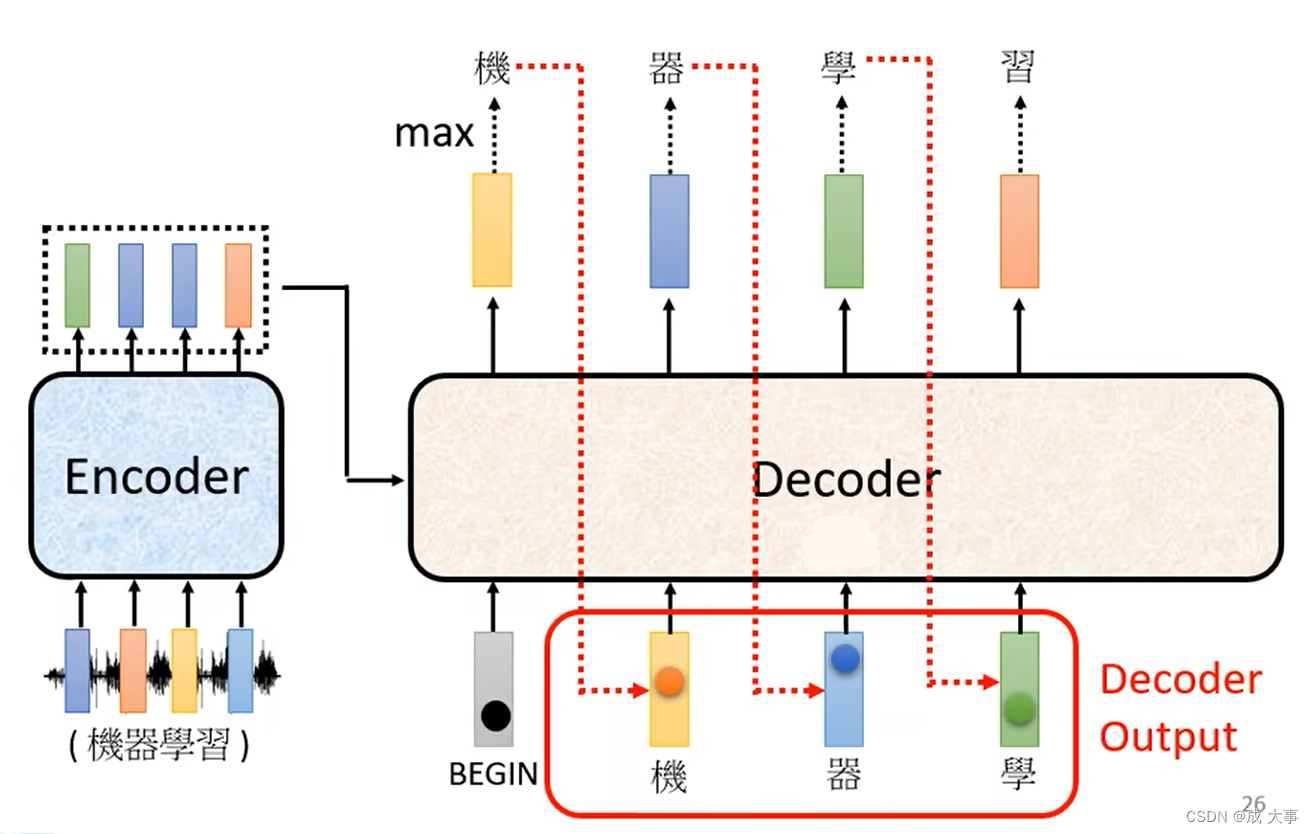
Decoder将自己的输出作为产生下一个字符的输入,所以,如果上一个输出错误,也会影响下一步的预测;
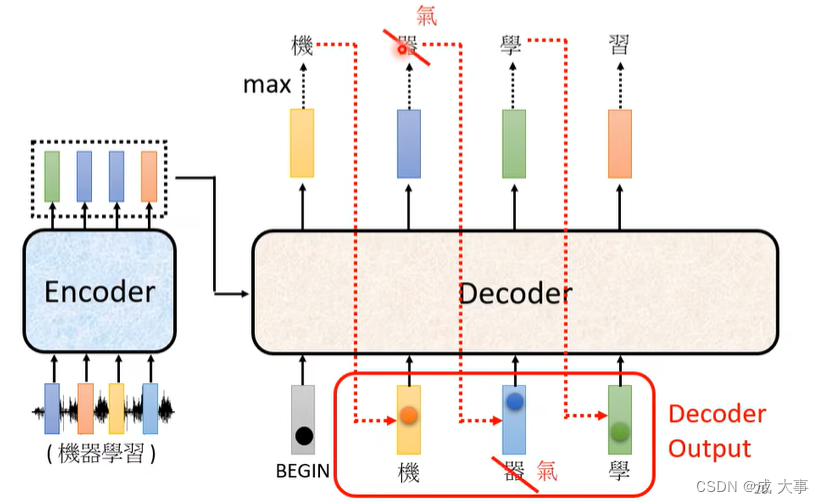
输出是一个个产生的,串行,只能考虑左边的。
拥有begin和end标志。
Transformer’s Decoder
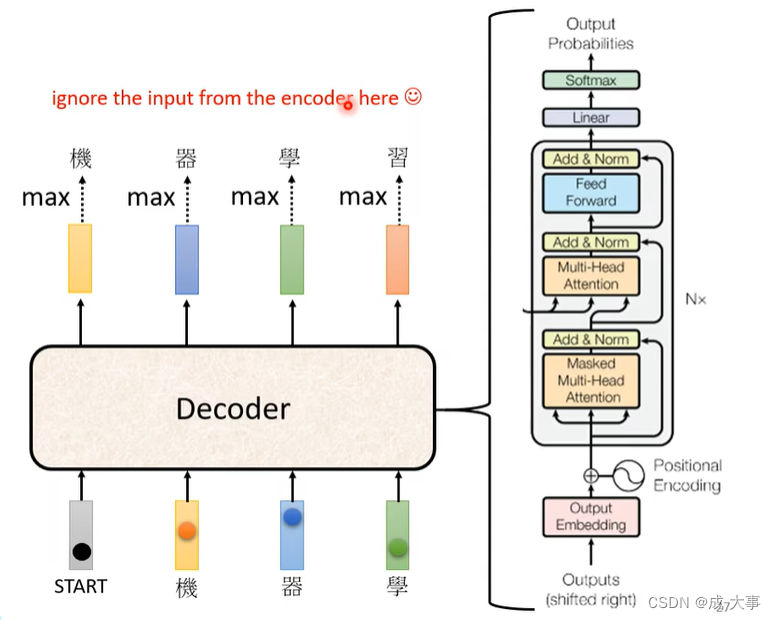
Transformer’s Encoder Vs Transformer’s Decoder
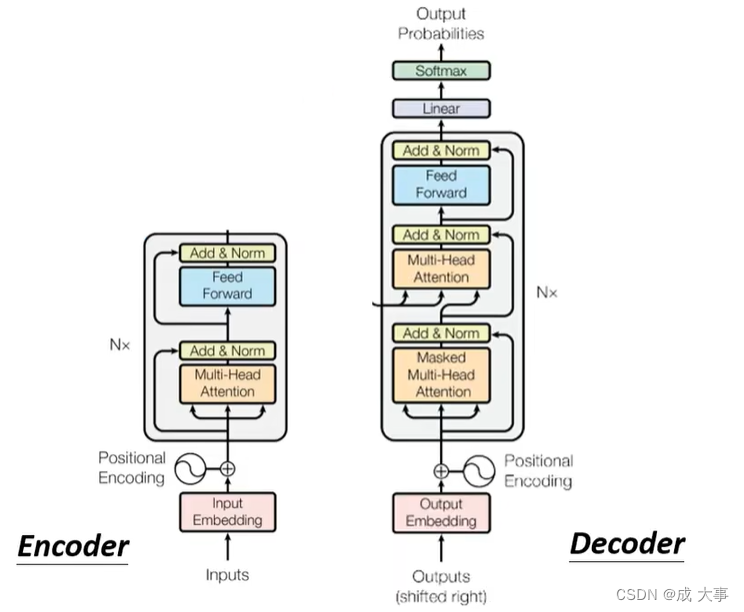
Decoder遮住中间一部分后,Encoder和Decoder没有太大差别。
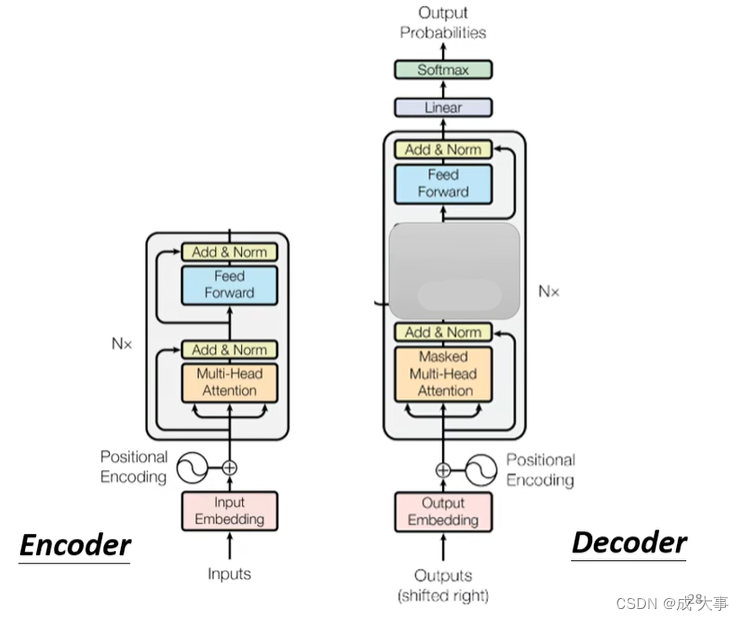
Decoder相比Encoder不同点:
masked self-attention vs self-attention
self-attention考虑全部的输入

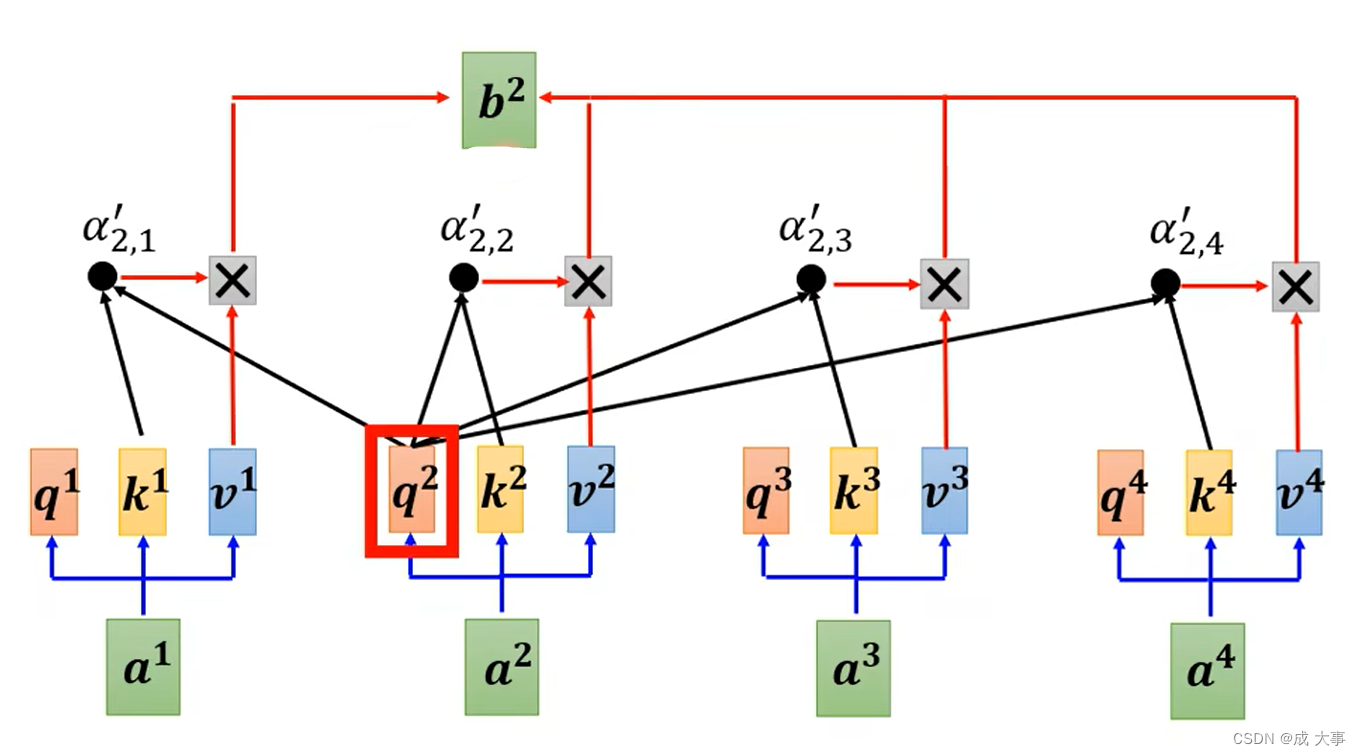
self-attention,如上图,输入一排vector,输出一排vector,这个vector的每一个输出都要看过完整的input之后才做决定,其实输出b1的时候其实是根据a1~a4所有的资讯去输出b1。
masked self-attention:只考虑左边的输入
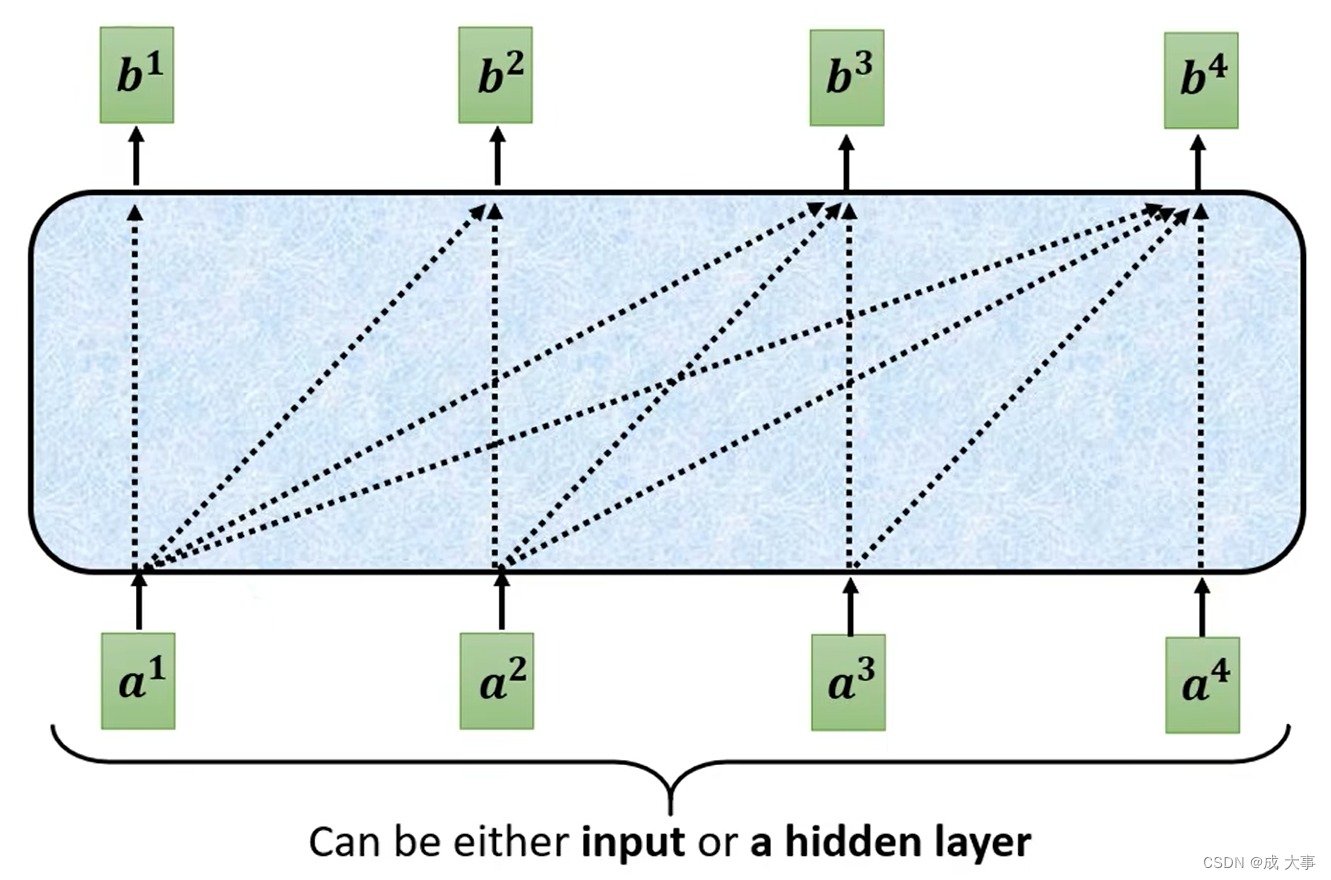

