







本篇围绕医疗VLP综述论文《Medical Vision Language Pretraining: A survey》展开,并挑选其中一些论文进一步阅读摘录。自己初入门,若有不当之处还请多多指正。
目录
B.1 特征抑制问题(feature suppression)
B.2 局部定位能力(local alignment / grounding)
一、动机整理
数据集方面,存在的一些源头问题:
- 数据稀缺(远比通用领域小几个数量级)
- 标注稀缺(费时费专家)
- 模态多样(各类结构不同的影像,报告,电子健康记录,传感器数据...)
- 图像相似(不同于通用领域中“猫”vs“狗”这样的差距,医疗数据的类间相似性很高,病理通常只占图像的一小部分,差异微妙且细粒度)
- 报告语言复杂(专业术语,较多缩写,写作风格多变,多为短句且正式,常用否定和不确定性的表达,更频繁的空间关系,特定领域修饰语的使用)
- 报告内容复杂(报告可能过长,每个短句都在单独描述某一方面)
- 类别不平衡(医疗数据集通常高度不平衡,与常见疾病或健康样本相比,罕见病理数量非常少,呈长尾分布)
- 类别重叠(类别细粒度+多标签+每种情况涉及多个病理条件 → 存在大量假负例)
其他的改进切入点:
- 局部对齐(词汇级/句子级/图像子区域/...)
- 利用报告结构(通常分为描述性片段Findings和结论性片段Impression,这两部分语义差别显著)
- 软化语义对比损失(细化标签 / 引入外部标签,引入领域知识,避免假负例)
- 数据增强(文本采样、重排、关系提取...)
- 未完待续...
二、自监督目标:
A. 掩码预测masked prediction
Masked Language Modeling (MLM) :屏蔽文本token,解码原始文本;
Masked Image Modeling (MIM):隐藏图像块,重建原始图像;
掩码预测提供了一种跨模态交互的直接方法:通过一种模态重建另一种模态。下面是两例:
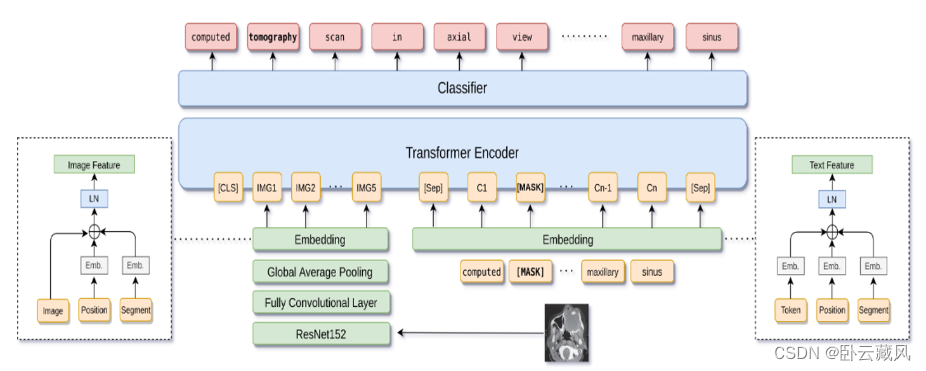
该模型使用ResNet提取的图像特征作为附加上下文,预测掩码医学文本
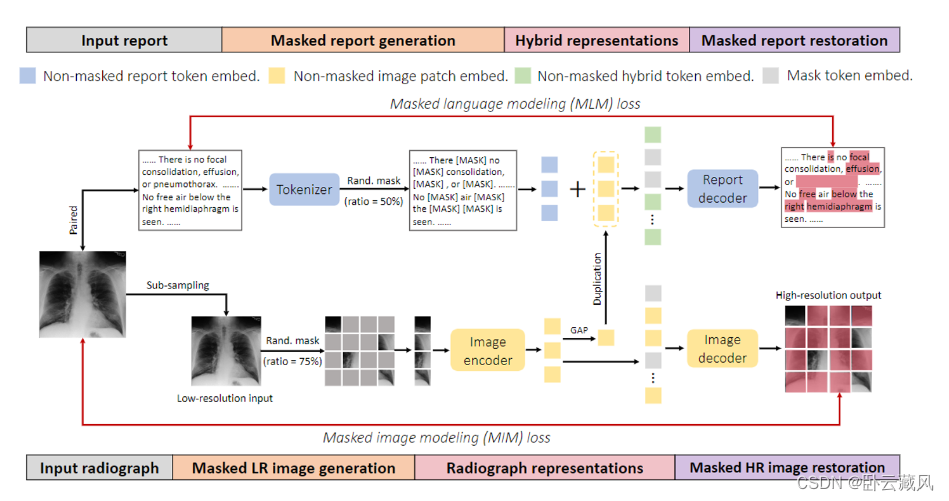
MIM:掩码低分辨率放射图像,重建高分辨率版本;
MIM:将图像特征与掩码文本表示相结合,以解码输入文本。
掩码预测的不足:
- 重建原始输入使模型能够学习低层次信息(pixel/token level),但需要特定的模态解码器,引入了额外的复杂性;
- 预训练阶段和下游阶段之间出现了轻微的域差距,预训练阶段需要掩码输入,而下游任务则为无掩码的完整输入。因此,仅依靠掩码预测目标的方法缺乏下游任务的zero-shot能力。
- 医学数据集通常包含罕见疾病,通常体现于局部的、细微的图像特征上。而 MIM 依赖于识别频繁模式进行学习,可能会在准确理解和表征这些罕见疾病方面遇到困难。
- 医学文本经常出现缩写和风格变化,这给 MLM 在学习一致表示方面带来了潜在的困难。
B. 对比学习contrastive learning
对比学习的目标是最大化每组图文对(正样本对)的表征相似性,最小化负样本对之间的相似性。最经典模型:CLIP
全局对比学习:Image-Text Contrastive Learning (ITC) / Global Alignment。下面是一例。

通过图像和文本模态的双向对比目标最大化图文对一致性
B.1 特征抑制问题(feature suppression)
对比学习需要良好的数据增强才能很好地工作,否则简单特征会抑制对困难特征的学习,模型走了捷径(shortcut)。比如,若要区分苹果和香蕉,“颜色分布”可能会抑制“物体形状”的学习,因此需要通过颜色增强(如转为灰度图)消除干扰。
然而,医疗领域有两大挑战:(1)存在已知增强方法都不能解决的特征抑制情况,不能确定模型走了什么捷径。(2)与预训练目标无关的特征可能会在后续下游任务中用到,特征的竞争会导致对潜在有用特征的建模能力不足。
有两篇同系列工作在尝试解决这一问题,分别发表在 MICCAI 2022 和 MICCAI 2023.