masked self-attention 如上图,当self-attention转成Masked Attention的时候,他的不同点是,不能再看右边的部分,也就是产生b1的时候只能考虑a1的资讯,不能去看a2、a3、a4,产生b2的时候只能考虑a1、a2的资讯,不能考虑a3、a4的资讯,后面类似,最后产生b4时可以考虑a1~a4所有的资讯。这就是Masked的self-attention。

一开始decoder的运作方式它是一个一个输出的,是先有a1,再有a2,然后是a3、a4,所以当计算b2时是没有a3和a4的,所以没办法将后面的考虑进来。
这跟原来的Self-Attention不一样,原来的Self-Attention中a1到a4是一次整个输入到Model里面的。
Decoder如何决定输出的Sequence的长度(何时停下来)?- “end”
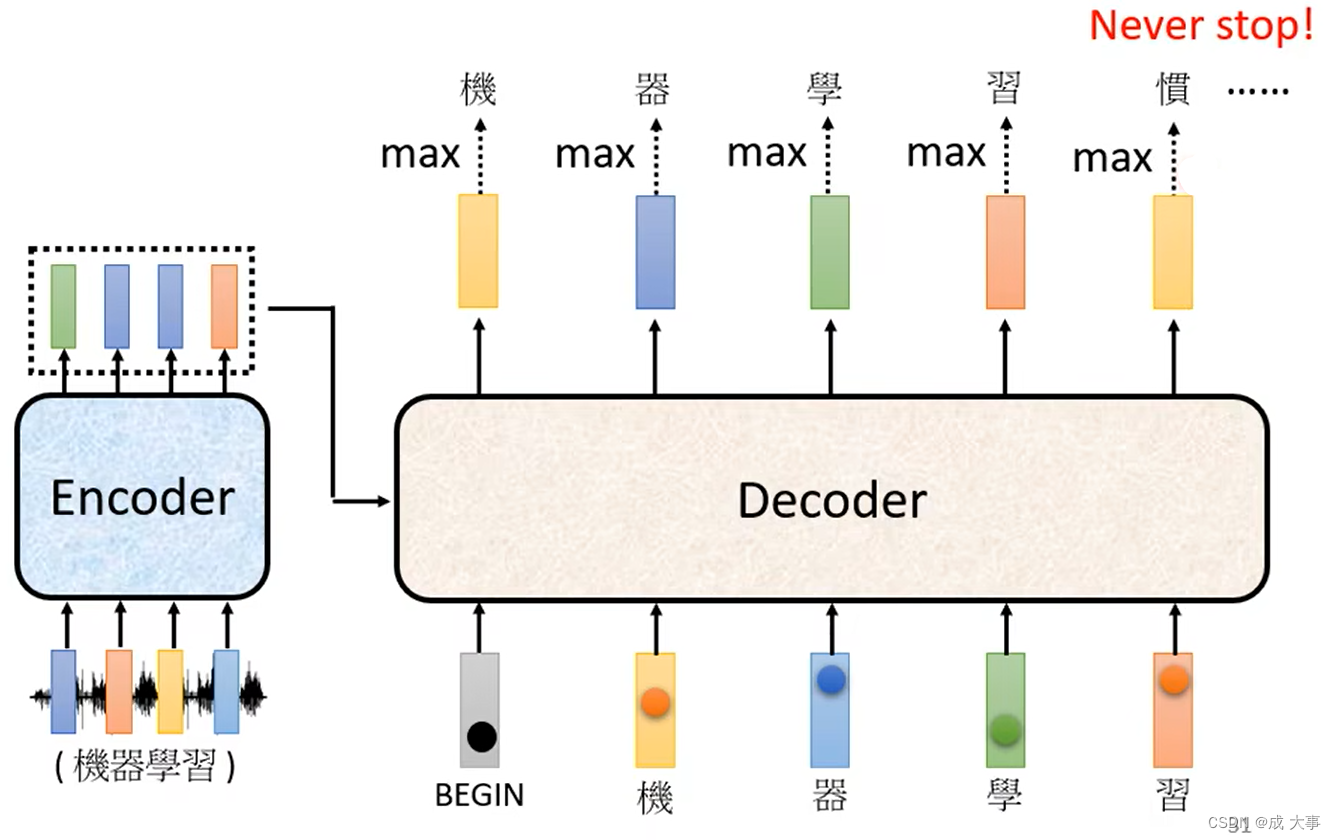
关键问题:Decoder自己决定输出的长度,但是到底输出的sequence的长度应该是多少呢?也就是机器如何决定该何时停下来。我们没办法决定,因为输出多少是非常复杂的,我们期望机器可以自己学到。
如下图,准备一个特别的符号“断”,用end来表示这个特别的符号,其实begin和end可以用同一个符号,因为begin只在开始时会出现一次。
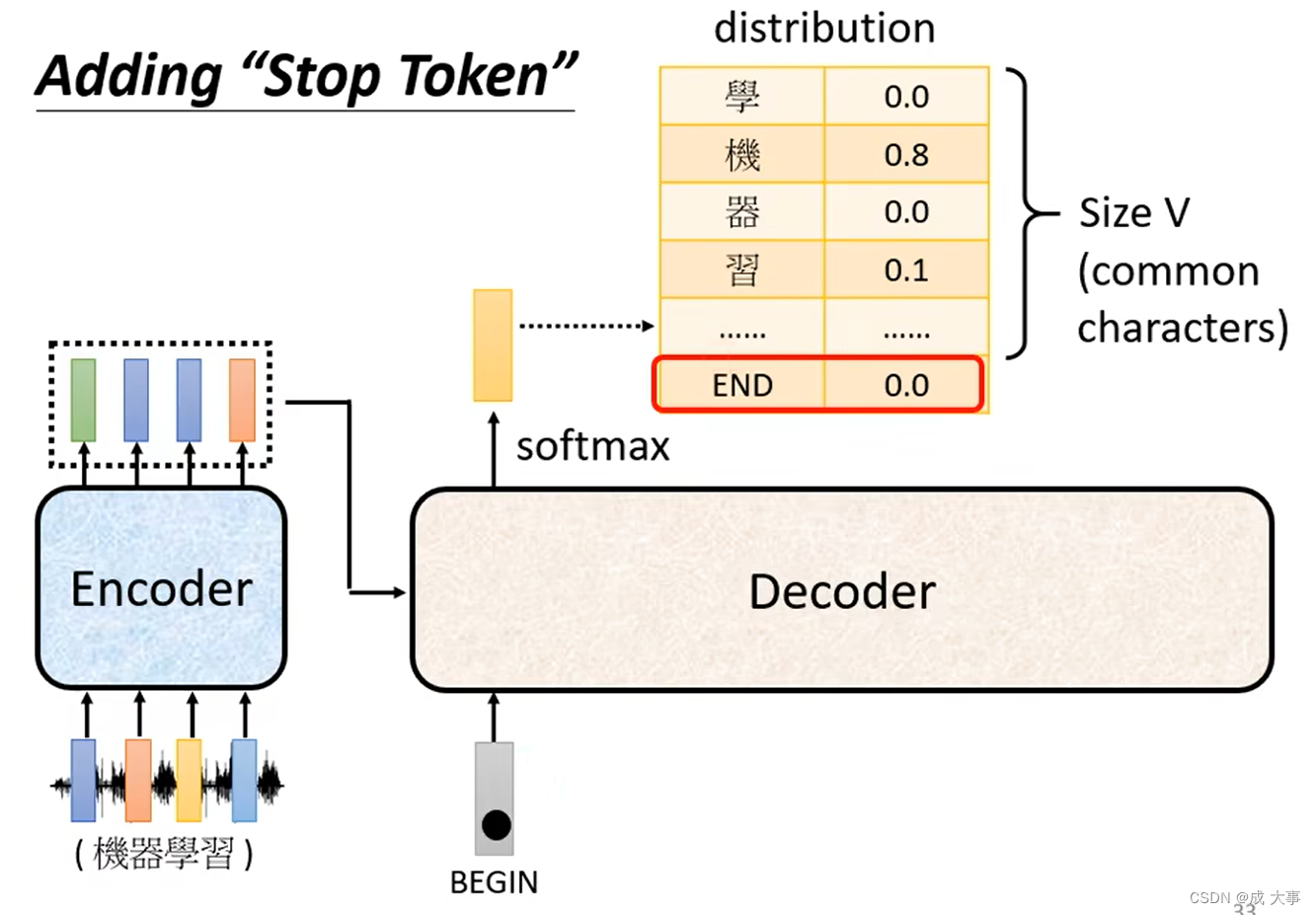
机器要自己知道在将自己的输出“习”再次当作输入时,要能够判断出现在应该输出end。

Non-autoregressive(NAT)
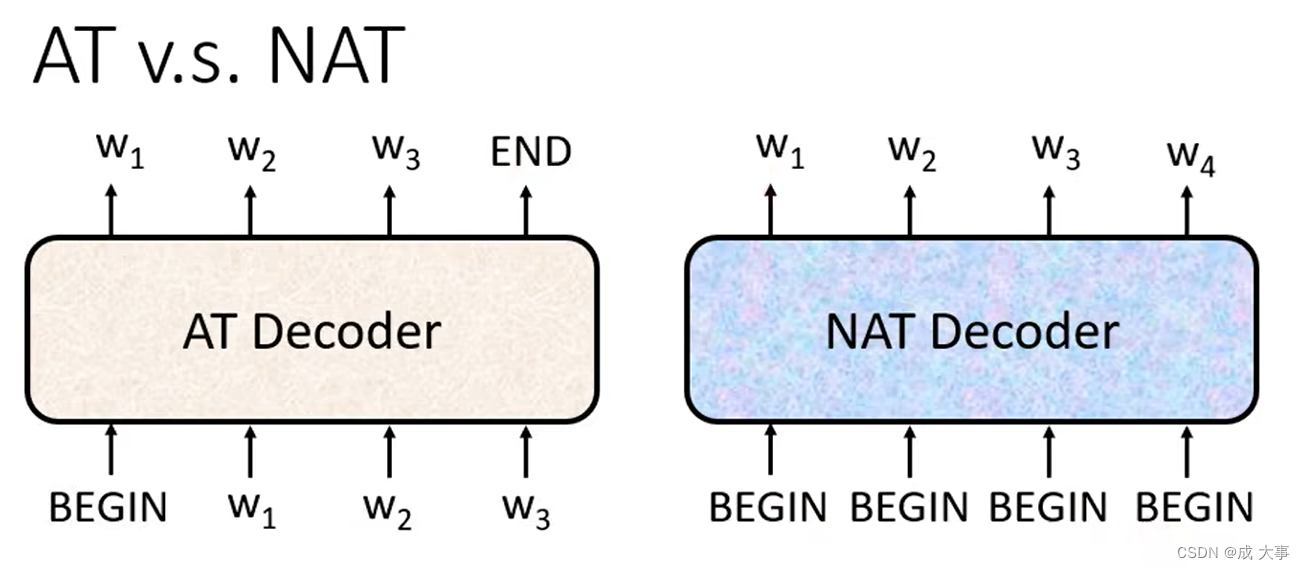
AT是输入一个begin,输出一个字符,将该字符作为后续的输入,输入一个输出一个,依次产生字符。