- Vision-Language Contrastive Learning Approach to Robust Automatic Placenta Analysis Using Photographic Images(MICCAI 2022)
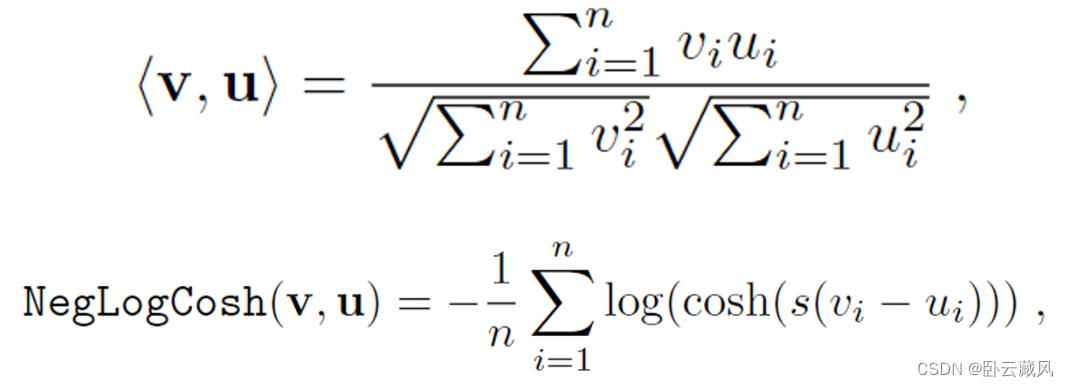
下:NegLogCosh相似度函数.
此文将余弦相似度函数修改为 neglogcosh 相似度函数,该函数对全局表示的变化更敏感。
简单来讲,作者认为cos相似度使用的是乘法,当向量某一位置为0时,就可能导致另一向量对应位置的特征被忽略。但在下游任务之前,特征的真正重要性是未知的。而neglogcosh会将所有值变化都反映在结果中,类似L1/L2,但比L1更稳定,比L2更平滑。
此外,作者受 dropout 启发,进一步提出子特征对比策略。既然不确定哪些特征有用,索性每个batch都只随机使用一些子特征来计算相似度。子特征对比,可以使模型学习特征空间中的更多、更一般的图文关系。既有助于缓解特征抑制问题,又减少过拟合。
- Enhancing Automatic Placenta Analysis Through Distributional Feature Recomposition in Vision-Language Contrastive Learning (MICCAI 2023)
此文指出,传统方法(例如 Con-VIRT)将整个报告编码为单个向量表示。有两个问题:1. 编码过程可能抑制报告中的重要特征,因为编码器会忽略某些特征以最小化损失,导致只有单个主导特征在影响目标,而非所有相关特征。2. 病理报告的长度可能过长导致在编码时截断。
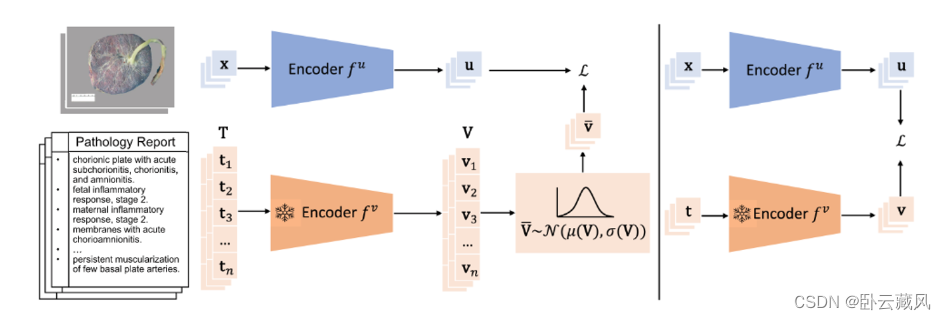
此文引入特征重组技术以增强特征表示的鲁棒性。(1)病理学报告特征重组:从可变长度的病理报告中捕获特征。(2)分布特征重组:提供更稳健的分布感知表示。
首先将病理报告分解,各自单独编码以捕获所有胎盘文本特征。为了避免这些特征向量相加时可能出现的“蝴蝶效应”(此处为个人概括;即使单个特征的微小变化也会显著改变整体表示,另外,两个完全不同的特征集合在各自求和后也可能会得到相同的表示),引入分布特征重组策略,估计由每组特征定义的稳定高维向量空间(数学公式过多,略)。
B.2 局部定位能力(local alignment / grounding)
全局对比学习,主要关注高级特征,倾向于忽略低级特征 /局部视觉关键信息,不适合分割/检测等任务。因此需要额外强制单词(或句子)与图像区域之间的显式局部对齐,还额外提高了可解释性。一般来说,局部对齐在成对的图文对特征中执行,而全局对齐则是不同对之间。
- GLoRIA(2021.10)
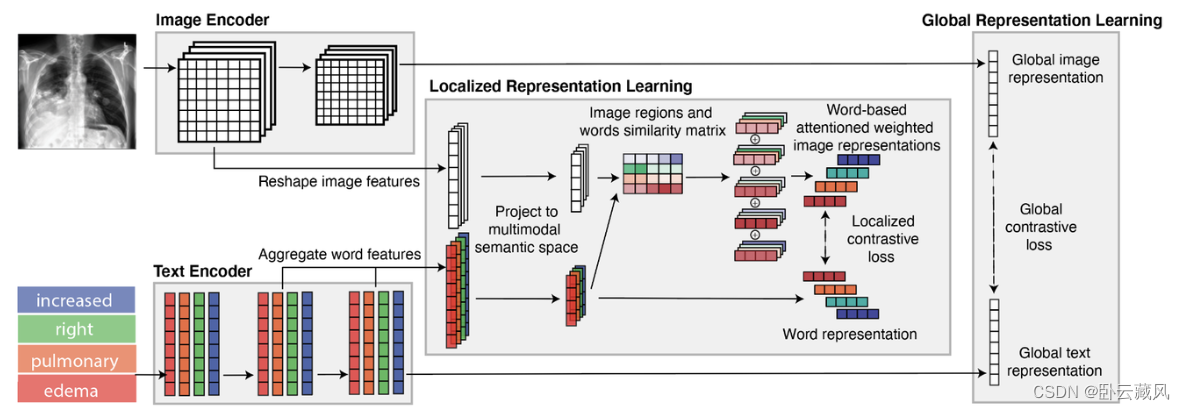
通过双向对比损失,对齐每个词嵌入向量与注意力加权的图像特征
动机:医学图像的类间相似性很高,只能通过非常微妙的视觉线索来区分。病理通常只占图像的一小部分,对应于医学报告中的某些关键词。
观点:同时使用全局和局部损失,模型能够使用互补信息学习更好的全局和局部表示。
方法:不依赖预训练的检测器,而是学习注意力权重,强调特定单词的重要图像子区域以创建带有上下文感知的局部图像表示,学习图像子区域和单词之间细粒度对齐的局部对比损失。
- IMITATE(2023.10)