NAT是一次性输入全部的begin,然后输出全部的字符。只需一个步骤即可完成句子的生成。
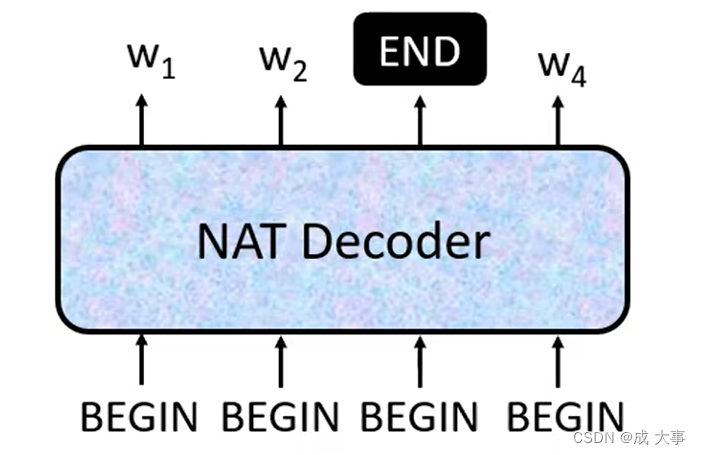
NAT Decoder 如何决定输出的Sequence的长度(Begin个数)?
方法一:classifier
另外取一个classifier,将encoder的input作为classifier的输入,classifier输出一个数字,该数字代表应该要输出的长度。
方法二:大于输出上限的begin个数
输入一堆begin的token,也就是大于输出上限值数量的输入,所以输出一堆的字符,忽略end后面的只取前面的字符。
NAT优点
(1)平行化(parallel):AT输出时是一个一个产生的,所以要输出100个字的句子,就要做一百次的decoder。但是NAT的decoder不管句子的长度如何,都是一个步骤就产生出完整的句子。速度上NAT的decoder会跑的比AT快。
(2)可以控制输出的长度(controllable output length)。例如语音合成时,如果想要系统讲话快一点,就可以把classfier的output除以二,讲话的速度就会变成二倍速。同理,放慢速度就将输出的长度乘以二。
这个NAT Decoder的想法是在有transformer和self-Attention的decoder以后才有的,因为以前如果用那个LSTM、RNN的话,就算给他一排Begin,也没有办法同时产生全部的输出,所以说在没有self-Attention,只有RNN、LSTM的时候,根本就不会有人想要做什么NAT的decoder。
NAT Decoder 通常比 AT Decoder 的表现差。
为什么 NAT Decoder 通常比 AT Decoder 的表现差?