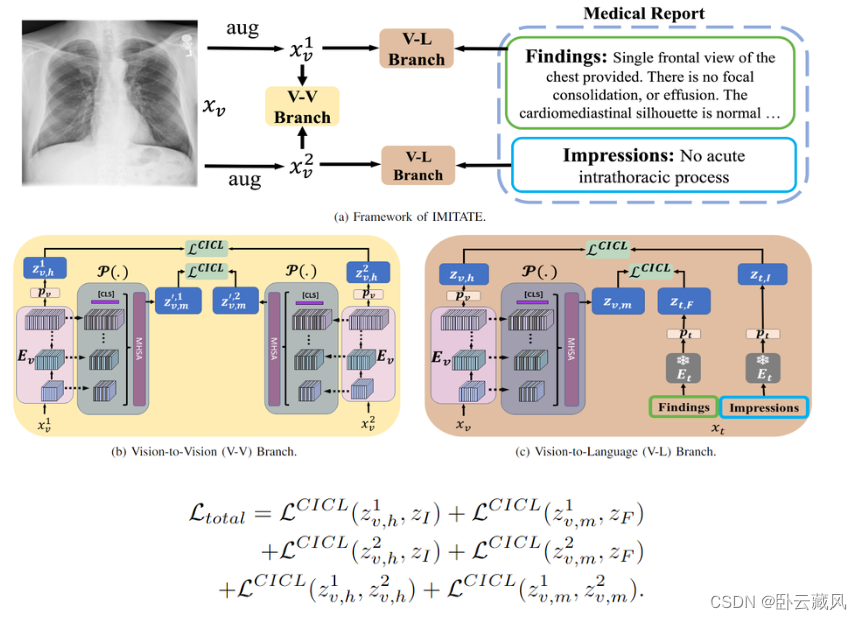
报告的Finding部分→局部对齐,Impression部分→全局对齐
动机:(1)之前的工作没有考虑到医疗报告中描述性(Finding)和结论性(Impression)片段之间的区别,前者描述图像内容,后者分析结论。(2)GLORIA等工作将报告分割成token进行局部对齐,但单独对token编码会缺乏适当的上下文,且不一定有直接的视觉对应。例如,在“Impression”部分,“兼容”或“急性”等术语缺乏直接的视觉相关性。
方法:提出了一种临床知情对比损失(CICL),将高级视觉特征和报告结论部分对齐,多层次的视觉特征和报告描述部分对齐。
B.3 假负例样本对(false negative)
对比学习容易出现假负例,即负样本可能属于与锚点存在相似性甚至同类别。
在医学领域这种情况的可能性更高,医学数据集本质上是多类的(multi-class),每种情况涉及多个病理条件,因此锚点和负样本可能共享一些异常条件。这些假负例会在无意中将具有相似语义的数据表征推开。如下图所示
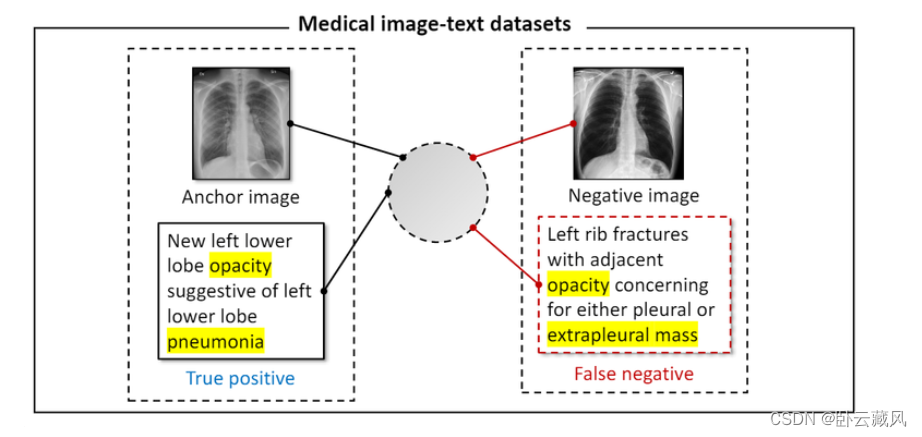
改进思路大致可分为:(1)改进构造正负例的方法,创造更多正样本对(解耦原始数据,拆分重组报告)(2)改进判断正负例的条件,避免误判为负样本对(如引入领域知识,根据语义判断正负例)
- MedCLIP(2022.10)
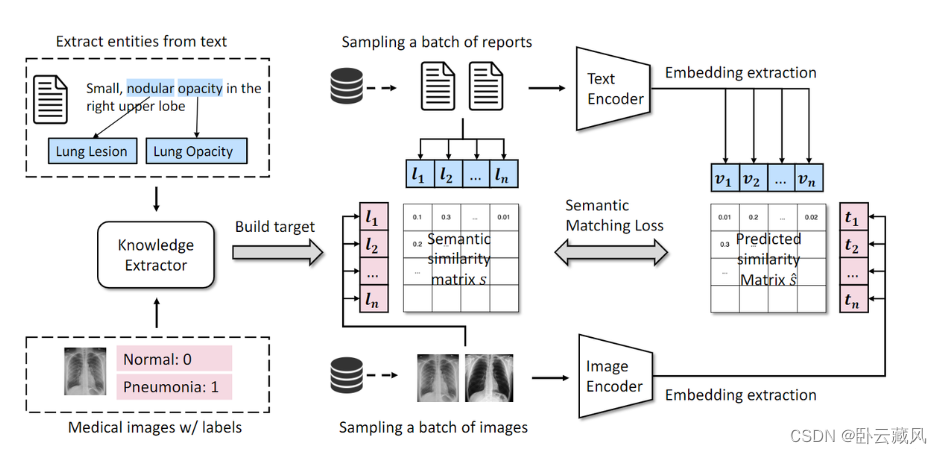
利用领域知识扩充数据集,减少假负例
动机:(1)数据太少,希望挖掘所有正对以消除假负例。 (2) 与一般领域的语义差异相比(如“猫”vs.“狗”),医学领域的差异更加细粒度,有必要捕捉微妙而关键的医学含义。
操作:(1)解耦原始图文对,根据领域知识重组,扩大数据集规模。(2)使用基于医学知识的软语义匹配损失代替InfoNCE loss,以医学语义相似度作为监督信号,消除对比学习假负例。
- Positive-pair loss relaxation(2022.12)
为了利用多标签的性质,MedCLIP使用了专家标签,而jang等人提出了一种基于句子采样和正对损失松弛的新微调策略,不需要任何显式标签。
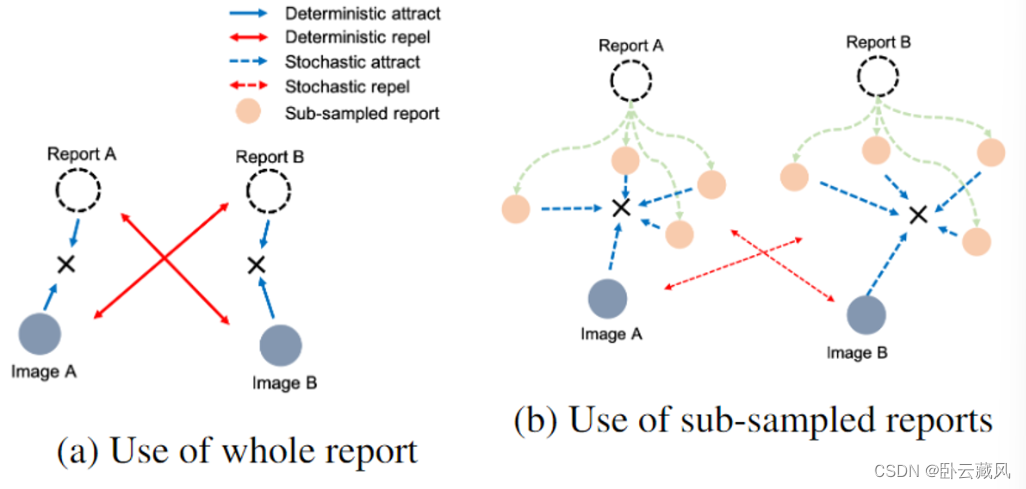
医疗报告大多数句子都简短且正式,每个句子通常包括对不同疾病或解剖发现的描述。因此,token级别的文本增强,例如随机删除或切换,可能会损害报告的正确语义。作者对每份报告中的句子做随机子采样,可得到更多的正样本,而不仅仅使用原始的一个正对进行训练。
与通用领域相比,由于医学领域的细粒度标签范围,假负例问题更严重。作者认为减少正对之间的吸引力可以缓解。通过裁剪相似函数的上限(放松对比损失),限制余弦相似度大于 t 的样本,确保假负例图文对的表征不会被推开太远,使模型专注于真负例样本对(perfectly negative pairs,即不同患者且不同语义的图像/报告)。如下图所示:
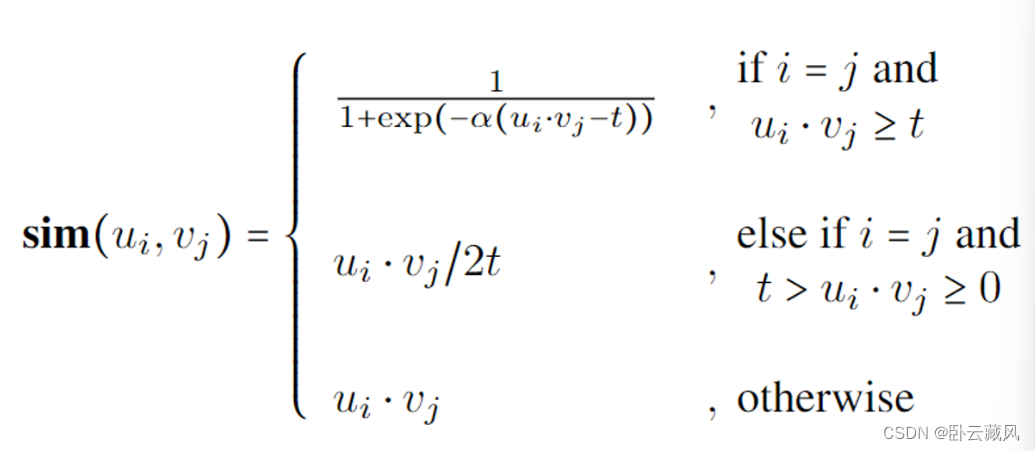
小结:对比学习没有复杂解码器和融合模块的复杂架构,目标简单且计算成本低。然而,假负例引入的噪声和偏差仍然是一个问题,需要进一步研究。
C. 匹配预测matching prediction
匹配预测的训练目标是预测输入视觉和文本对是否匹配,需要结合图像和文本特征,输入匹配概率值,用二元交叉熵损失BCE loss训练。通常被称为图像-文本匹配(ITM)。通常,匹配预测与其他预训练目标结合使用。