NAT(Non-Autoregressive Transformer)解码器和AT(Autoregressive Transformer)之间的性能差异主要与它们的生成方式和特点有关。
-
生成方式不同:AT解码器是自回归的,即在生成每个输出时,它依赖于之前已生成的所有输出。而NAT解码器是非自回归的,它可以并行生成所有输出,无需等待先前的输出。这种并行生成的特性使得NAT解码器在生成速度上具有优势,因为不需要等待前一个标记生成完毕。
-
信息缺失:由于AT解码器的自回归性质,它可以利用已生成的标记来指导下一个标记的生成过程。这种依赖关系使得AT解码器在每个时间步能够捕捉到更多的上下文信息,有利于生成准确的输出。而NAT解码器在并行生成时,无法利用后续生成标记的信息,可能会导致信息缺失和错误的累积。
-
错误传播:由于NAT解码器的并行生成特性,一个生成错误的标记可能会影响后续标记的生成,导致错误的累积。这是因为NAT解码器无法在生成过程中进行修正。而AT解码器在生成每个标记时都可以进行修正和调整,减少了错误的传播。
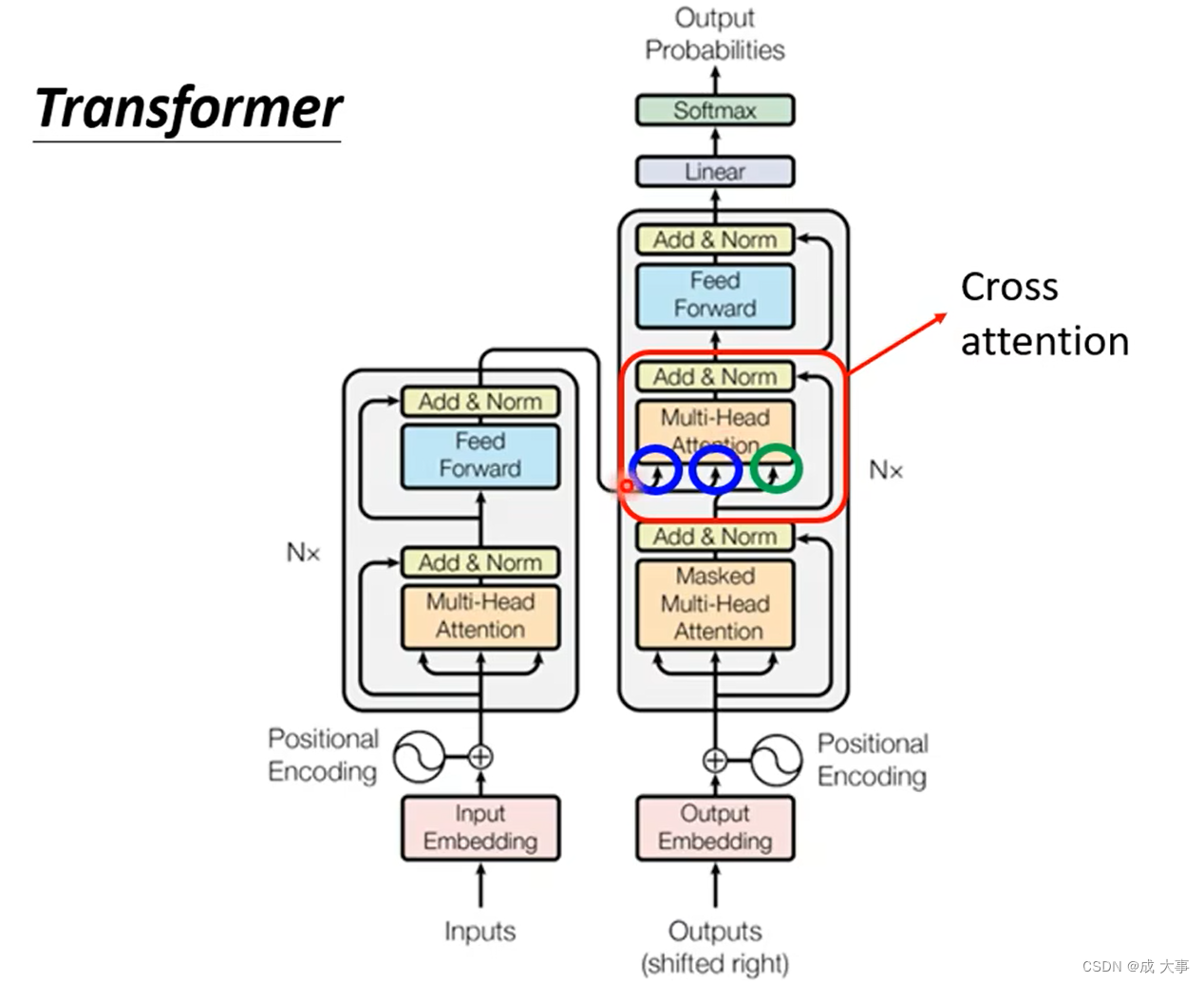
Encoder与Decoder间如何传递信息?- Cross Attention
Cross attention,它是连接Encoder跟Decoder之间的桥梁,从图中可以看出,这个模块的输入部分,有两个箭头来自encoder,一个来自decoder。
Cross attention 原理
Cross Attention 出现在 Transformer 之前,且 Cross Attention 出现之后才出现了 self-attention。
Cross attention:用Encoder产生的所有的K、V和decoder中的Mask self-attention产生的q分别再做attention计算。