D. 混合目标hybrid objectives
上述三种方法都有局限性,对比和匹配预测方法容易出现假负例,而掩码建模方法缺乏zero-shot能力。因此常常混合使用。
D.1 掩码预测+对比学习
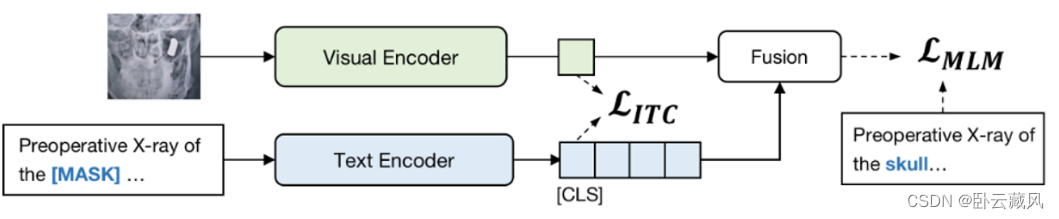
这两者学习原则相辅相成。对比学习明确区分正负图文对,增强了表征的判别能力。掩码预测能更细粒度的捕获低级模态信息。如下图PMC-CLIP:
一些工作还利用单模态对比学习或掩码建模,以便在预训练之前初始化编码器。
- BioViL(2022.4)
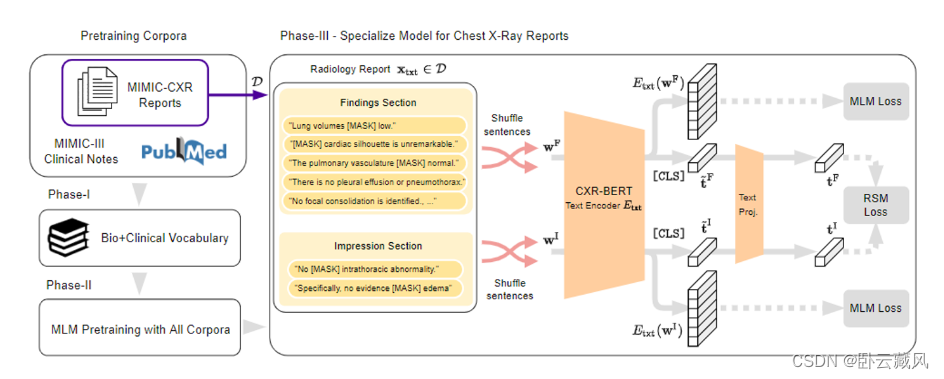
动机:(1)不充分的文本建模会降低联合潜在表征的质量。(2)文本描述提供了语义更密集的学习信号,在联合训练前充分利用文本建模,可以巨大改进。
BioViL所提出的CXR-BERT文本编码器,在预训练时使用了相关领域词汇表、掩码语言建模 (MLM) 、描述-结论片段的匹配损失(RSM)、正则化和文本增强(shuffle)。
D.2 掩码预测+匹配预测
对比学习是在几乎没有模态融合的情况下进行的,无法建立模态间的丰富交互,而匹配预测应用于融合的多模态嵌入,并能够更好地捕获跨模态交互。
- MedViLL(2022.12)
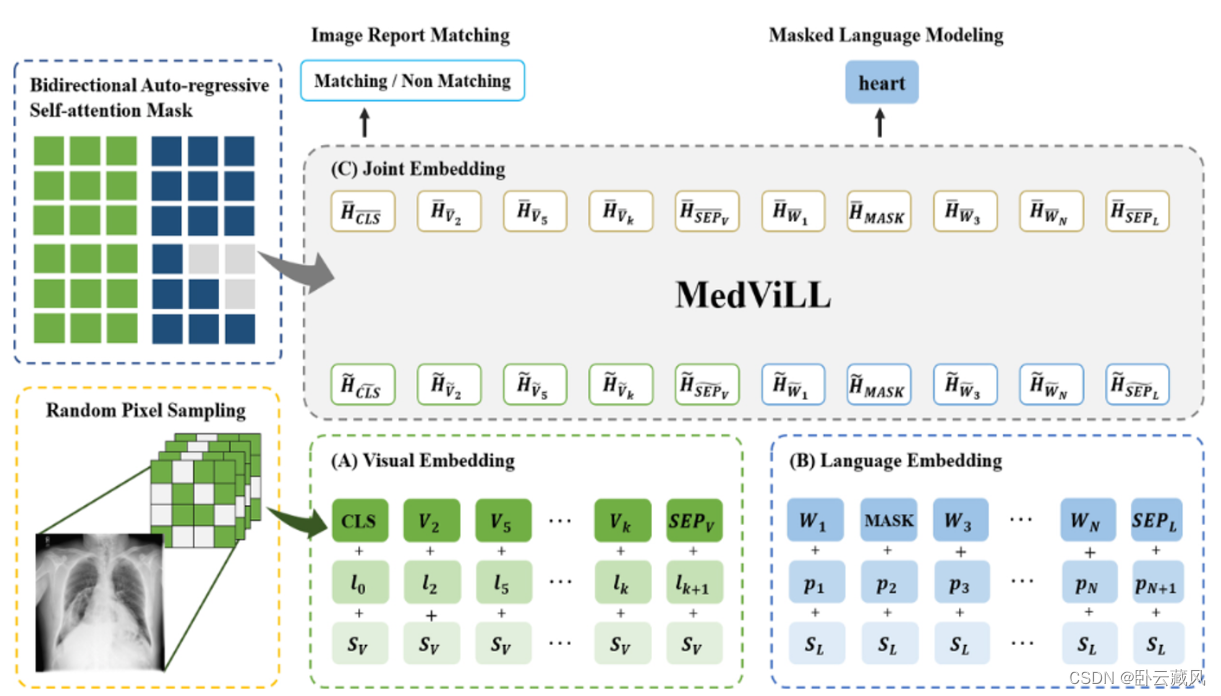
使用MLM和ITM进行预训练,并提出了一种新的自注意力掩码方式——双向自回归 (BAR),允许在预训练期间将图像特征与语言特征混合,同时保留自回归语言生成的因果性质。
D.3 其他混合目标