模块Cross attention实际运作过程:
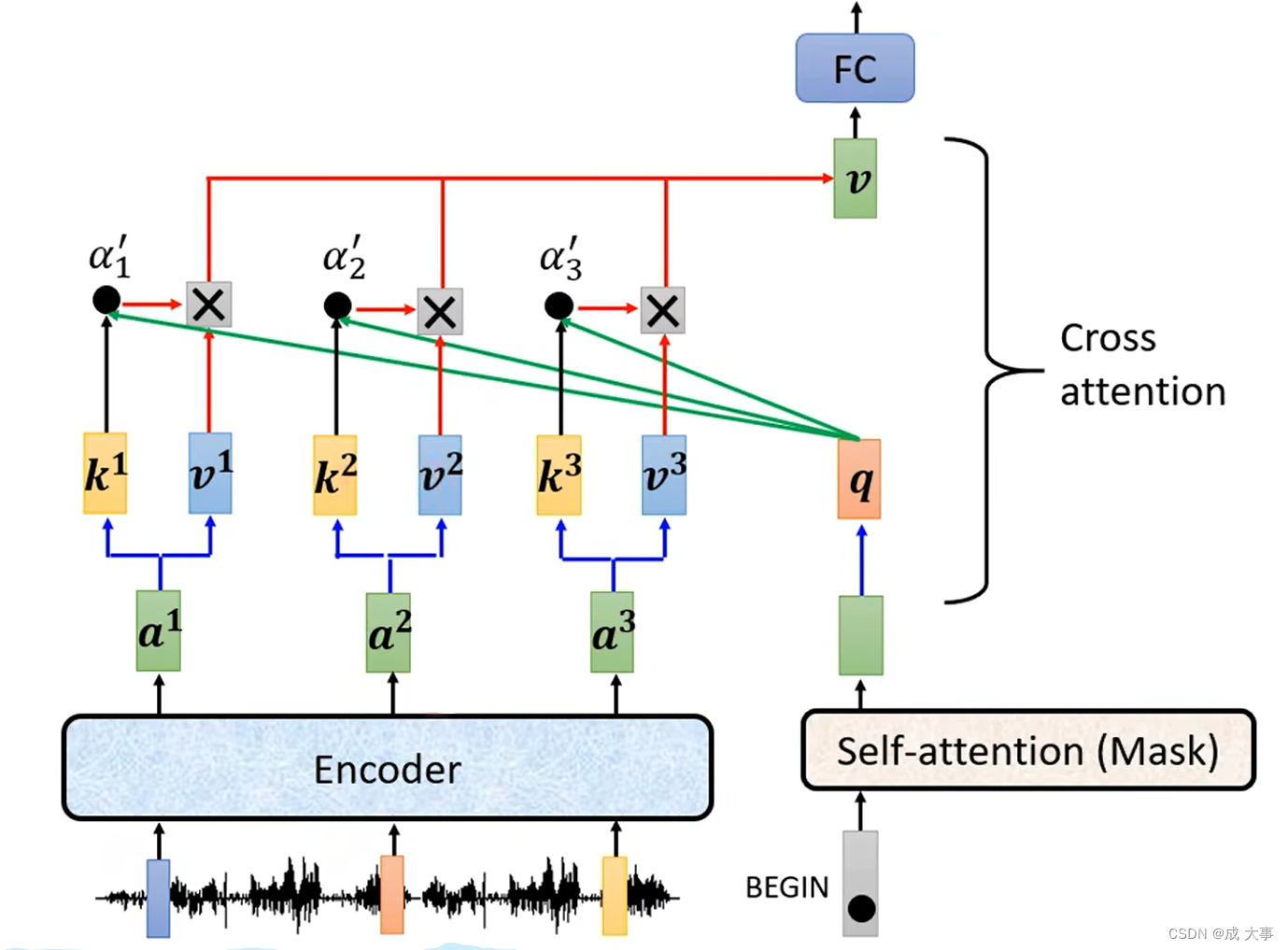
如上图,decoder就是产生一个q,去encoder那边抽取资讯出来当作接下来decoder里面的Fully-Connected 的Network的Input。具体来说就是,q和 k 1 , k 2 , k 3 k^1,k^2,k^3 k1,k2,k3去计算分数,然后在和 v 1 , v 2 , v 3 v^1,v^2,v^3 v1,v2,v3做Weighted Sum做加权,加起来得到v,然后交给Fully-Connected处理。
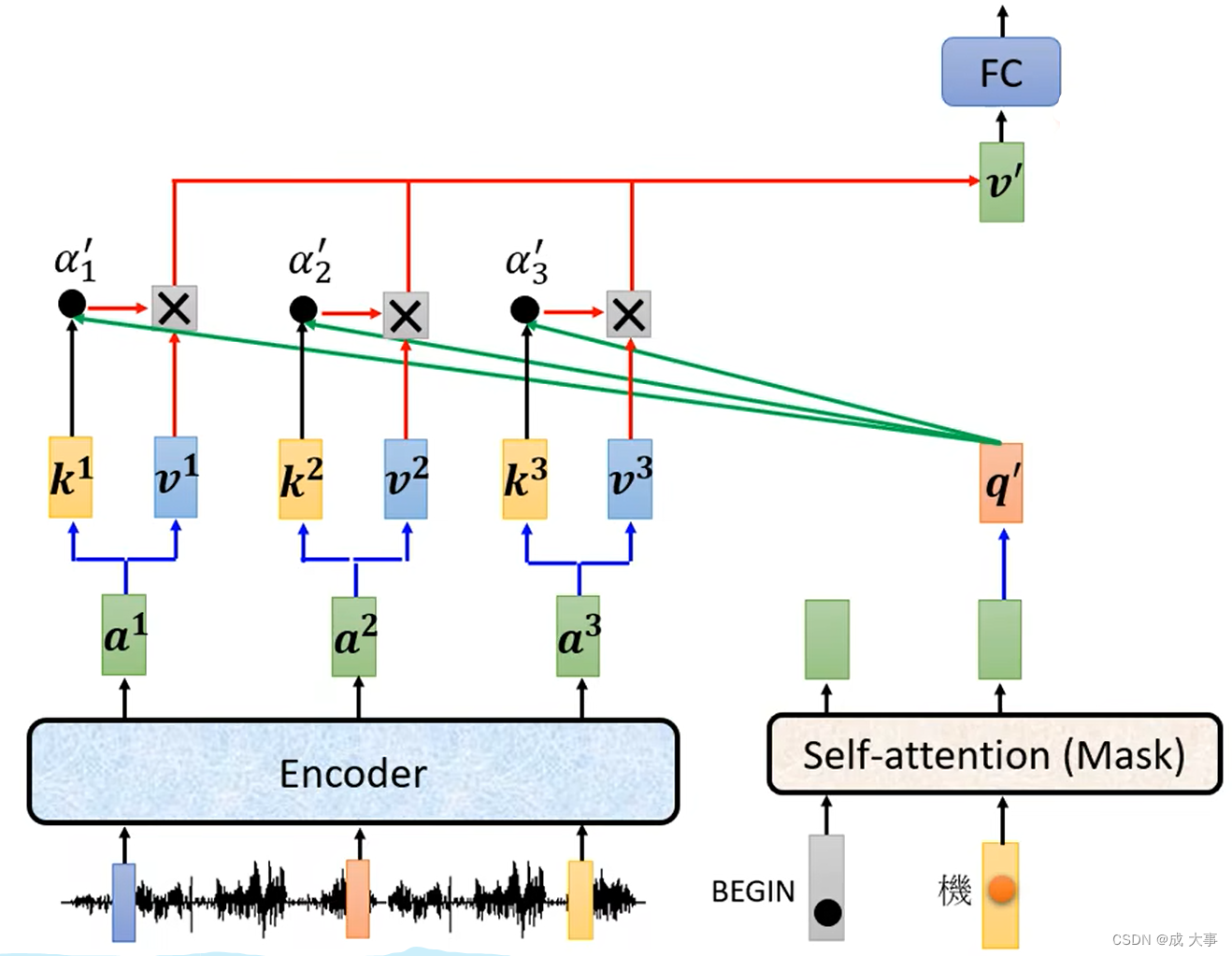
然后持续这个步骤。
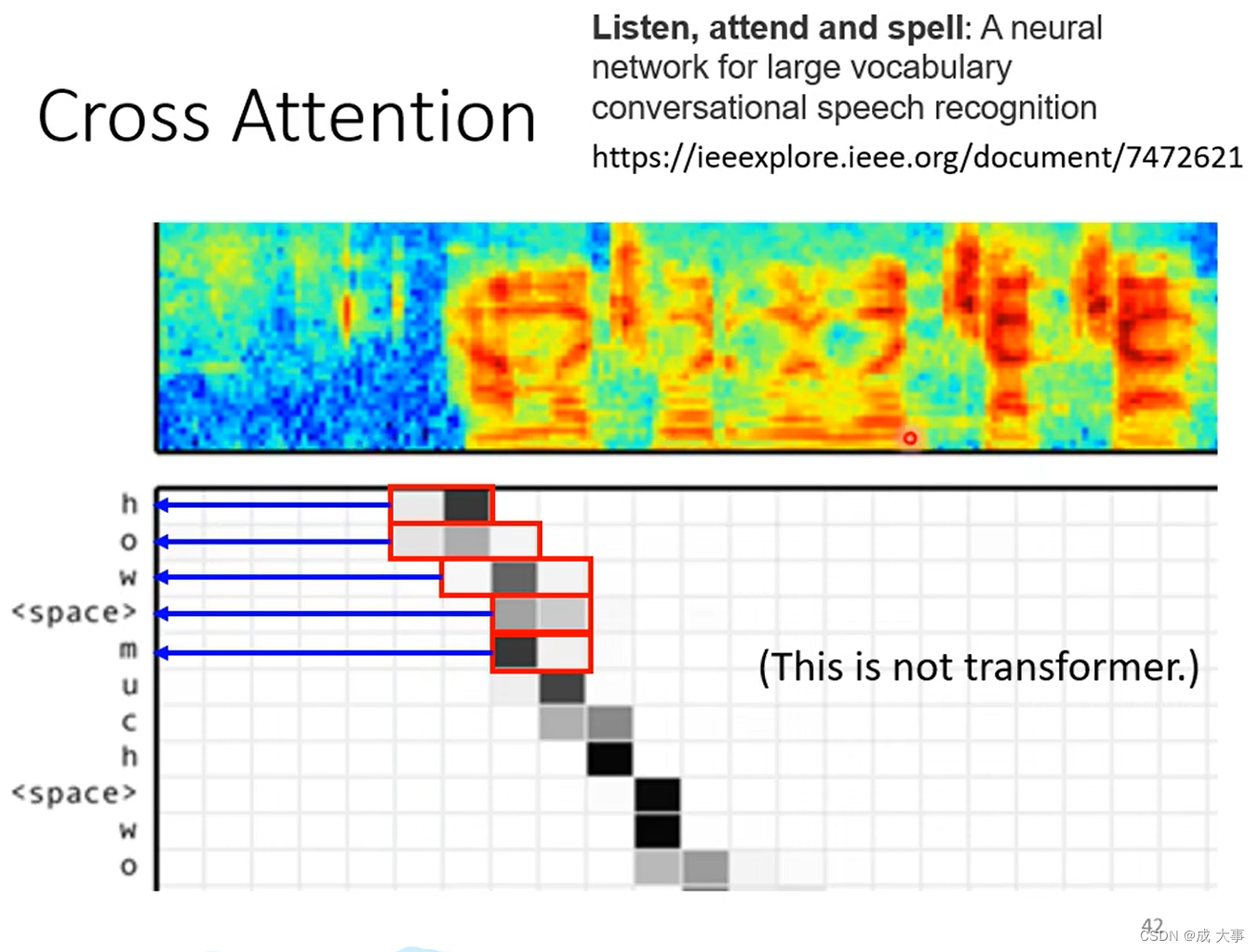
Cross attention 效果展示
该效果分析,并不是来自Transformer论文,而是出自论文 Listen, attend and spell: A neural network for large vocabulary conversational speech recognition。
该论文作者在斯坦福大学做了论文介绍。链接
该论文中的模型没有赢过当时最好的语音辨识系统,但是只差一点,该论文证明了Seq2Seq应用在语音辨识系统中似乎是有潜力的。
Cross Attention 出现在 Transformer 之前,且 Cross Attention 出现之后才出现了 self-attention。
原始论文中,所有Decoder层都是取最后一个Encoder层的输出。但是,并不是一定要这样设计,关于Decoder层如何取Encoder层的输出,可以有不同的设计。

Training
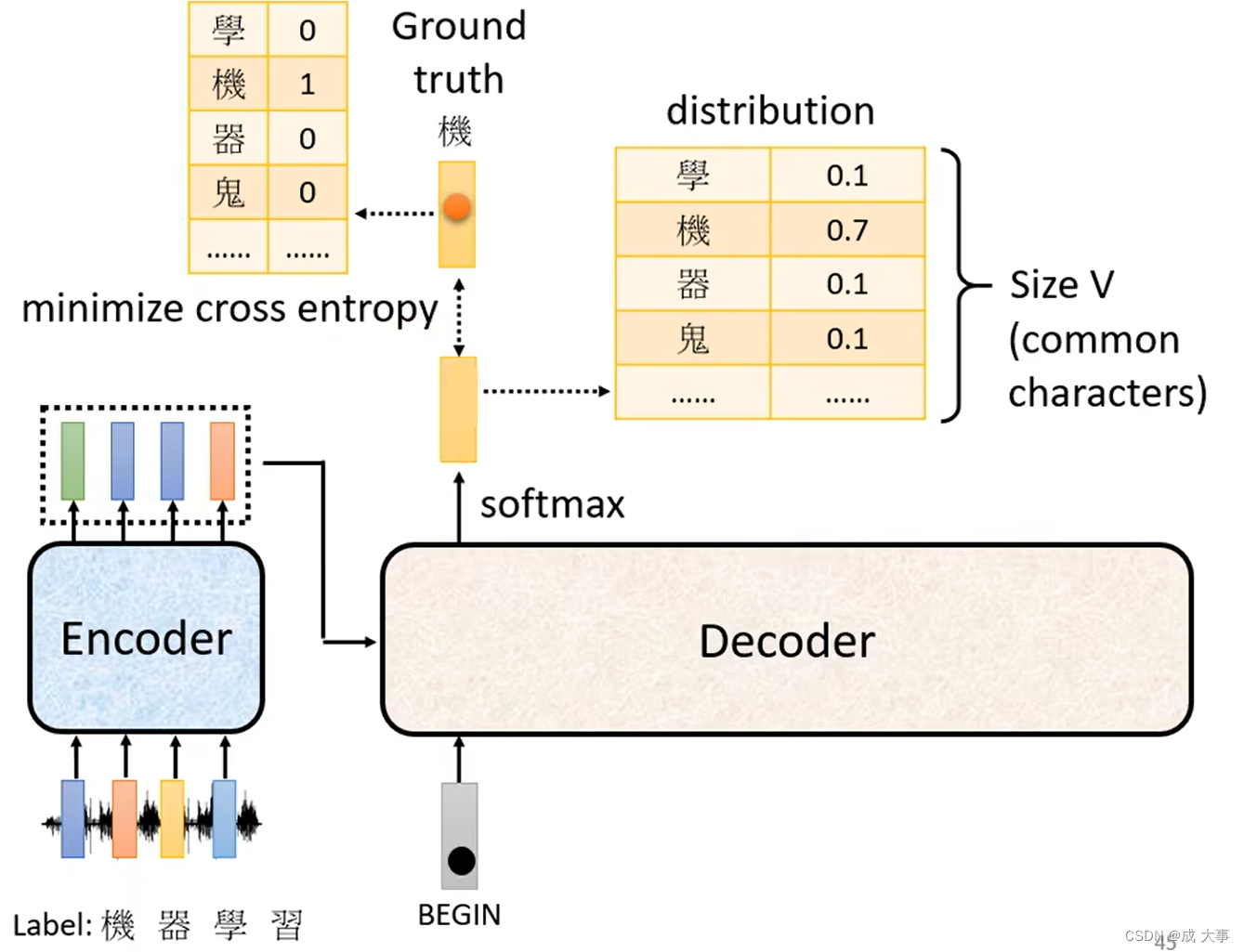