各类工作还探索了其他目标(例如生成、聚类、分类、蒸馏等)以增强预训练。但需要注意不同的预训练目标会给训练过程带来额外的复杂性,还可能引入目标之间的彼此干扰与破坏。
- MGCA(2022.10)
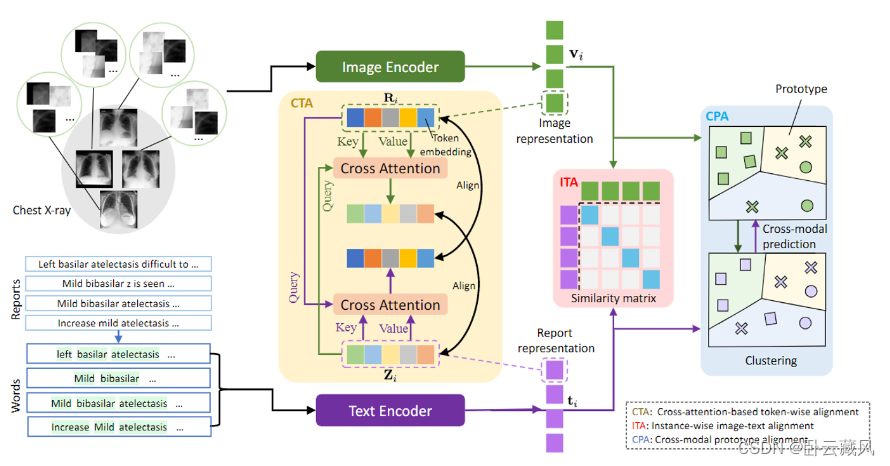
动机:(1)现有的方法受限于实例和局部的监督目标,忽略了疾病级别的语义对应。(2)为了减少假负例,可以引入一个聚类目标,将语义相似的样本分组到同一个集群中,从而实现对跨实例的疾病级语义对应关系的利用。
创新:提出了一种新颖的多粒度跨模态对齐框架MGCA,在三个不同的层次上执行对齐,分别是局部病理区域级、患者实例级、疾病原型级。对于疾病级对齐,利用Sinkhorn-Knopp聚类算法,用一种模态的软聚类分配(soft cluster assignment codes)来训练另一种模态的表示。
- KAD(2023.6)
还有一些方法,旨在利用从外部标记工具和知识库中获得的额外监督信号作为分类目标,来增强预训练。提取标签不仅涉及识别不同病理实体,还需准确识别否定和不确定性表达。KAD(2023.6)利用现有的医学领域知识,显式学习医学知识图的神经表示,将专家知识注入到文本嵌入空间中,为视觉方面的表示学习提供知识指导。
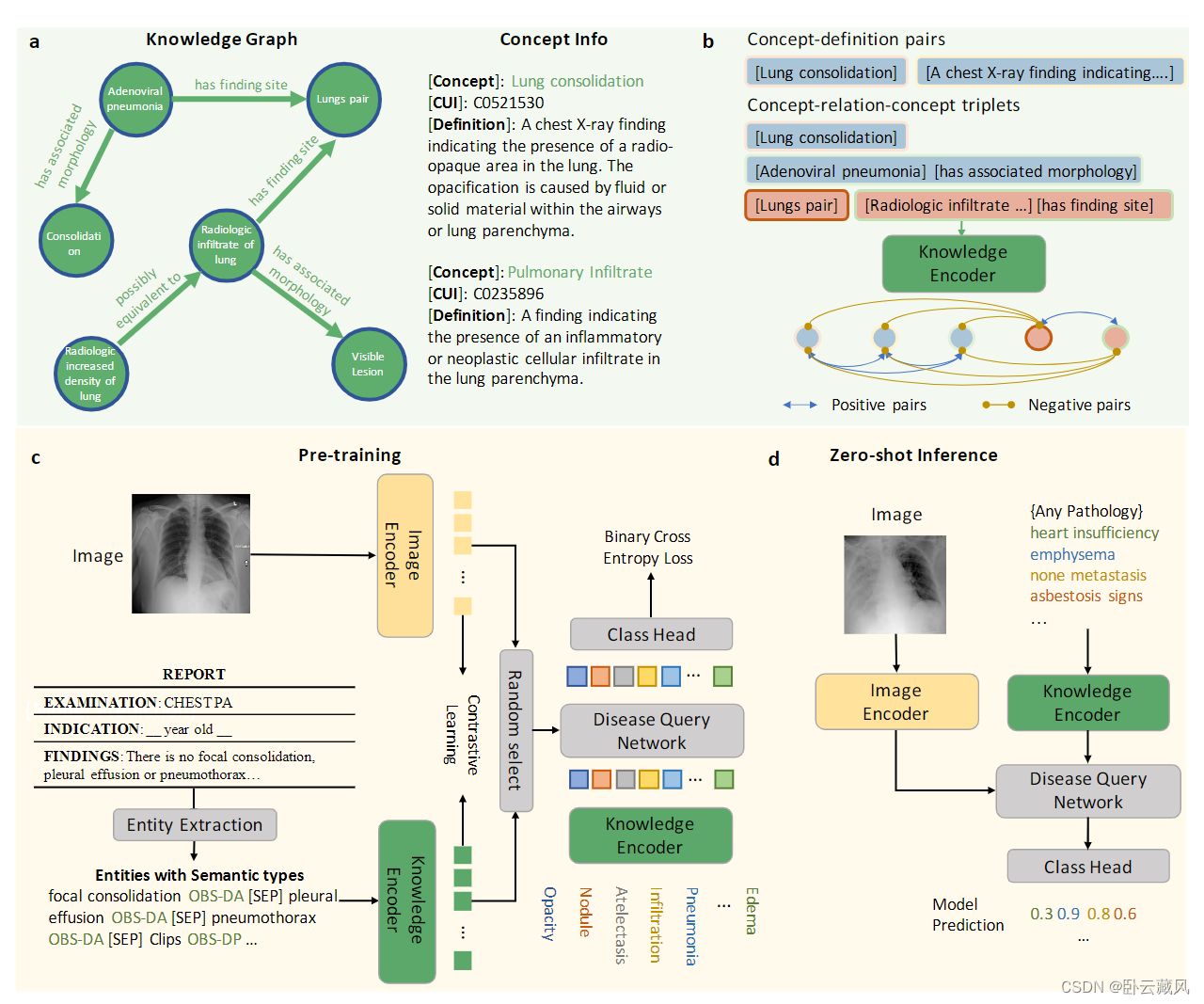
KAD:1 训练一个知识编码器学习知识图的表示;2 使用启发式规则、RadGraph或ChatGPT从医疗报告中提取实体和关系;3 利用预训练的知识编码器来指导视觉表征学习,优化用于分类的Disease Query Network,将领域知识注入到视觉编码器中
三、其他技术点
-
使用无配对的图文对数据