如上图,输入一段声音讯号,第一个而应该要输出的中文字是“机”,所以当把begin丢给decoder的时候,它的第一个输出要跟“机”越接近越好,即“机”这个字会被表示成一个One-Hot的Vector,在这个vector里面只有“机”对应的那个维度为1,而decoder的输出是一个Distribution是一个几率的分布,我们希望这个几率的分布跟One-Hot的Vector越接近越好。所以去计算Ground truth和distribution之间的Cross Entropy,希望这个Cross Entropy的值越小越好。
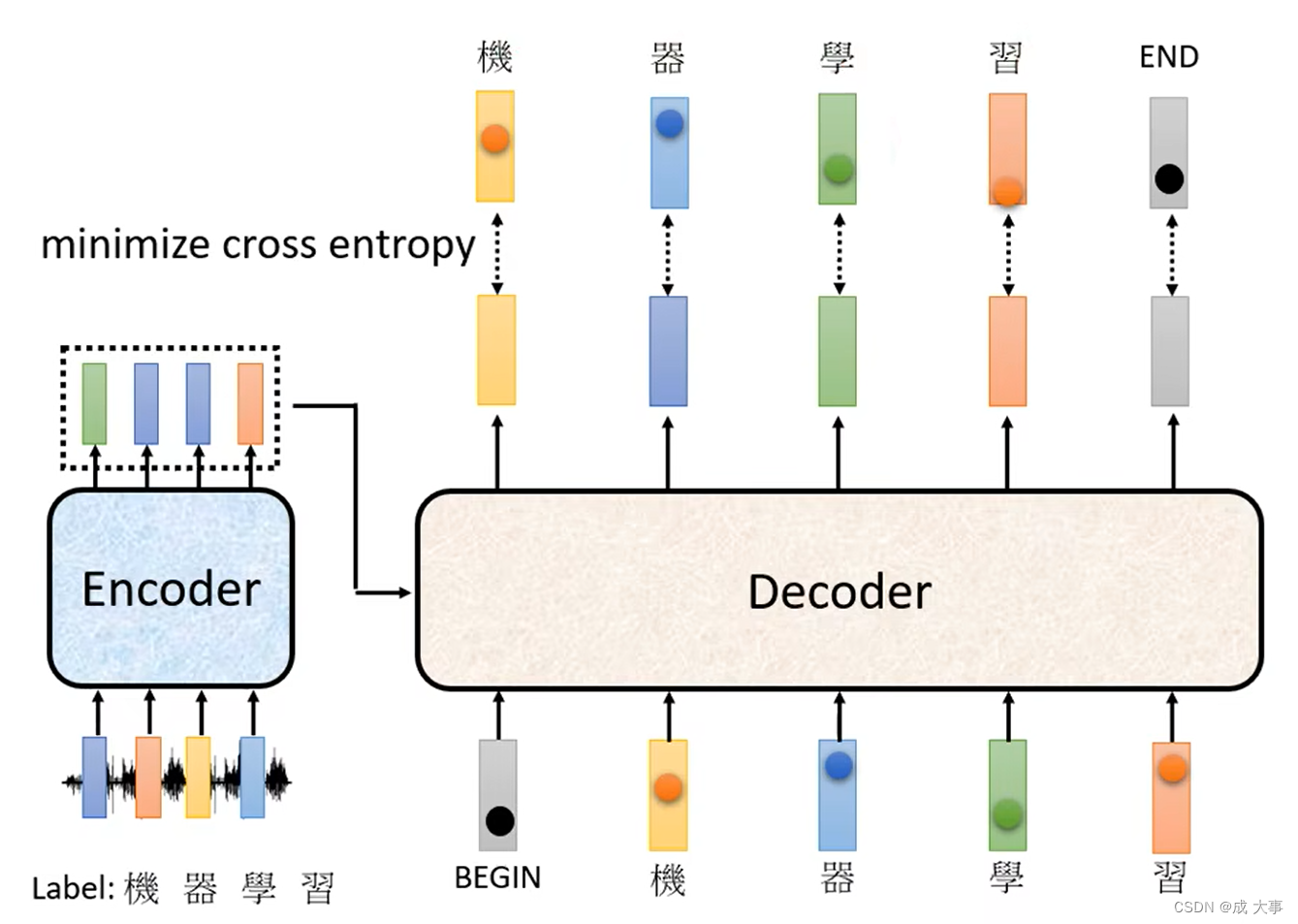
首先,已经知道输出应该是“机器学习”这四个字,然后告诉decoder它的正确输出应该是“机器学习”这四个中文字的One-Hot Vector,我们希望输出跟这四个字的One-Hot Vector越接近越好,在训练的时候每一个输出都会有一个Cross Entropy,每一个输出跟One-Hot Vector 跟他对应的正确答案都有一个Cross Entropy,最后希望所有的Cross Entropy的总和最小。
现在还有end的问题,机器要输出的不只是四个字,还有一个end,所以要让机器知道输出四个字以后,还要记着输出“断”。所以应该告诉decoder第五个位置的输出应该跟断的One-Hot Vector它的Cross Entropy越小越好。这个就是Decoder的训练。
Teacher forcing:训练时给正确的答案 Ground Truth 作为Decoder的输入。
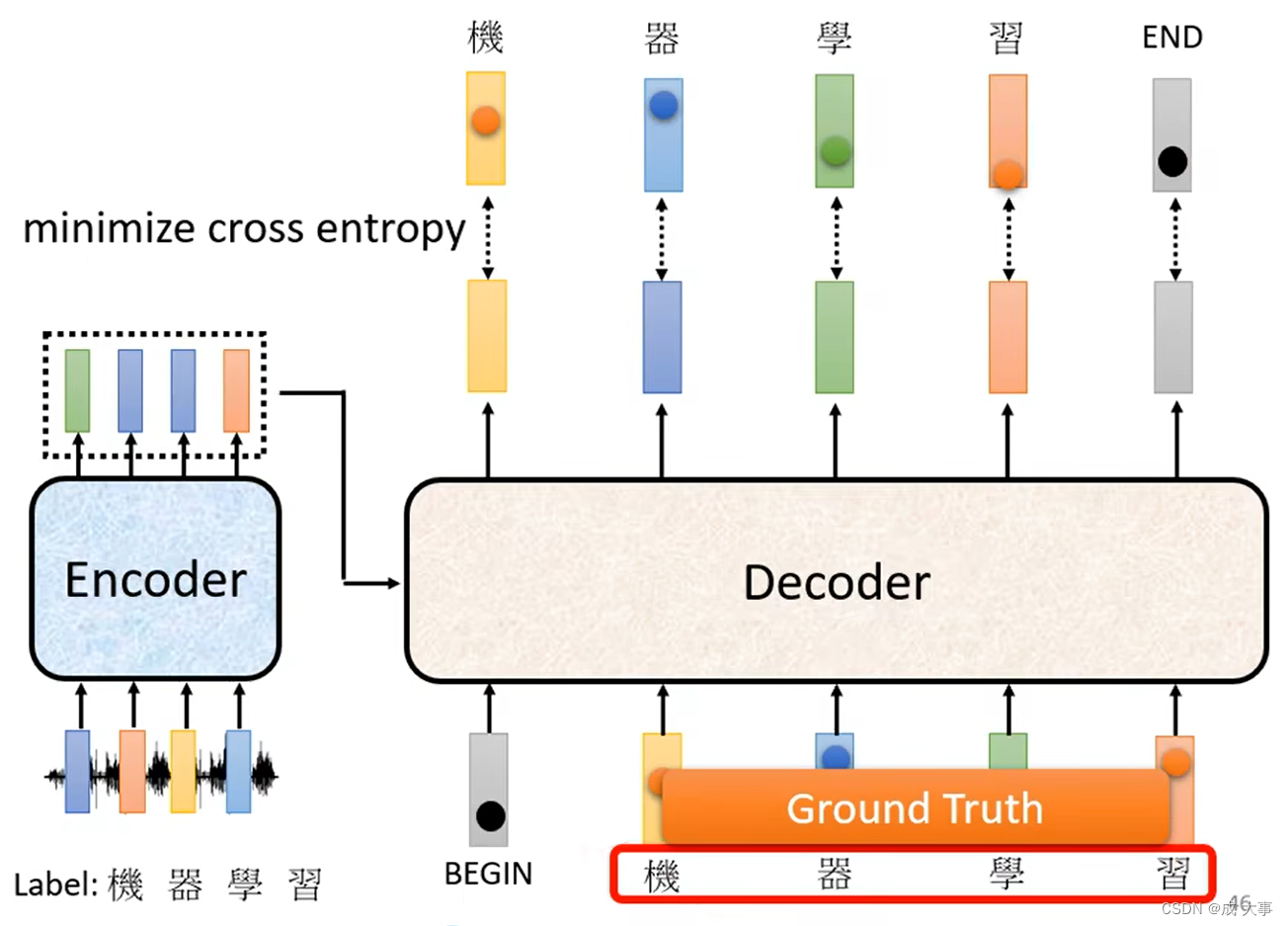
这个训练会产生一个问题:训练的时候decoder会得到正确的答案作为输入,但是testing时没有正确答案,这中间显然会有一个Mismatch。
[待补充:如何解决这个Mismatch?]