为了克服图文对数据不足的问题,许多论文提出了在预训练期间利用无配对数据集(仅图像或纯文本)的方法。如利用图像数据集中存在的类标签/图表信息来创建文本句子,其他工作使用生成方法获得额外的配对数据。
-
使用时序信息
与典型的自然语言文本不同,临床报告经常包含对过去历史的引用,提供时间上下文。例如,“胸部x光显示治疗后巩固和支气管血管标记减少”。因此需要跨时间的密集型多图视觉推理来捕获时间特征。
-
综合不同视角影像
在临床实践中,医生通常依赖于放射影像的多角度视图进行准确评估。不同的视觉线索往往在不同的视图上更加明显。
-
数据增强
数据增强有助于提高模型的鲁棒性和泛化性能。由于医学领域的数据量特别有限,增强可以极大地帮助增加数据集的大小。但在应用图像的空间增强(例如翻转、裁剪和掩蔽)时,应考虑因增强图像而与报告中的空间描述产生错位,文本同理。主要用于的文本增强技术包括句子重排序、随机句子采样和句子转述。
LeMDA(2023.4)可以在特征空间中自动学习多模态数据的增强方法, 解除了对破坏输入数据语义的担忧。作者将增强变换设计为可学习的模块,使其能够适应各种多模态任务和跨模态关系。增强模块与多模态网络一起学习,通过对抗性训练生成增强数据,同时通过一致性正则化保留语义结构,如下图。
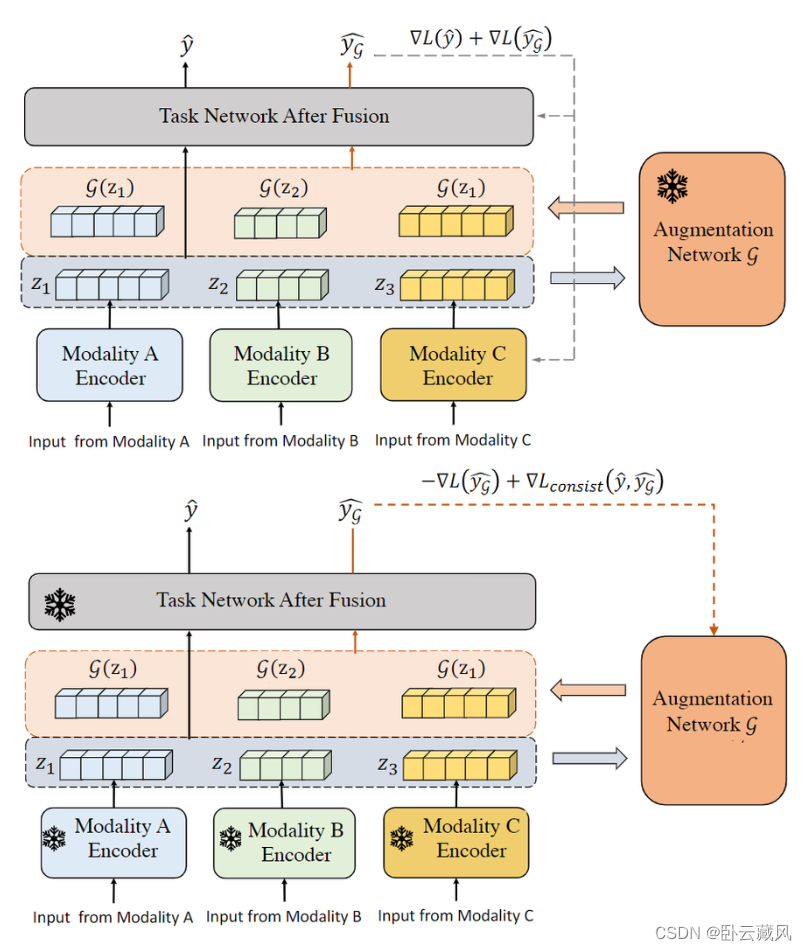
四、启发:
- 要多跳出医疗领域,关注通用领域,很多buff都是搬来的
- 从数据特点入手对症下药
- 可以引入大模型去执行生成任务、多句子推理判断
- 未完待续

















 1801
1801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