Tips(训练Seq2Seq模型)
Copy Mechanism
Copy Mechanism,有些信息可以从输入的信息中复制过来,不需要机器生成(例:从文章中复制重要信息训练生成摘要)。
聊天机器人: 比如输入“你好,我是库洛洛”,但是“库洛洛”可能在机器的训练过程中一次都没有出现过。但是机器可以直接复制过来,回复“库洛洛你好,很高兴认识你”。

文章总结:
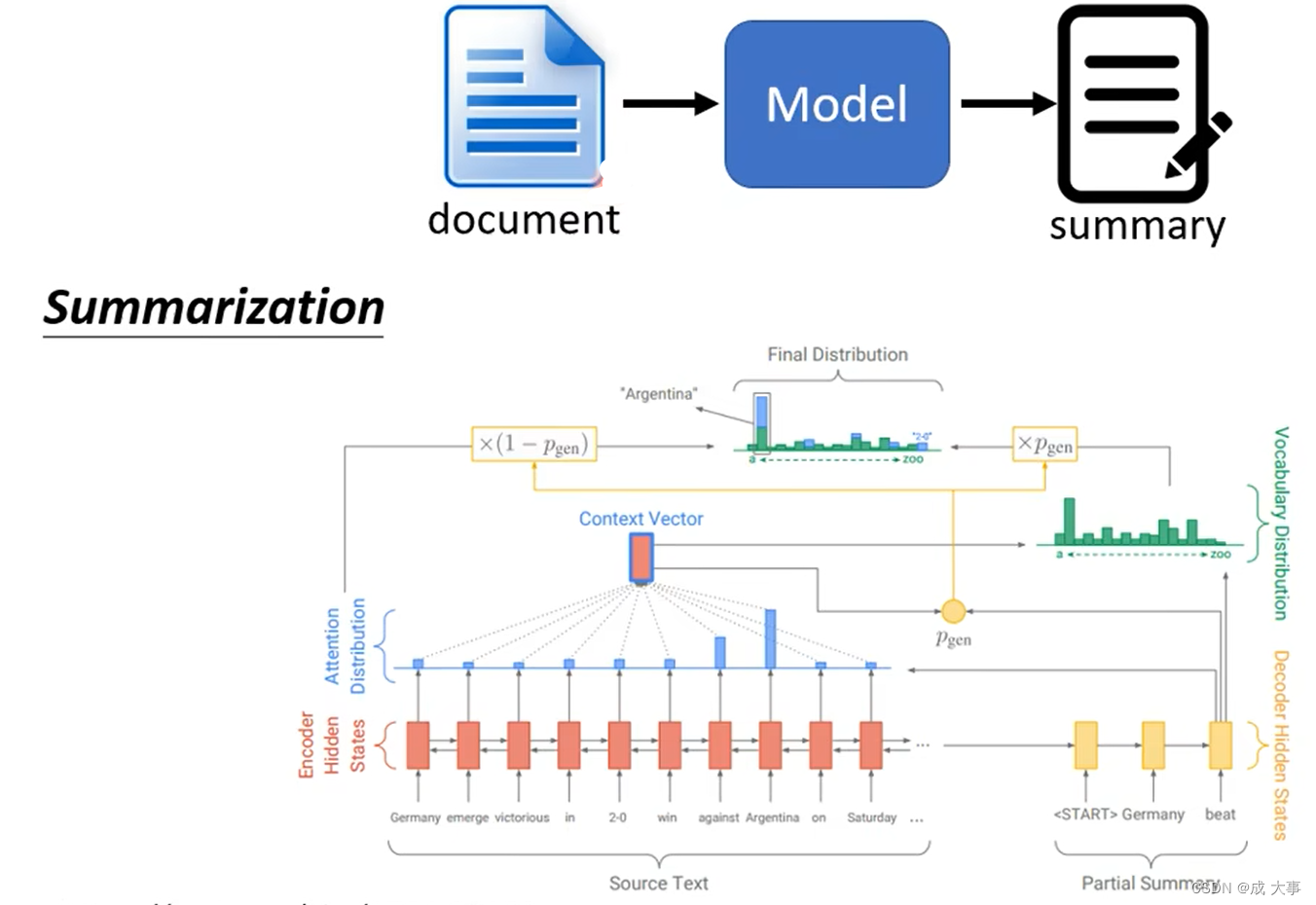
Get To The Point: Summarization with Pointer-Generator Networks
Seq2Seq模型有能力做到上述功能(从输入中复制一部分信息到输出信息中),例如:Pointer Network。

还有变形Copying network :Incorporating Copying Mechanism in Sequence-to-Sequence Learning
Guided Attention
机器学习可以看做是一个黑盒子,存在发生错误的可能性,例如:语音生成任务(将中文转化为语音)中,读4个发财、3个发财、2个发财都没有问题,但是1个发财时,机器只读“财”没有读“发”,机器漏字。

机器发生错误的情况,可以使用Guided Attention技术进行修正。
Guided Attention:强制机器看完全部的输入。要求机器去领导这个Attention的过程,要求机器做attention的时候是有固定的方式的,就是让机器以固定的attention模式学习。
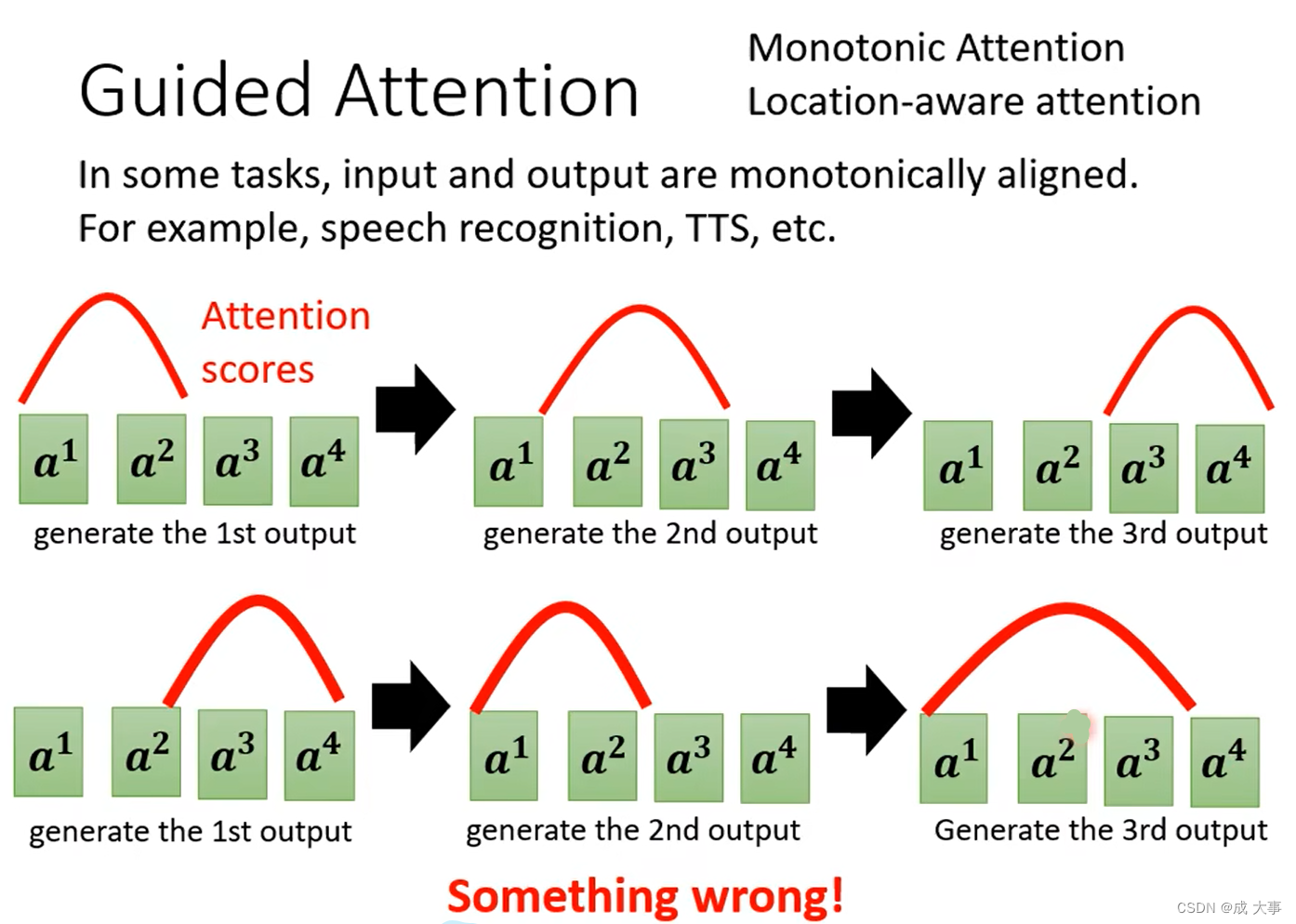
对于语音合成或者语音辨识来说,我们想象中的Attention应该是由左往右的,上图中红色曲线代表Attention的分数,若是语音合成的话,应该先看最左边输入的词去产生声音,再根据中间的词汇去产生声音,最后看右边的词汇产生声音。
但是当你做语音合成时发现机器的读取顺序是颠三倒四的,显然是错的,无法合成出好的结果。而Guided Attention在这里要做的事情就是强迫Attention有一个固定的样貌,将这个必须从左到右的限制放到training里面,要求机器学到Attention就应该从左到右。
有哪些框架可以实现Guided Attention?
Monotonic Attention
Location-aware Attention
Beam Search
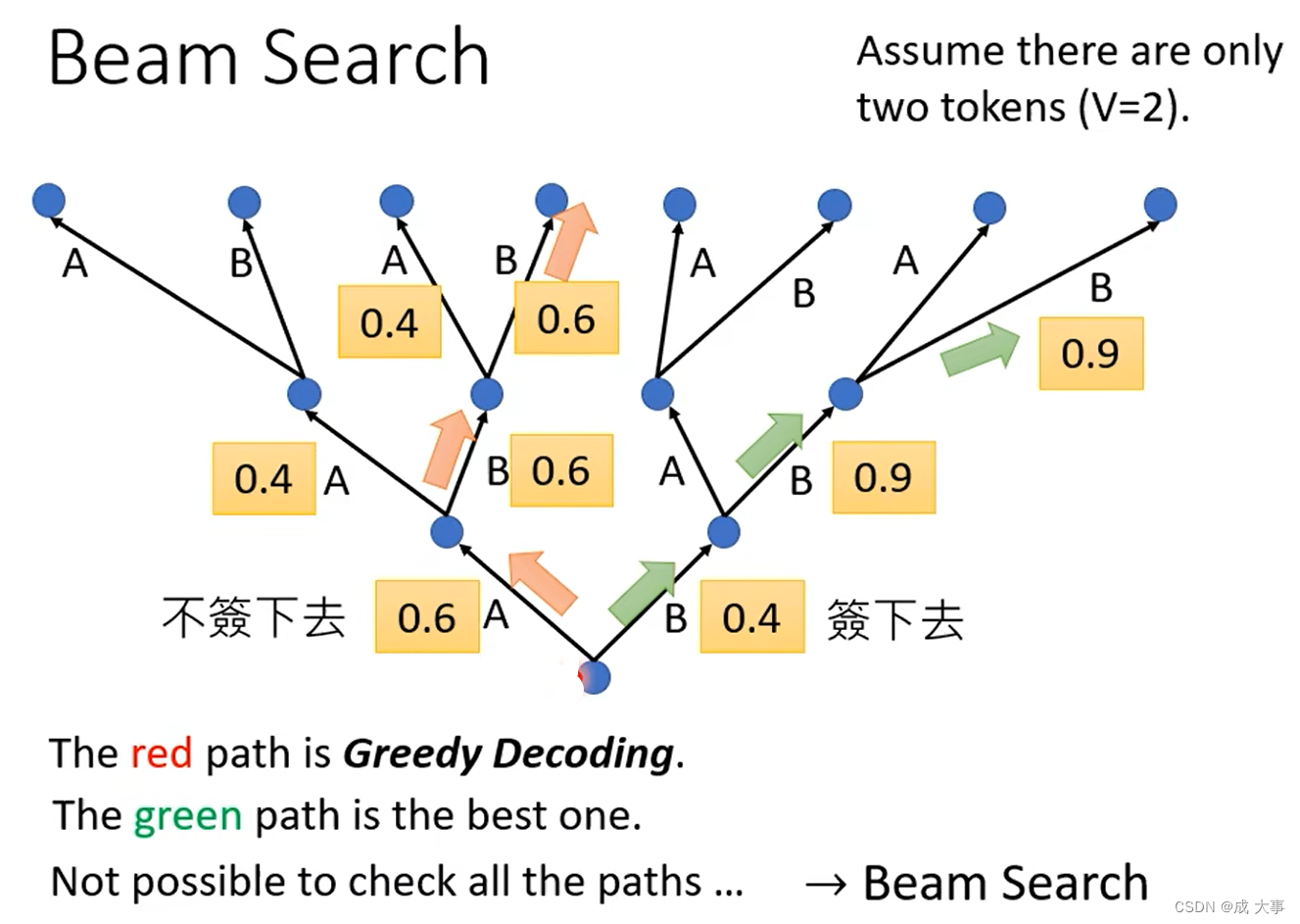
假设现在的decoder只能产生两个字,只能产生两个可能的输出一个是A,另一个为B。那对decoder而言,他做的事情就是在每一次第一个Time Step,在A、B里面决定一个,假如决定A以后将A当作输入在决定A、B要选哪一个,依次向后进行。在这个过程中,每一次Decoder都是选分数最高的那一个,但是有时候刚开始选分数高的,后面还是有可能差下来,还有时候一开始选择分数低点的,后面反而会更好。
有的任务中,树的分支很多,不可能穷举所有路径找到最优路径,可以通过Beam Search这个技术来找一个approximate(不是完全精准的估测的solution)。
Beam Search 是寻找最优路径的一个比较好的方法(有时有用,有时没用,看任务本身,任务目标本事很明确,结果确定的比较有用;有时候decoder有一些随机性比较好,比如语音合成TTS)
现在对于Beam Search的评价有好有坏,在 Sentence complication 任务中,如果使用 Beam Search 会出现严重的问题,机器会不断的产生重复文字。当然了,要看具体的任务需求,若一个任务它的答案非常明确,例如语音识别,有唯一明确的答案,一段语音识别结果只有唯一明确的答案。通常Beam Search就会比较有帮助。如果任务需要机器发挥一点创造力的时候,任务答案不唯一,Beam Search的帮助就会很小,这种任务中需要加入随机性,例如语音合成TTS。

Optimizing Evaluation Metrics
接下来有另外一个问题,在作业里面我们用的评估标准是BLEU Score,它是decoder先产生一个完整的句子以后跟正确的答案一整句作比较。是拿两个句子之间作比较才算出BLEU Score。但是在训练时显然不是这样的,训练时每一个词汇是分开考虑的,且Minimize的是Cross Entropy。
为什么不拿两个句子进行比较而是两个字进行比较?
因为两个句子间算BLEU score没有办法做微分,在两个字间进行比较才有办法处理。
Minimize Cross Entropy一定可以Maximizes BLEU Score吗?
不一定,因为这两个仅仅有一点关联,没有那么的直接相关,他们根本就是两个不同的数值。
训练时一般用cross Entropy,而测试时用BLEU Score。
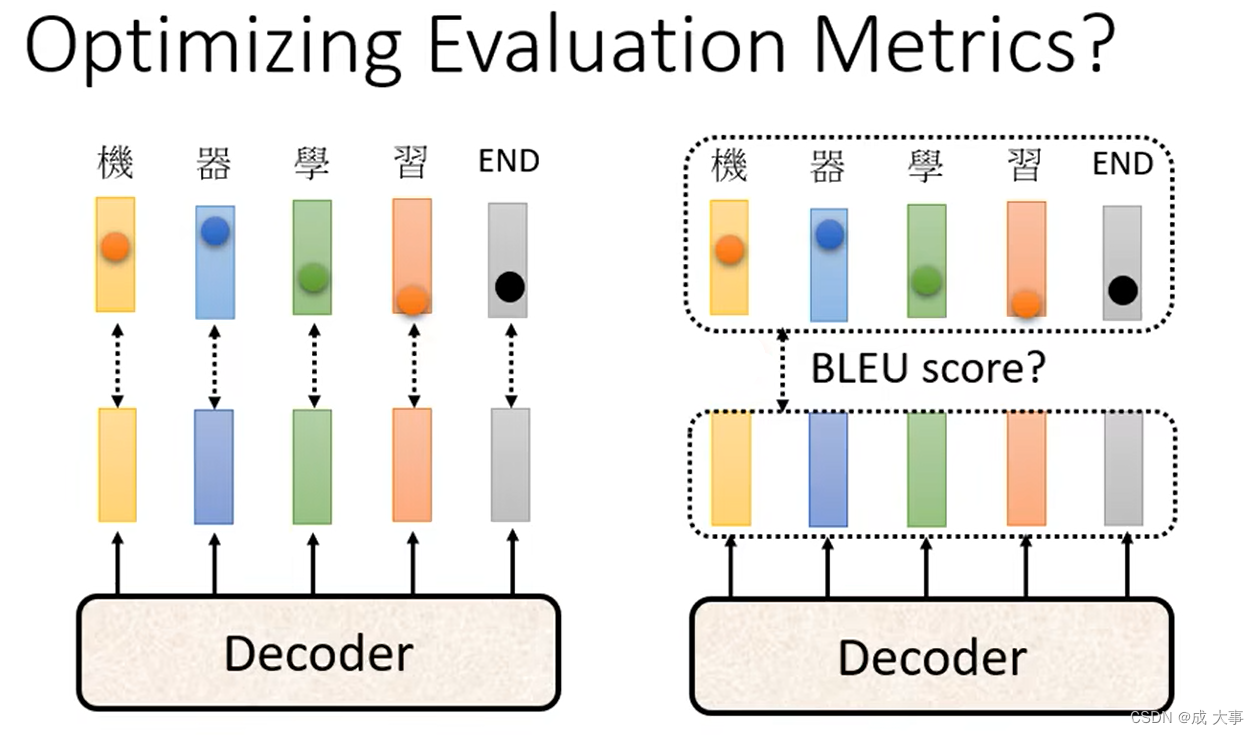
能不能在 Training 的时候,就考虑 BLEU Score ?
Loss = BLEU Score 乘一个负号,那要 Minimize 那个 Loss 也等於就是 Maximize BLEU Score。
但是这件事实际上没有那麼容易,当然可以把 BLEU Score,当做训练的时候要最大化的一个目标,但是 BLEU Score 本身很复杂,它是不能微分的,之所以采用 Cross Entropy,而且是每一个中文的字分开来算,就是因为这样才有办法处理,如果要计算两个句子之间的 BLEU Score,这一个 Loss根本没有办法做微分,那怎麼办呢?记住一个口诀,遇到 Optimization 无法解决的问题,用 RL 硬 Train 就对了,遇到无法 Optimize 的 Loss Function,把它当做是 RL 的 Reward,把 Decoder 当做是 Agent,它当作是 RL, Reinforcement Learning 的问题硬做。
其实也是有可能可以做的,有人真的这样试过,当然这是一个比较难的做法,并没有特别推荐你在作业里面用这一招。论文:Sequence Level Training with Recurrent Neural Networks
Exposure Bias
训练跟测试居然是不一致的,测试的时候decoder看到的时自己的输出,所以它会看到一些错误的东西,但是在训练的时候decoder看考的是完全正确的,这个不一致的现象叫做Exposure Bias。

假设decoder在训练的时候永远只看到正确的东西,那么在测试的时候只要有一个错误就会一步错步步错。所以解决这个问题的一个可能的思路是给decoder的输入加入一些错误的东西,这被叫做Scheduled Sampling。但是这一思路可能会伤害到Transformer的平行化的能力。
Scheduled Sampling:在decoder进行训练的时候就给一些噪声(错误数据)。
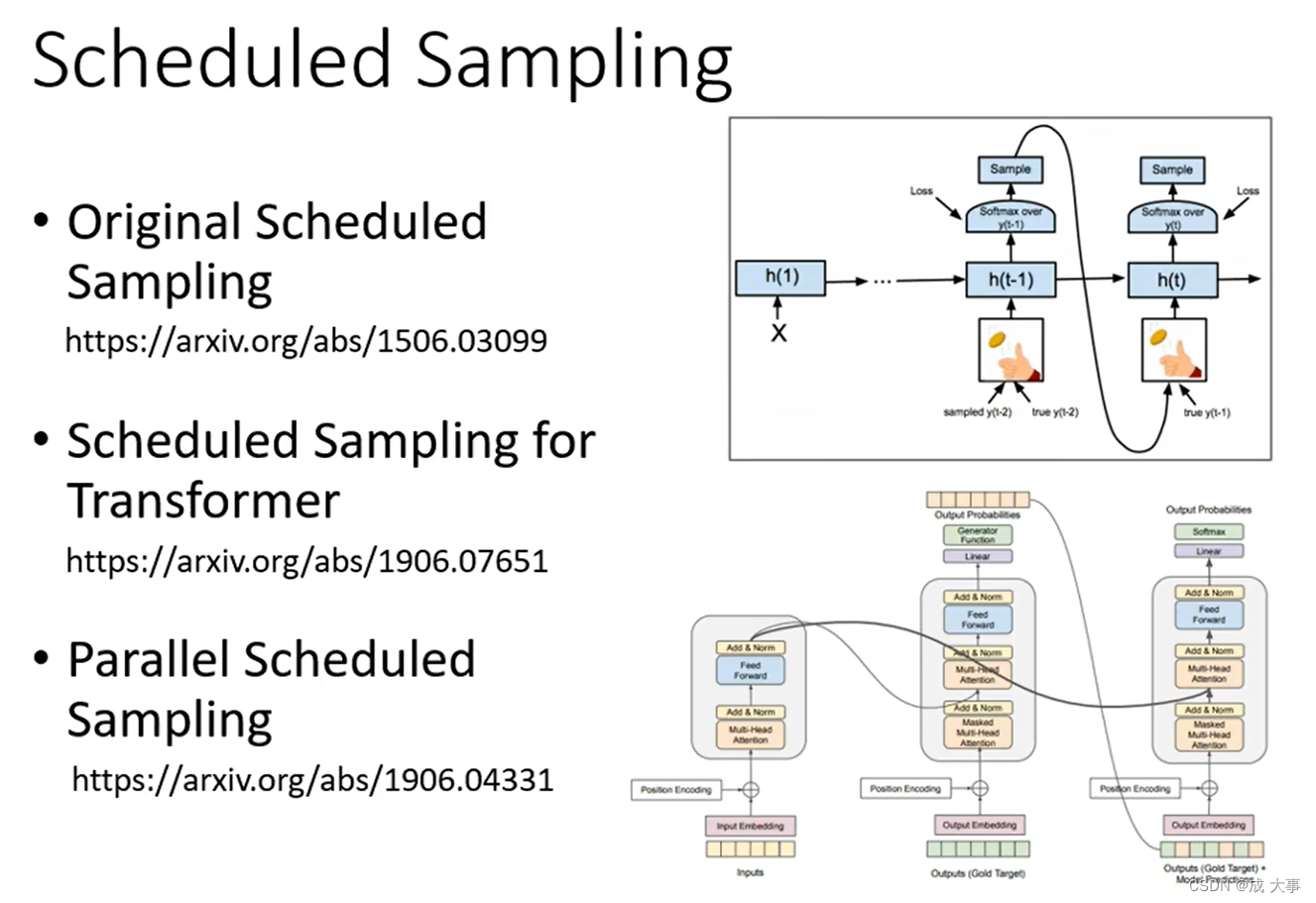
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks
Scheduled Sampling for Transformers
Parallel Scheduled Sampling















 969
969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









